Download as PDF, PPTX




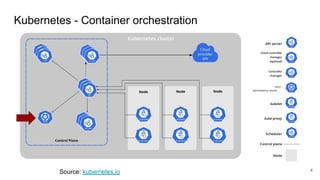
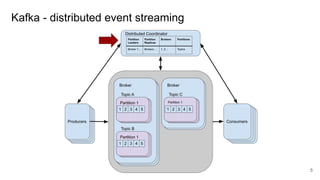
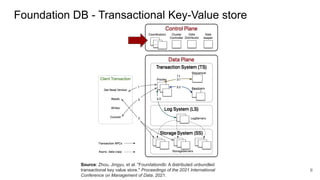
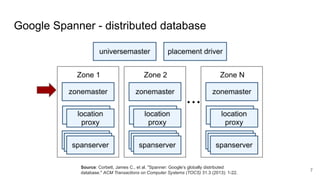
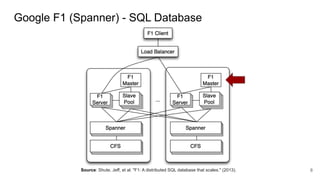
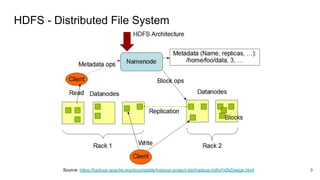


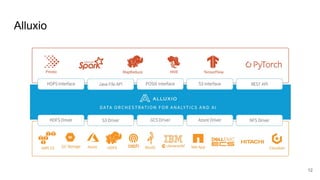
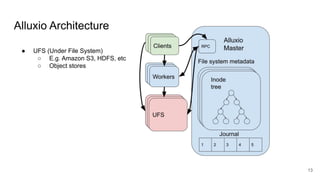
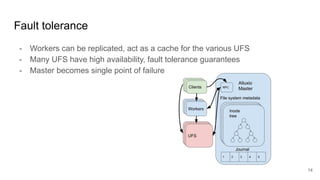
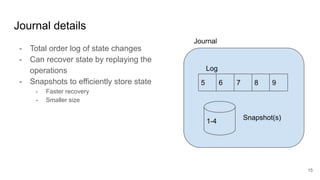


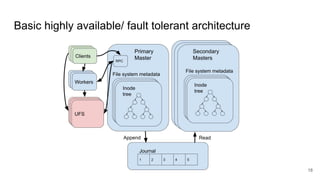
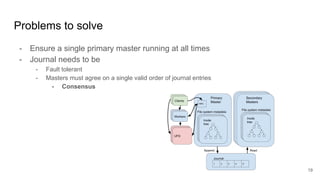



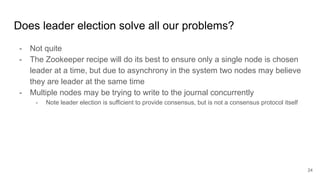
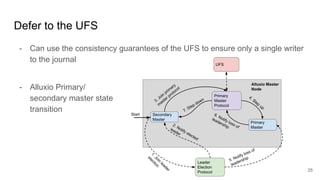

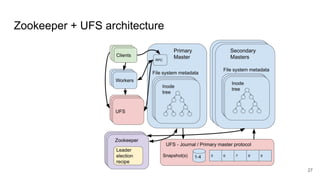


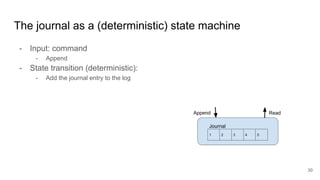
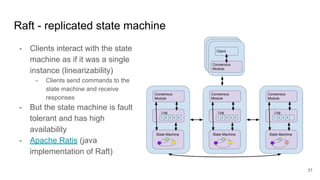
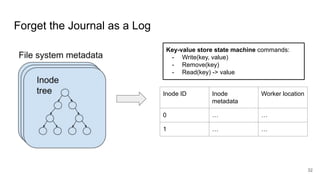
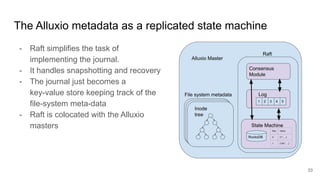

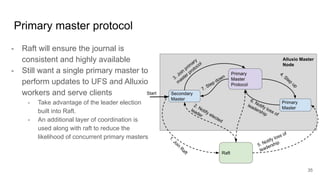
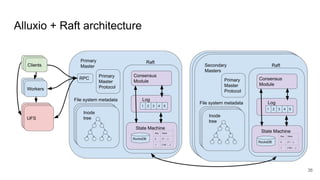





The document compares two stateful distributed coordination implementations in Alluxio: Zookeeper with UFS and Raft. It discusses high availability and fault tolerance mechanisms, outlining the challenges of maintaining a single primary master and ensuring journal consistency. Ultimately, Raft is presented as a simpler and more efficient alternative due to its integrated handling of leader election and journal management.






![Distributed Consensus: Making Impossible Possible [Revised]](https://cdn.slidesharecdn.com/ss_thumbnails/impossibleconsensus-161020212626-thumbnail.jpg?width=640&height=640&fit=bounds)




























































