Download free for 30 days
Sign in
Upload
Language (EN)
Support
Business
Mobile
Social Media
Marketing
Technology
Art & Photos
Career
Design
Education
Presentations & Public Speaking
Government & Nonprofit
Healthcare
Internet
Law
Leadership & Management
Automotive
Engineering
Software
Recruiting & HR
Retail
Sales
Services
Science
Small Business & Entrepreneurship
Food
Environment
Economy & Finance
Data & Analytics
Investor Relations
Sports
Spiritual
News & Politics
Travel
Self Improvement
Real Estate
Entertainment & Humor
Health & Medicine
Devices & Hardware
Lifestyle
Change Language
Language
English
Español
Português
Français
Deutsche
Cancel
Save
Submit search
EN
Uploaded by
Yuki Arase
PDF, PPTX
44,136 views
[最新版] JSAI2018 チュートリアル「"深層学習時代の" ゼロから始める自然言語処理」
最新版のJSAI2018でのチュートリアル資料です。 --- 6月7日(木) 13:50-15:30 I会場(2F ロイヤルガーデンA) ---
Technology
◦
Related topics:
Deep Learning
•
Read more
59
Save
Share
Embed
Embed presentation
Download
Download as PDF, PPTX
1
/ 80
2
/ 80
3
/ 80
4
/ 80
5
/ 80
6
/ 80
7
/ 80
8
/ 80
9
/ 80
10
/ 80
11
/ 80
12
/ 80
13
/ 80
14
/ 80
15
/ 80
16
/ 80
17
/ 80
18
/ 80
19
/ 80
20
/ 80
21
/ 80
22
/ 80
23
/ 80
24
/ 80
25
/ 80
26
/ 80
27
/ 80
28
/ 80
29
/ 80
30
/ 80
31
/ 80
32
/ 80
33
/ 80
34
/ 80
35
/ 80
36
/ 80
37
/ 80
38
/ 80
39
/ 80
40
/ 80
41
/ 80
42
/ 80
43
/ 80
44
/ 80
45
/ 80
46
/ 80
47
/ 80
48
/ 80
49
/ 80
50
/ 80
51
/ 80
52
/ 80
53
/ 80
54
/ 80
55
/ 80
56
/ 80
57
/ 80
58
/ 80
59
/ 80
60
/ 80
61
/ 80
62
/ 80
63
/ 80
64
/ 80
65
/ 80
66
/ 80
67
/ 80
68
/ 80
69
/ 80
70
/ 80
71
/ 80
72
/ 80
73
/ 80
74
/ 80
75
/ 80
76
/ 80
77
/ 80
78
/ 80
79
/ 80
80
/ 80
More Related Content
PDF
最適化超入門
by
Takami Sato
PDF
自己教師学習(Self-Supervised Learning)
by
cvpaper. challenge
PDF
Skip Connection まとめ(Neural Network)
by
Yamato OKAMOTO
PDF
Layer Normalization@NIPS+読み会・関西
by
Keigo Nishida
PDF
生成モデルの Deep Learning
by
Seiya Tokui
PDF
深層強化学習と実装例
by
Deep Learning Lab(ディープラーニング・ラボ)
PDF
研究効率化Tips Ver.2
by
cvpaper. challenge
PDF
High-impact Papers in Computer Vision: 歴史を変えた/トレンドを創る論文
by
cvpaper. challenge
最適化超入門
by
Takami Sato
自己教師学習(Self-Supervised Learning)
by
cvpaper. challenge
Skip Connection まとめ(Neural Network)
by
Yamato OKAMOTO
Layer Normalization@NIPS+読み会・関西
by
Keigo Nishida
生成モデルの Deep Learning
by
Seiya Tokui
深層強化学習と実装例
by
Deep Learning Lab(ディープラーニング・ラボ)
研究効率化Tips Ver.2
by
cvpaper. challenge
High-impact Papers in Computer Vision: 歴史を変えた/トレンドを創る論文
by
cvpaper. challenge
What's hot
PPTX
【DL輪読会】SimCSE: Simple Contrastive Learning of Sentence Embeddings (EMNLP 2021)
by
Deep Learning JP
PDF
Word2vecの理論背景
by
Masato Nakai
PPTX
報酬設計と逆強化学習
by
Yusuke Nakata
PDF
Optimizer入門&最新動向
by
Motokawa Tetsuya
PDF
第5章混合分布モデルによる逐次更新型異常検知
by
Tetsuma Tada
PDF
【メタサーベイ】基盤モデル / Foundation Models
by
cvpaper. challenge
PDF
グラフニューラルネットワーク入門
by
ryosuke-kojima
PPTX
[DL輪読会]ドメイン転移と不変表現に関するサーベイ
by
Deep Learning JP
PPTX
PyTorchLightning ベース Hydra+MLFlow+Optuna による機械学習開発環境の構築
by
Kosuke Shinoda
PDF
大規模な組合せ最適化問題に対する発見的解法
by
Shunji Umetani
PPTX
Transformerを雰囲気で理解する
by
AtsukiYamaguchi1
PDF
SSII2022 [SS2] 少ないデータやラベルを効率的に活用する機械学習技術 〜 足りない情報をどのように補うか?〜
by
SSII
PDF
最適輸送の計算アルゴリズムの研究動向
by
ohken
PDF
【DL輪読会】Mastering Diverse Domains through World Models
by
Deep Learning JP
PPTX
【DL輪読会】ViT + Self Supervised Learningまとめ
by
Deep Learning JP
PDF
BlackBox モデルの説明性・解釈性技術の実装
by
Deep Learning Lab(ディープラーニング・ラボ)
PDF
トップカンファレンスへの論文採択に向けて(AI研究分野版)/ Toward paper acceptance at top conferences (AI...
by
JunSuzuki21
PDF
強化学習その3
by
nishio
PDF
[DL輪読会]Model soups: averaging weights of multiple fine-tuned models improves ...
by
Deep Learning JP
PDF
2019年度チュートリアルBPE
by
広樹 本間
【DL輪読会】SimCSE: Simple Contrastive Learning of Sentence Embeddings (EMNLP 2021)
by
Deep Learning JP
Word2vecの理論背景
by
Masato Nakai
報酬設計と逆強化学習
by
Yusuke Nakata
Optimizer入門&最新動向
by
Motokawa Tetsuya
第5章混合分布モデルによる逐次更新型異常検知
by
Tetsuma Tada
【メタサーベイ】基盤モデル / Foundation Models
by
cvpaper. challenge
グラフニューラルネットワーク入門
by
ryosuke-kojima
[DL輪読会]ドメイン転移と不変表現に関するサーベイ
by
Deep Learning JP
PyTorchLightning ベース Hydra+MLFlow+Optuna による機械学習開発環境の構築
by
Kosuke Shinoda
大規模な組合せ最適化問題に対する発見的解法
by
Shunji Umetani
Transformerを雰囲気で理解する
by
AtsukiYamaguchi1
SSII2022 [SS2] 少ないデータやラベルを効率的に活用する機械学習技術 〜 足りない情報をどのように補うか?〜
by
SSII
最適輸送の計算アルゴリズムの研究動向
by
ohken
【DL輪読会】Mastering Diverse Domains through World Models
by
Deep Learning JP
【DL輪読会】ViT + Self Supervised Learningまとめ
by
Deep Learning JP
BlackBox モデルの説明性・解釈性技術の実装
by
Deep Learning Lab(ディープラーニング・ラボ)
トップカンファレンスへの論文採択に向けて(AI研究分野版)/ Toward paper acceptance at top conferences (AI...
by
JunSuzuki21
強化学習その3
by
nishio
[DL輪読会]Model soups: averaging weights of multiple fine-tuned models improves ...
by
Deep Learning JP
2019年度チュートリアルBPE
by
広樹 本間
Similar to [最新版] JSAI2018 チュートリアル「"深層学習時代の" ゼロから始める自然言語処理」
PDF
[旧版] JSAI2018 チュートリアル「"深層学習時代の" ゼロから始める自然言語処理」
by
Yuki Arase
PDF
東京大学2020年度深層学習(Deep learning基礎講座) 第9回「深層学習と自然言語処理」(一部文字が欠けてます)
by
Hitomi Yanaka
PDF
東京大学2021年度深層学習(Deep learning基礎講座2021) 第8回「深層学習と自然言語処理」
by
Hitomi Yanaka
PDF
Deep Learningの基礎と応用
by
Seiya Tokui
PDF
Recurrent Neural Networks
by
Seiya Tokui
PDF
Extract and edit
by
禎晃 山崎
PPTX
東京大学2020年度深層学習(Deep learning基礎講座) 第9回「深層学習と自然言語処理」
by
Hitomi Yanaka
PPTX
【論文紹介】Distributed Representations of Sentences and Documents
by
Tomofumi Yoshida
PDF
第64回情報科学談話会(岡﨑 直観 准教授)
by
gsis gsis
PPTX
Interop2017
by
tak9029
PDF
Deep nlp 4.2-4.3_0309
by
cfiken
PDF
ニューラルネットワークを用いた自然言語処理
by
Sho Takase
PDF
20181123 seq gan_ sequence generative adversarial nets with policy gradient
by
h m
PDF
BERTに関して
by
Saitama Uni
PDF
transformer解説~Chat-GPTの源流~
by
MasayoshiTsutsui
PDF
論文紹介:PaperRobot: Incremental Draft Generation of Scientific Idea
by
HirokiKurashige
PDF
STAIR Lab Seminar 202105
by
Sho Takase
PDF
Fast abstractive summarization with reinforce selected sentence rewriting
by
Yasuhide Miura
PPTX
「機械学習とは?」から始める Deep learning実践入門
by
Hideto Masuoka
PDF
Non-autoregressive text generation
by
nlab_utokyo
[旧版] JSAI2018 チュートリアル「"深層学習時代の" ゼロから始める自然言語処理」
by
Yuki Arase
東京大学2020年度深層学習(Deep learning基礎講座) 第9回「深層学習と自然言語処理」(一部文字が欠けてます)
by
Hitomi Yanaka
東京大学2021年度深層学習(Deep learning基礎講座2021) 第8回「深層学習と自然言語処理」
by
Hitomi Yanaka
Deep Learningの基礎と応用
by
Seiya Tokui
Recurrent Neural Networks
by
Seiya Tokui
Extract and edit
by
禎晃 山崎
東京大学2020年度深層学習(Deep learning基礎講座) 第9回「深層学習と自然言語処理」
by
Hitomi Yanaka
【論文紹介】Distributed Representations of Sentences and Documents
by
Tomofumi Yoshida
第64回情報科学談話会(岡﨑 直観 准教授)
by
gsis gsis
Interop2017
by
tak9029
Deep nlp 4.2-4.3_0309
by
cfiken
ニューラルネットワークを用いた自然言語処理
by
Sho Takase
20181123 seq gan_ sequence generative adversarial nets with policy gradient
by
h m
BERTに関して
by
Saitama Uni
transformer解説~Chat-GPTの源流~
by
MasayoshiTsutsui
論文紹介:PaperRobot: Incremental Draft Generation of Scientific Idea
by
HirokiKurashige
STAIR Lab Seminar 202105
by
Sho Takase
Fast abstractive summarization with reinforce selected sentence rewriting
by
Yasuhide Miura
「機械学習とは?」から始める Deep learning実践入門
by
Hideto Masuoka
Non-autoregressive text generation
by
nlab_utokyo
More from Yuki Arase
PDF
闘病ブログからの医薬品奏功情報認識
by
Yuki Arase
PDF
自然言語処理によるテキストデータ処理
by
Yuki Arase
PDF
SPADE: Evaluation Dataset for Monolingual Phrase Alignment
by
Yuki Arase
PDF
NLP R&D 育成と連携:NLP若手の会 (YANS)の取り組み
by
Yuki Arase
PDF
Monolingual Phrase Alignment on Parse Forests (EMNLP2017 presentation)
by
Yuki Arase
PDF
ゼロから始める自然言語処理 【FIT2016チュートリアル】
by
Yuki Arase
闘病ブログからの医薬品奏功情報認識
by
Yuki Arase
自然言語処理によるテキストデータ処理
by
Yuki Arase
SPADE: Evaluation Dataset for Monolingual Phrase Alignment
by
Yuki Arase
NLP R&D 育成と連携:NLP若手の会 (YANS)の取り組み
by
Yuki Arase
Monolingual Phrase Alignment on Parse Forests (EMNLP2017 presentation)
by
Yuki Arase
ゼロから始める自然言語処理 【FIT2016チュートリアル】
by
Yuki Arase
[最新版] JSAI2018 チュートリアル「"深層学習時代の" ゼロから始める自然言語処理」
1.
"深層学習時代の" ゼロから始める自然言語処理 大阪大学大学院情報科学研究科 荒瀬由紀 1
2.
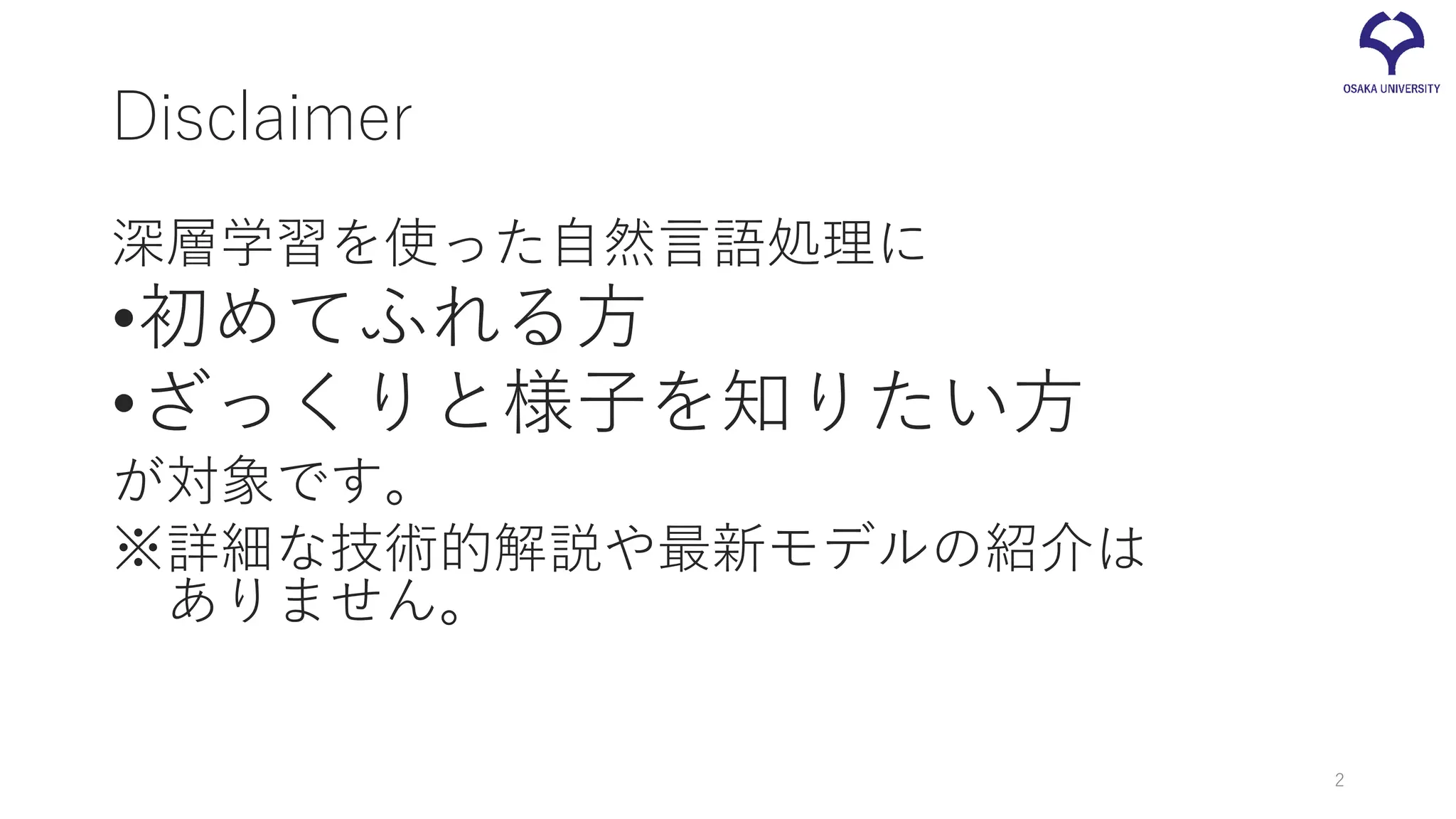
Disclaimer 深層学習を使った自然言語処理に •初めてふれる方 •ざっくりと様子を知りたい方 が対象です。 ※詳細な技術的解説や最新モデルの紹介は ありません。 2
3.
