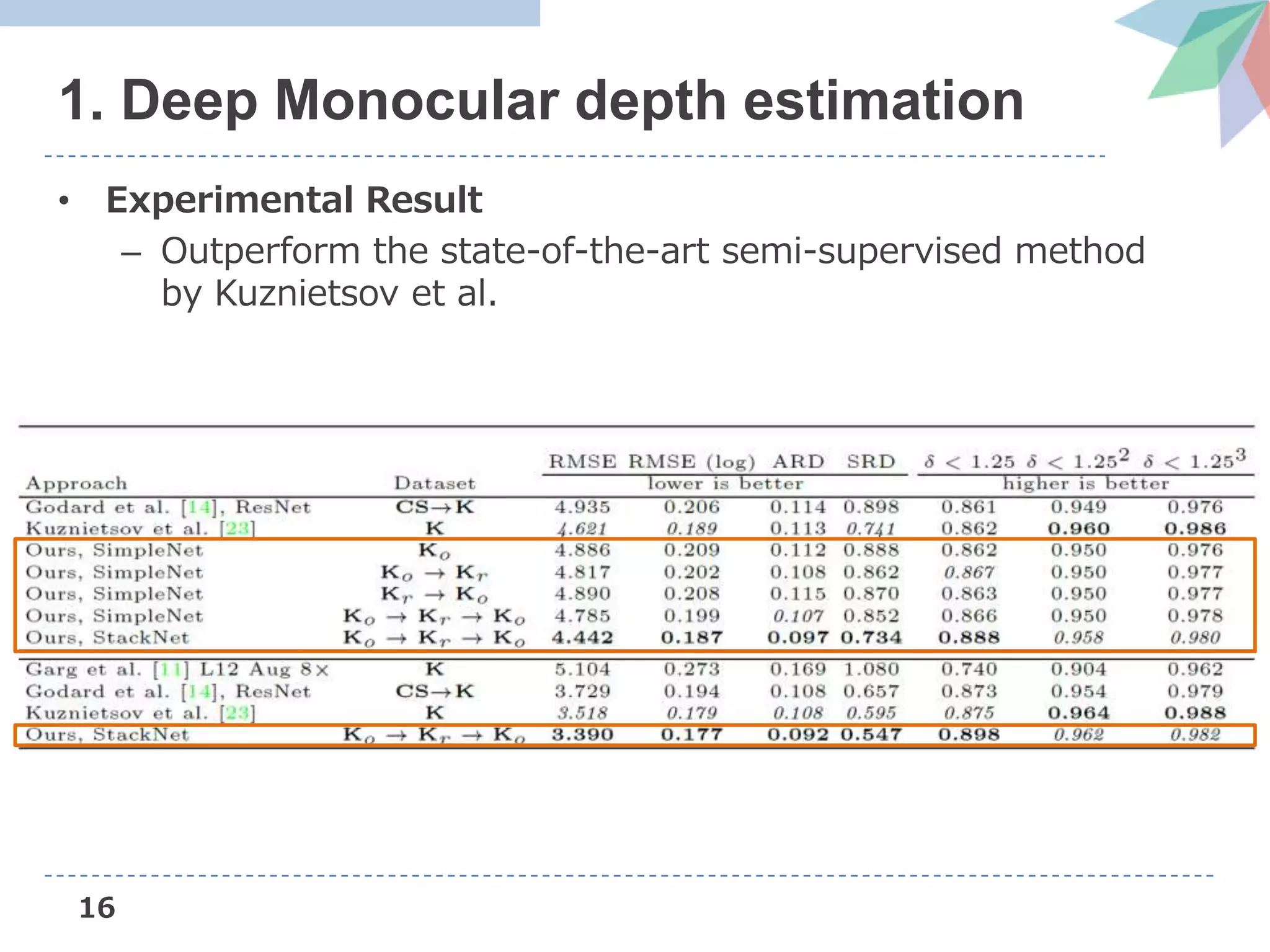
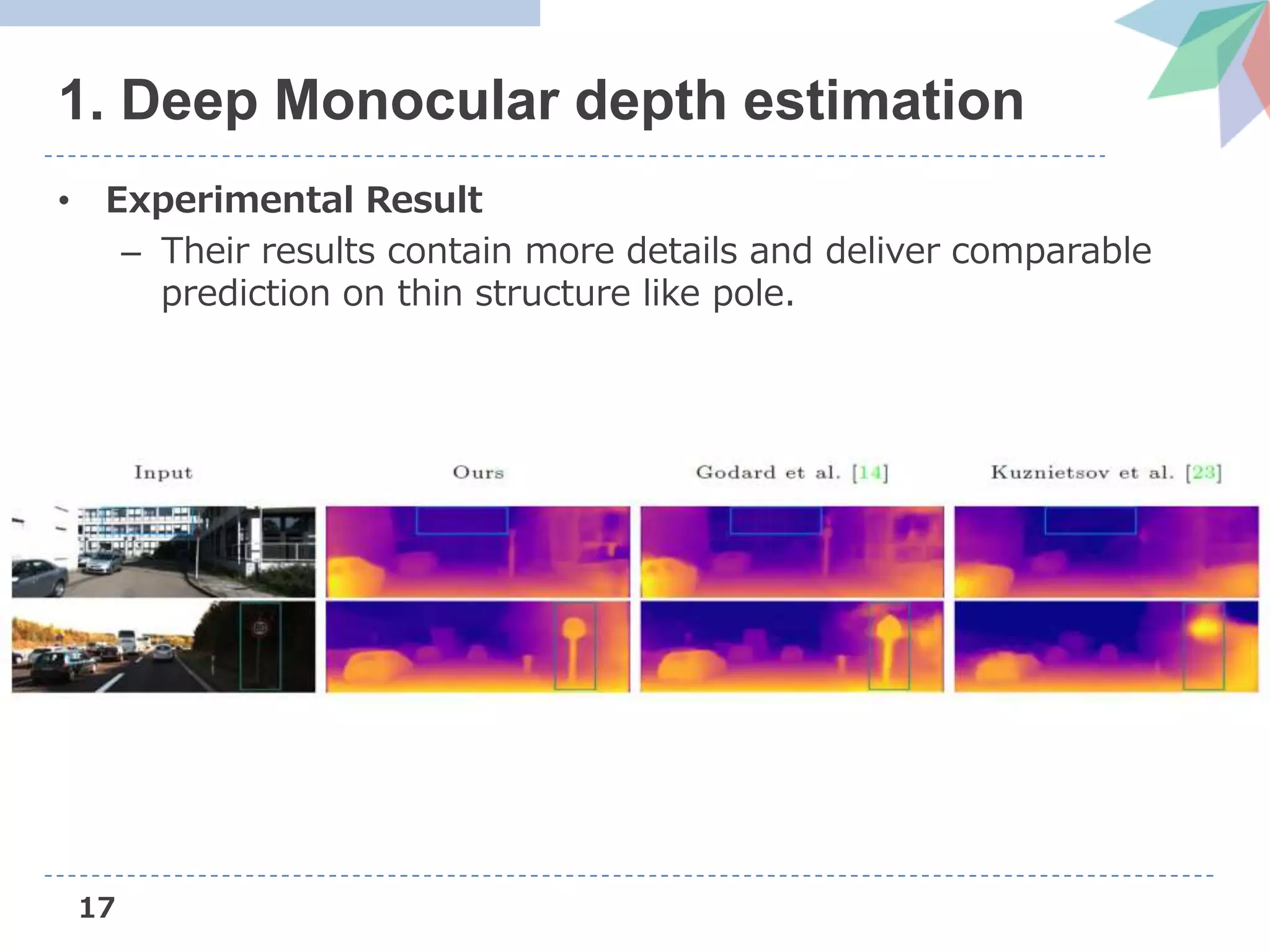
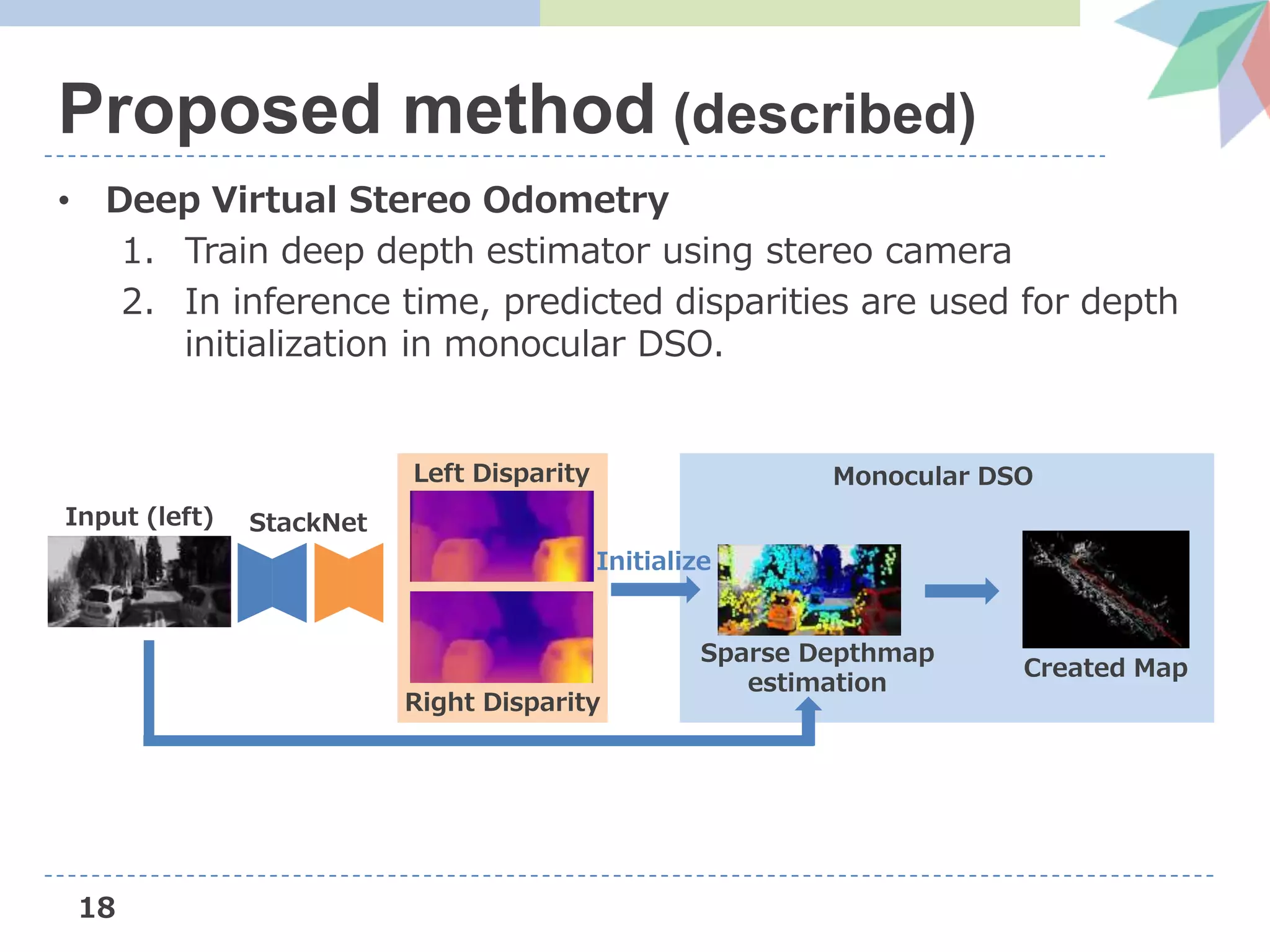
The document presents Deep Virtual Stereo Odometry (DVSO), a novel monocular visual odometry system that utilizes deep depth prediction to mitigate scale drift and improve the accuracy of 3D reconstruction. The approach trains a depth estimator using stereo camera inputs, which are then applied during inference with monocular cameras for depth initialization in Direct Sparse Odometry. Experimental results demonstrate that DVSO achieves performance comparable to stereo methods while outperforming state-of-the-art monocular visual odometry techniques.
