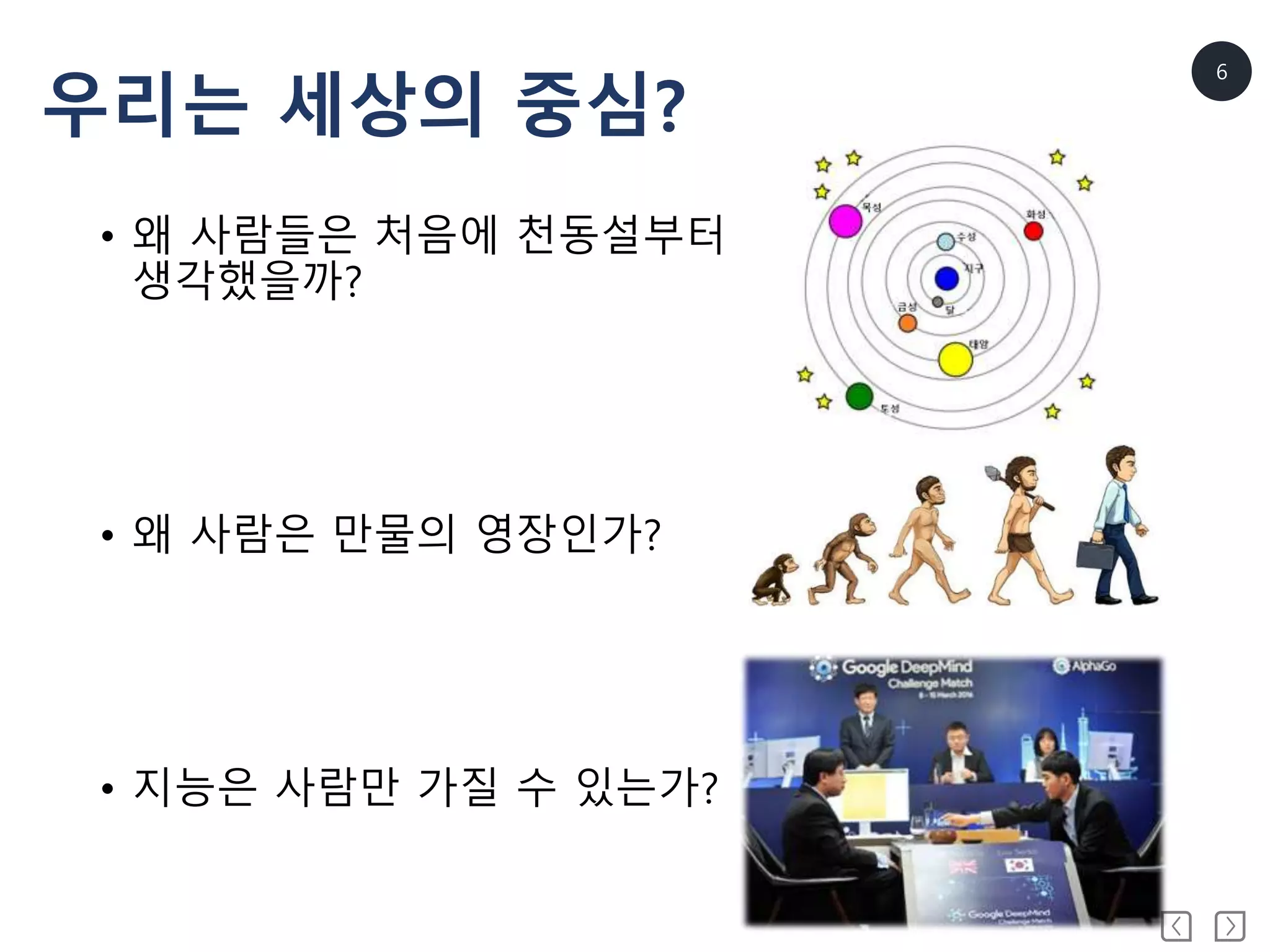
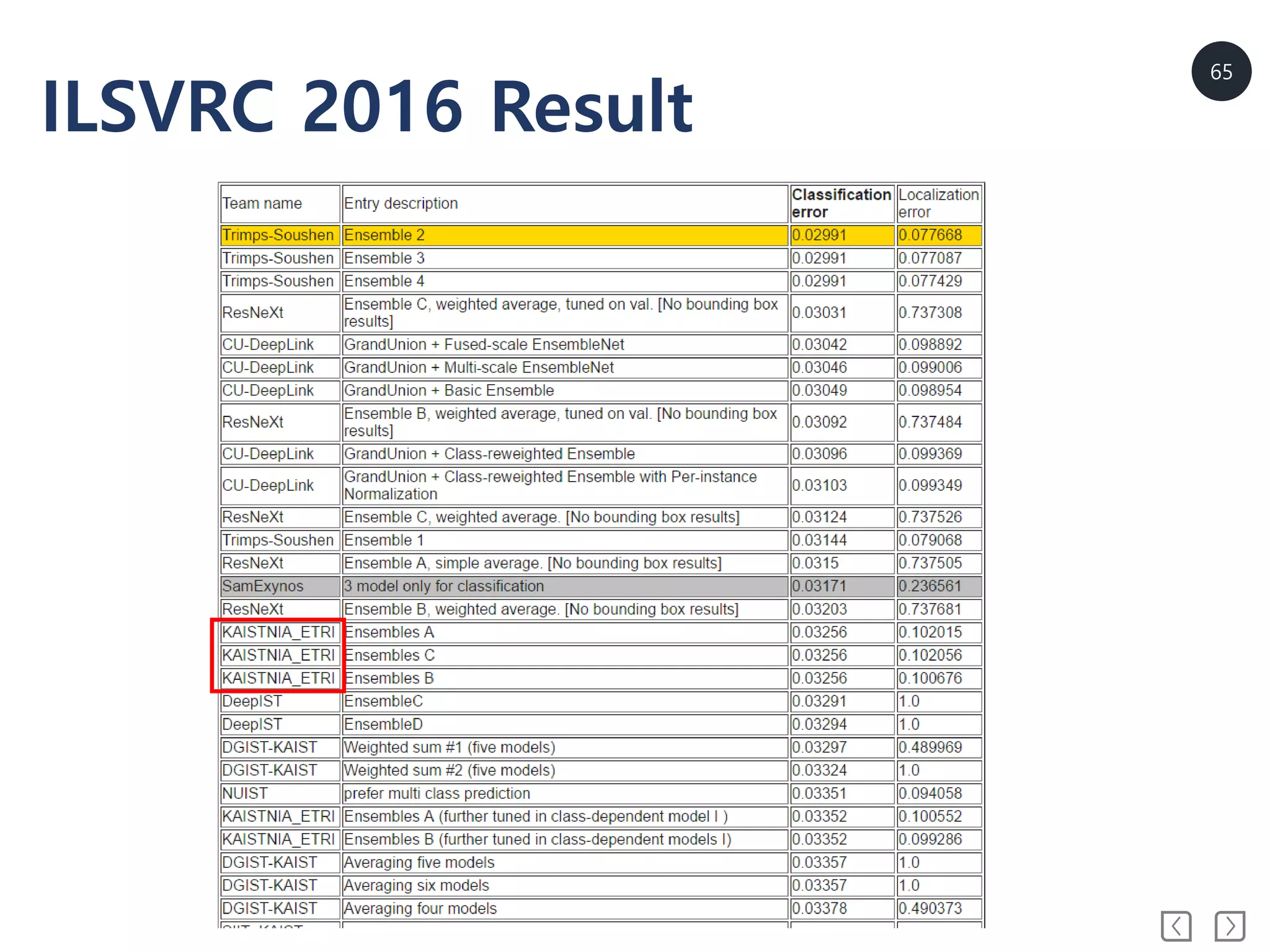
9
인공지능(Artificial Intelligence)
• 1956년다트머스 회의에서 처음 사용
• From Wikipedia:
Artificial intelligence (AI) is intelligence exhibited
by machines. In computer science, an ideal "intelligent"
machine is a flexible rational agent that perceives its
environment and takes actions that maximize its chance
of success at some goal
AI Translation:
인공 지능 (AI)은 기계가 나타내는 지능입니다. 컴퓨터 과학
에서 이상적인 "지능형"기계는 환경을 인식하고 목표 달
성의 기회를 극대화하는 유연하고 합리적인 에이전트입니다.
