Downloaded 82 times


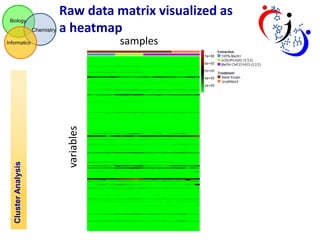
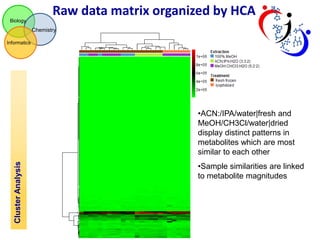
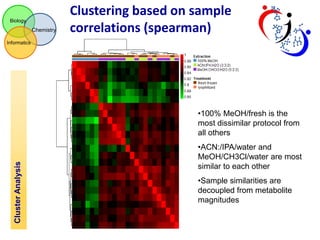



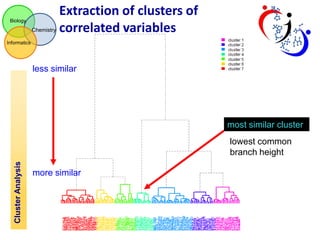
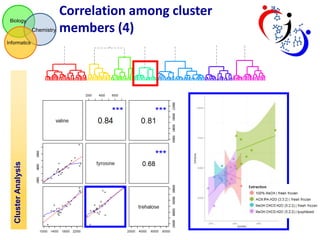

The document discusses using hierarchical cluster analysis (HCA) to evaluate metabolomic sample processing methods. It describes two goals: 1) Use HCA to cluster samples based on raw data similarities and correlations to determine the impact of extraction and treatment methods on data variance. Extraction had the greatest effect, with ACN:/IPA/water and MeOH/CH3Cl/water samples most similar. 2) Use HCA to cluster metabolites based on z-scaled data and correlations to identify groups of related metabolites and evaluate the robustness of different correlation measures. Clusters extracted from the correlation-based dendrogram contained metabolites that shared biological functions.





