![Deep Virtual Stereo Odometry:
Leveraging Deep Depth Prediction for Monocular
Direct Sparse Odometry [ECCV2018(oral)]
The University of Tokyo
Aizawa Lab M1 Masaya Kaneko
論文読み会 @ AIST](https://image.slidesharecdn.com/dvsoslideshare-181104042256/75/AIST-Deep-Virtual-Stereo-Odometry-ECCV2018-1-2048.jpg)
![1
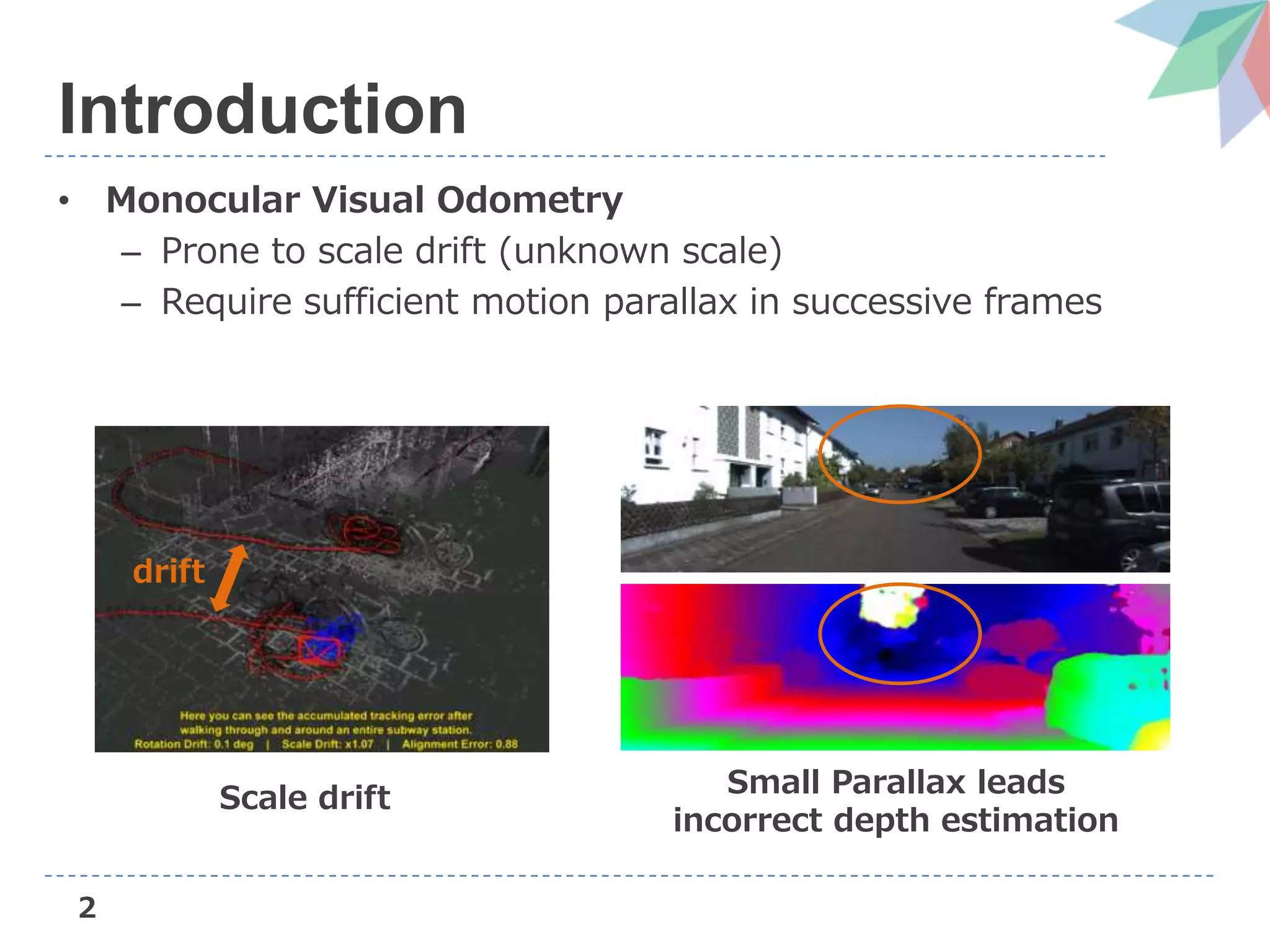
Introduction
• Monocular Visual Odometry
– Camera’s trajectory estimation and 3D reconstruction from
image sequences obtained by monocular camera
Direct Sparse Odometry [Engel+, PAMI’18]](https://image.slidesharecdn.com/dvsoslideshare-181104042256/75/AIST-Deep-Virtual-Stereo-Odometry-ECCV2018-2-2048.jpg)

![4
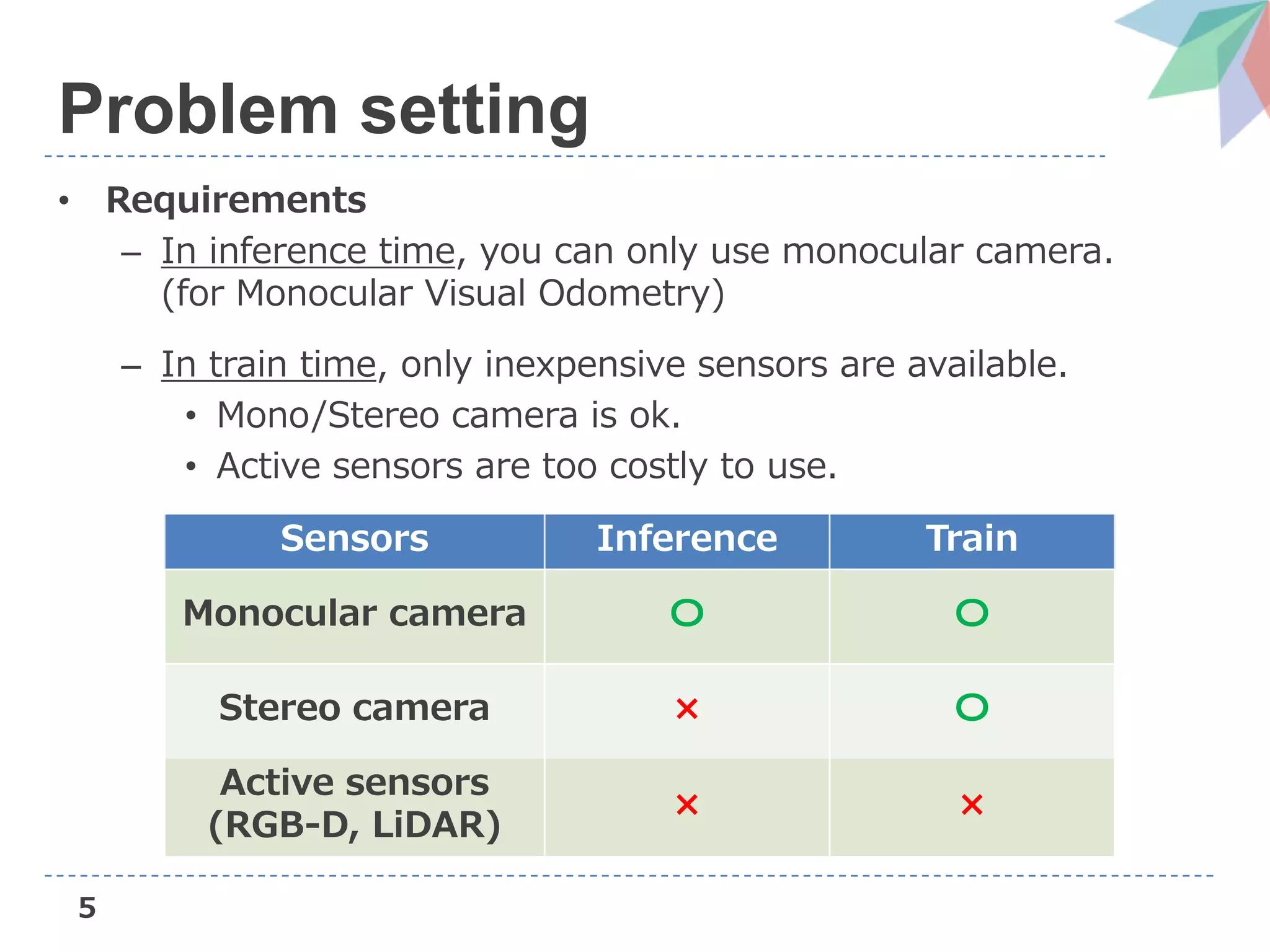
Introduction
• If a priori knowledge about environment is used, this issue
can be solved without complex sensors.