14
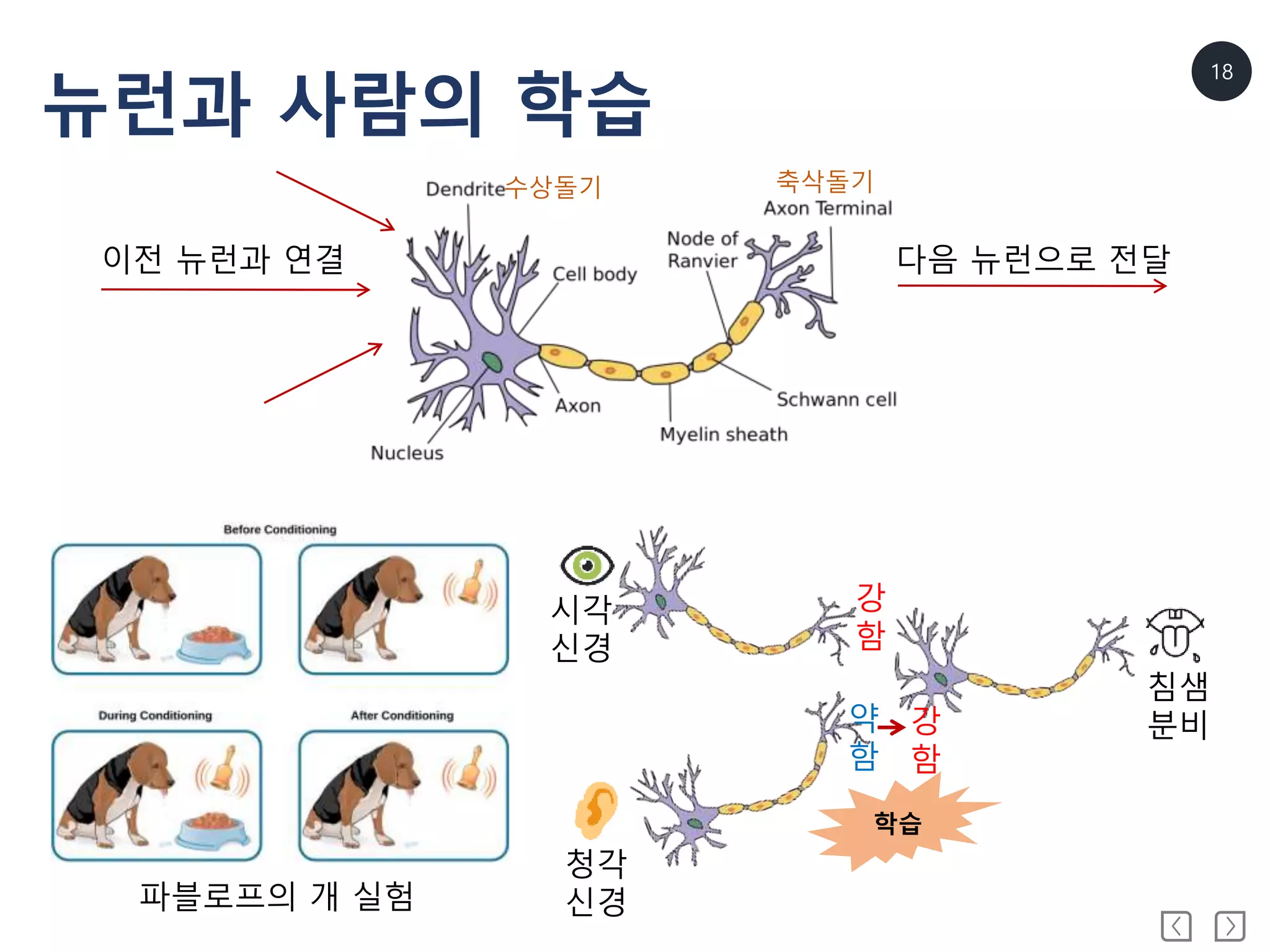
기계학습(Machine Learning)
• 기계학습(MachineLearning)
Machine learning is the subfield of computer science that
"gives computers the ability to learn without being explicitly
programmed“
기계 학습은 "컴퓨터에 명시적으로 프로그래밍하지 않고 학습 할
수 있는 능력을 부여하는“ 컴퓨터 과학의 하위 분야입니다.
Computer
inputs
program
outputs
Computer
inputs
outputs
program
일반적인 programming
기계학습
기계가 program을 직접 작성!
15.
15
Quiz
• □와 △에들어갈 정수는?
3 x □ + 2 x △ = 1
1 x □ + 4 x △ = -3
5 x □ + 5 x △ = 0
8 x □ + 3 x △ = 5
• □ = 1, △ = -1
• (3, 2), (1, 4), (5, 5), (8, 3) 은 input data, 1, -3, 0, 5 는 label
이다
• □와 △를 weight라고 하며 이 weight 값을 기계가 스스로
학습을 통해 찾아내도록 하는 것이 기계학습이 하는 일
16.
