Download as PDF, PPTX











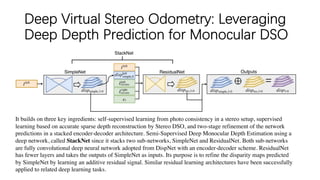


![Deep Virtual Stereo Odometry: Leveraging
Deep Depth Prediction for Monocular DSO
[46]. Yin, X., Wang, X., Du, X., Chen, Q. “Scale recovery for monocular visual odometry using depth
estimated with deep convolutional neural fields”. CVPR 2017
[49]. Zhou, T., Brown, M., Snavely, N., Lowe, D.G. “Unsupervised learning of depth and ego-motion from
video”. CVPR 2017](https://image.slidesharecdn.com/deepslam-200130064533/85/Deep-VO-and-SLAM-24-320.jpg)

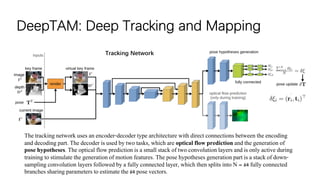
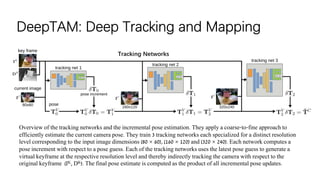

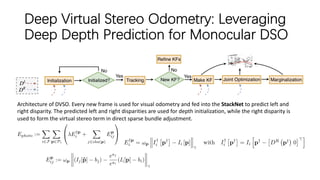
![DeepTAM: Deep Tracking and Mapping
Mapping consists of a fixed band and narrow band module. Fixed band module: it takes the keyframe image IK(320 ×
240 × 3) and the cost volume Cfb (320 × 240 × 32) generated with 32 depth labels equally spaced in the range [0.01, 2.5]
as inputs and outputs an interpolation factor sfb (320 × 240 × 1). The fixed band depth estimation is Dfb = (1−sfb)·dmin
+sfb ·dmax. Narrow band module: The narrow band module is run iteratively; in each iteration build a cost volume Cnb from
a set of depth labels distributed with a band width σnb of 0.0125. It consists of two encoder-decoder pairs.](https://image.slidesharecdn.com/deepslam-200130064533/85/Deep-VO-and-SLAM-29-320.jpg)





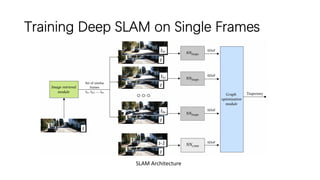
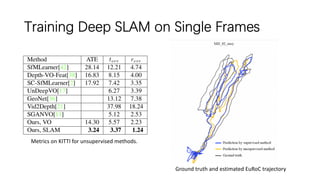

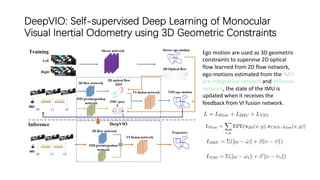

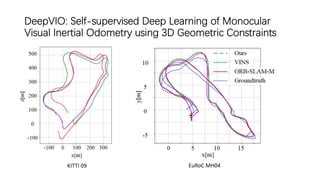

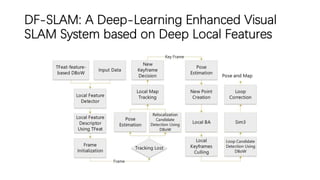

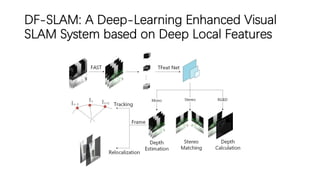


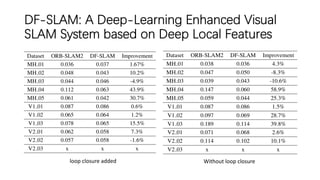

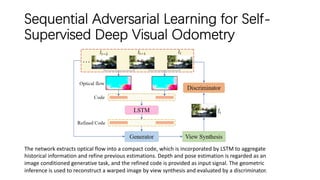
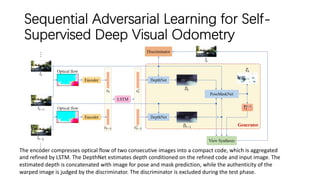