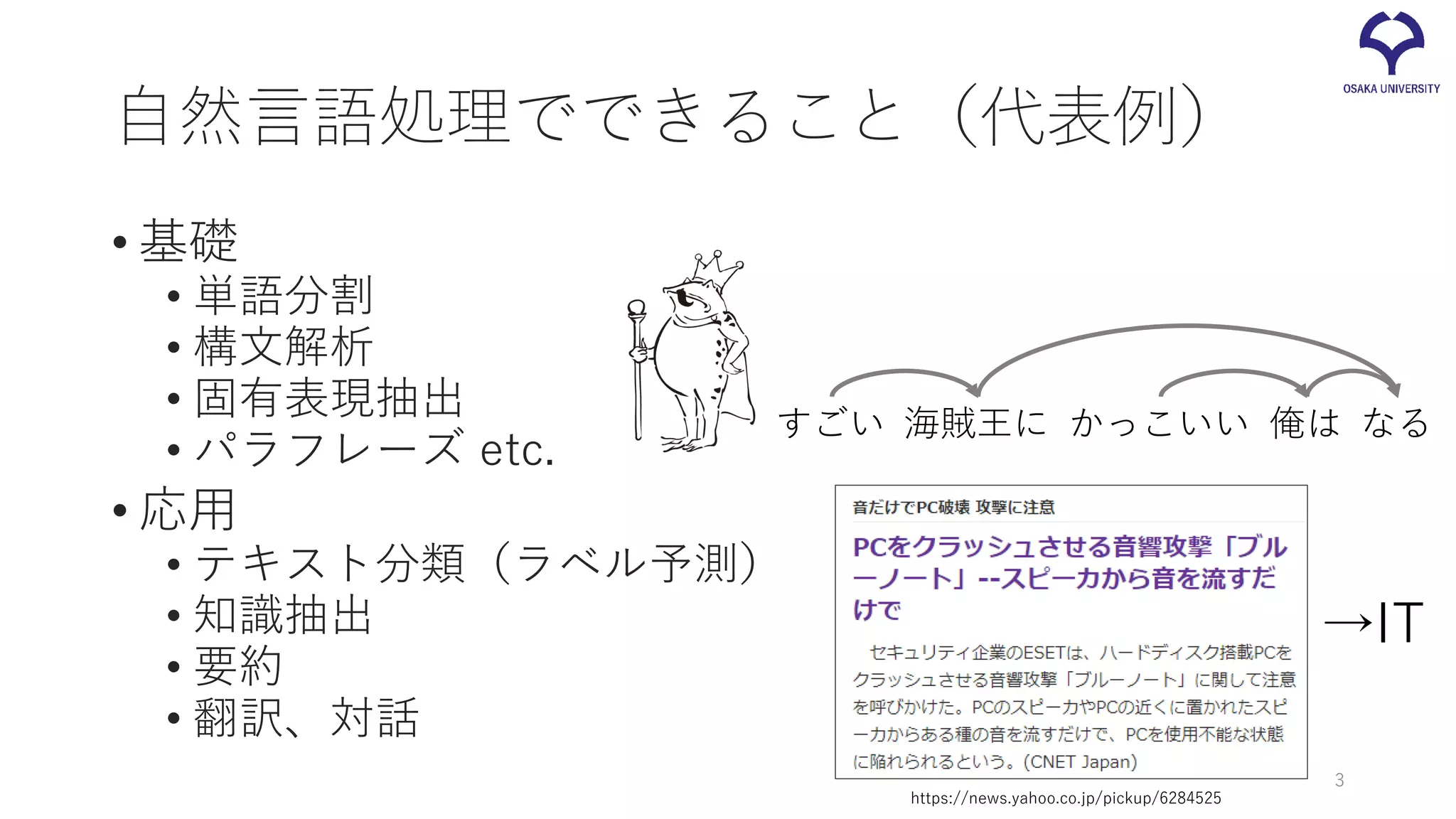
自然言語処理でできること(代表例) • 基礎 • 単語分割 •
構文解析 • 固有表現抽出 • パラフレーズ etc. • 応用 • テキスト分類(ラベル予測) • 知識抽出 • 要約 • 翻訳、対話 3 俺は海賊王に なるすごい かっこいい https://news.yahoo.co.jp/pickup/6284525 →IT
4.
Agenda 1. 深層学習によるNLP 2. 単語のベクトル化 3.
文のベクトル化 4. 系列変換モデル 5. 学習データが、ない 6. 実はとても重要な前処理 7. もっと詳しく知りたい方に 4
5.
Agenda 1. 深層学習によるNLP 2. 単語のベクトル化 3.
文のベクトル化 4. 系列変換モデル 5. 学習データが、ない 6. 実はとても重要な前処理 7. もっと詳しく知りたい方に 5
6.
ざっくり深層学習 入力:入力データを表現する ベクトル 𝑊𝑊1, 𝒃𝒃1 𝑊𝑊𝑘𝑘, 𝒃𝒃𝑘𝑘 … 出力:各出力候補
𝑦𝑦 のスコアが並んだ ベクトル 𝑦𝑦0 𝑦𝑦𝑁𝑁… 6
7.
ざっくり深層学習 入力:入力データを表現する ベクトル 𝑊𝑊1, 𝒃𝒃1 𝑊𝑊𝑘𝑘, 𝒃𝒃𝑘𝑘 … 出力:各出力候補
𝑦𝑦 のスコアが並んだ ベクトル 𝑦𝑦0 𝑦𝑦𝑁𝑁… 7
8.
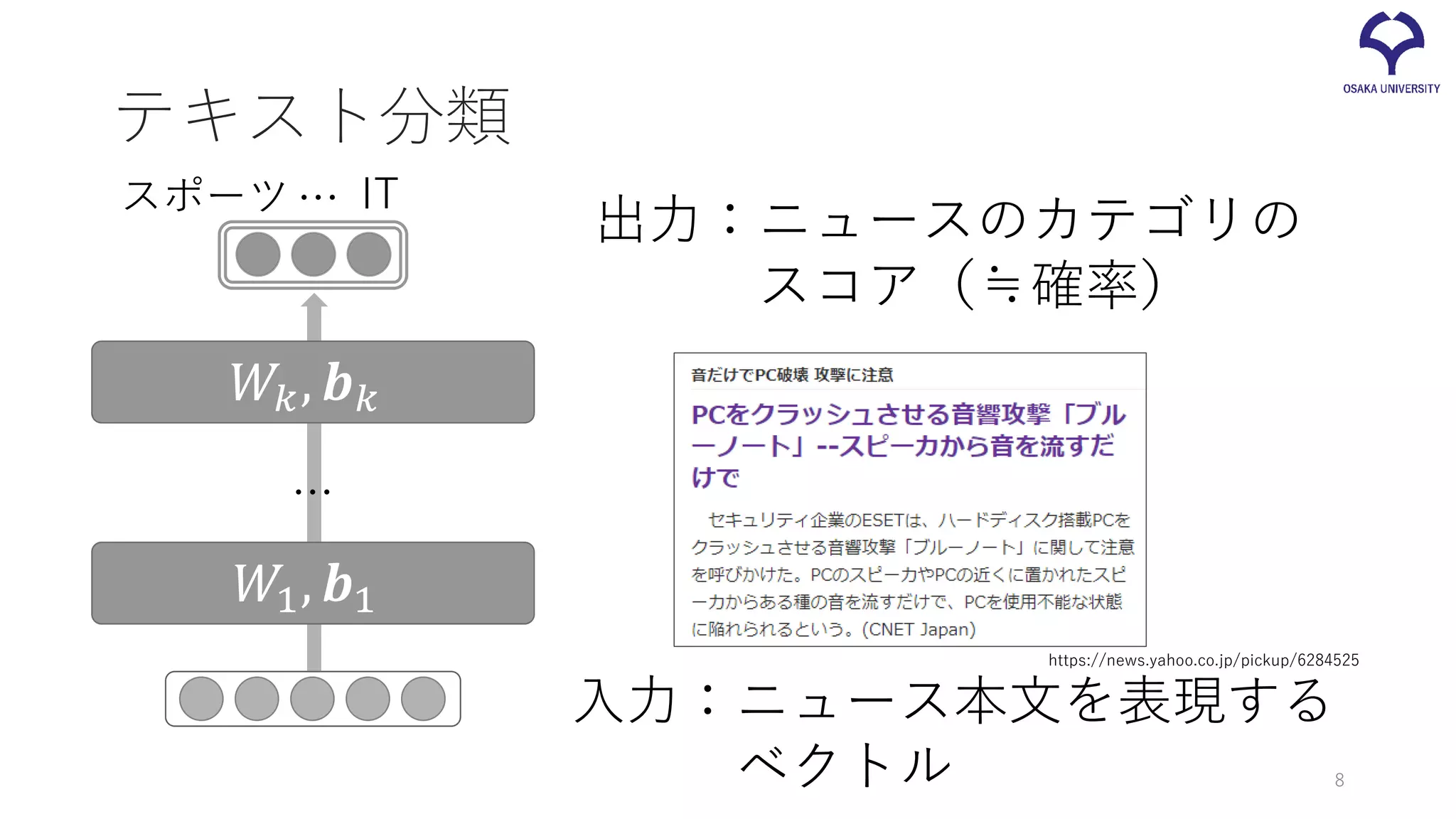
テキスト分類 入力:ニュース本文を表現する ベクトル 出力:ニュースのカテゴリの スコア(≒確率) スポーツ IT… https://news.yahoo.co.jp/pickup/6284525 𝑊𝑊1, 𝒃𝒃1 𝑊𝑊𝑘𝑘,
𝒃𝒃𝑘𝑘 … 8
9.
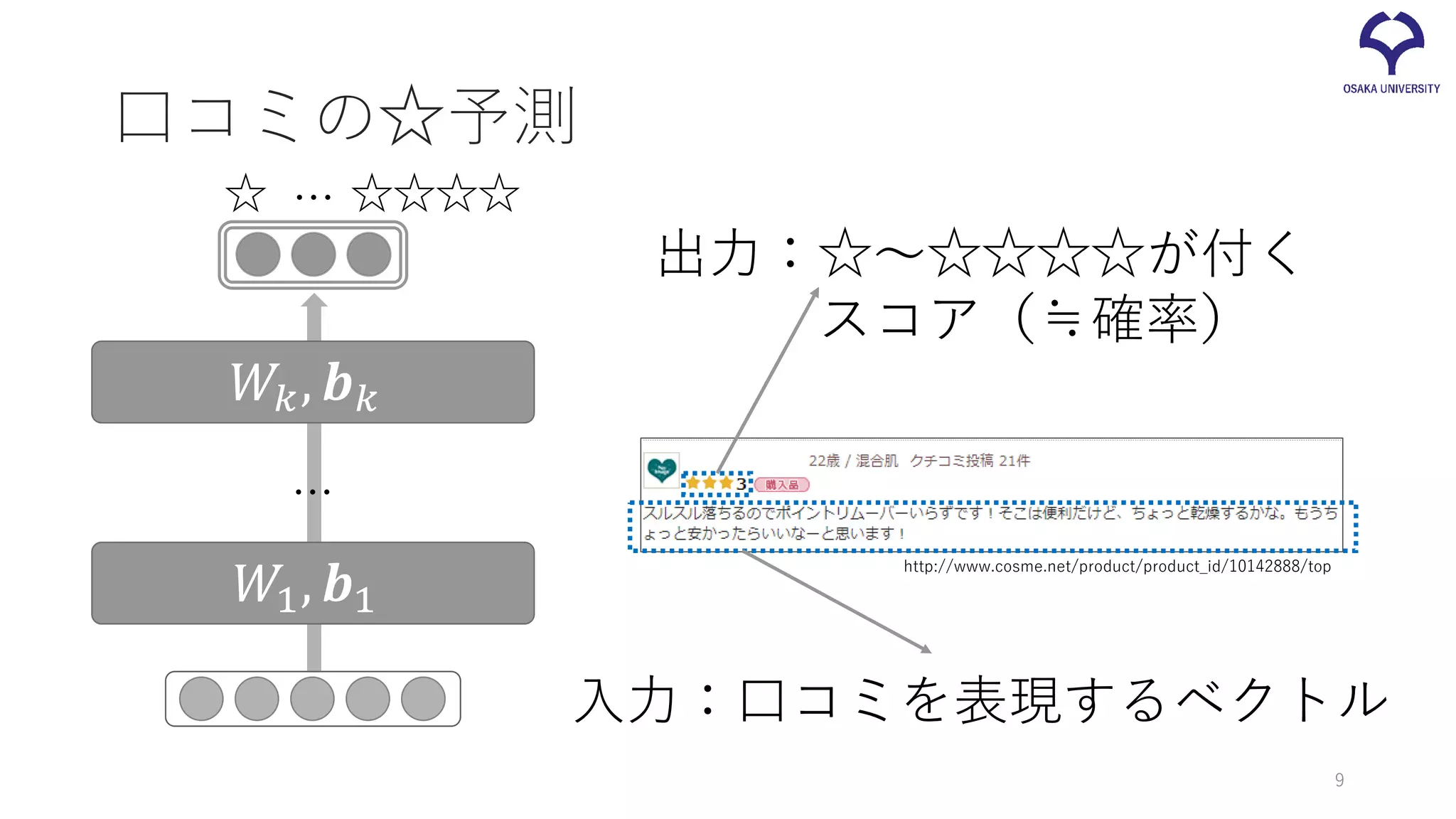
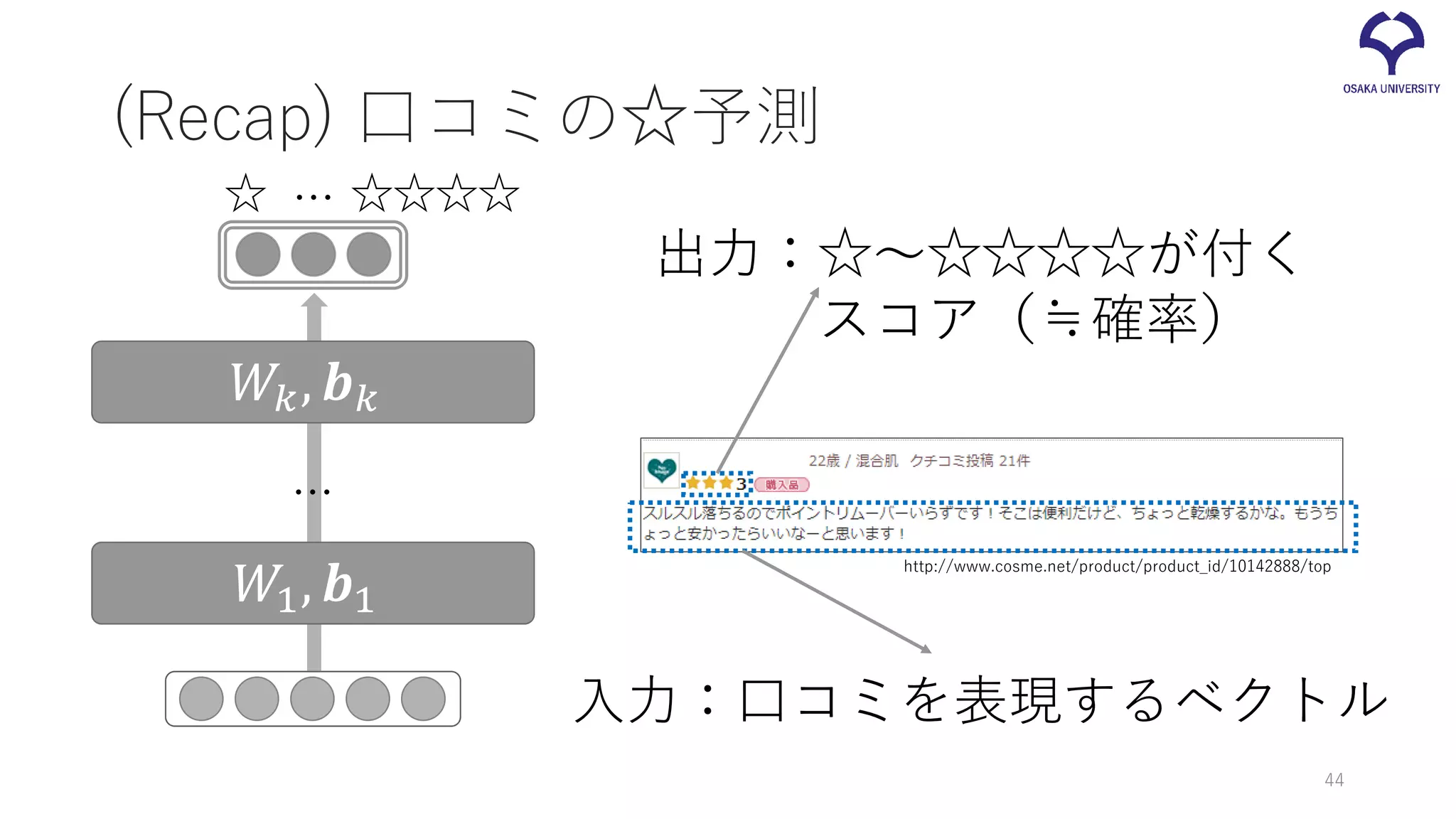
口コミの☆予測 入力:口コミを表現するベクトル 出力:☆~☆☆☆☆が付く スコア(≒確率) ☆ ☆☆☆☆… http://www.cosme.net/product/product_id/10142888/top 𝑊𝑊1, 𝒃𝒃1 𝑊𝑊𝑘𝑘,
𝒃𝒃𝑘𝑘 … 9
10.
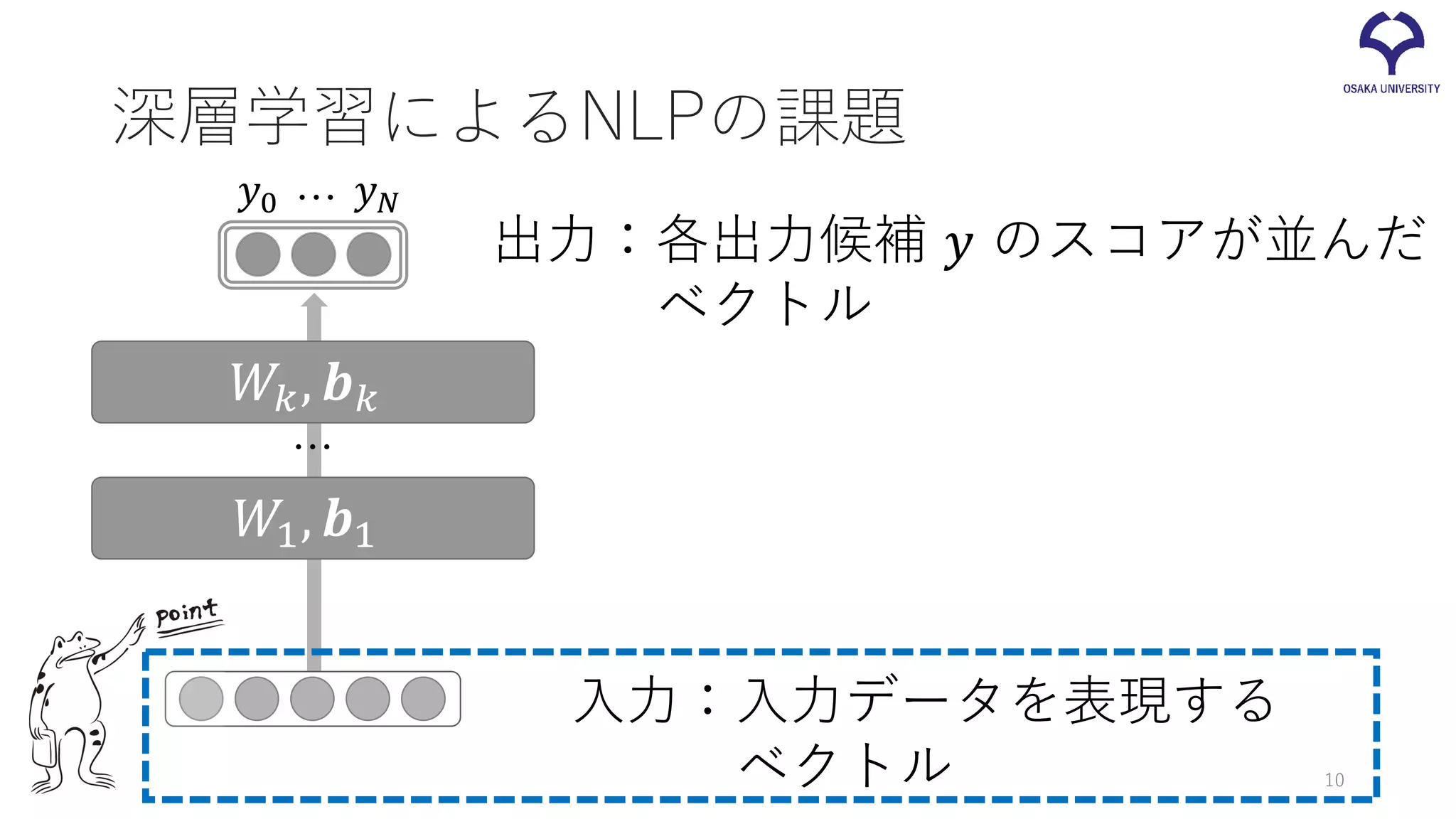
深層学習によるNLPの課題 入力:入力データを表現する ベクトル 𝑊𝑊1, 𝒃𝒃1 𝑊𝑊𝑘𝑘, 𝒃𝒃𝑘𝑘 … 出力:各出力候補
𝑦𝑦 のスコアが並んだ ベクトル 𝑦𝑦0 𝑦𝑦𝑁𝑁… 10
11.
