Downloaded 1,670 times
![SSD: Single Shot MultiBox Detector
Wei Liu, Dragomir Anguelov, Dumitru Erhan, Christian Szegedy, Scott Reed,
Cheng-Yang Fu, Alexander C.Berg
[arXiv][demo][code] (Mar 2016)
Slides by Míriam Bellver
Computer Vision Reading Group, UPC
28th October, 2016](https://image.slidesharecdn.com/05-singleshotmultiboxdetector-161028144820/85/SSD-Single-Shot-MultiBox-Detector-UPC-Reading-Group-1-320.jpg)
![SSD: Single Shot MultiBox Detector
Wei Liu, Dragomir Anguelov, Dumitru Erhan, Christian Szegedy, Scott Reed,
Cheng-Yang Fu, Alexander C.Berg
[arXiv][demo][code] (Mar 2016)
Slides by Míriam Bellver
Computer Vision Reading Group, UPC
28th October, 2016](https://image.slidesharecdn.com/05-singleshotmultiboxdetector-161028144820/75/SSD-Single-Shot-MultiBox-Detector-UPC-Reading-Group-1-2048.jpg)







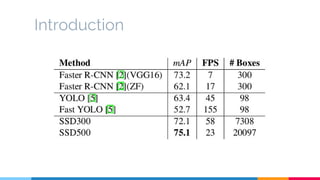



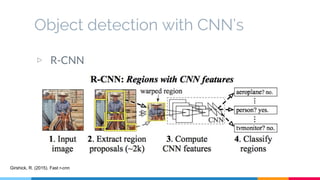
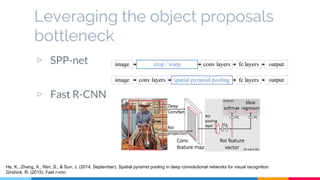




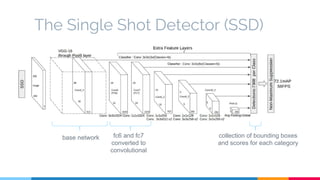
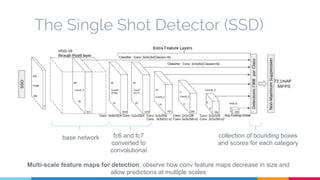
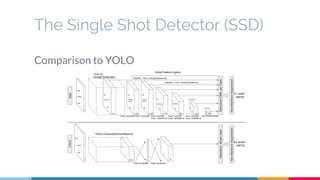
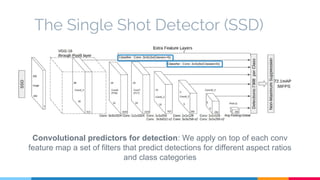






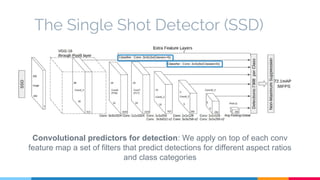
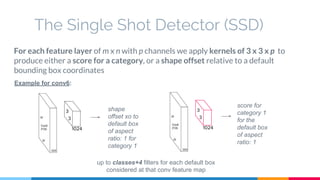












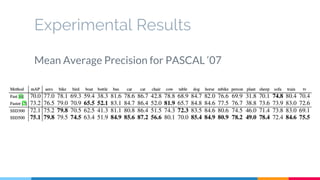

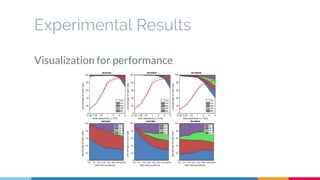


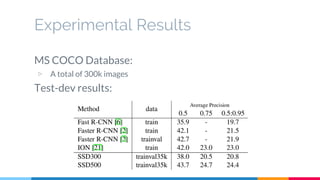
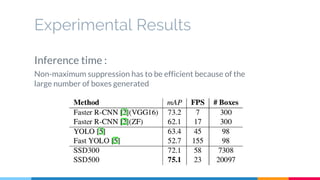





The SSD (Single Shot Multibox Detector) is a novel deep learning-based object detection framework that predicts object boxes and category scores in a single forward pass of the network, significantly improving speed while maintaining accuracy compared to previous methods like Faster R-CNN and YOLO. It utilizes small convolutional filters applied to different scaled feature maps to enhance detection of various object sizes and aspect ratios. The experimental results affirm SSD's efficiency and precision, marking it as a strong contender in real-time object detection applications.












![[PR12] You Only Look Once (YOLO): Unified Real-Time Object Detection](https://cdn.slidesharecdn.com/ss_thumbnails/yolo-170616085751-thumbnail.jpg?width=640&height=640&fit=bounds)
































































![제 23회 보아즈(BOAZ) 빅데이터 컨퍼런스 - [MBOAX] : ABSA를 활용한 소비자 반응 분석 기반 운영 효율화 대시보드 설계](https://cdn.slidesharecdn.com/ss_thumbnails/3-1boaz23rdconferencemboax-260203102709-9d519923-thumbnail.jpg?width=640&height=640&fit=bounds)

