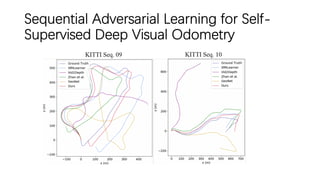


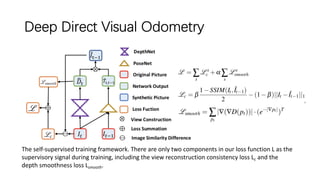
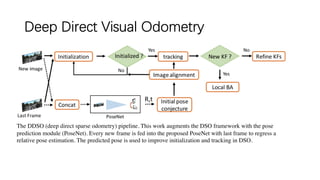
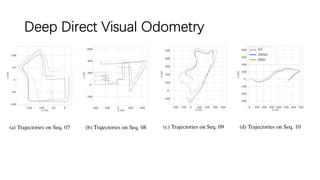

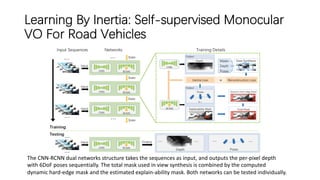


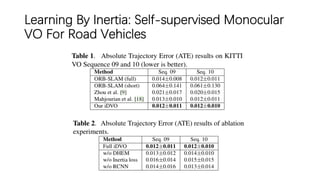


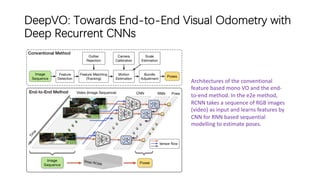
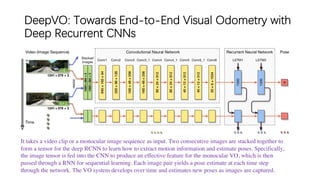
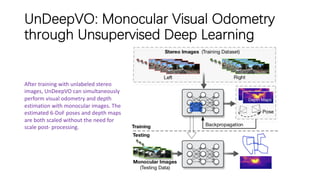
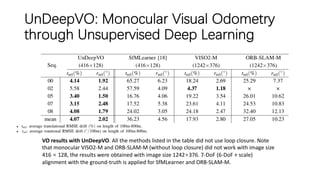
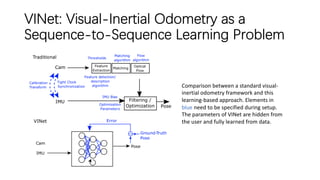
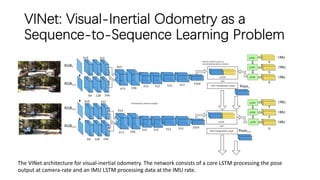
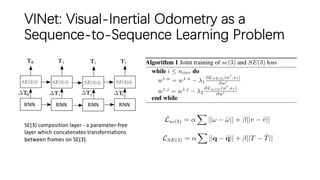
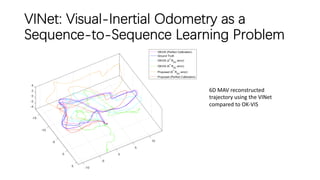
This document outlines advancements in visual odometry (VO) and simultaneous localization and mapping (SLAM) using deep learning techniques. Key contributions include the development of end-to-end frameworks like DeepVO and UndeepVO, which leverage deep neural networks for real-time pose estimation and depth recovery. Additional projects such as Vinet and DeepFusion focus on fusing visual and inertial information for improved navigation and dense 3D reconstruction capabilities.











![[DL輪読会]NeRF: Representing Scenes as Neural Radiance Fields for View Synthesis](https://cdn.slidesharecdn.com/ss_thumbnails/nerfdlseminar1-200327021512-thumbnail.jpg?width=640&height=640&fit=bounds)







![SSII2022 [SS1] ニューラル3D表現の最新動向〜 ニューラルネットでなんでも表せる?? 〜](https://cdn.slidesharecdn.com/ss_thumbnails/ss1ssii2022hkatoneural3drepresentationhiroharukato-220607054619-fadc6480-thumbnail.jpg?width=640&height=640&fit=bounds)








![論文読み会@AIST (Deep Virtual Stereo Odometry [ECCV2018])](https://cdn.slidesharecdn.com/ss_thumbnails/dvsoslideshare-181104042256-thumbnail.jpg?width=640&height=640&fit=bounds)


























