Agenda 1. 深層学習によるNLP 2. 単語のベクトル化 3.
文のベクトル化 4. 系列変換モデル 5. 学習データが、ない 6. 実はとても重要な前処理 7. もっと詳しく知りたい方に 11
12.
言語は「記号」 •言語(単語)=人間がある事象や概念を表すため に創り出した「記号」 Cf. 画像のRGB値=物理量 •文は可変長かつ構造をもつ •物理量で表現したい 12
13.
単語のベクトル化 •Word embedding, word
vector, 分散表現, 単語埋め込み, 単語ベクトル •単語を200~500次元程度のベクトルで表現 •分布仮説に基づき、単語ベクトルを学習 13
14.
分布仮説(Distributional hypothesis) 「単語の意味はその単語が出現したときに周辺に 現れる単語(共起する単語)によって決まる」 お誕生日に食べたくなっちゃうケーキですよ! 誕生日やお祝いに美味しいスイーツをプレゼントしたい。 がんの検査の内容は症状によって異なります。 病気の治療に症状にあった薬の使用が必要です。 14
15.
CBoWとskip-gram •深層学習による分布仮説の自然なモデル化 •word2vecに実装されている2つのモデル • CBoW (Continuous
Bag-of-Words ) • skip-gram •“king-man+woman=queen” の例でおなじみ 15
16.
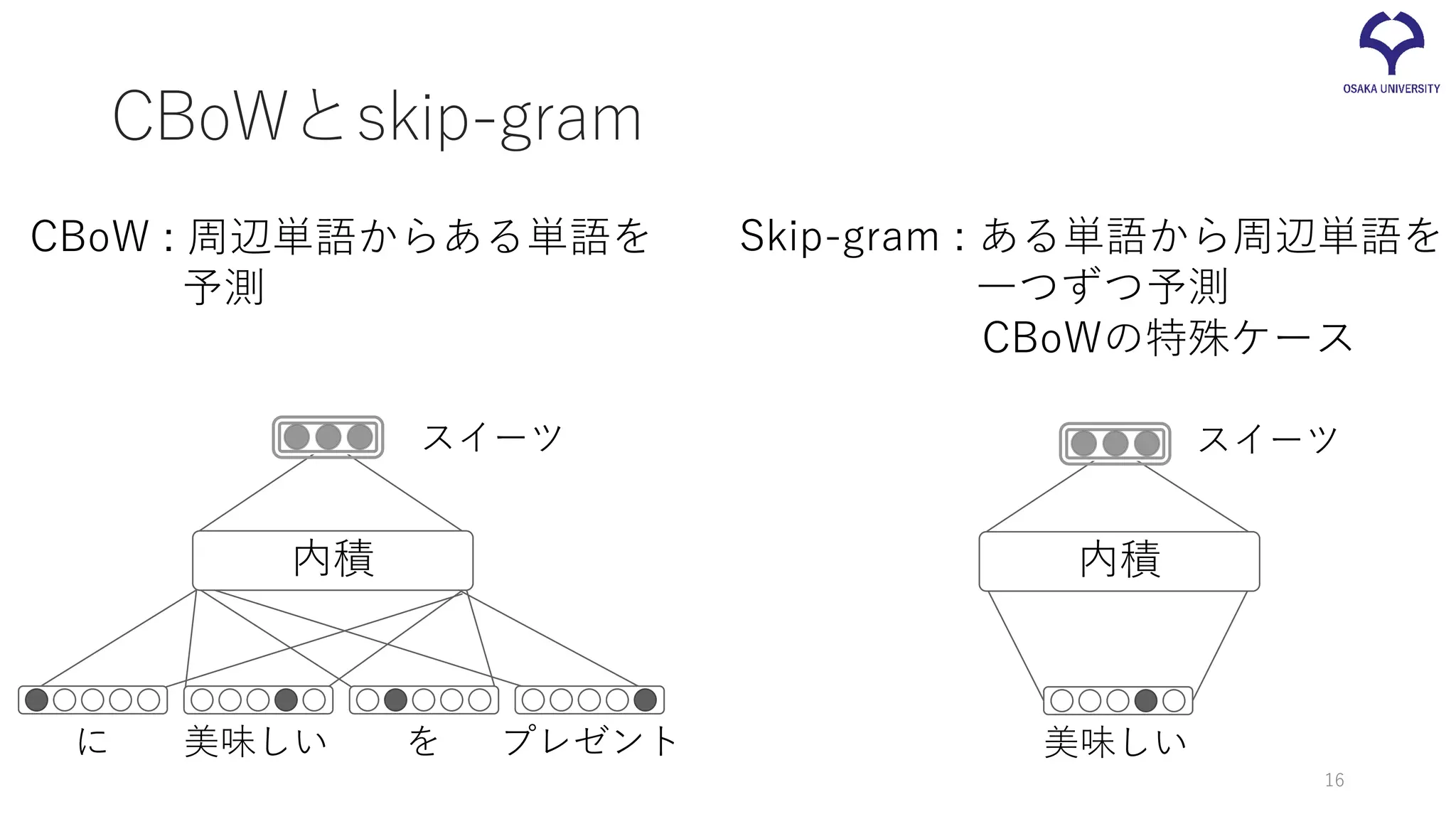
CBoWとskip-gram 内積 スイーツ 美味しい を プレゼントに CBoW
: 周辺単語からある単語を 予測 Skip-gram : ある単語から周辺単語を 一つずつ予測 CBoWの特殊ケース スイーツ 美味しい 内積 16
17.
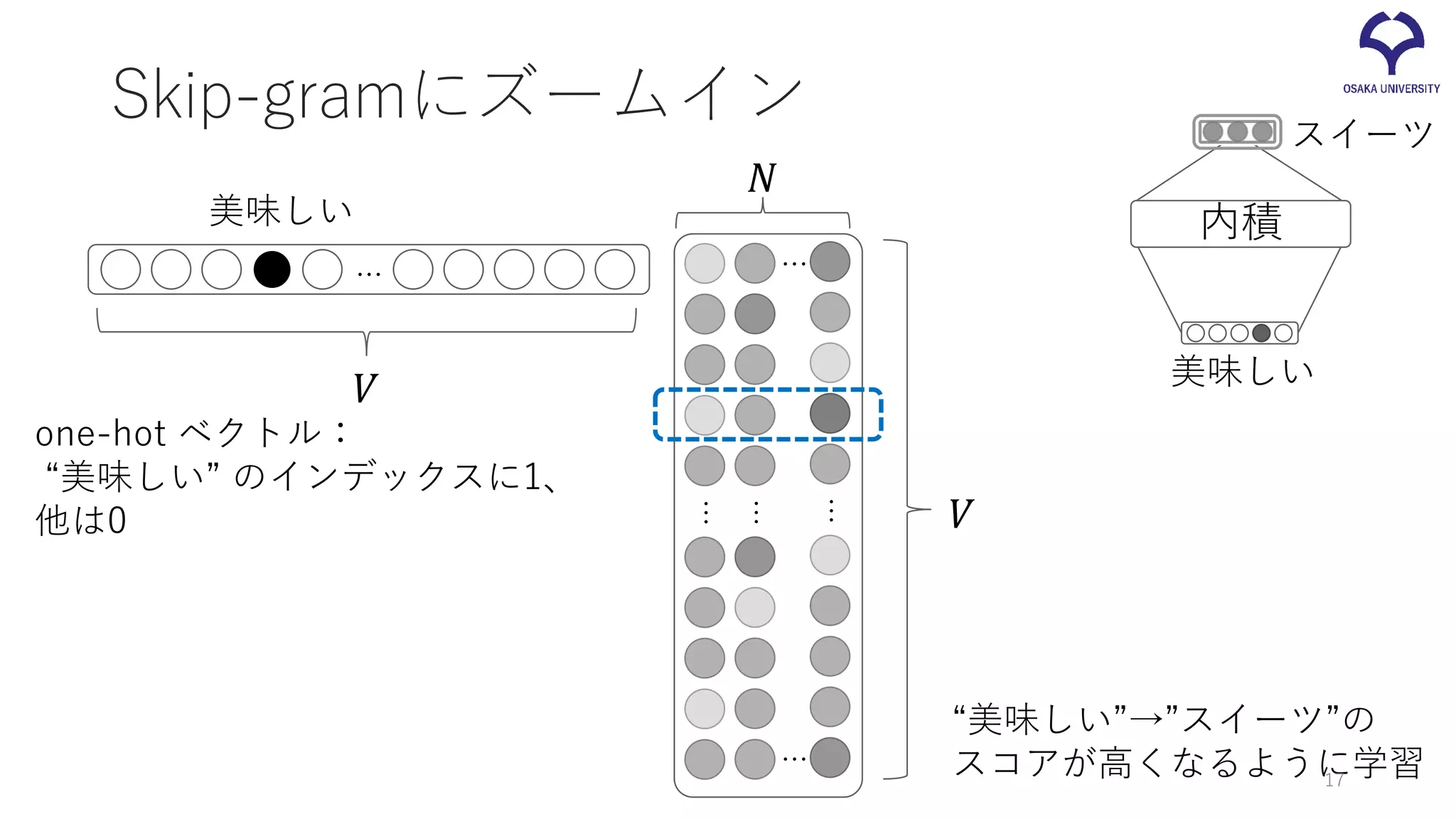
Skip-gramにズームイン 美味しい … 𝑁𝑁 𝑉𝑉 … … … … … 𝑉𝑉 one-hot ベクトル: “美味しい” のインデックスに1、 他は0 “美味しい”→”スイーツ”の スコアが高くなるように学習 スイーツ 美味しい 内積 17
18.
https://sites.google.com/site/iwanamidatascience/vol2/ word-embedding 18
19.
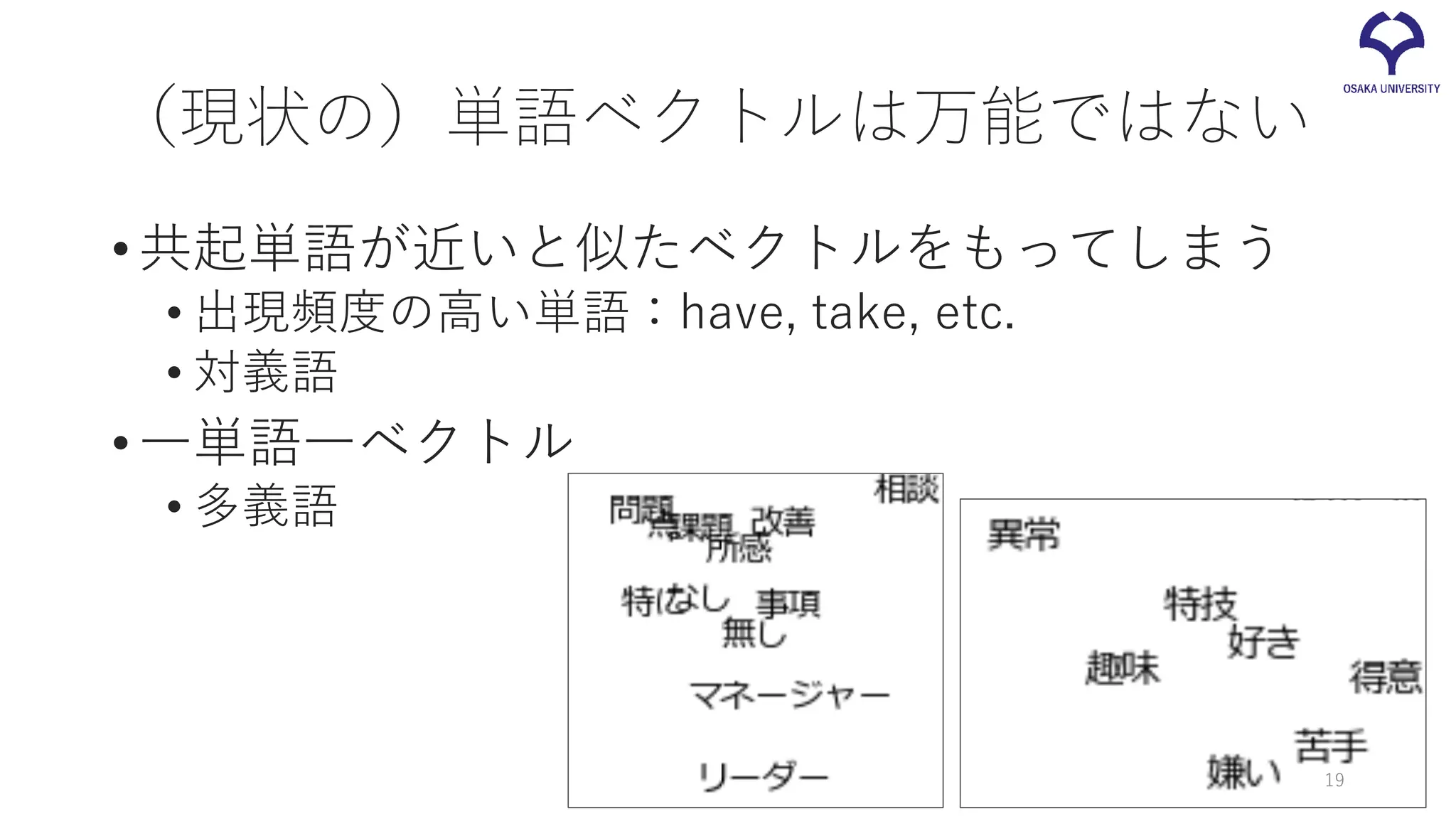
(現状の)単語ベクトルは万能ではない •共起単語が近いと似たベクトルをもってしまう • 出現頻度の高い単語:have, take,
etc. • 対義語 •一単語一ベクトル • 多義語 19
20.
定番の学習済み単語ベクトル •word2vec https://code.google.com/archive/p/word2vec/ gensim https://radimrehurek.com/gensim/ •GloVe (Stanford University) https://nlp.stanford.edu/projects/glove/ 20
21.
「単語」が最適? •伝統的に「単語」が最小単位。解釈も容易。 •単語分割が必要。でも「単語」の単位って? • 最適な単語の単位はアプリケーション依存 • Web検索:「大阪大学」→「大阪」「大学」として検索 した方が多くのドキュメントにマッチしやすい •
翻訳:「大阪大学」は「Osaka University」と訳したい •未知語(Unknown word)の問題 21
22.
サブワードの台頭 • 「単語」に捕らわれないユニット • 単語より小さな単位を含むため、未知語の低減に効果 •
機械翻訳ではスタンダードな手法 お誕生日 → お 誕生 日 食べたくなっちゃう → 食べ た くなっちゃう employer → employ er 22
23.
サブワードの抽出手法 BPE (Byte Pair
Encoding) • データ圧縮のため提案された手法 • 頻出する文字列を新たな記号(サブワード)とする 手法 • データからサブワードを抽出、分割 • アプリケーションにおいて最適な分割かどうかは 不明 • 分割における曖昧性が存在 23 employer →employ er; em p loyer; e m p l o y e r
24.
サブワード抽出のツール SentencePiece https://github.com/google/sentencepiece 24
25.
Agenda 1. 深層学習によるNLP 2. 単語のベクトル化 3.
文のベクトル化 4. 系列変換モデル 5. 学習データが、ない 6. 実はとても重要な前処理 7. もっと詳しく知りたい方に 25
26.