– Deep based approach like CNN-SLAM [Tateno+, CVPR’18]
– Now they propose a method to adapt this approach into
state-of-the-art VO, DSO (Direct Sparse Odometry).
https://drive.google.com/file/d/108CttbYiBqaI3b1jIJFTS26SzNfQqQNG/view](https://image.slidesharecdn.com/dvsoslideshare-181104042256/75/AIST-Deep-Virtual-Stereo-Odometry-ECCV2018-5-2048.jpg)
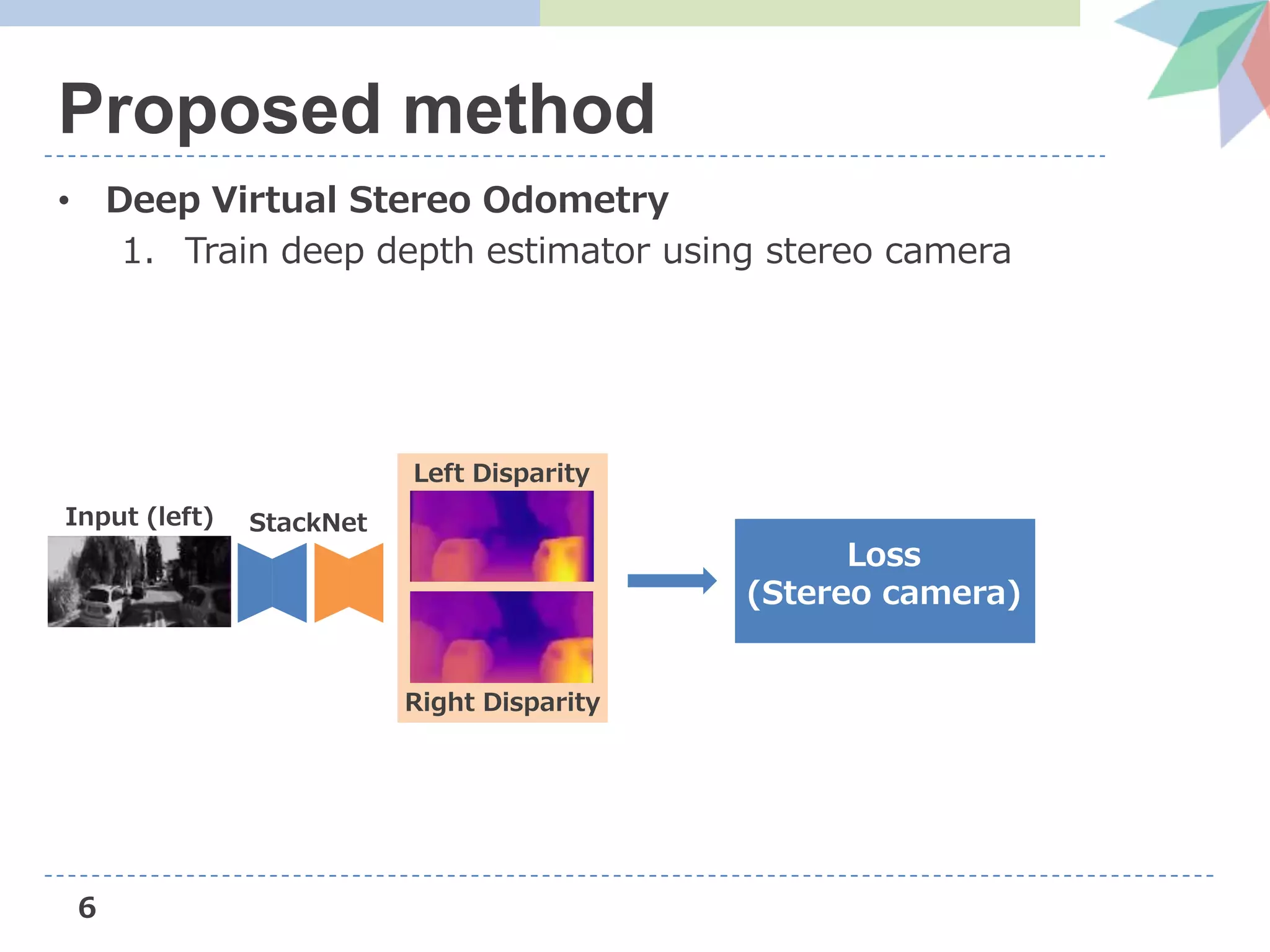
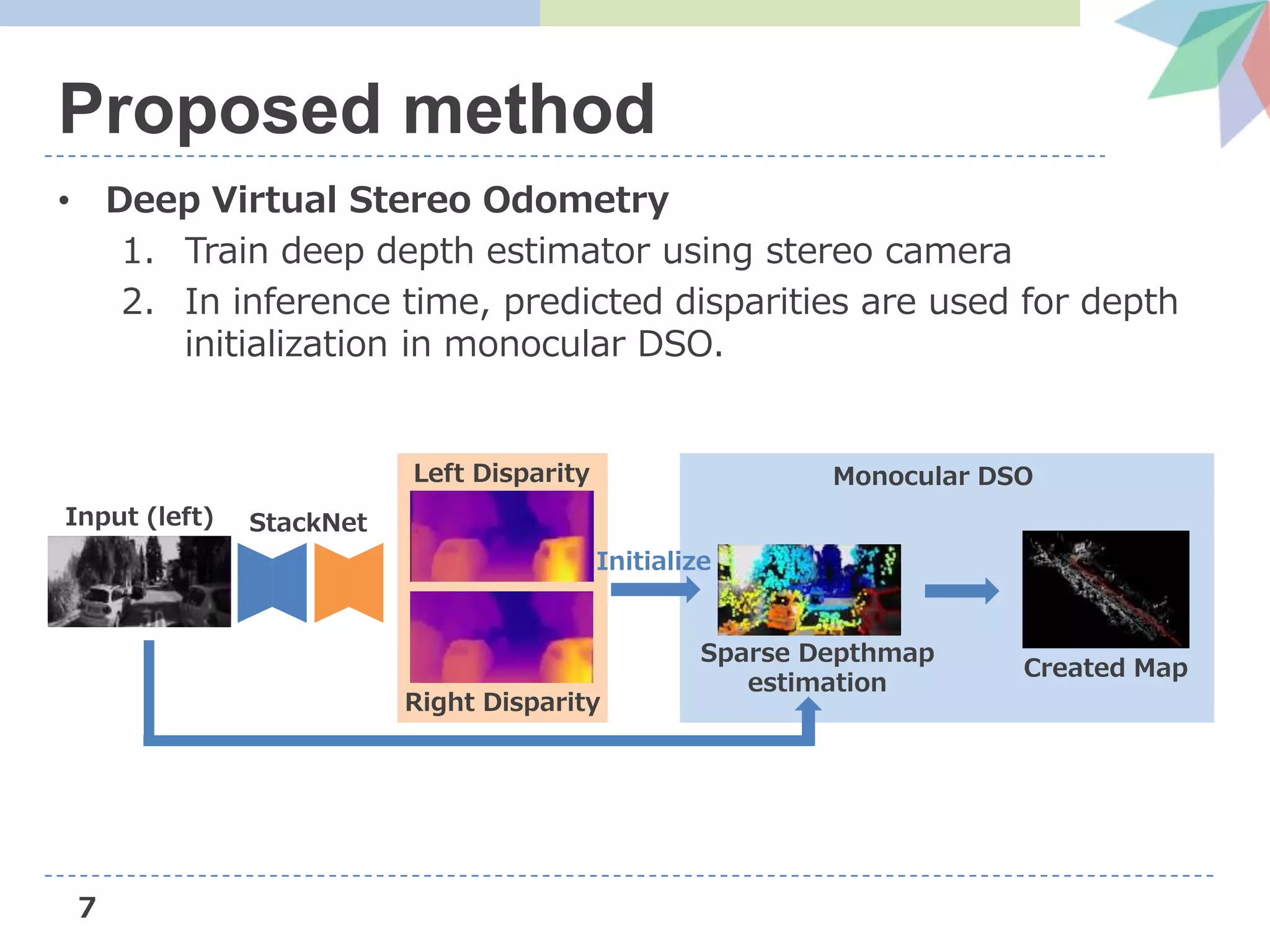
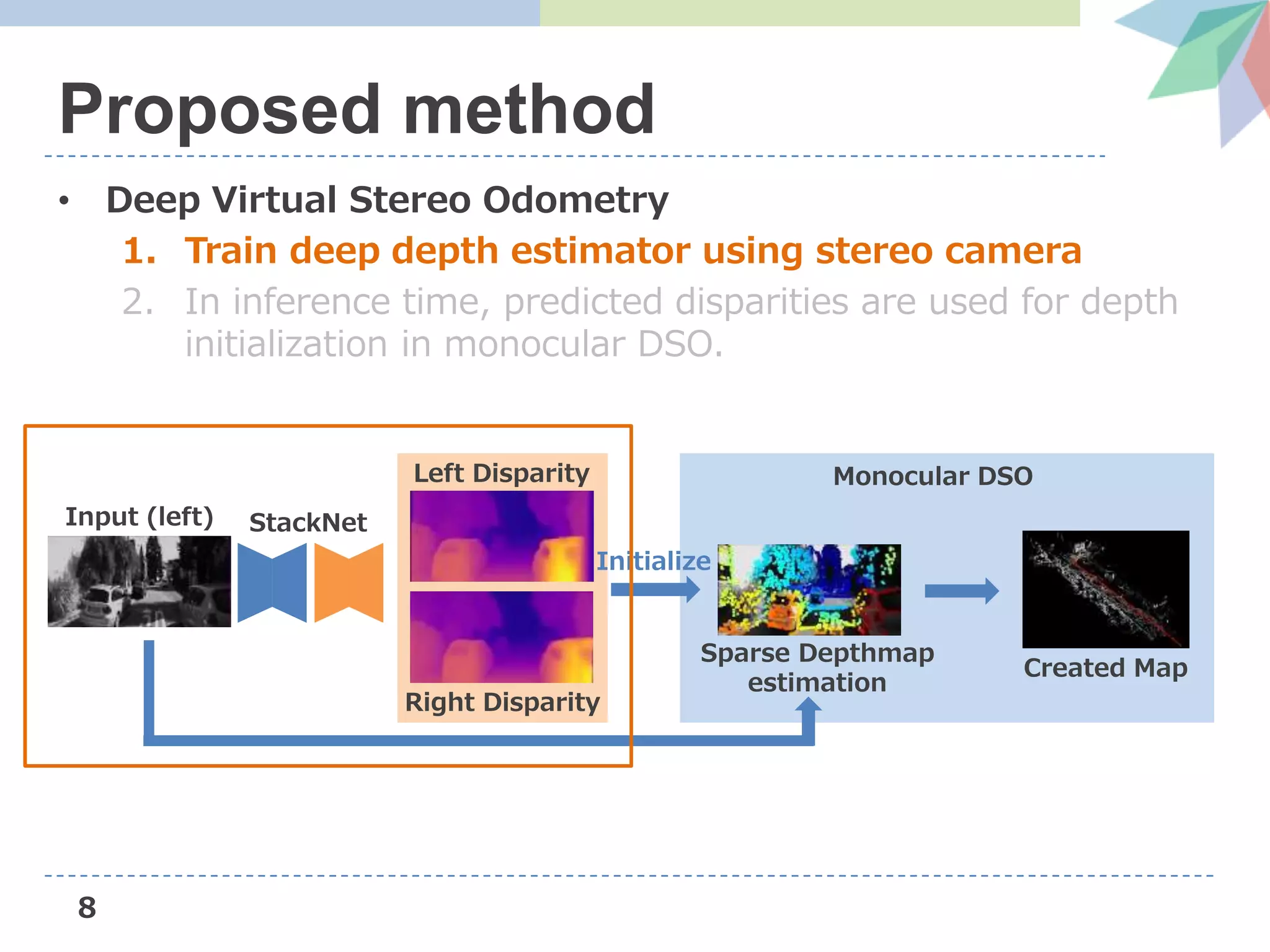
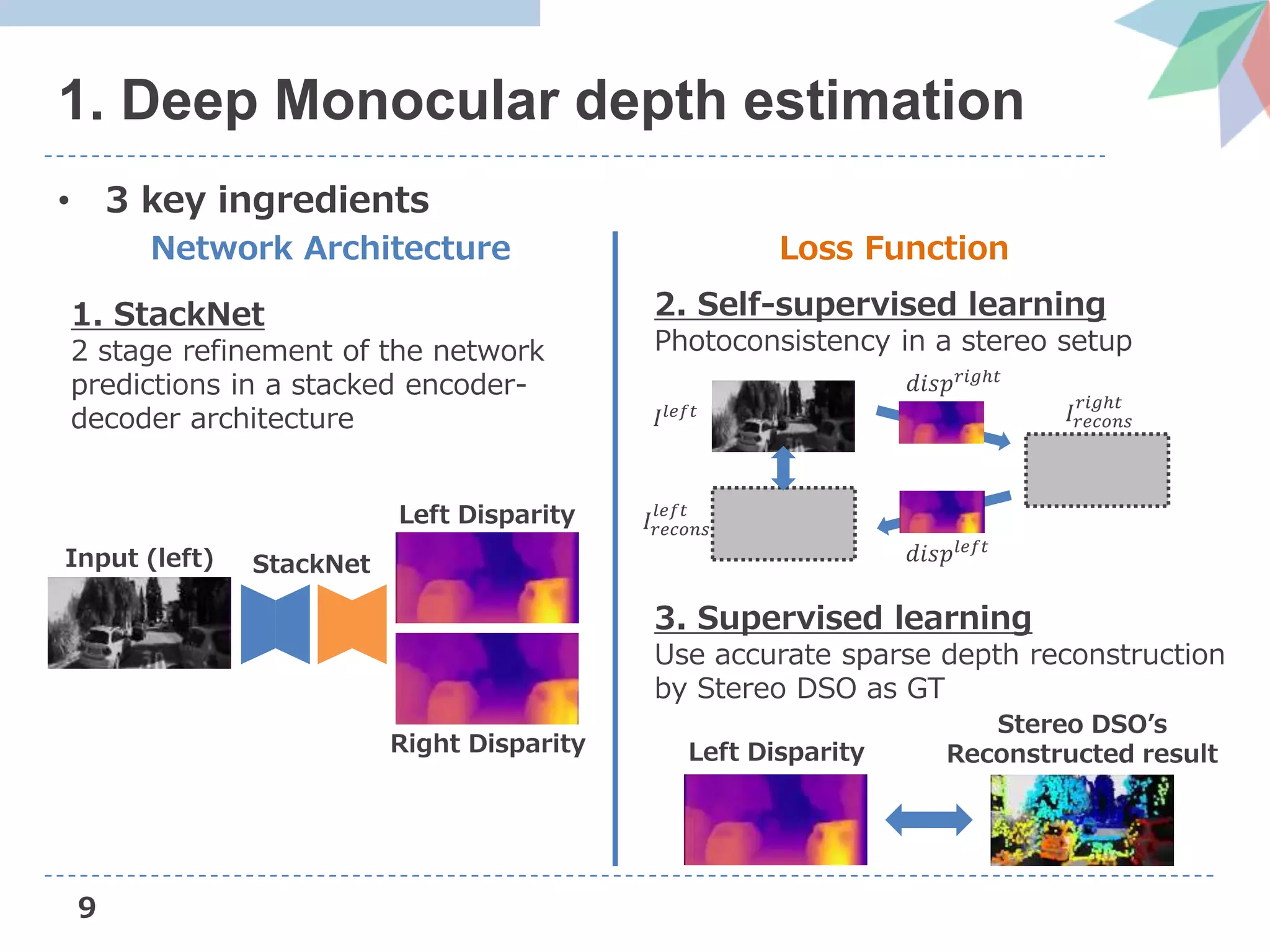
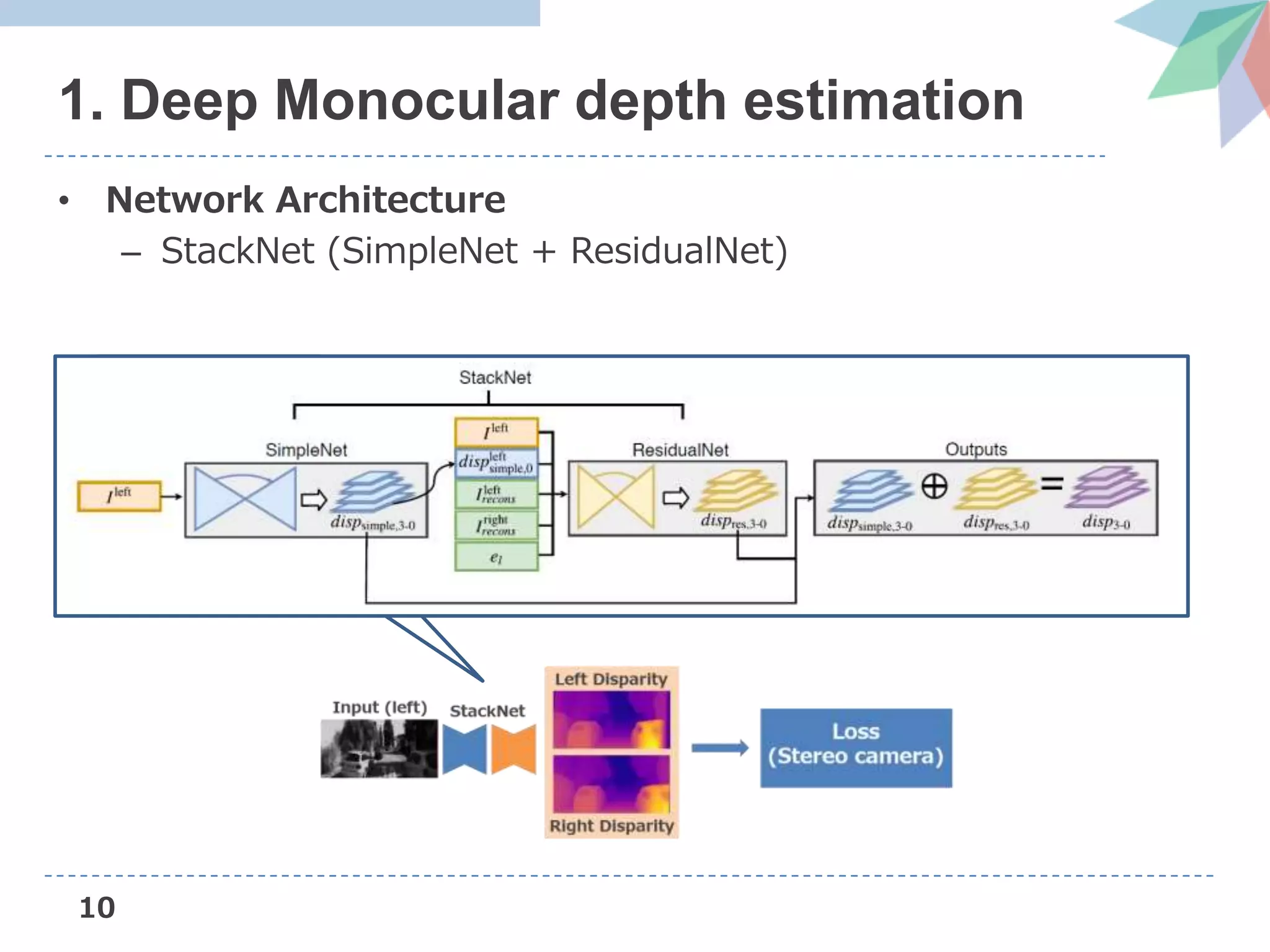
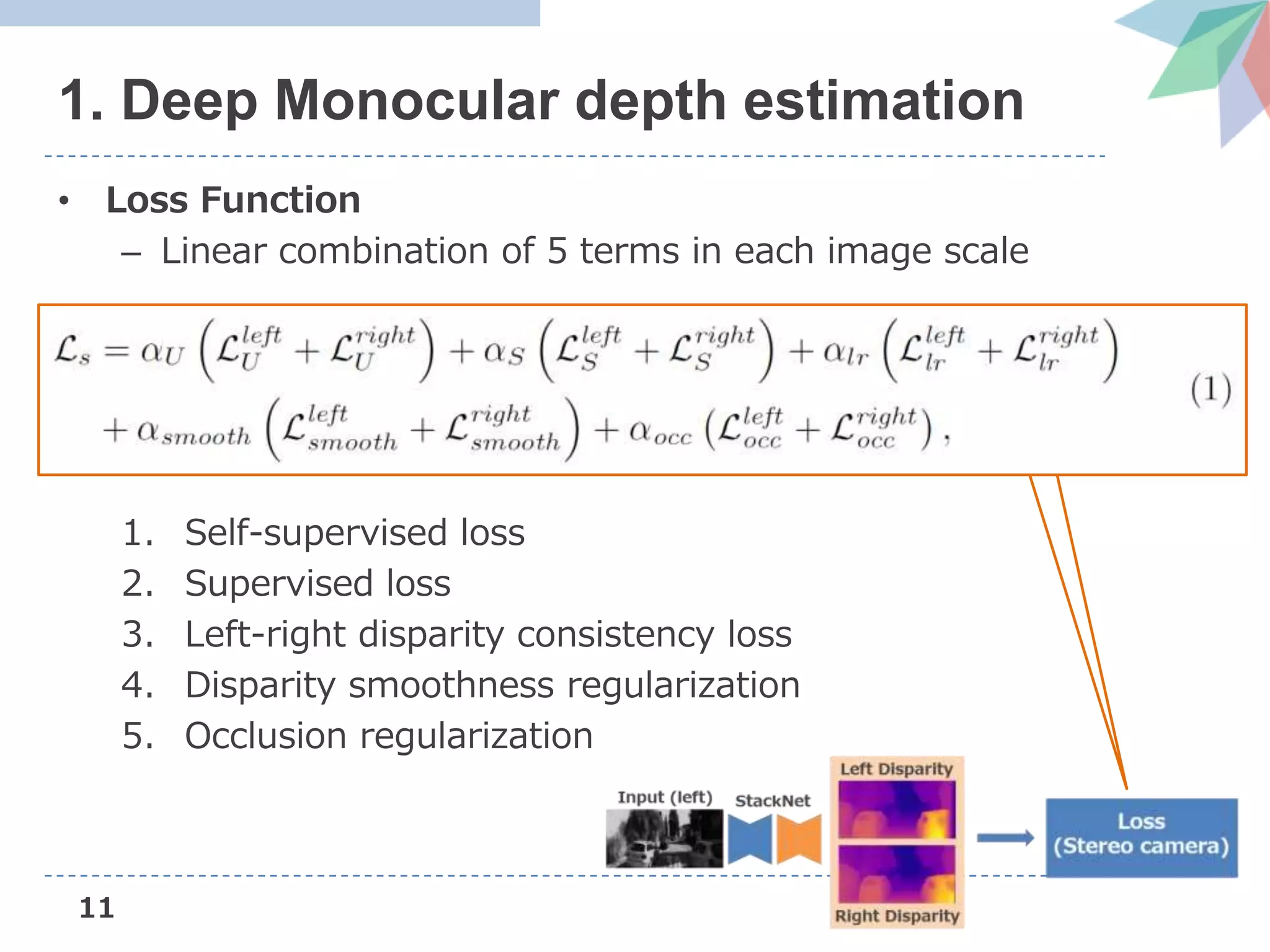
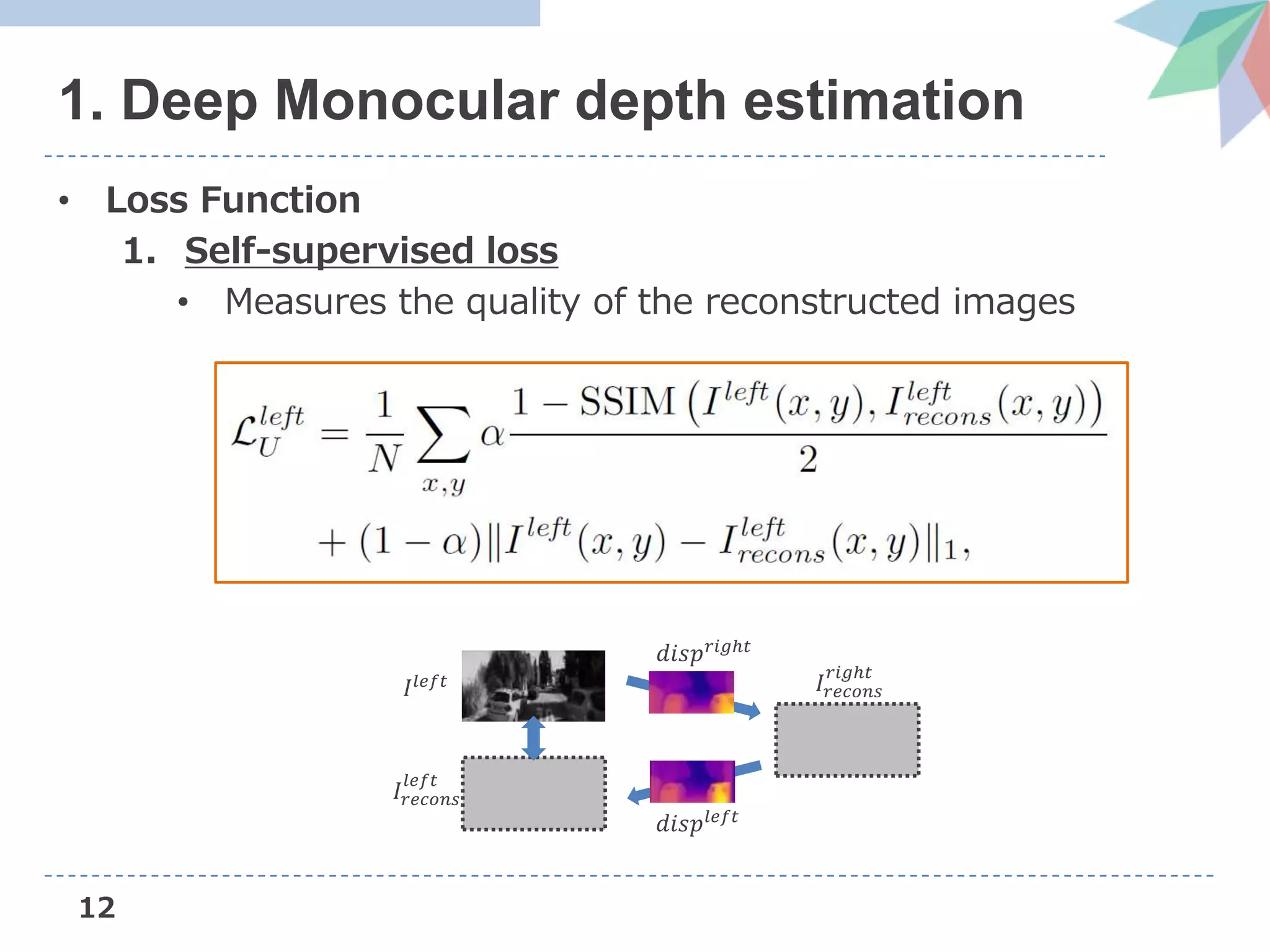
![13
1. Deep Monocular depth estimation
• Loss Function
2. Supervised loss
• Measures the deviation of the predicted disparity from
disparities estimated by Stereo DSO [Wang+, ICCV’17]
Left Disparity
Stereo DSO’s
Reconstructed result
Stereo DSO
(using Stereo camera)](https://image.slidesharecdn.com/dvsoslideshare-181104042256/75/AIST-Deep-Virtual-Stereo-Odometry-ECCV2018-14-2048.jpg)
