BERT仕組み
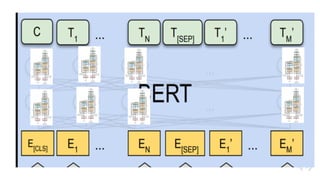
出典:BERT: Pre-training ofDeep Bidirectional Transformers for Language
Understanding 図1より引⽤
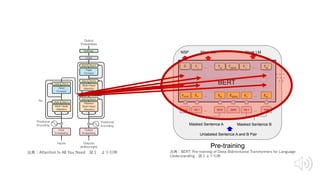
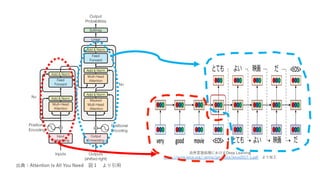
出典:Attention Is All You Need 図1 より引⽤
6.
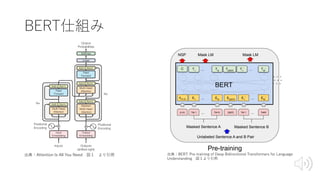
出典:BERT: Pre-training ofDeep Bidirectional Transformers for Language
Understanding 図1より引⽤
出典:Attention Is All You Need 図1 より引⽤
8.
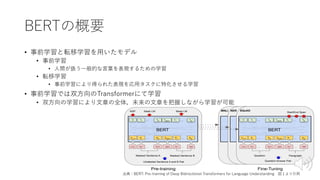
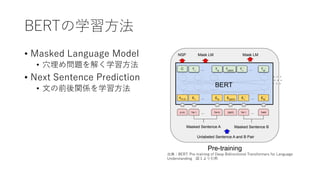
BERTの学習⽅法
• Masked LanguageModel
• ⽳埋め問題を解く学習⽅法
• Next Sentence Prediction
• ⽂の前後関係を学習⽅法
出典:BERT: Pre-training of Deep Bidirectional Transformers for Language
Understanding 図1より引⽤
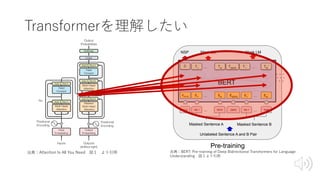
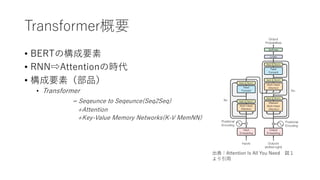
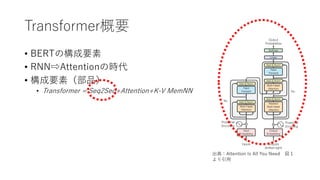
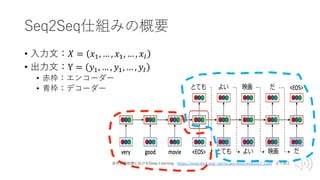
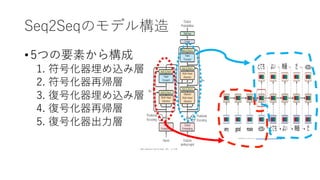
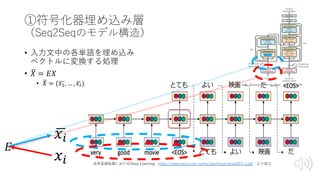
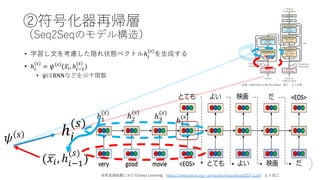
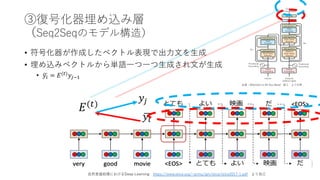
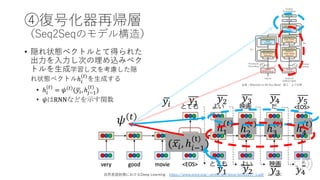
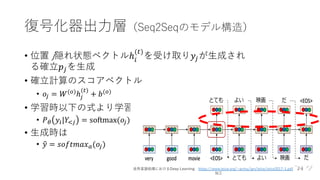
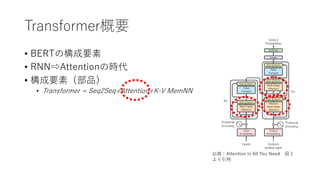
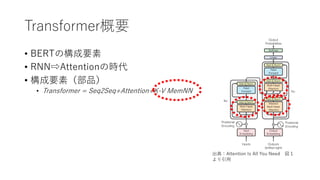
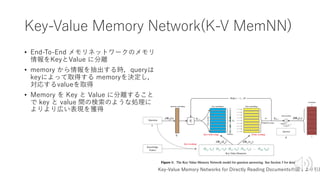
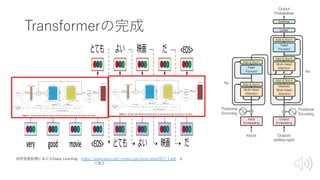
Transformer概要
• BERTの構成要素
• RNN⇨Attentionの時代
•構成要素(部品)
• Transformer
= Seqeunce to Seqeunce(Seq2Seq)
+Attention
+Key-Value Memory Networks(K-V MemNN)
出典:Attention Is All You Need 図1
より引⽤




![Masked Language Model
• ⼊⼒⽂の15%を確率的に
[MASK]トークンで置き換え
る
• [MASK] トークンのうち
• 80%が マスク変換
• 10%がランダムな別の
トークンに変換
• 10%をそのままのトーク
ン
https://ja.wikipedia.org/wiki/%E8%87%AA%E7%84%B6%E8%A8%80%E8%AA%9E%E5%87%A6%
E7%90%86 より加⼯
https://www.lyrn.ai/2018/11/07/explained-bert-state-of-the-art-
language-model-for-nlp/#appendix-A より引⽤](https://image.slidesharecdn.com/aaa-191129221818/85/BERT-9-320.jpg)








![[DL輪読会]BERT: Pre-training of Deep Bidirectional Transformers for Language Und...](https://cdn.slidesharecdn.com/ss_thumbnails/dlreadingpaper20181019-181019010218-thumbnail.jpg?width=640&height=640&fit=bounds)



![[DL輪読会]Discriminative Learning for Monaural Speech Separation Using Deep Embe...](https://cdn.slidesharecdn.com/ss_thumbnails/201912227dldiscriminativeleraningformanaouraspeechseparationusingdeepembeddingfeaturessumissionver2-191227001259-thumbnail.jpg?width=640&height=640&fit=bounds)

![[旧版] JSAI2018 チュートリアル「"深層学習時代の" ゼロから始める自然言語処理」](https://cdn.slidesharecdn.com/ss_thumbnails/jsai2018tutorialslideshare-180606065226-thumbnail.jpg?width=640&height=640&fit=bounds)


![[最新版] JSAI2018 チュートリアル「"深層学習時代の" ゼロから始める自然言語処理」](https://cdn.slidesharecdn.com/ss_thumbnails/jsai2018tutorialslideshare-180607030706-thumbnail.jpg?width=640&height=640&fit=bounds)





![[DL輪読会]Convolutional Sequence to Sequence Learning](https://cdn.slidesharecdn.com/ss_thumbnails/dl0519-170519005603-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL Hacks]Pretraining-Based Natural Language Generation for Text Summarizatio...](https://cdn.slidesharecdn.com/ss_thumbnails/dlhackspretraining-basednaturallanguagegenerationfortextsummarization-190422070150-thumbnail.jpg?width=640&height=640&fit=bounds)