単語から文のベクトルへ 1. 単語ベクトルの平均 2. 系列を考慮:Recurrent
neural net 3. 文法構造を考慮:Recursive neural net アクティブな研究分野 26
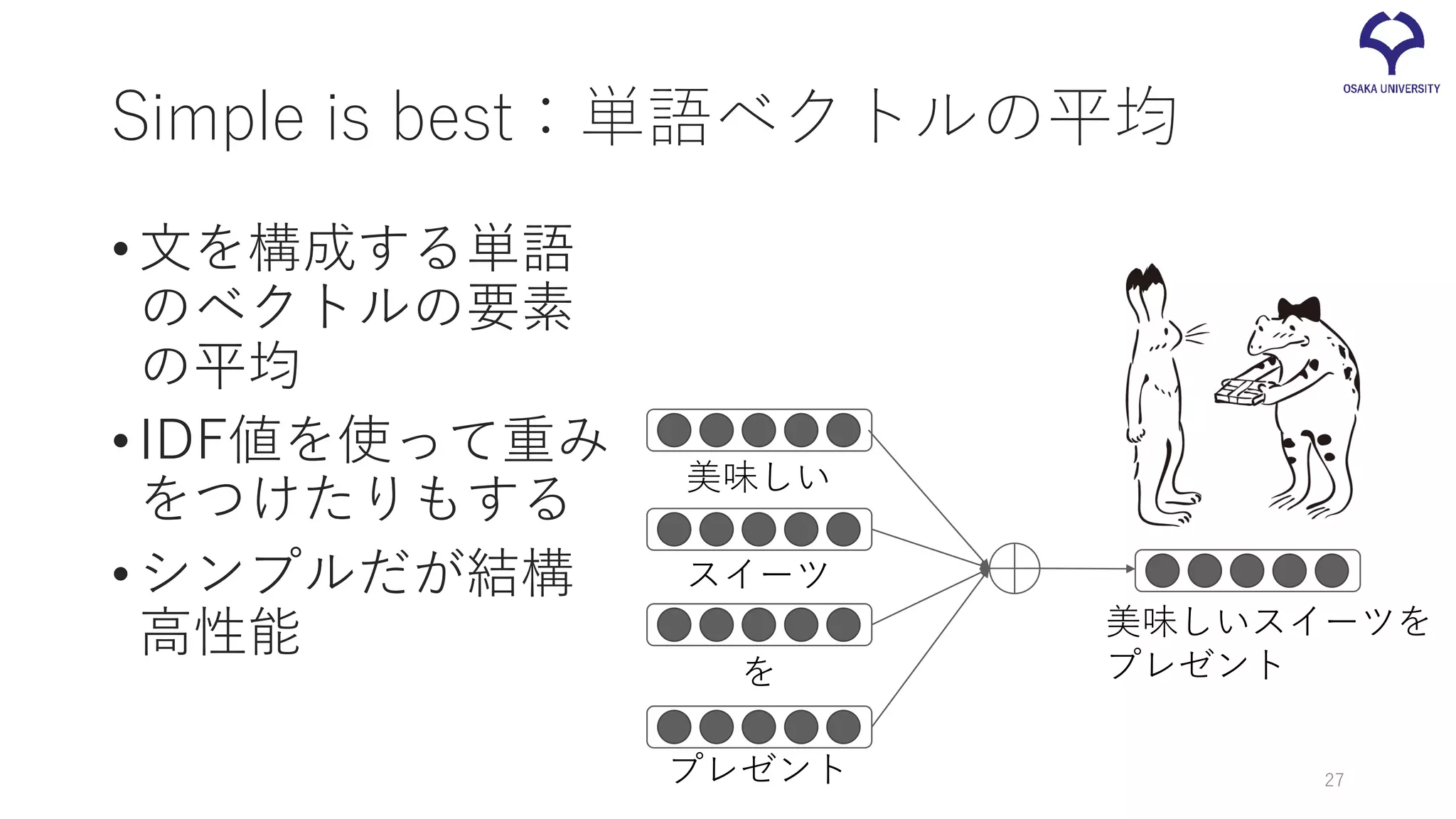
27.
Simple is best:単語ベクトルの平均 •文を構成する単語 のベクトルの要素 の平均 •IDF値を使って重み をつけたりもする •シンプルだが結構 高性能 美味しい スイーツ を プレゼント 美味しいスイーツを プレゼント 27
28.
IDF (Inverse Document
Frequency) あるドキュメントに集中して現れる単語は、特徴 的な単語 𝐼𝐼 𝐼𝐼 𝐼𝐼 𝑡𝑡 = log 全ドキュメント数 単語𝑡𝑡が現れるドキュメント数 IDF 大:単語𝑡𝑡は様々なドキュメントに現れる (冠詞、前置詞) 28
29.
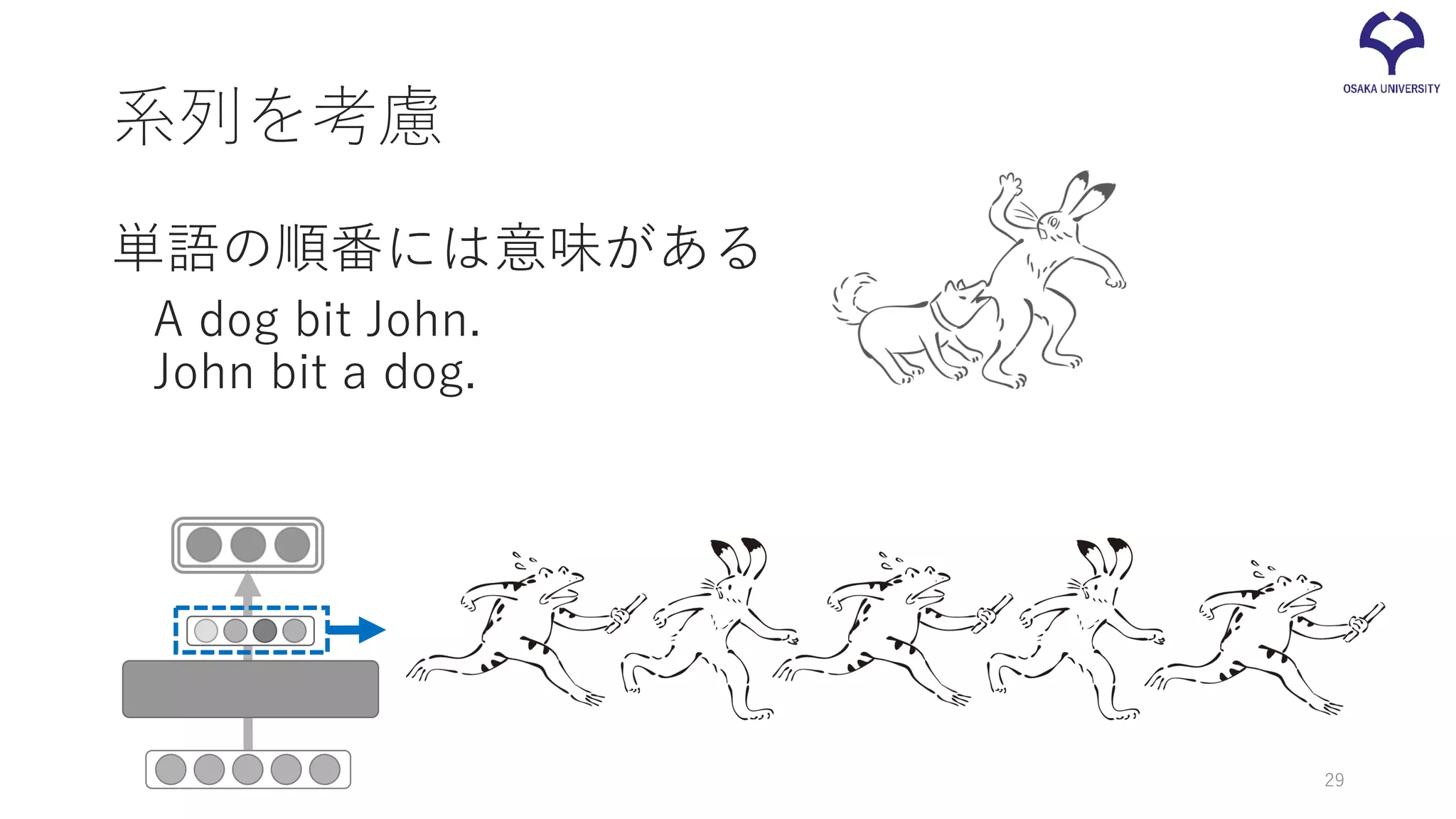
系列を考慮 単語の順番には意味がある A dog bit
John. John bit a dog. 29
30.
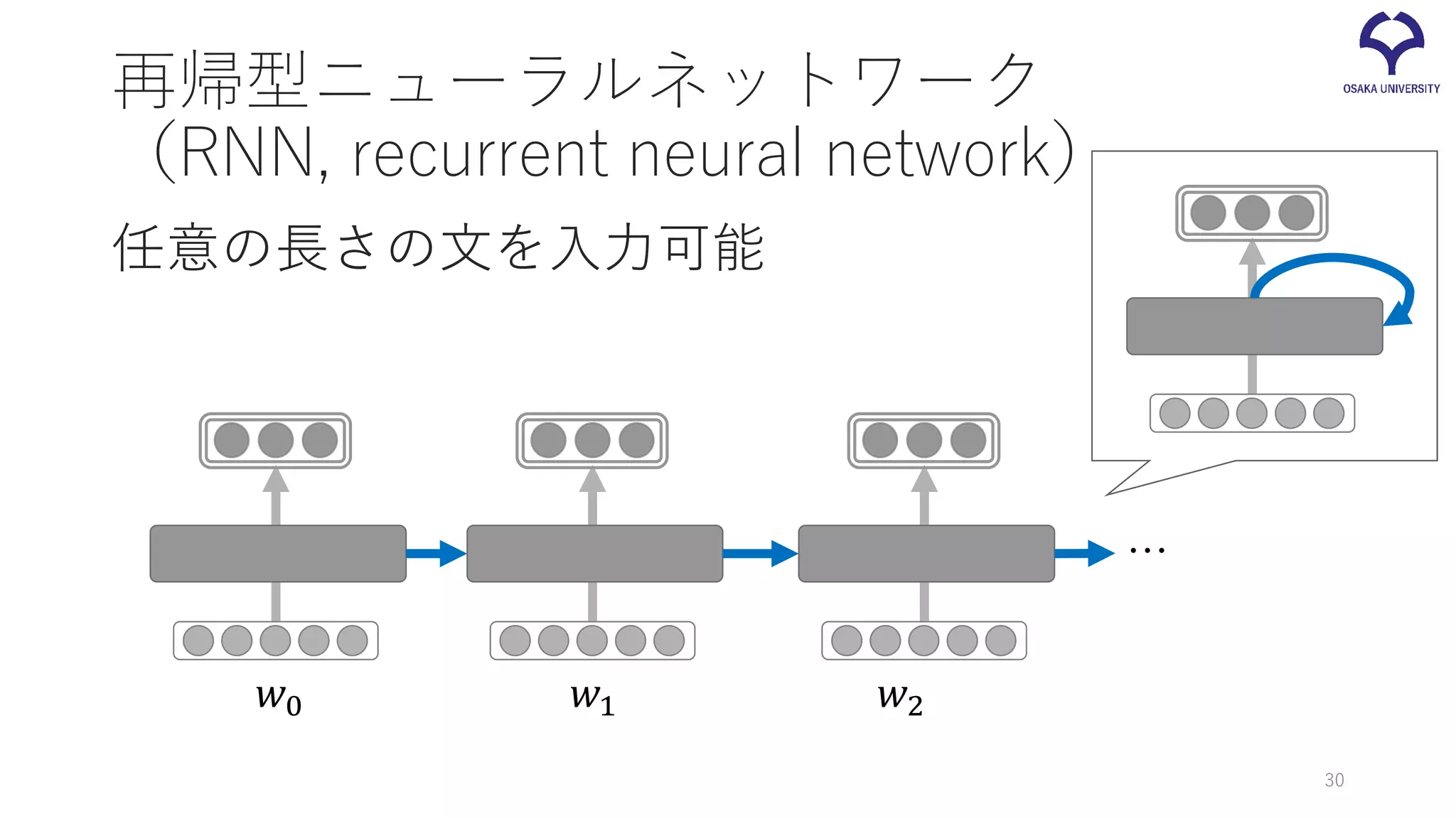
再帰型ニューラルネットワーク (RNN, recurrent neural
network) 任意の長さの文を入力可能 𝑤𝑤0 𝑤𝑤1 𝑤𝑤2 … 30
31.
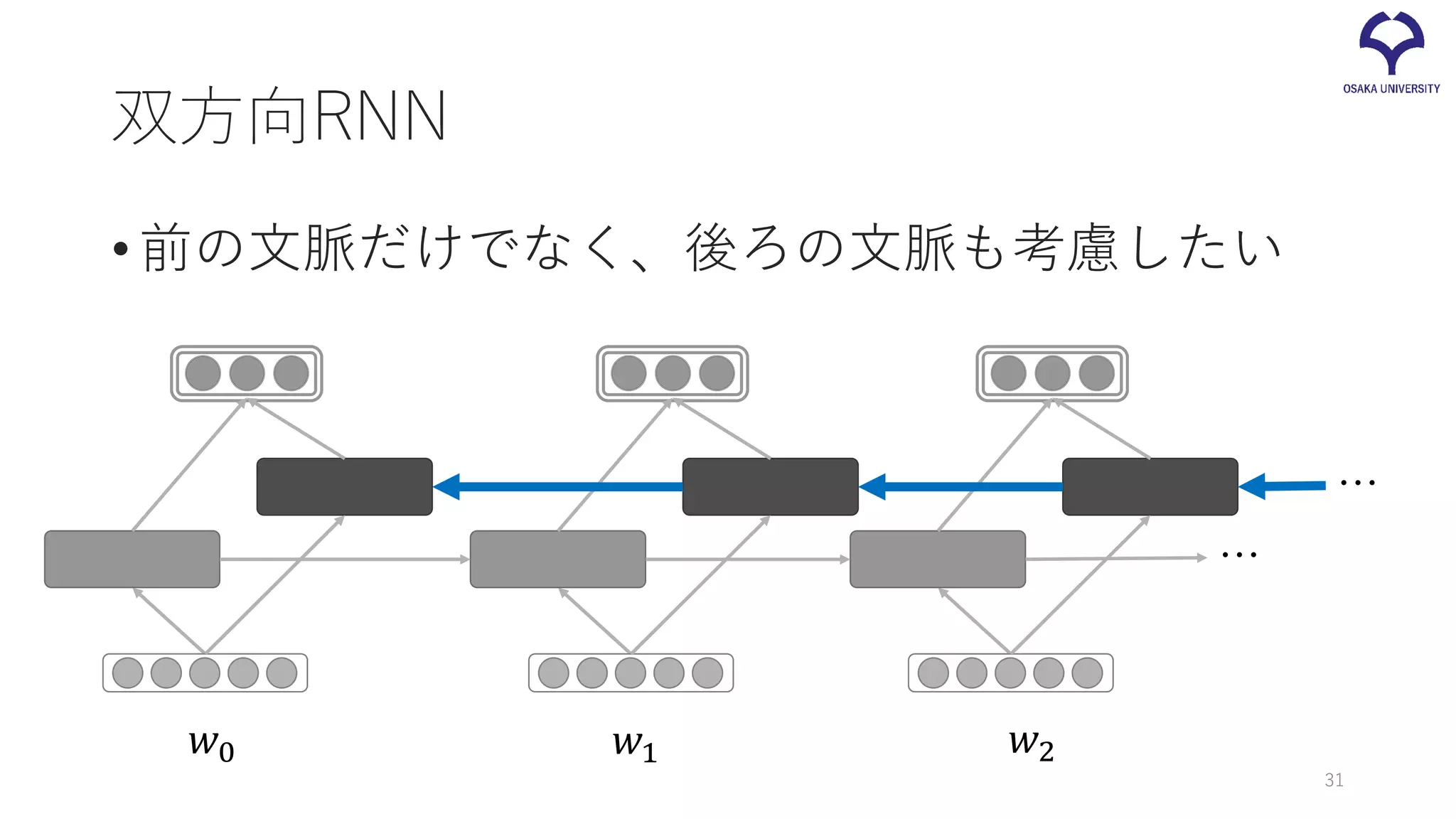
双方向RNN •前の文脈だけでなく、後ろの文脈も考慮したい 𝑤𝑤0 𝑤𝑤1 𝑤𝑤2 … … 31
32.
記憶力の改善 遠く離れた時刻(単語)を記憶する能力の付加 •LSTM (Long-Short-Term-Memory) • 長期記憶、短期記憶のバランス •GRU
(Gated Recurrent Unit) • LSTMよりも少ない計算量、使用空間量 32
33.