![14
1. Deep Monocular depth estimation
• Loss Function
3. Left-right disparity consistency loss
• Consistency loss proposed in MonoDepth [Godard+, CVPR’17]
𝐼𝑙𝑒𝑓𝑡
𝑑𝑖𝑠𝑝𝑙𝑒𝑓𝑡 𝑑𝑖𝑠𝑝 𝑟𝑖𝑔ℎ𝑡
𝐼 𝑟𝑖𝑔ℎ𝑡
𝑑𝑖𝑠𝑝𝑙𝑒𝑓𝑡](https://image.slidesharecdn.com/dvsoslideshare-181104042256/75/AIST-Deep-Virtual-Stereo-Odometry-ECCV2018-15-2048.jpg)

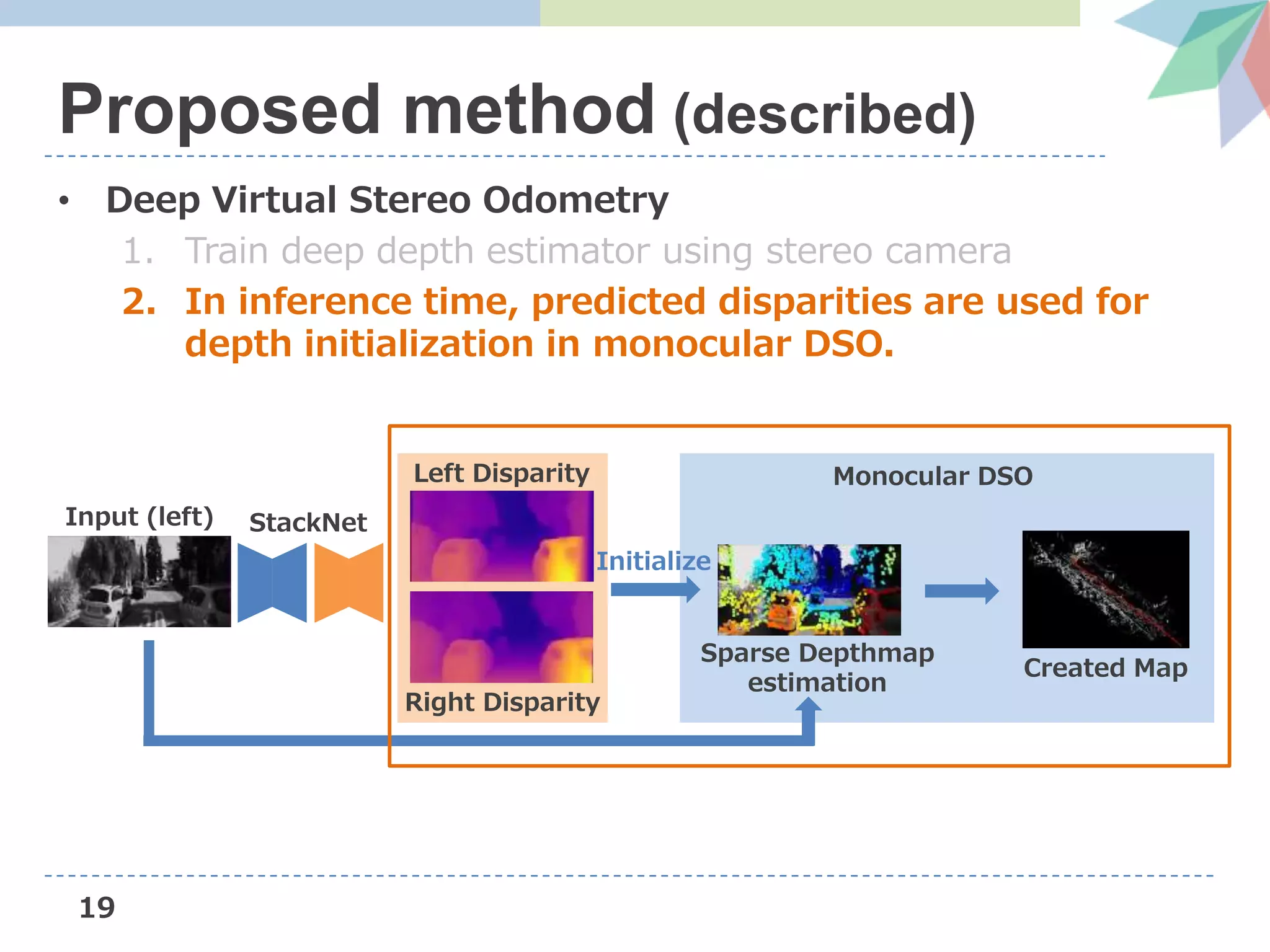
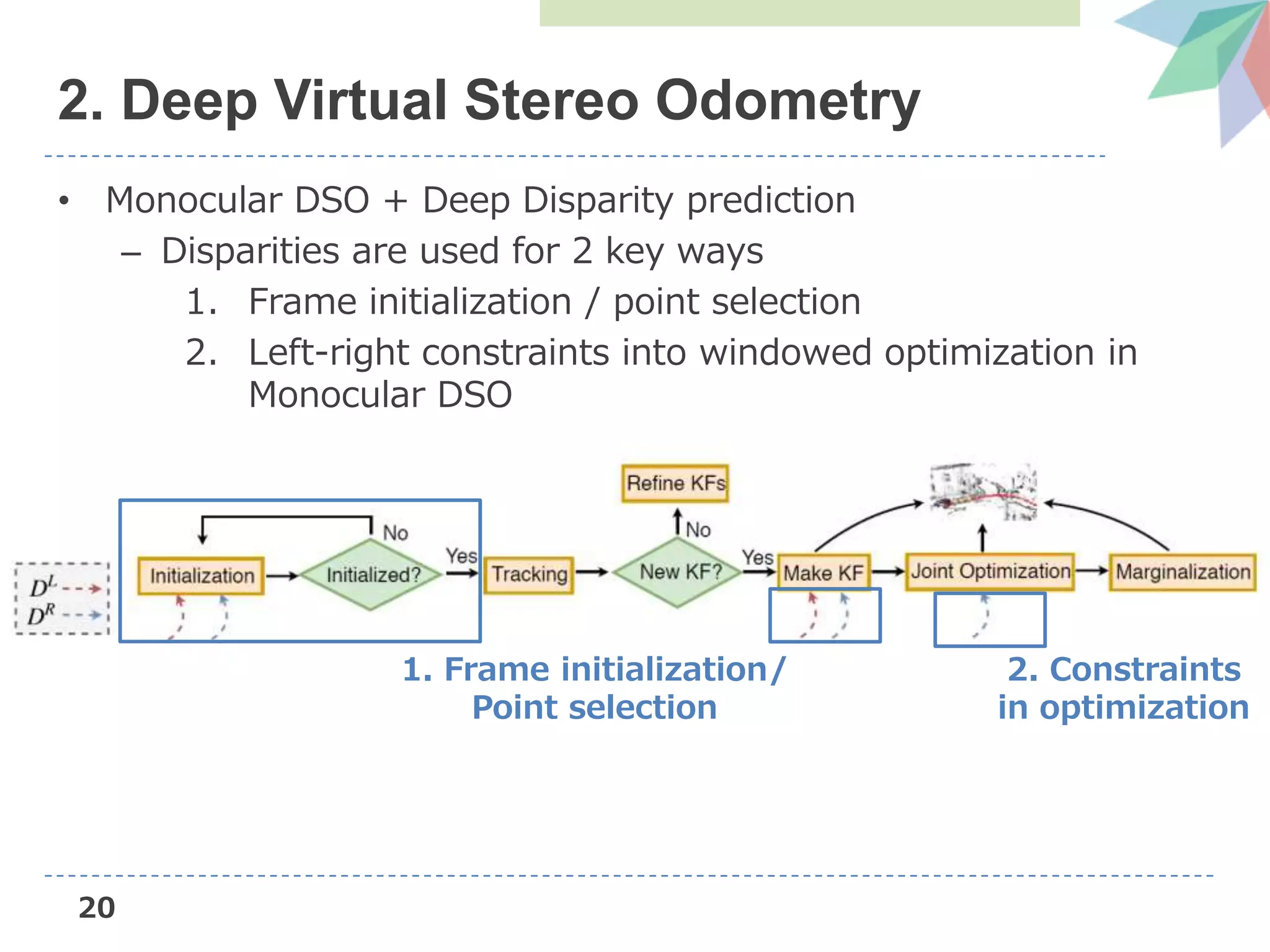
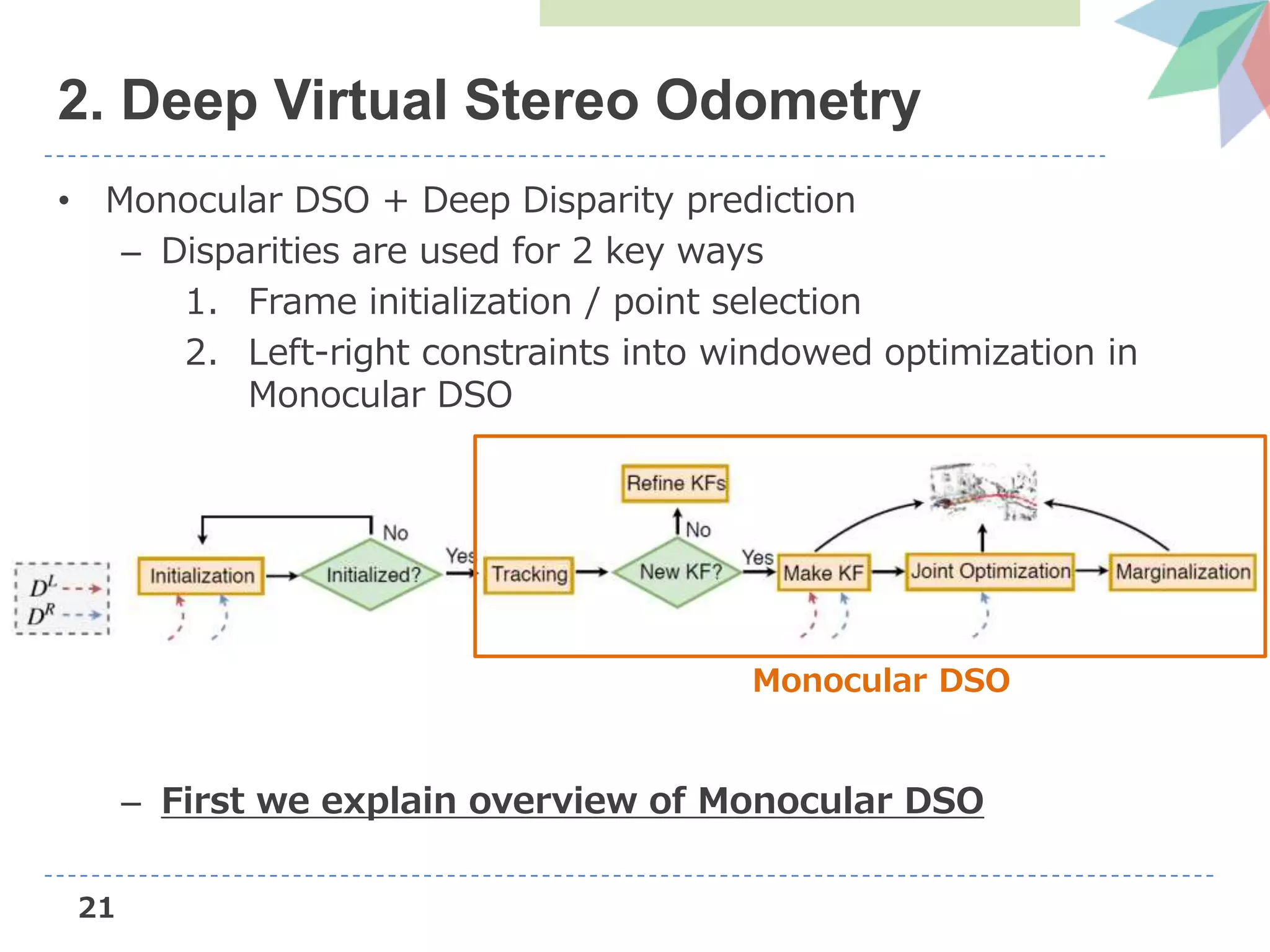
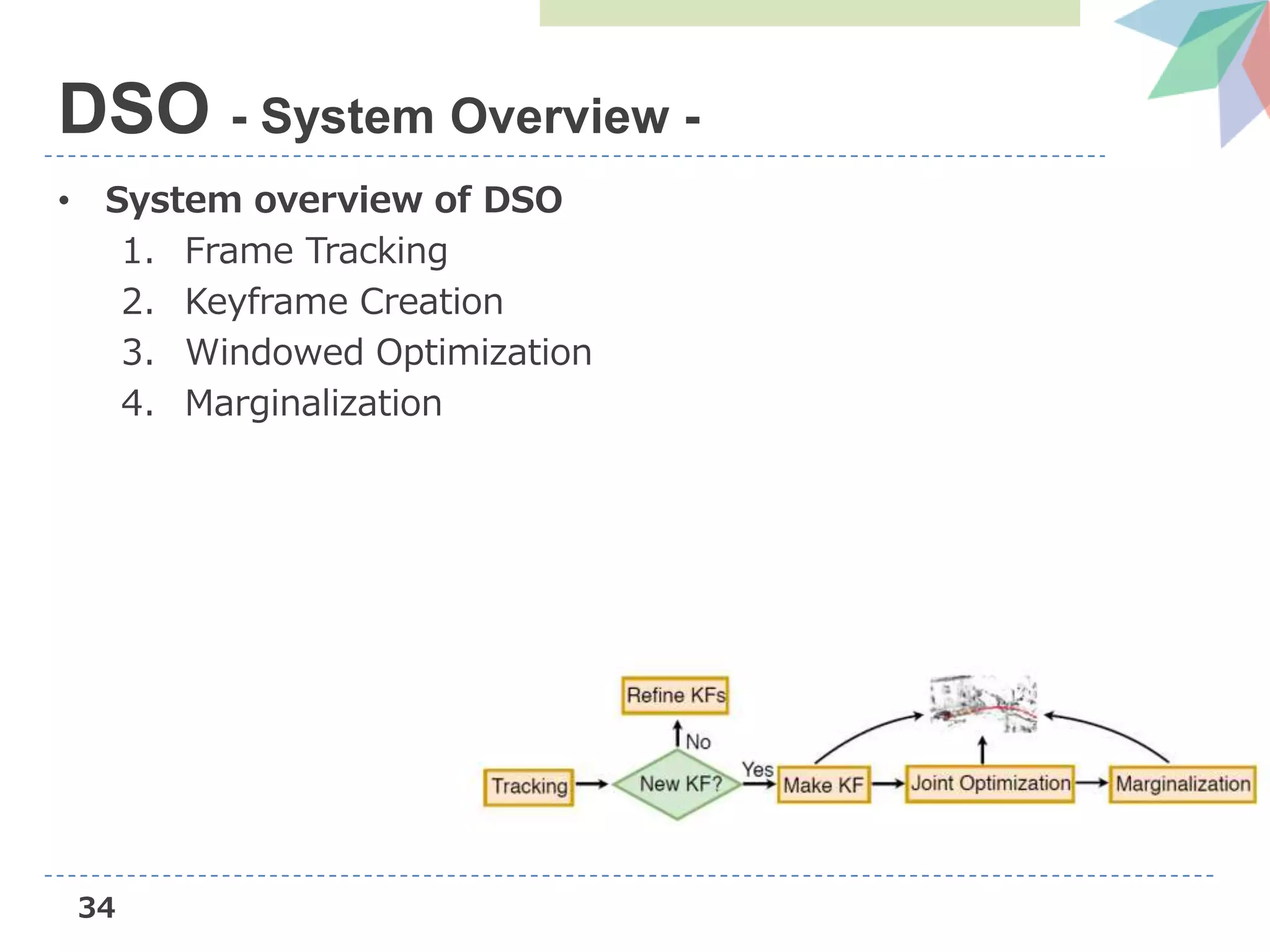
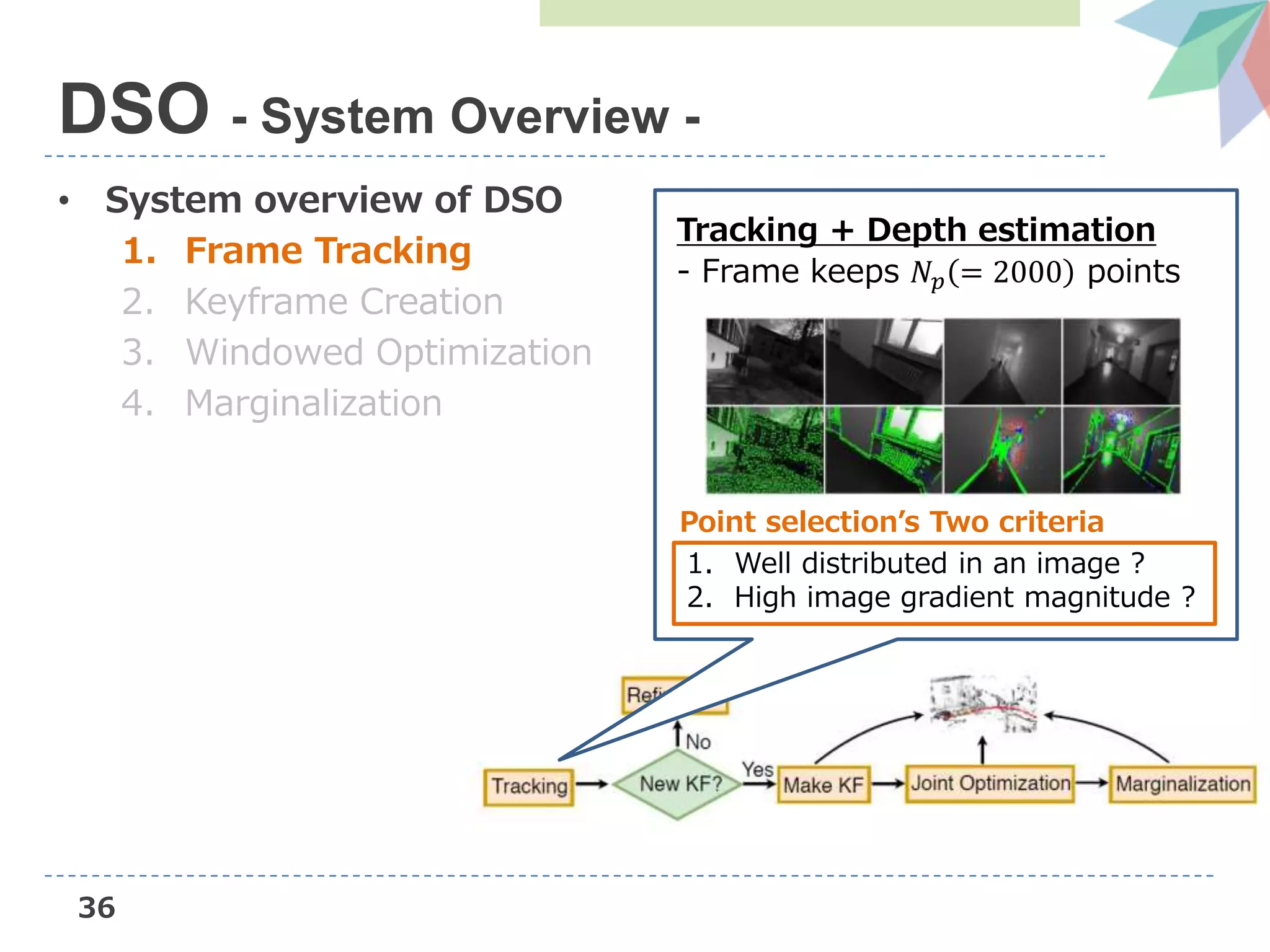
![22
DSO (Direct Sparse Odometry)
• Novel direct sparse Visual Odometry method
– Direct: seamless ability to use & reconstruct all points
instead of only corners
– Sparse: efficient, joint optimization of all parameters
Feature-based,
Sparse
Direct,
Semi-dense
Taking both approach’s benefits
[1] https://drive.google.com/file/d/108CttbYiBqaI3b1jIJFTS26SzNfQqQNG/view
LSD-SLAM [Engel+, ICCV’14] ORB-SLAM [Mur-Artal+, MVIGRO’14]](https://image.slidesharecdn.com/dvsoslideshare-181104042256/75/AIST-Deep-Virtual-Stereo-Odometry-ECCV2018-23-2048.jpg)
