Download as PDF, PPTX


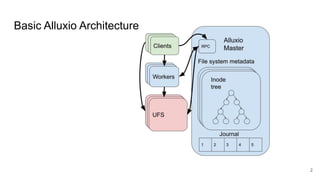
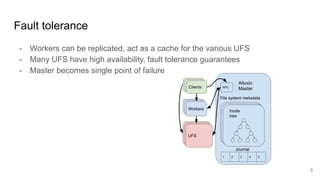



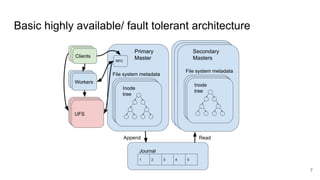
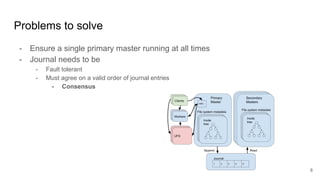



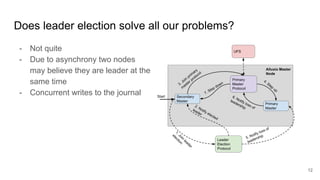
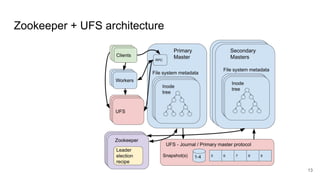

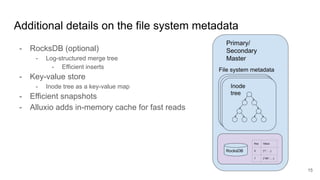

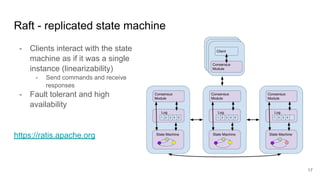
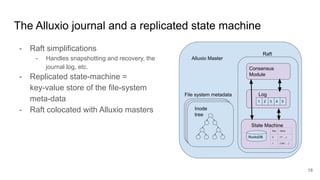
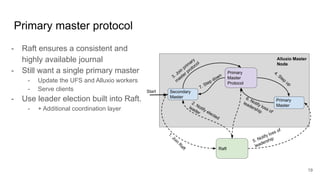
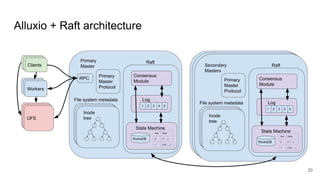



The document discusses the evolution of Alluxio's journal system aimed at achieving high availability and fault tolerance. It details the architecture, including the use of a replicated state machine (Raft) for consistent journal management and leader election, as well as challenges related to maintaining a single primary master and handling concurrent writes. The advantages of simplifying the system by colocating the Raft protocol with Alluxio masters are highlighted, focusing on performance and efficiency.

















































