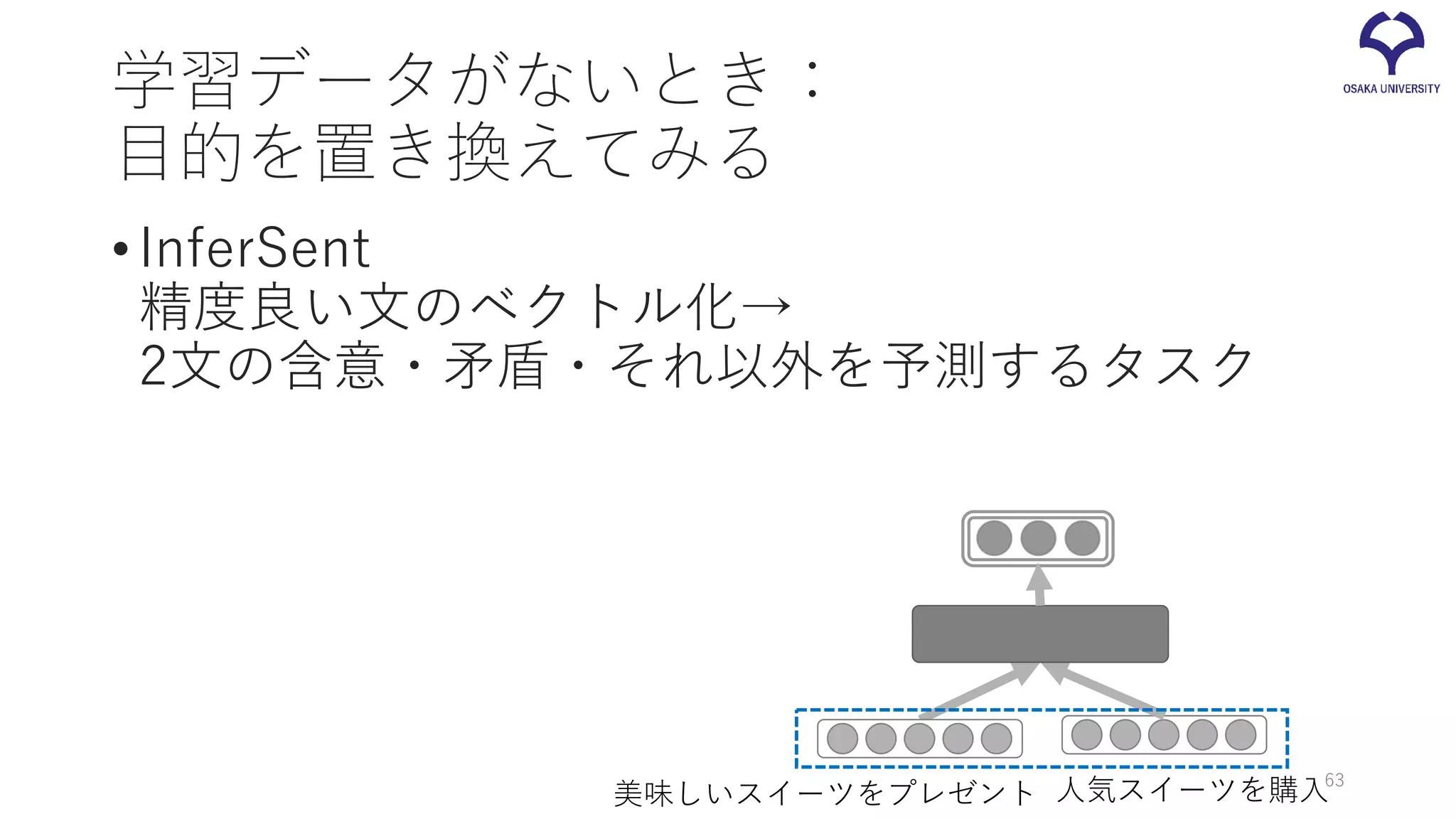
InferSent •SNLI (Stanford Natural
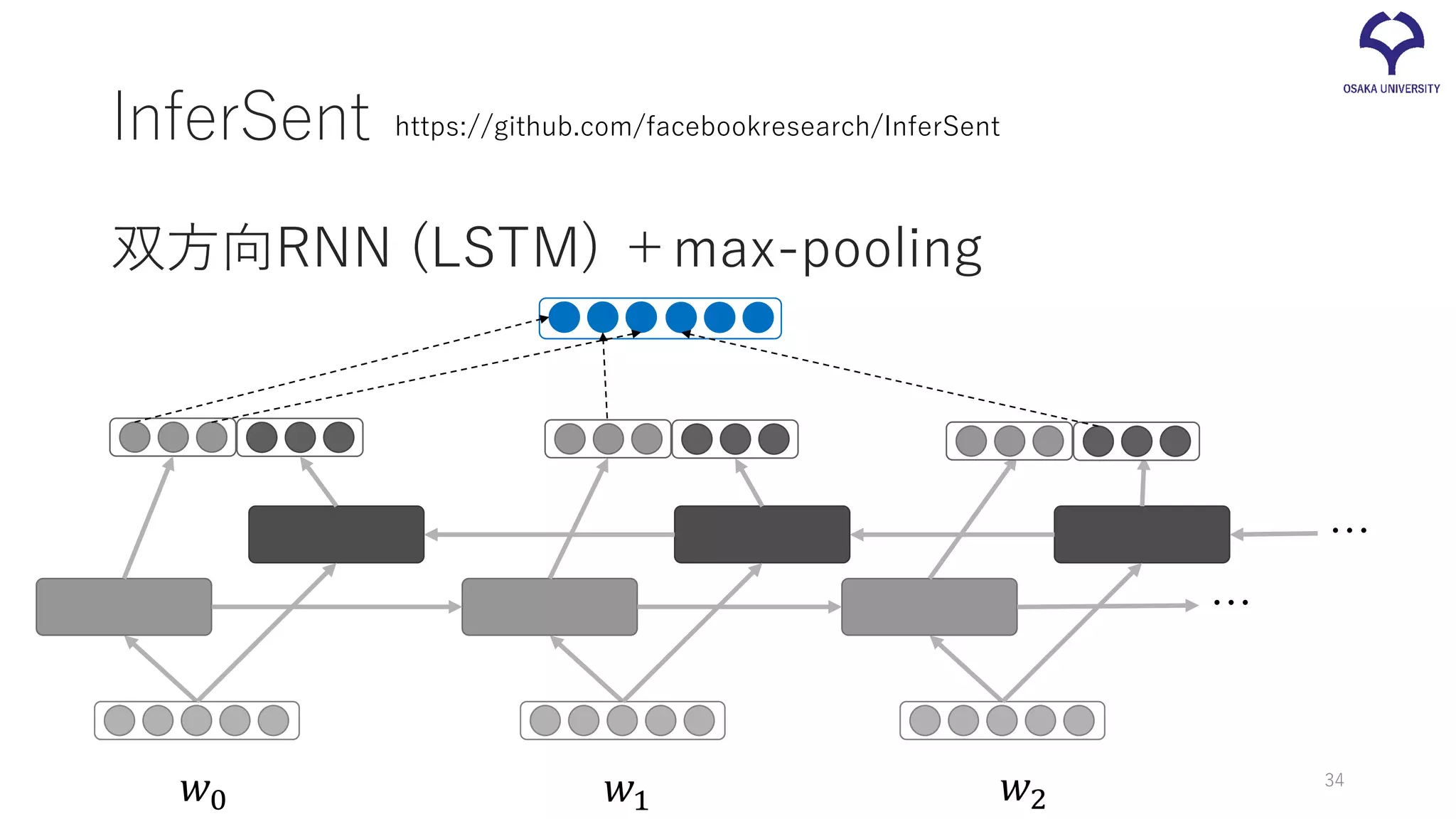
Language Inference) で学習 • 2つの文に含意関係があるか、矛盾しているか、 どちらでもないかを予測 •あらゆるアプリケーションで高い性能を発揮する、 汎用的な文ベクトルを生成 美味しいスイーツをプレゼント 人気スイーツを購入 https://github.com/facebookresearch/InferSent 33
34.
InferSent 双方向RNN (LSTM) +max-pooling https://github.com/facebookresearch/InferSent 𝑤𝑤0
𝑤𝑤1 𝑤𝑤2 … … 34
35.
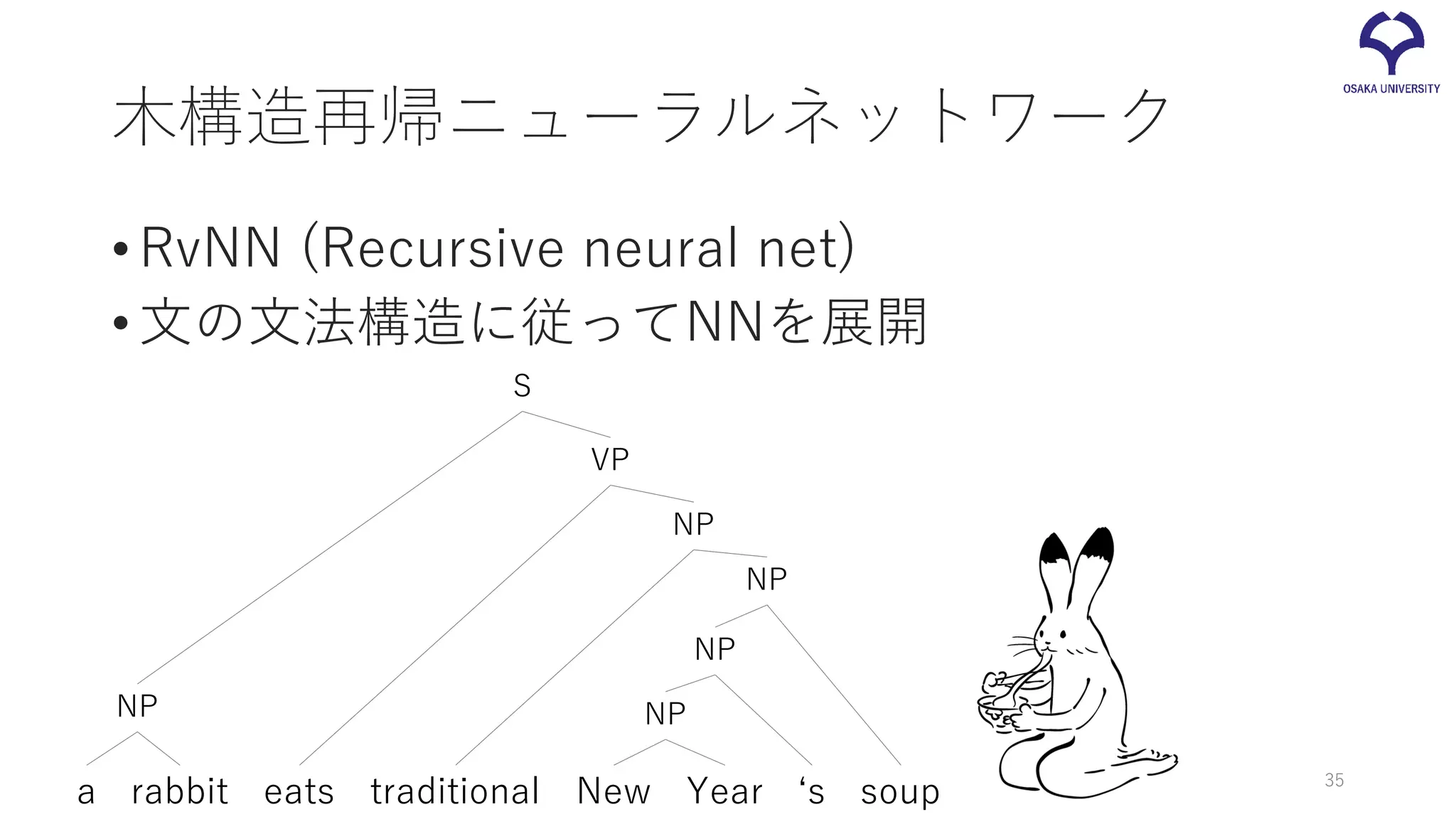
木構造再帰ニューラルネットワーク •RvNN (Recursive neural
net) •文の文法構造に従ってNNを展開 a eats traditionalrabbit New Year ‘s soup NP NP NP NP NP VP S 35
36.
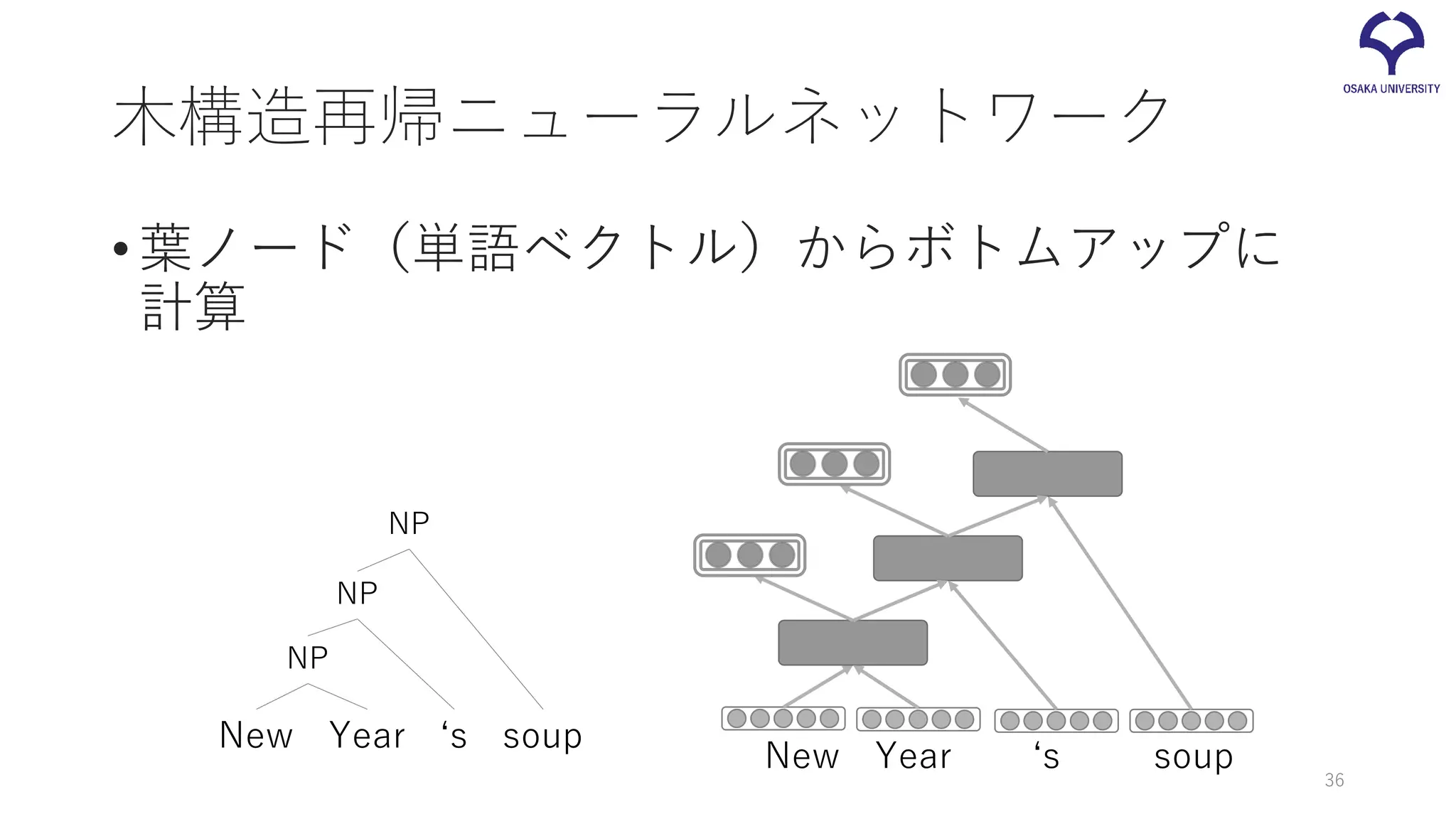
木構造再帰ニューラルネットワーク •葉ノード(単語ベクトル)からボトムアップに 計算 New Year ‘s
soup New Year ‘s soup NP NP NP 36
37.
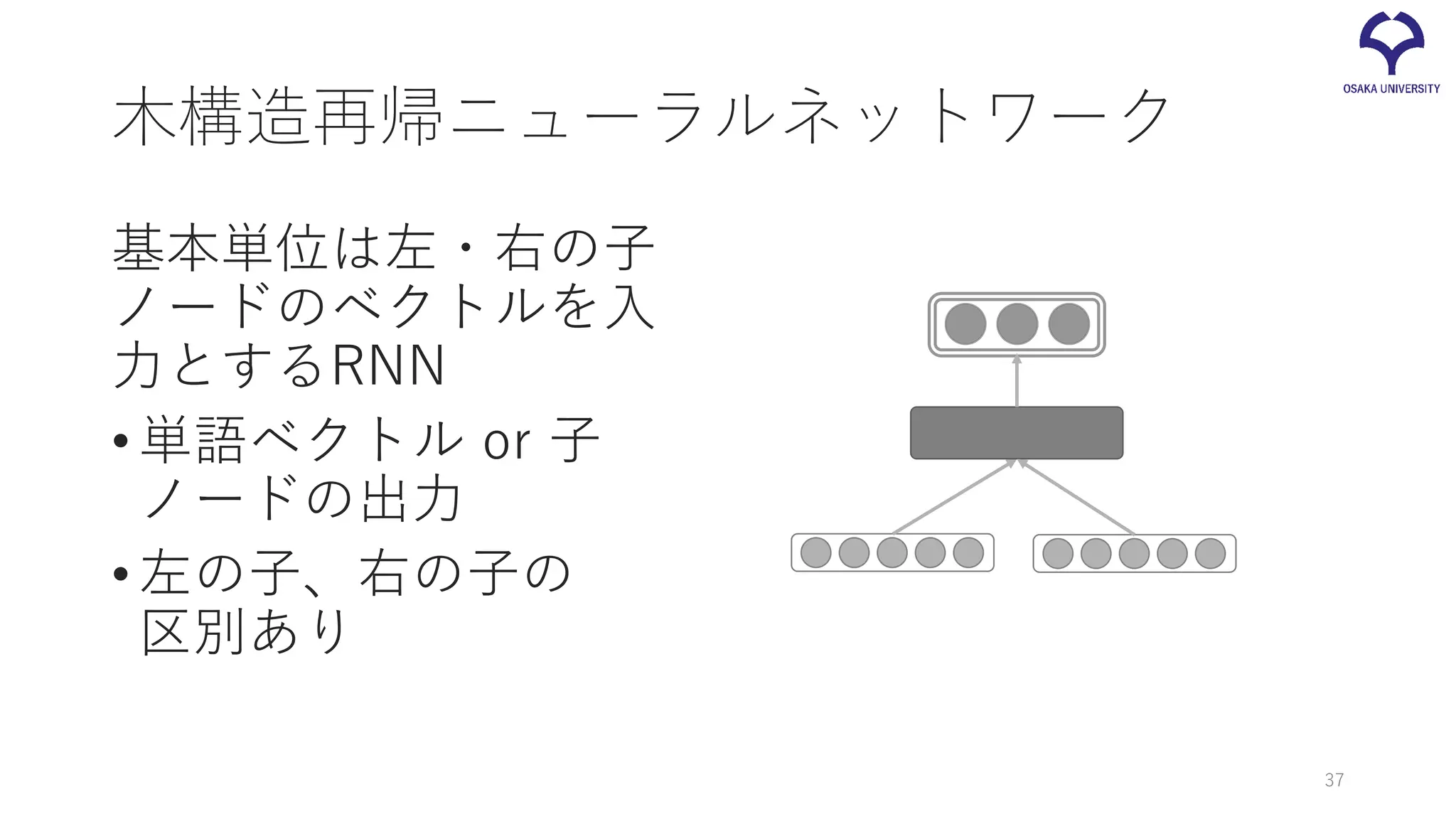
木構造再帰ニューラルネットワーク 基本単位は左・右の子 ノードのベクトルを入 力とするRNN •単語ベクトル or 子 ノードの出力 •左の子、右の子の 区別あり 37
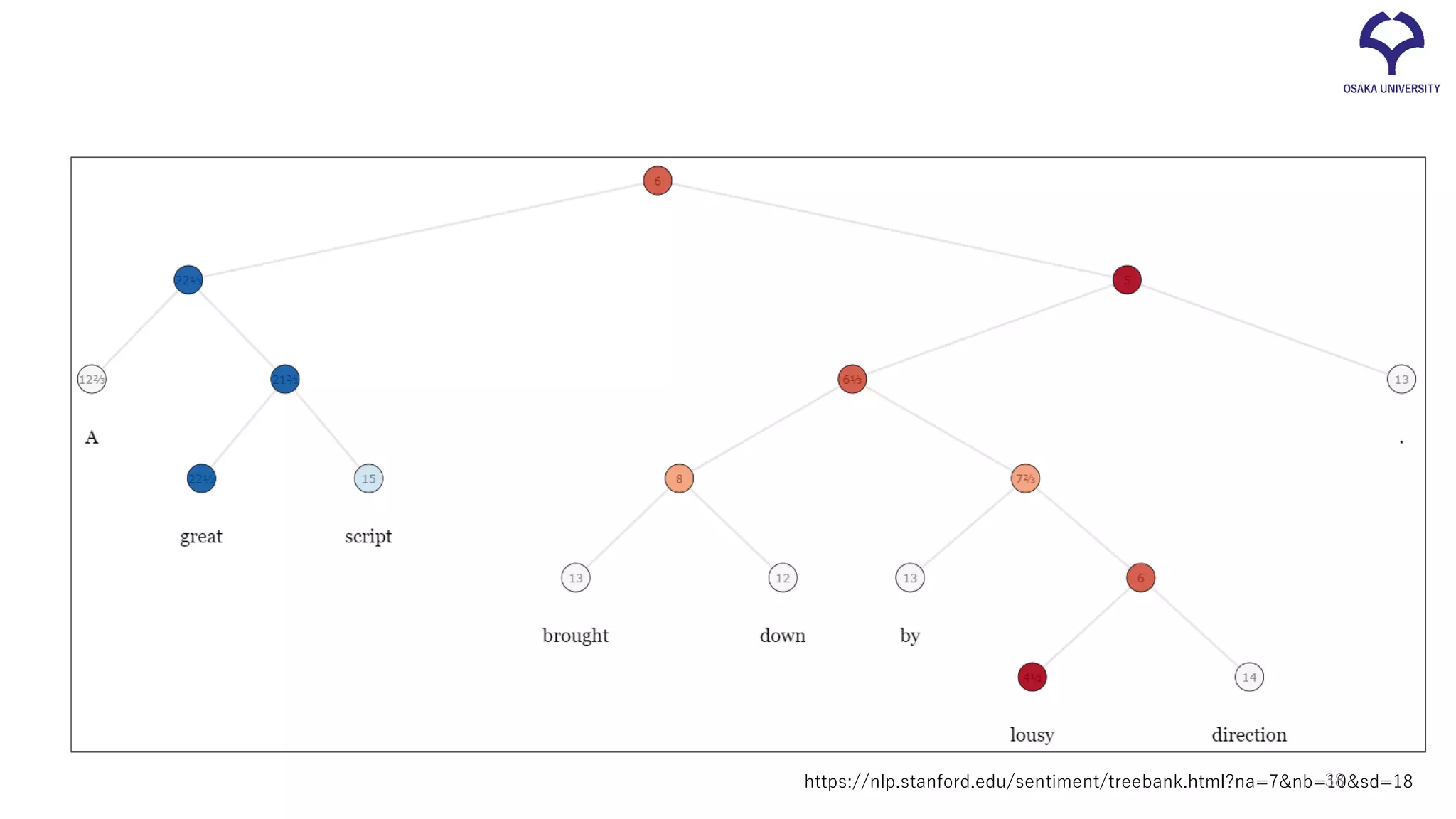
38.
https://nlp.stanford.edu/sentiment/treebank.html?na=7&nb=10&sd=1838
39.