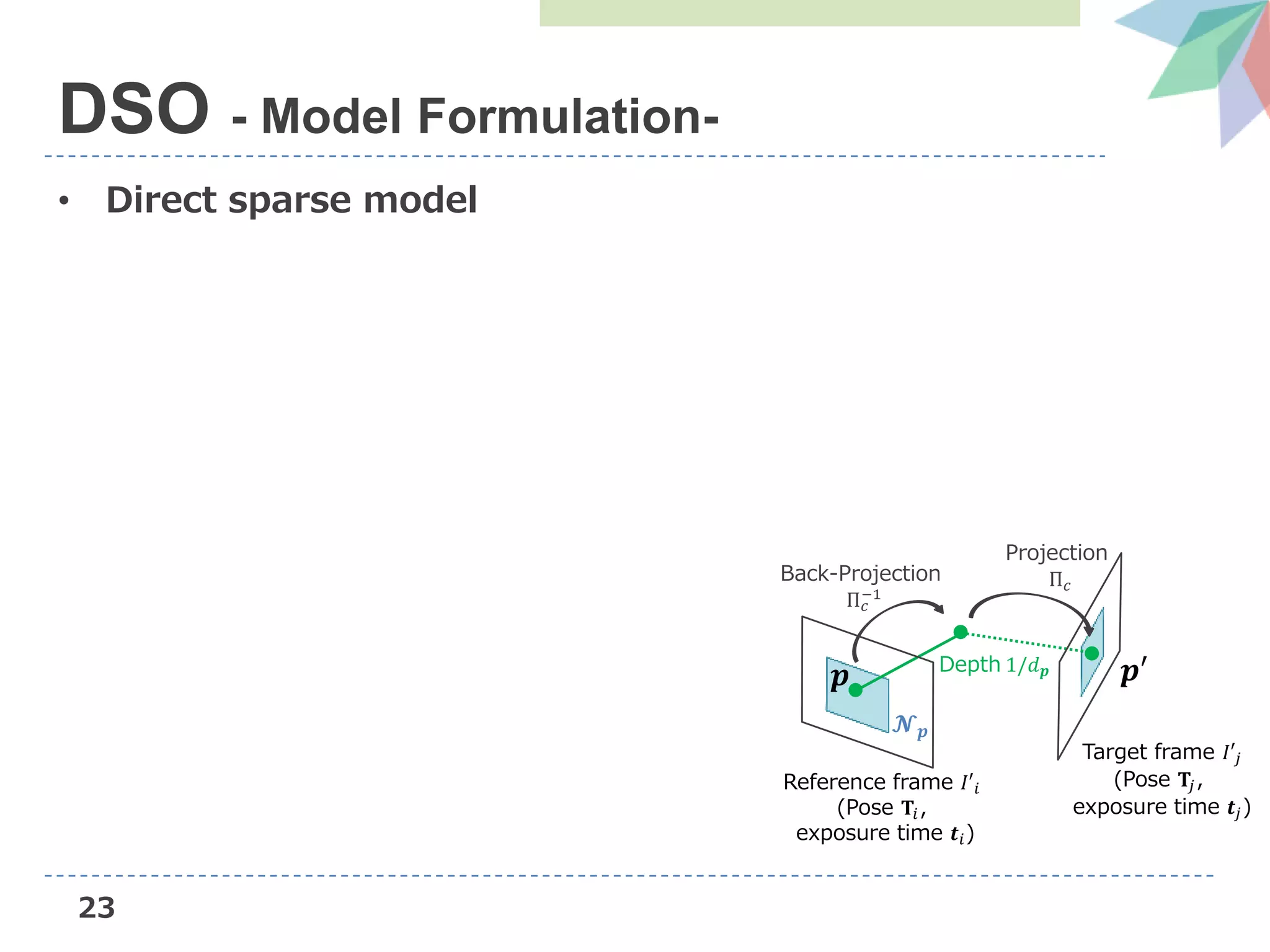
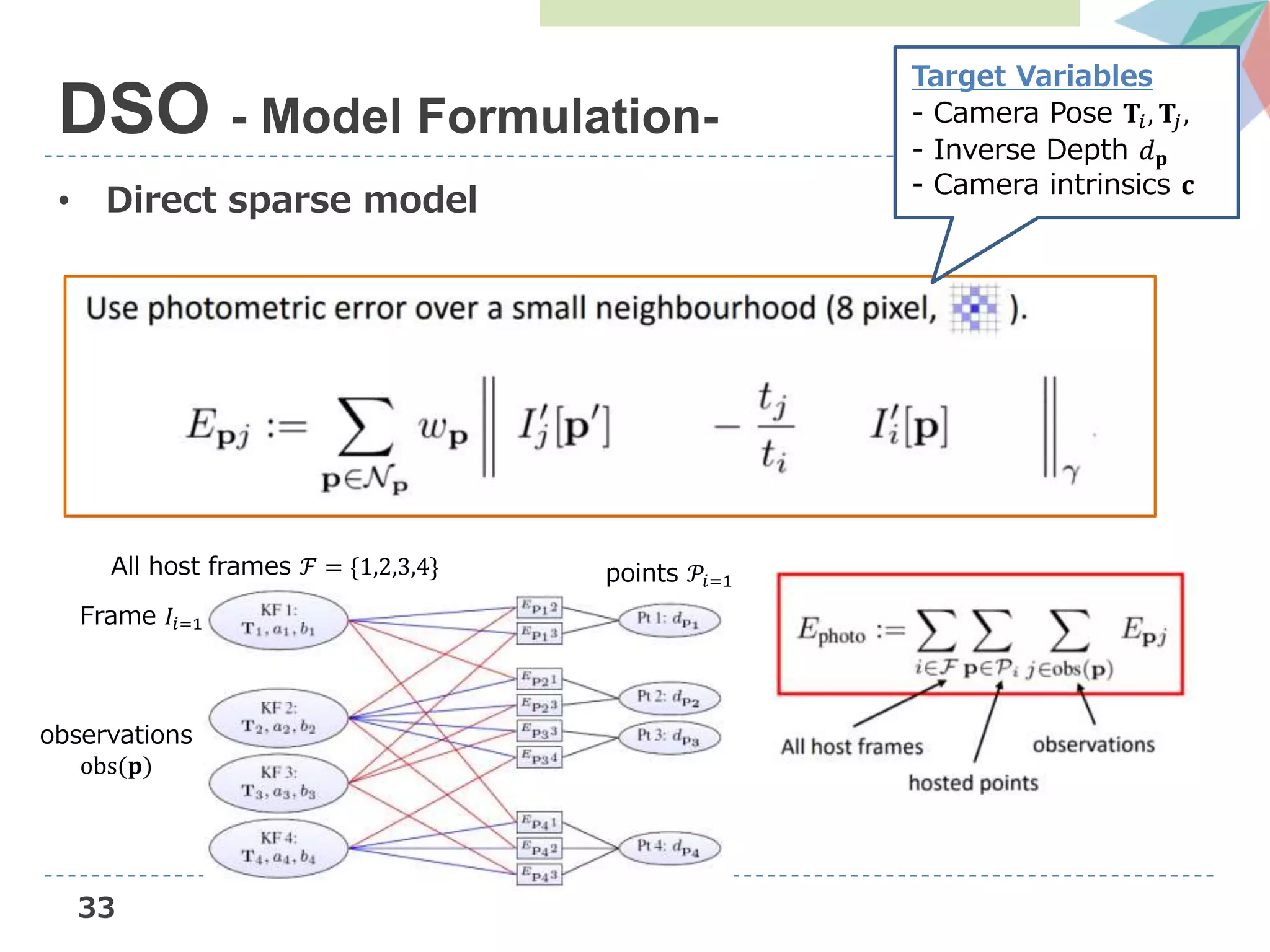
![24
• Direct sparse model
DSO - Model Formulation-
Target frame 𝐼′𝑗
(Pose 𝐓𝑗,
exposure time 𝒕𝑗)
𝒑
𝓝 𝒑
𝒑′Depth 1/𝑑 𝒑
Back-Projection
Π 𝑐
−1
Projection
Π 𝑐
Reference frame 𝐼′𝑖
(Pose 𝐓𝑖,
exposure time 𝒕𝑖)
𝓝 𝒑
[1] https://people.eecs.berkeley.edu/~chaene/cvpr17tut/SLAM.pdf](https://image.slidesharecdn.com/dvsoslideshare-181104042256/75/AIST-Deep-Virtual-Stereo-Odometry-ECCV2018-25-2048.jpg)
![25
• Direct sparse model
DSO - Model Formulation-
Target frame 𝐼′𝑗
(Pose 𝐓𝑗,
exposure time 𝒕𝑗)
𝒑
𝓝 𝒑
𝒑′Depth 1/𝑑 𝒑
Back-Projection
Π 𝑐
−1
Projection
Π 𝑐
Reference frame 𝐼′𝑖
(Pose 𝐓𝑖,
exposure time 𝒕𝑖)
𝓝 𝒑
Target Variables
- Camera Pose 𝐓𝑖, 𝐓𝑗,
- Inverse Depth 𝑑 𝐩
- Camera intrinsics 𝐜
[1] https://people.eecs.berkeley.edu/~chaene/cvpr17tut/SLAM.pdf](https://image.slidesharecdn.com/dvsoslideshare-181104042256/75/AIST-Deep-Virtual-Stereo-Odometry-ECCV2018-26-2048.jpg)