STS Benchmark •2つの文の類似度を0~5の6段階でラベル付け •人間のラベルと、自動的に推定した類似度の相関 により、文ベクトルの性能を評価 •Webサイトで最新の手法の性能がチェックできる http://ixa2.si.ehu.es/stswiki/index.php/STSbenchmark 手法 Pearson
correlation ×100 GloVeの平均 40.6 InferSent 75.8 Tree-LSTM 71.9 39
40.
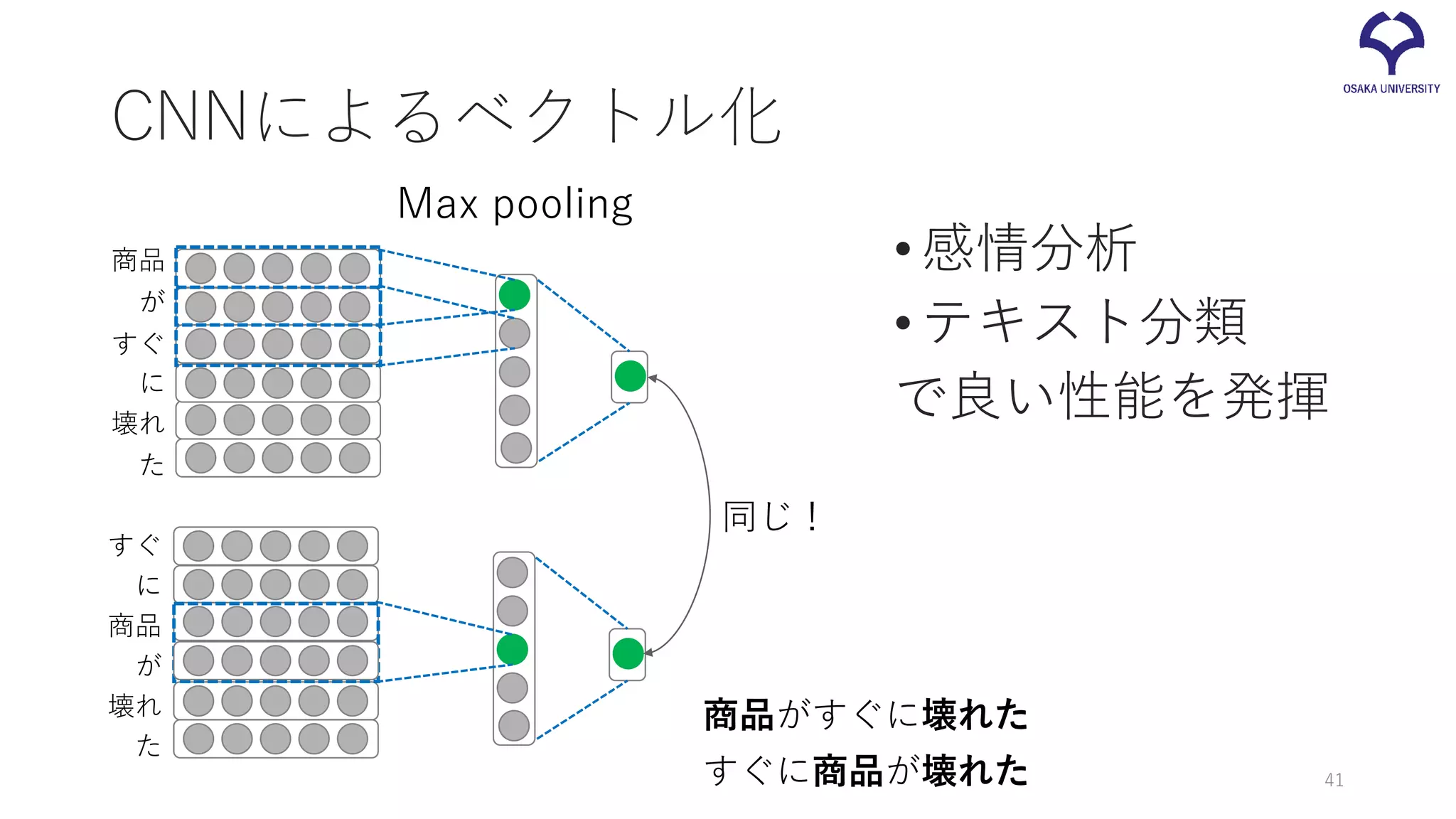
CNNによるベクトル化 •CNN (Convolutional Neural
Network) も文のベクトル化 に利用される • 局所的な変換に対して頑健 • 並列化しやすく、高速 40
41.
CNNによるベクトル化 •感情分析 •テキスト分類 で良い性能を発揮 商品 が すぐ 壊れ た に 商品 が すぐ 壊れ た に 同じ! 商品がすぐに壊れた すぐに商品が壊れた 41 Max pooling
42.
マルチモーダルなデータ処理 画像・音声・センサデータなど、多様なデータと テキストを融合 this is a
dark blue bird with white eyes and a small beak this bird has wings that are brown and black and has a white belly 42
43.
Agenda 1. 深層学習によるNLP 2. 単語のベクトル化 3.
文のベクトル化 4. 系列変換モデル 5. 学習データが、ない 6. 実はとても重要な前処理 7. もっと詳しく知りたい方に 43
44.
(Recap) 口コミの☆予測 入力:口コミを表現するベクトル 出力:☆~☆☆☆☆が付く スコア(≒確率) ☆ ☆☆☆☆… http://www.cosme.net/product/product_id/10142888/top 𝑊𝑊1,
𝒃𝒃1 𝑊𝑊𝑘𝑘, 𝒃𝒃𝑘𝑘 … 44
45.
系列変換モデル •Seq2seq (Sequence-to-Sequence), Encoder-Decoder •Transformer •入力から「系列」を生成する柔軟なモデル •
英語文を入力として、日本語文を生成→翻訳 • 発話を入力として、返事を生成→対話 • 画像を入力として、説明文を生成→キャプション 45
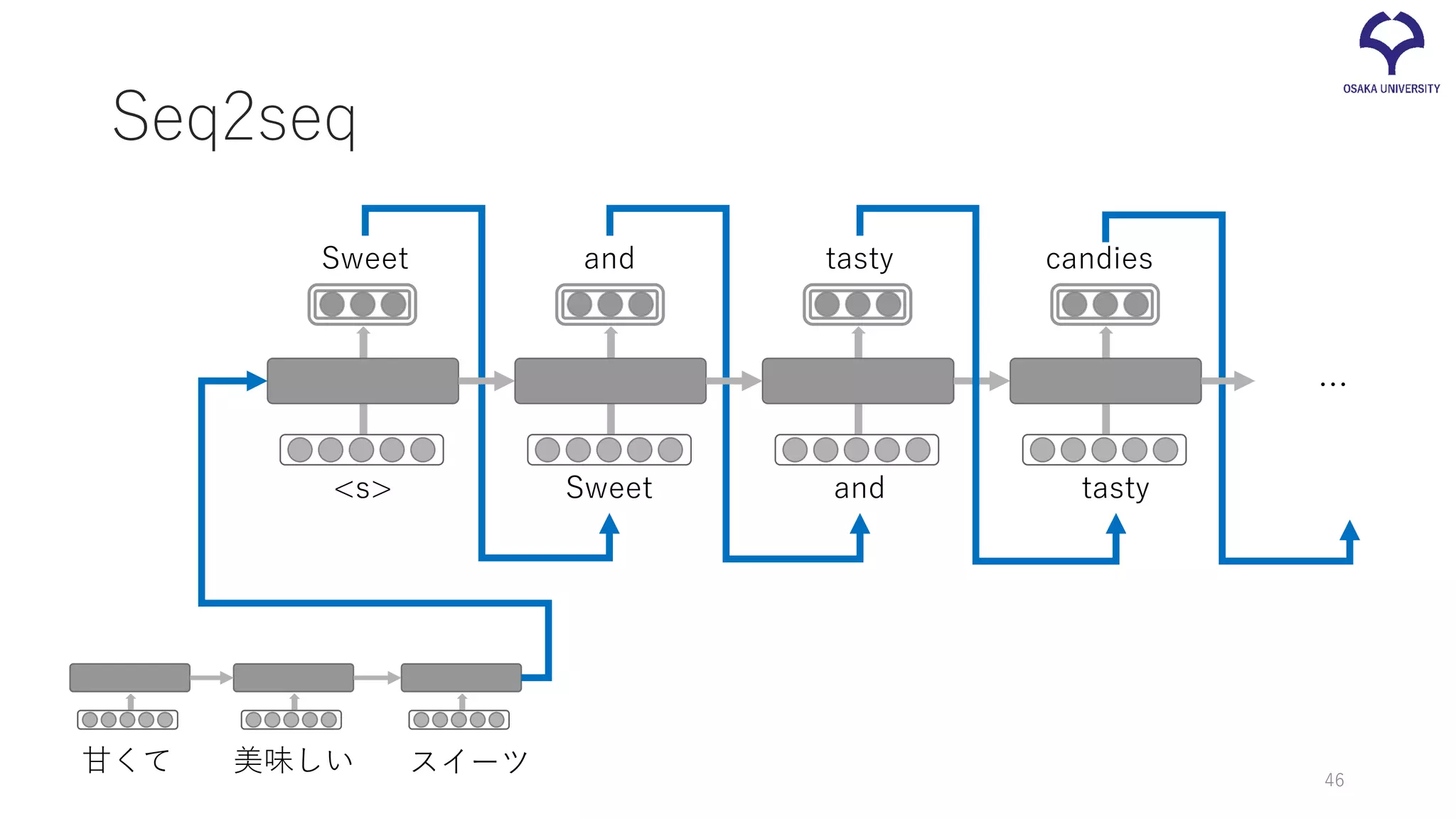
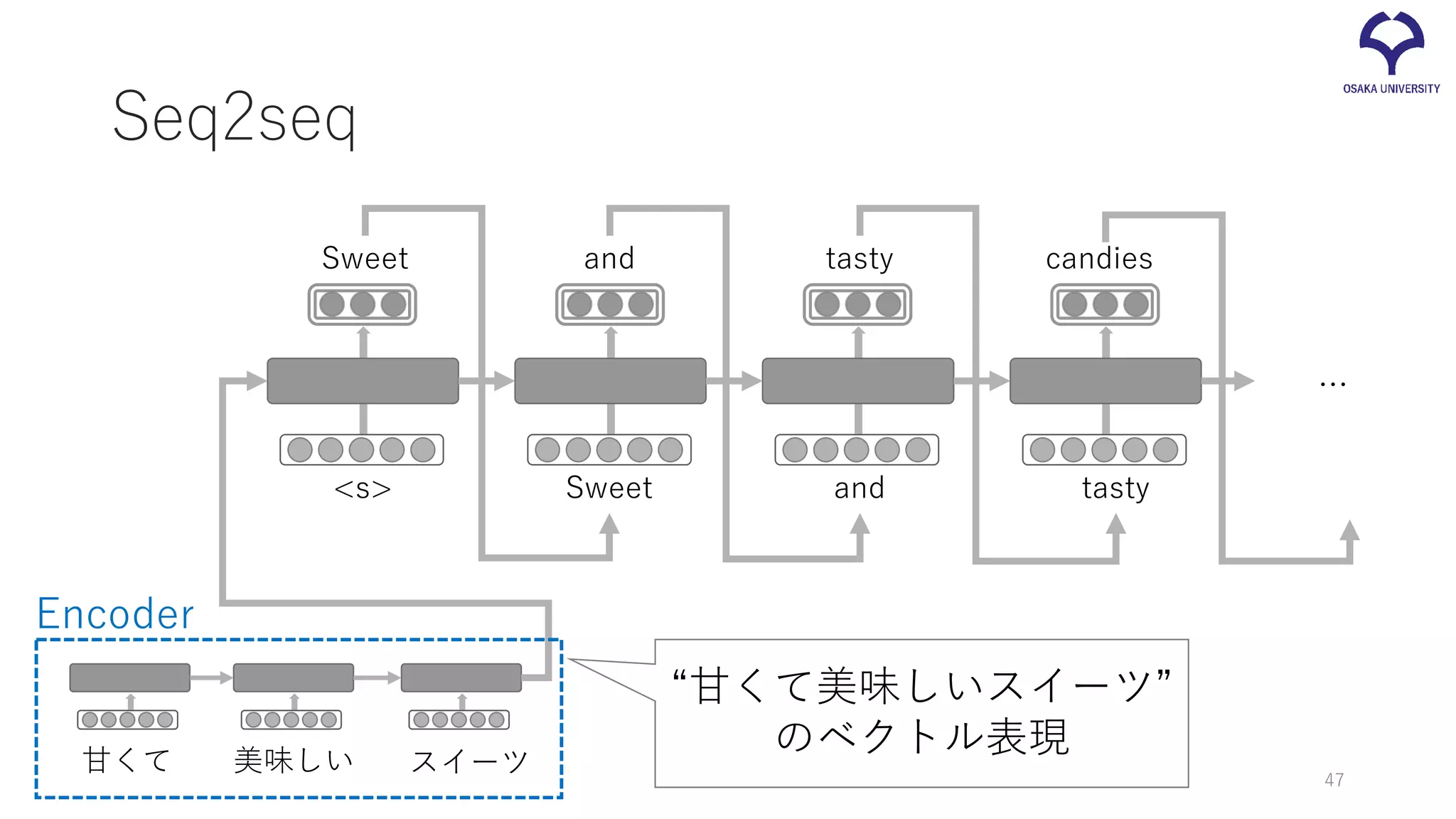
46.
Seq2seq 甘くて 美味しい スイーツ <s> Sweet
and tasty candies Sweet and tasty … 46
47.
Seq2seq 甘くて 美味しい スイーツ <s> Sweet
and tasty candies Sweet and tasty … “甘くて美味しいスイーツ” のベクトル表現 Encoder 47
48.
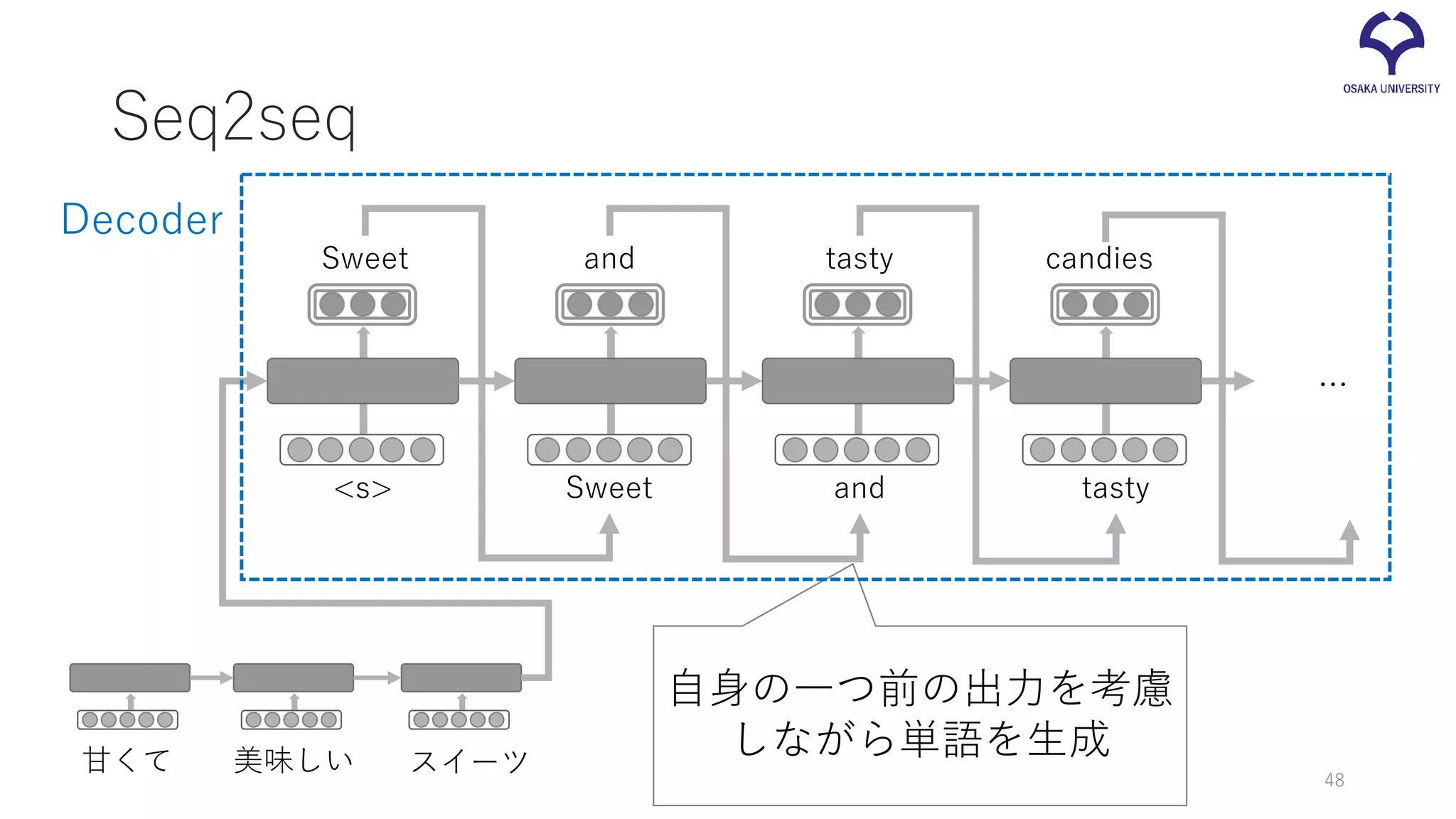
Seq2seq 甘くて 美味しい スイーツ <s> Sweet
and tasty candies Sweet and tasty … 自身の一つ前の出力を考慮 しながら単語を生成 Decoder 48
49.
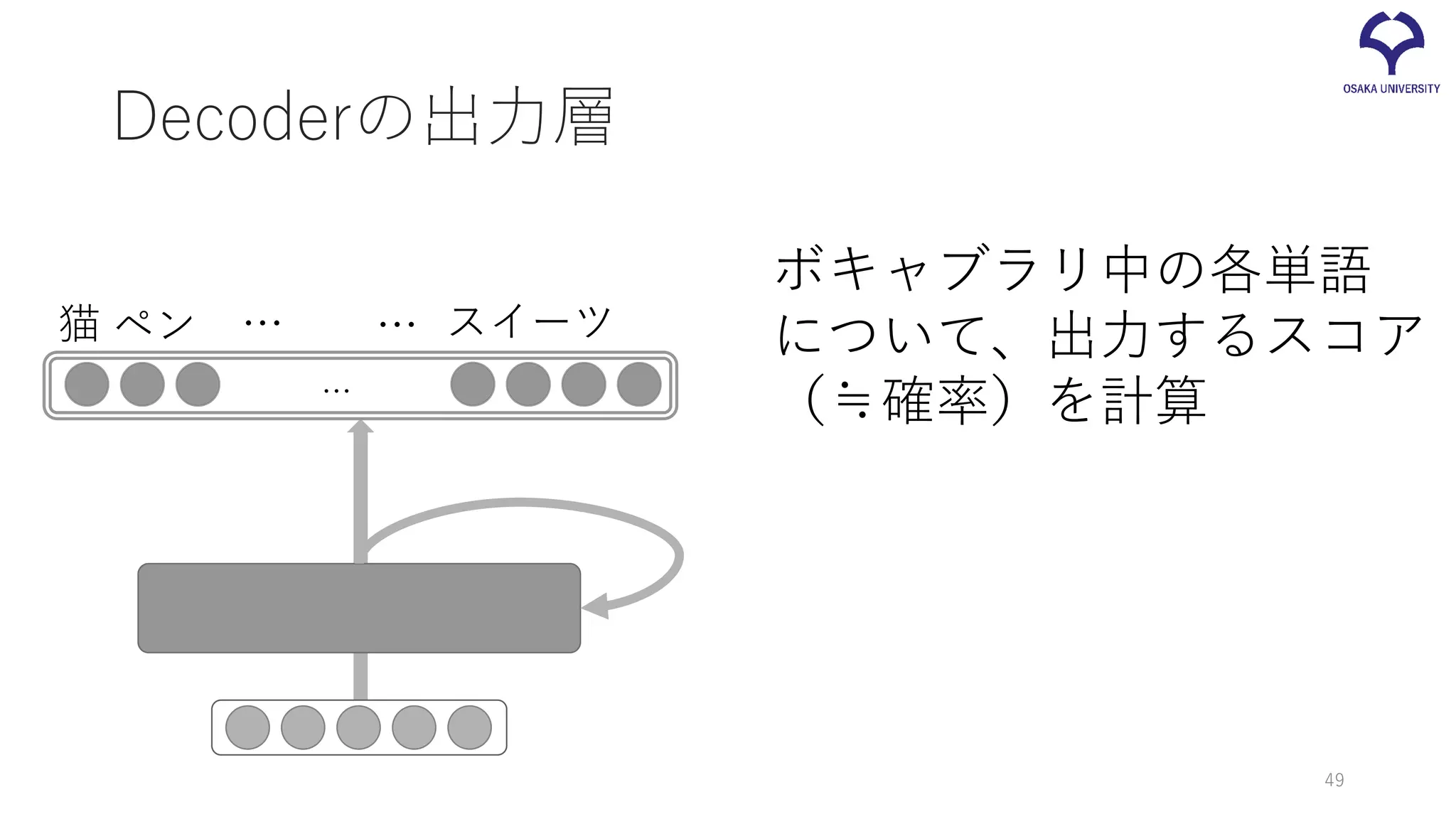
Decoderの出力層 ボキャブラリ中の各単語 について、出力するスコア (≒確率)を計算 スイーツペン … … 猫 … 49
50.
注意機構 (Attention mechanism) •LSTMを使っても、やっぱり昔のことは 忘れてしまう •(全部の情報を見なくても)ピンポイント で参照したい部分がある 例)翻訳する単語 •注意機構で直接的にその情報を利用 50
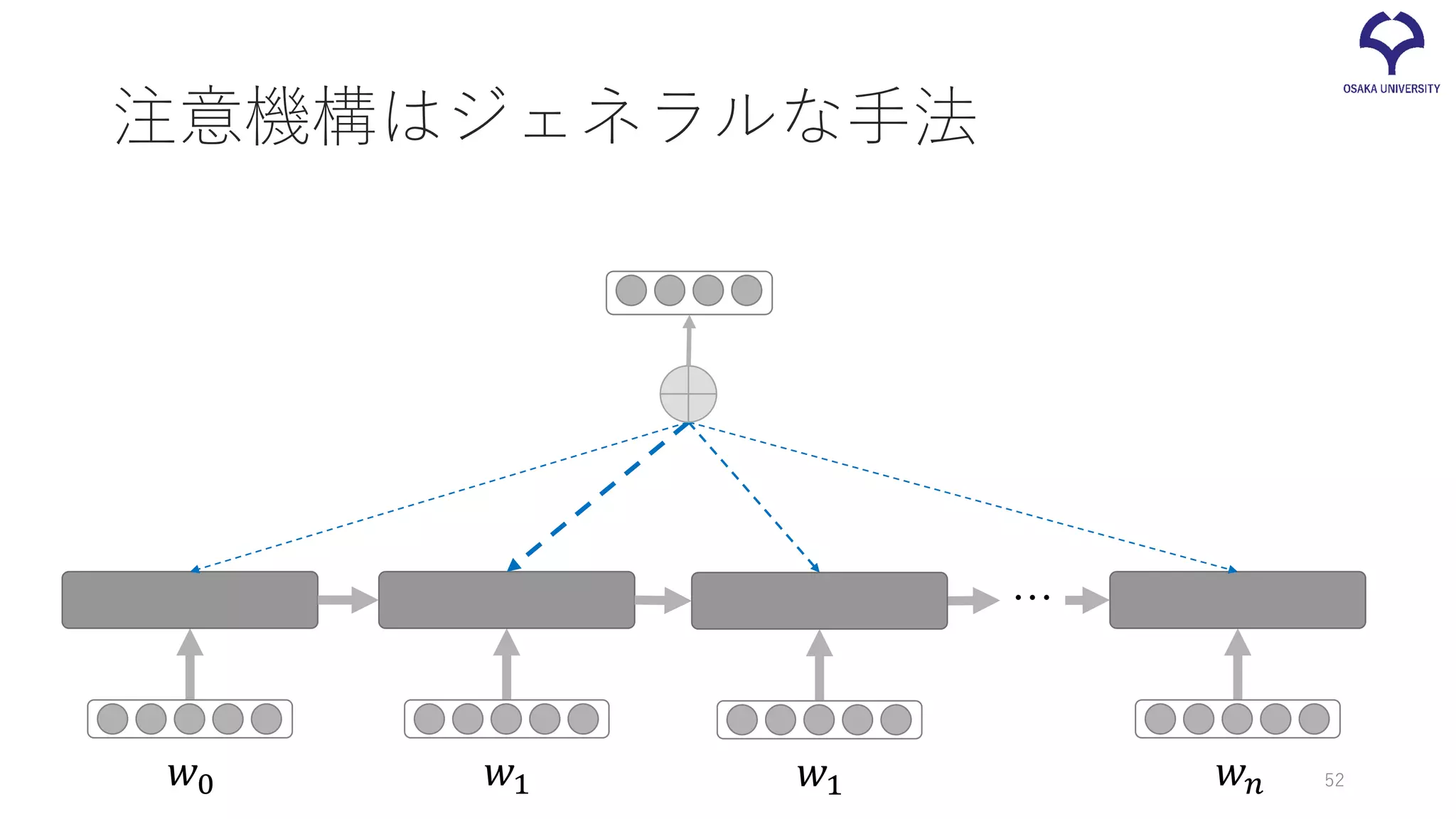
51.
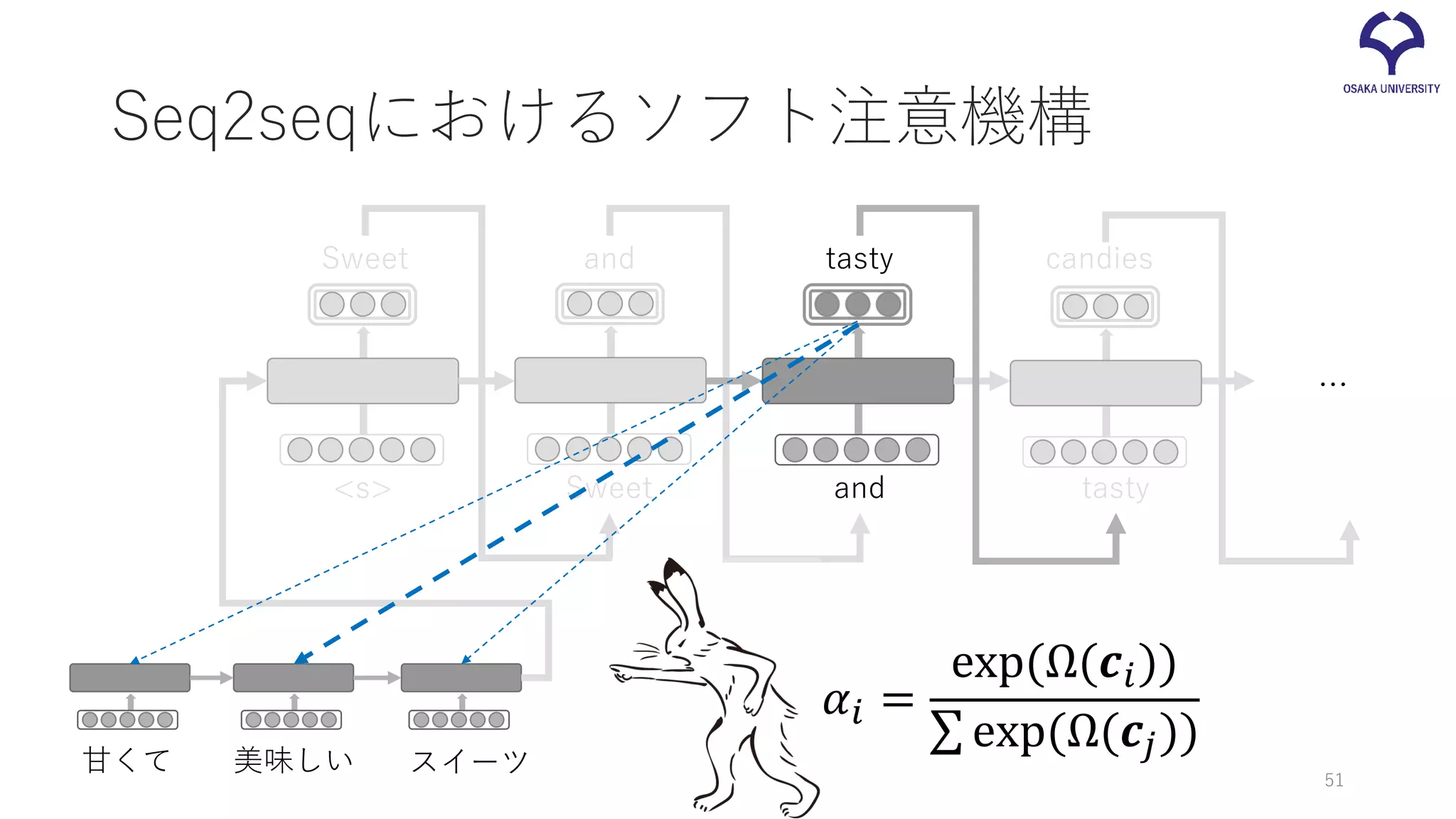
Seq2seqにおけるソフト注意機構 甘くて 美味しい スイーツ <s> Sweet
and tasty candies Sweet and tasty … 𝛼𝛼𝑖𝑖 = exp(Ω(𝒄𝒄𝑖𝑖)) ∑ exp(Ω(𝒄𝒄𝑗𝑗)) 51
52.
注意機構はジェネラルな手法 𝑤𝑤0 𝑤𝑤1 𝑤𝑤𝑛𝑛 … 𝑤𝑤1
52
53.
Transformer 53 https://ai.googleblog.com/2017/08/transformer-novel-neural-network.html
54.
NLPでよく使われるNNパッケージ •PyTorch https://pytorch.org/ • PyTorch
Forum https://discuss.pytorch.org/ •Chainer https://chainer.org/ •TensorFlow https://www.tensorflow.org/ •Torch (Lua) http://torch.ch/ 54
55.
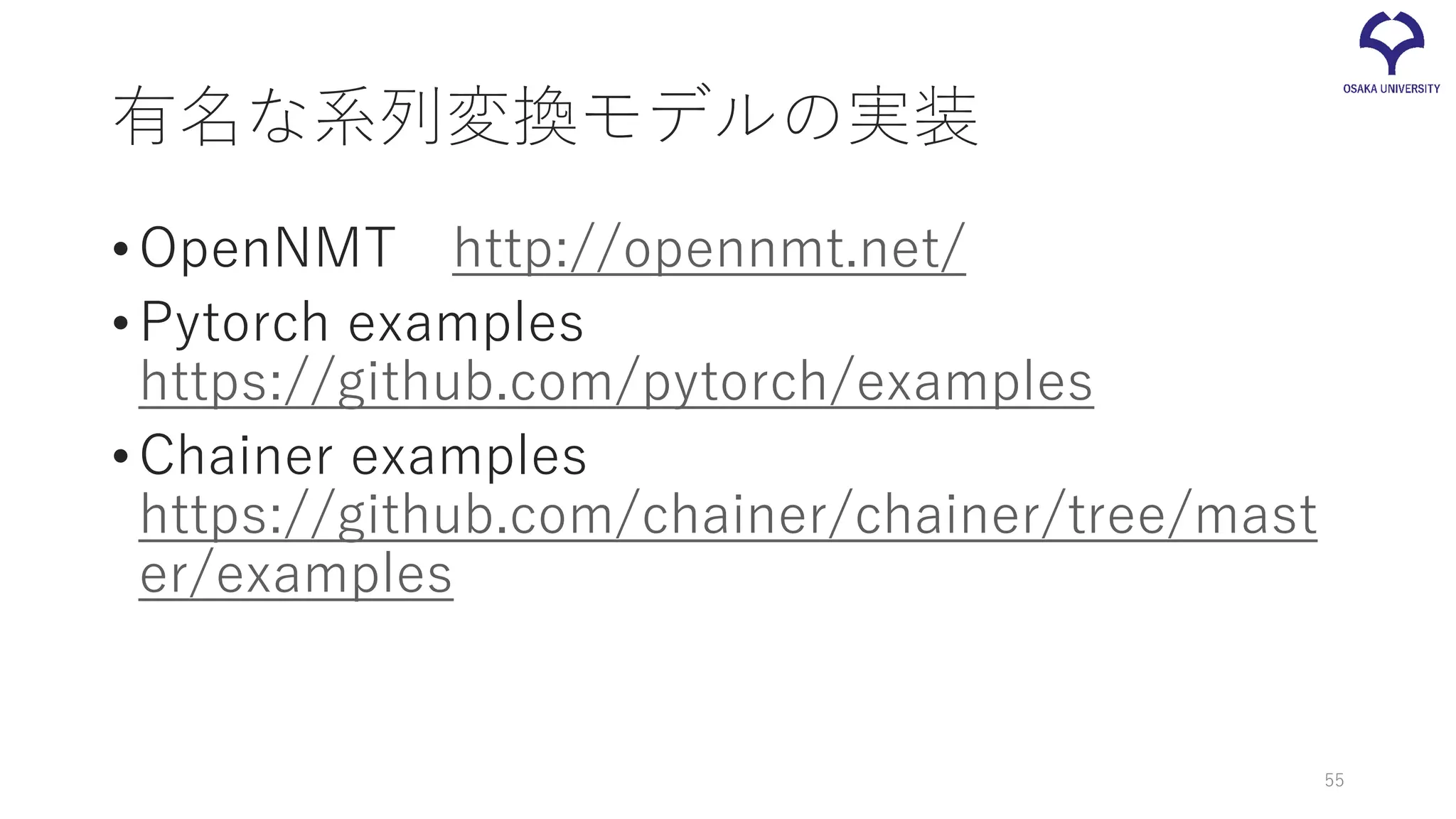
有名な系列変換モデルの実装 •OpenNMT http://opennmt.net/ •Pytorch examples https://github.com/pytorch/examples •Chainer
examples https://github.com/chainer/chainer/tree/mast er/examples 55
56.
再現実験は大変 •実装にはたくさんの選択肢が存在 • LSTMのデザインは複数存在、ライブラリによって サポートしているものが違う • Attentionの計算方法 •
Linear layer はさむ?はさまない? •著者が公開している実装、前処理のスクリプト を使う •第三者が公開している実装を使うときは、信頼で きそうな人のものを使う 56
57.
Agenda 1. 深層学習によるNLP 2. 単語のベクトル化 3.
文のベクトル化 4. 系列変換モデル 5. 学習データが、ない 6. 実はとても重要な前処理 7. もっと詳しく知りたい方に 57
58.