![26
• Direct sparse model
DSO - Model Formulation-
Target frame 𝐼′𝑗
(Pose 𝐓𝑗,
exposure time 𝒕𝑗)
𝒑
𝓝 𝒑
𝒑′Depth 1/𝑑 𝒑
Back-Projection
Π 𝑐
−1
Projection
Π 𝑐
Reference frame 𝐼′𝑖
(Pose 𝐓𝑖,
exposure time 𝒕𝑖)
𝓝 𝒑
Target Variables
- Camera Pose 𝐓𝑖, 𝐓𝑗,
- Inverse Depth 𝑑 𝐩
- Camera intrinsics 𝐜
Error between irradiance 𝑩 = 𝑰/𝒕
[1] https://people.eecs.berkeley.edu/~chaene/cvpr17tut/SLAM.pdf](https://image.slidesharecdn.com/dvsoslideshare-181104042256/75/AIST-Deep-Virtual-Stereo-Odometry-ECCV2018-27-2048.jpg)
![27
• Photometric calibration
– Feature-based method only focus on geometric calibration,
widely ignores this (features are invariant).
– In direct method, this calibration is very important!
DSO - Model Formulation-
Observed Pixel value 𝐼𝑖
[1] https://people.eecs.berkeley.edu/~chaene/cvpr17tut/SLAM.pdf](https://image.slidesharecdn.com/dvsoslideshare-181104042256/75/AIST-Deep-Virtual-Stereo-Odometry-ECCV2018-28-2048.jpg)


![30
• Direct sparse model
DSO - Model Formulation-