深層学習には大量の学習データが必要 •学習データ:入力と、正解がペアになったもの • ニューステキストとカテゴリ • 日本語とその英訳 •深層学習には多数の学習データが必要 •
Seq2seq:100万文ペア以上 • 分類問題:数万~数十万 58
59.
学習データが「ちょっと」あるとき 例)一般ドメインの英日対訳データは大量にある 医療ドメインの英日対訳データは少ししかない •Pre-training • 大量にある一般ドメインのデータで単語ベクトルを 学習 •Fine-tuning • 大量にある一般ドメインのデータでseq2seqを訓練 •
学習したパラメータを初期値として、少量の医療ド メインデータを使ってseq2seqを再訓練 59
60.
学習データが「ちょっと」あるとき •Pre-trainされたモデル(e.g., 単語ベクトル)で 特徴量を生成 •利用できる学習データを使って、SVMやRandom forestなどを訓練する 60
61.
そもそもデータがない 契約するか買うか自分でクローリングするか 6/6(水)13:20-15:00 鳥海 不二夫先生 「計算社会科学におけるWebマイニング」 https://www.slideshare.net/toritorix/ web-100905271 61
62.
学習データがないとき: クラウドソーシング •Web上で様々なアノテーションを依頼できる •簡潔なタスクについては非常にパワフルな仕組み •日本でも各種サービスが利用可能 6/8(金)14:00-15:40 馬場 雪乃 先生 「ヒューマンコンピュテーションと クラウドソーシング」 62
63.
学習データがないとき: 目的を置き換えてみる •InferSent 精度良い文のベクトル化→ 2文の含意・矛盾・それ以外を予測するタスク 美味しいスイーツをプレゼント 人気スイーツを購入63
64.
学習データがないとき: 目的を置き換えてみる •quick thoughts (Logeswaran
& Lee 2018) 文を上手くベクトル化できていれば、周辺の文を 判別できるはず Logeswaran & Lee: An efficient framework for learning sentence representations, ICLR 2018. 美味しいスイーツをプレゼント RNN 商品がすぐに壊れた RNN ケーキと一緒にコーヒーを飲んだ RNN いい天気ですね RNN Classifier 2 64
65.
学習データがないとき: 目的を置き換えてみる Doersch, Gupta, and
Efros. Unsupervised visual representation learning by context prediction. in Proc. of ICCV 2015. ※図は論文より引用 65
66.
Agenda 1. 深層学習によるNLP 2. 単語のベクトル化 3.
文のベクトル化 4. 系列変換モデル 5. 学習データが、ない 6. 実はとても重要な前処理 7. もっと詳しく知りたい方に 66
67.
定番の前処理 •HTMLタグなどタグの除去 •スペース記号の除去 •(不要な)改行記号の除去 •文ごとに分割 •単語分割 67
68.
ノイズ除去、テキスト正規化 68
69.
よくあるノイズ •URL •非文(@mention,hashtag,商品コード,etc.) •アクセント記号:ã,ä,é •対象以外の言語データ •記号のバリエーション --﹣ ‐ -
⁃ ˗ − ➖ ‒ – ~ ~ ∼ ˜ ˷ ∽ ∾ ∿ 〜 〰 ﹏ •謎のUnicode文字 69
70.
ノイズ除去 • URL・非テキスト・記号のバリエーション →データに頻繁に出現するパターンを観察してルール で除去 • アクセント記号 →文字コードに注意すれば大丈夫 HTMLでは特殊記号に置き替えられるので置換 •
対象言語以外 →Unicodeの範囲指定である程度何とかなる • 謎のUnicode文字 →テキストをまずデコード、失敗したものは排除 70
71.
テキスト正規化 • 顔文字、絵文字の正規化や除去 • 連続した長音符、記号の除去 •
全角数字・アルファベットの半角数字への統一 • 数値表現(年、月、日、金額、etc. )のタグ置き換え 例)2018年6月3日→ $date ※必要かどうかはアプリケーション依存 ※顔文字・絵文字は感情表現として重要 71
72.
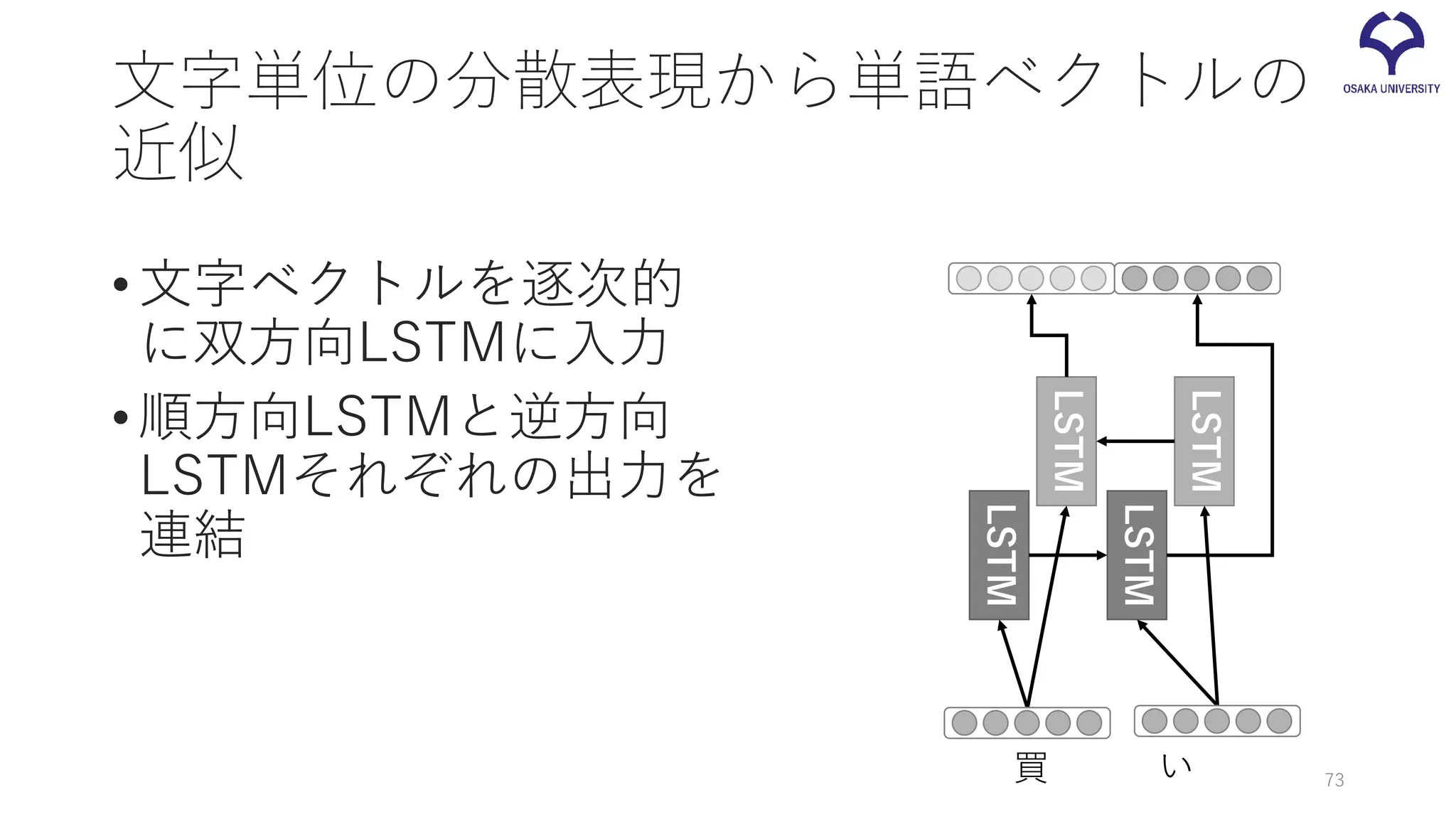
未知語への対処 •単語ベクトルはあるが、モデルの語彙にない • seq2seqは語彙サイズに制限 • 単語ベクトルの最も近い語に置き換える (Li
et al. 2016) • サブワードを使う •単語ベクトルにない • <unk> タグを学習しておく • 「適当」に作る • 文字単位の分散表現から近似する Li, Zhang, and Zong. Towards zero unknown word in neural machine translation. in Proc. of IJCAI 2016. 72
73.
文字単位の分散表現から単語ベクトルの 近似 •文字ベクトルを逐次的 に双方向LSTMに入力 •順方向LSTMと逆方向 LSTMそれぞれの出力を 連結 LSTM LSTM LSTM LSTM 買 い 73
74.
Agenda 1. 深層学習によるNLP 2. 単語のベクトル化 3.
文のベクトル化 4. 系列変換モデル 5. 学習データが、ない 6. 実はとても重要な前処理 7. もっと詳しく知りたい方に 74
75.
もっと詳しく知りたい方に •出た本 深層学習による自然言語処理 (機械学習プロフェッショ ナルシリーズ) 坪井 祐太、海野
裕也、鈴木 潤 (著) •青本 深層学習 (機械学習プロフェッショナルシリーズ) 岡谷 貴之 (著) 75
76.
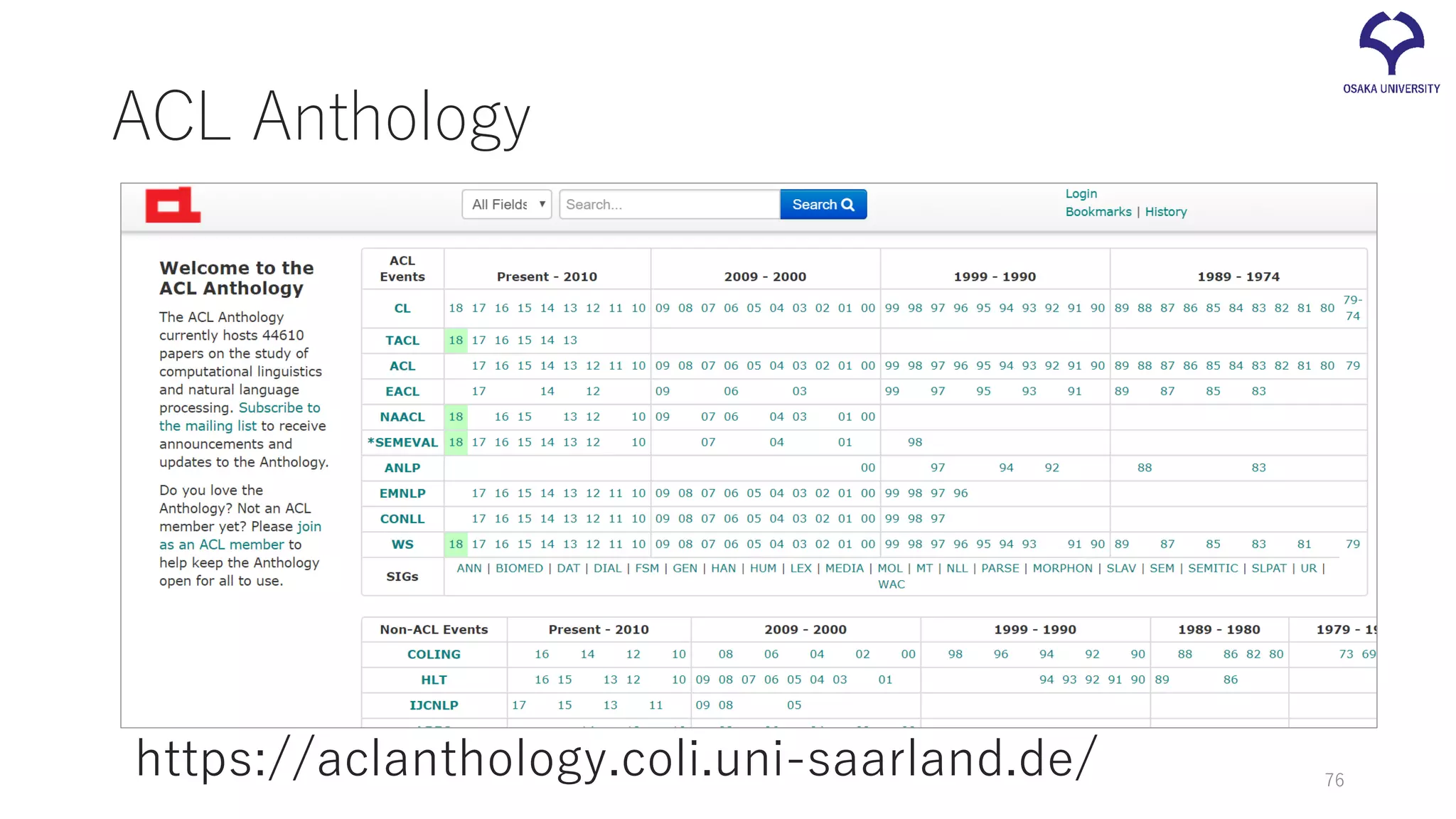
ACL Anthology https://aclanthology.coli.uni-saarland.de/ 76
77.
言語処理学会 論文誌発行、年次大会(3月) http://www.anlp.jp/ 77
78.
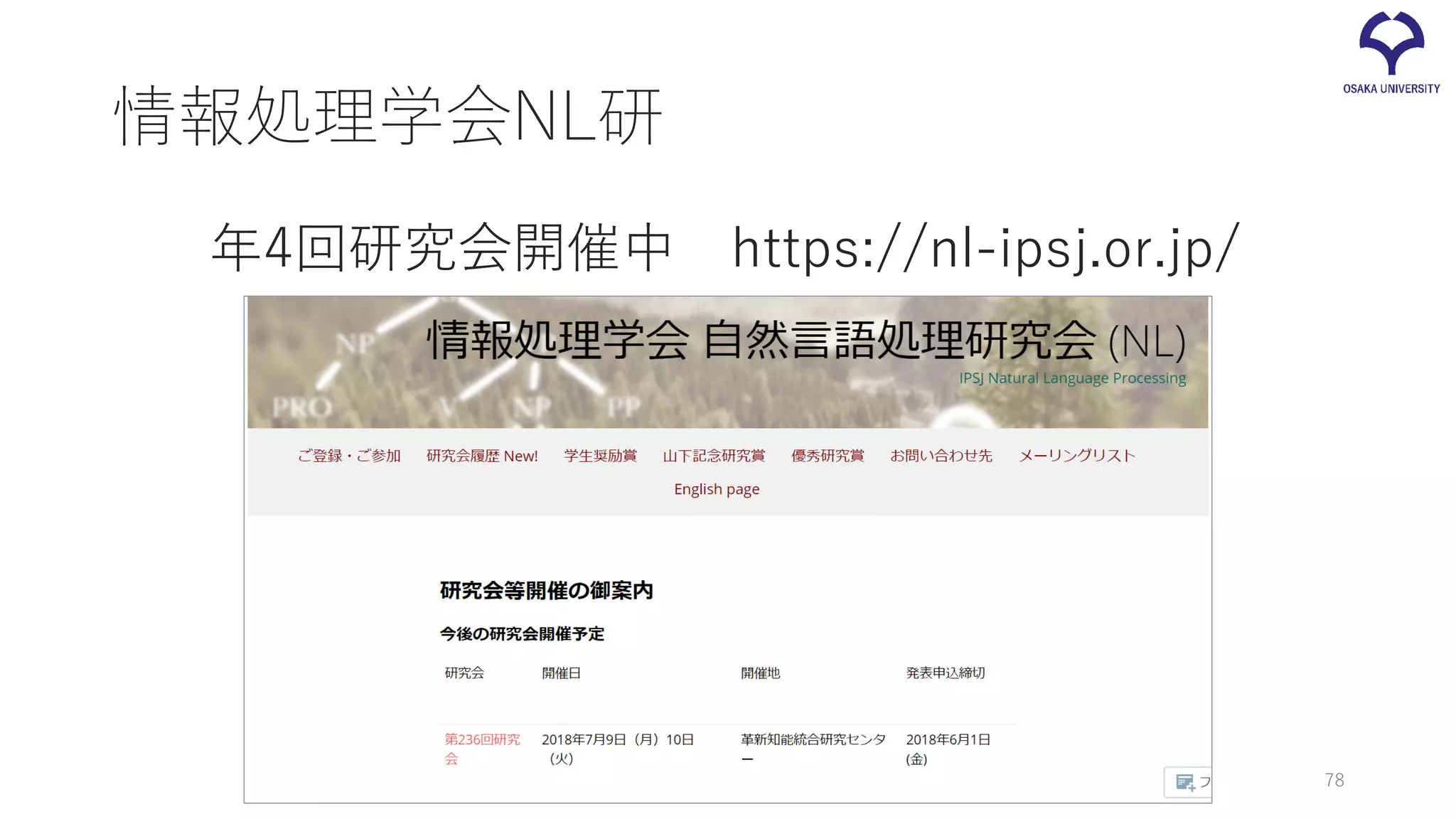
情報処理学会NL研 年4回研究会開催中 https://nl-ipsj.or.jp/ 78
79.
NLP若手の会 NLPおよび関連分野の若手研究者・若手技術者の 交流を促進 http://yans.anlp.jp/ 79
80.
NLP若手の会 •大学をまたいだ学生の交流 •企業と大学研究者、企業と学生の橋渡し 2018年シンポジウム:8/27-29@香川 80
Download


































































![[DL輪読会]ドメイン転移と不変表現に関するサーベイ](https://cdn.slidesharecdn.com/ss_thumbnails/20190614iwasawa-190614005939-thumbnail.jpg?width=640&height=640&fit=bounds)



![SSII2022 [SS2] 少ないデータやラベルを効率的に活用する機械学習技術 〜 足りない情報をどのように補うか?〜](https://cdn.slidesharecdn.com/ss_thumbnails/ss2ssii2022-220607054716-2760bd30-thumbnail.jpg?width=640&height=640&fit=bounds)






![[DL輪読会]Model soups: averaging weights of multiple fine-tuned models improves ...](https://cdn.slidesharecdn.com/ss_thumbnails/dl0401-220405031053-thumbnail.jpg?width=640&height=640&fit=bounds)

![[旧版] JSAI2018 チュートリアル「"深層学習時代の" ゼロから始める自然言語処理」](https://cdn.slidesharecdn.com/ss_thumbnails/jsai2018tutorialslideshare-180606065226-thumbnail.jpg?width=640&height=640&fit=bounds)
