Target frame 𝐼′𝑗
(Pose 𝐓𝑗,
exposure time 𝒕𝑗)
𝒑
𝓝 𝒑
𝒑′Depth 1/𝑑 𝒑
Back-Projection
Π 𝑐
−1
Projection
Π 𝑐
Reference frame 𝐼′𝑖
(Pose 𝐓𝑖,
exposure time 𝒕𝑖)
𝓝 𝒑
Error between irradiance 𝑩 = 𝑰/𝒕
[1] https://people.eecs.berkeley.edu/~chaene/cvpr17tut/SLAM.pdf](https://image.slidesharecdn.com/dvsoslideshare-181104042256/75/AIST-Deep-Virtual-Stereo-Odometry-ECCV2018-31-2048.jpg)
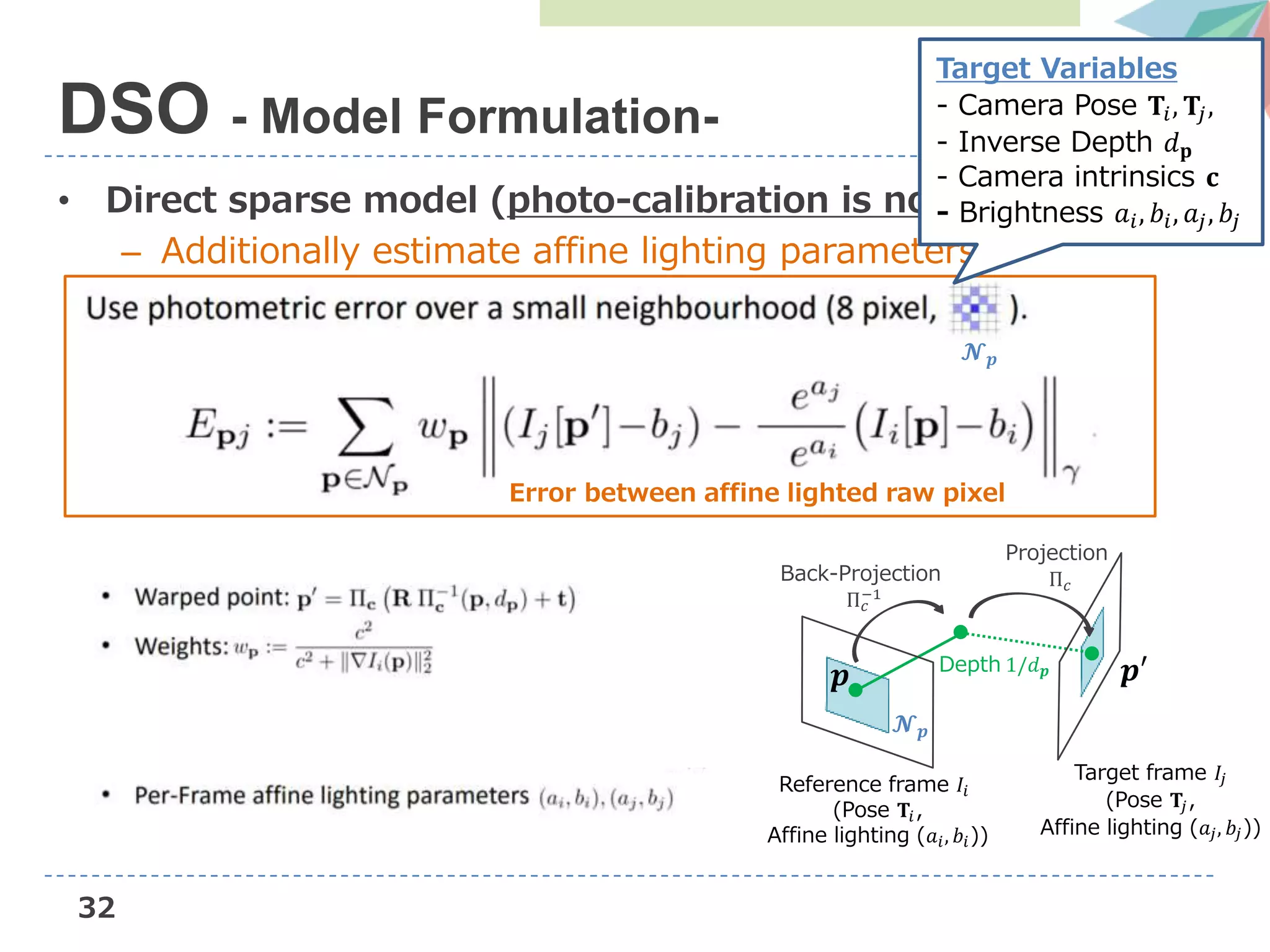
![31
• Direct sparse model (photo-calibration is not available)
– Additionally estimate affine lighting parameters
DSO - Model Formulation-
Reference frame 𝐼𝑖
(Pose 𝐓𝑖,
Affine lighting (𝑎𝑖, 𝑏𝑖))
Target frame 𝐼𝑗
(Pose 𝐓𝑗,
Affine lighting (𝑎𝑗, 𝑏𝑗))
𝒑
𝓝 𝒑
𝒑′Depth 1/𝑑 𝒑
Back-Projection
Π 𝑐
−1
Projection
Π 𝑐
𝓝 𝒑
Error between affine lighted raw pixel
[1] https://people.eecs.berkeley.edu/~chaene/cvpr17tut/SLAM.pdf](https://image.slidesharecdn.com/dvsoslideshare-181104042256/75/AIST-Deep-Virtual-Stereo-Odometry-ECCV2018-32-2048.jpg)









![[DL輪読会]A closer look at few shot classification](https://cdn.slidesharecdn.com/ss_thumbnails/acloserlookatfew-shotclassification-190304034759-thumbnail.jpg?width=640&height=640&fit=bounds)



![[DL輪読会]Swin Transformer: Hierarchical Vision Transformer using Shifted Windows](https://cdn.slidesharecdn.com/ss_thumbnails/swintransformer-210514020542-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]MetaFormer is Actually What You Need for Vision](https://cdn.slidesharecdn.com/ss_thumbnails/20220121metaformer-220121085750-thumbnail.jpg?width=640&height=640&fit=bounds)





![[DL輪読会]Neural Radiance Flow for 4D View Synthesis and Video Processing (NeRF...](https://cdn.slidesharecdn.com/ss_thumbnails/20210806journalclub-210806023711-thumbnail.jpg?width=640&height=640&fit=bounds)



![[DL輪読会]Pyramid Stereo Matching Network](https://cdn.slidesharecdn.com/ss_thumbnails/2019-05-31psmnetpyramidstereomatchingnetwork-hiroakisugisaki-190531000258-thumbnail.jpg?width=640&height=640&fit=bounds)























