16
기계학습의 종류
• SupervisedLearning(지도학습)
Input 과 labels을 이용한 학습
분류(classification), 회귀(regression)
• Unsupervised Learning(비지도학습)
Input만을 이용한 학습
군집화(clustering), 압축(compression)
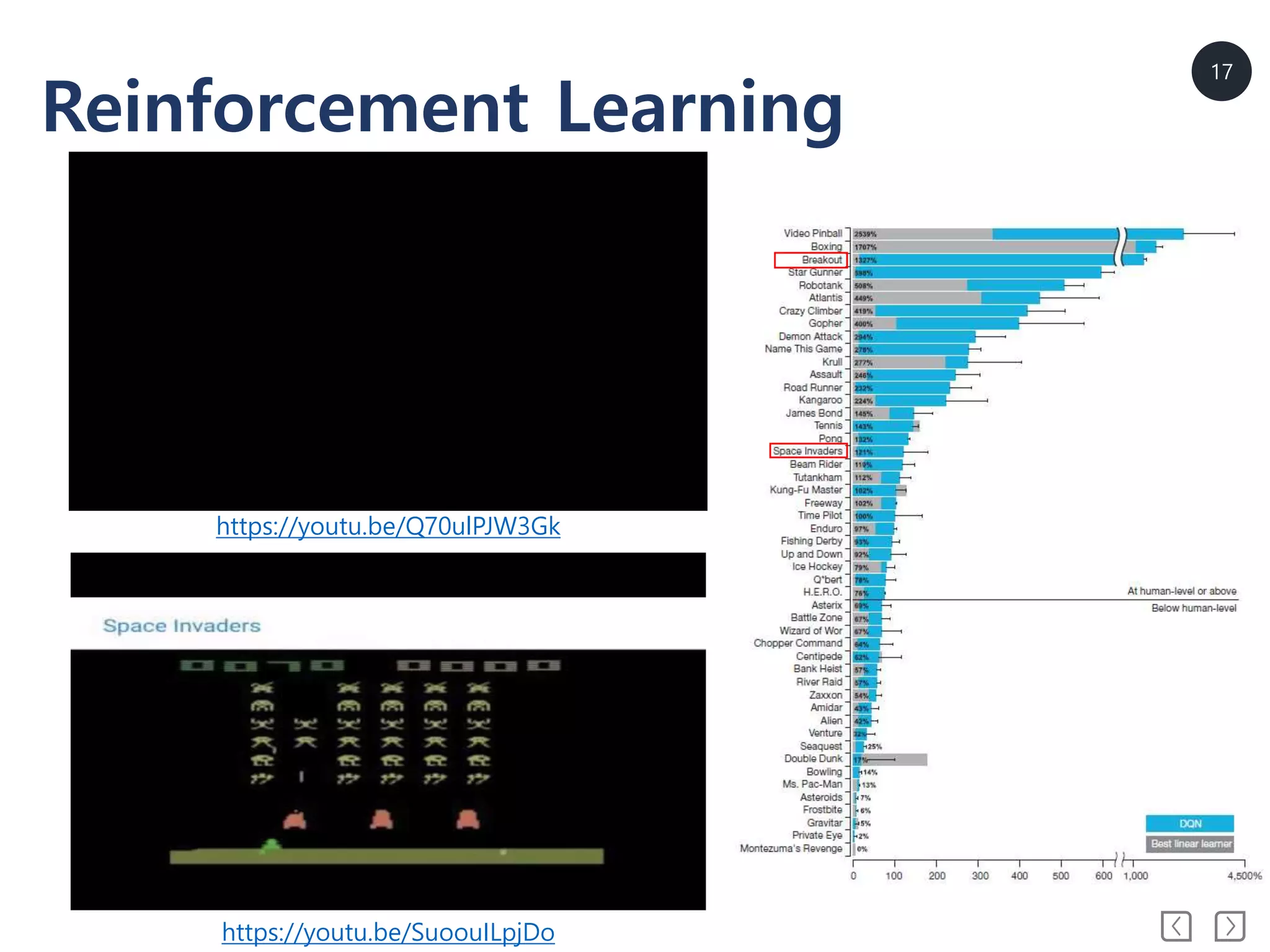
• Reinforcement Learning(강화학습)
Label 대신 reward가 주어짐
Action selection, policy learning
20
Example of ANN(logicalAND)
0
1
1
ℎ 𝑥 = 0
ℎ 𝑥 =1
𝑥1
𝑥2
학습이란 이러한 weight 값(-30, 20, 20)을
기계 스스로 찾을 수 있도록 해주는 과정!
21.
21
아파트 가격 예측(Regression)
•아파트 가격을 예측하는 프로그램을 작성해보자
평수(평)
층수(층)
가장 가까운 지하철 역까지의 거리(km)
해당 지역의 1인당 소득 평균(천만원)
평수 층수
지하철
역까지의 거리
(km)
해당지역
1인당 소득
(천만원)
아파트가격
(천만원)
34 15 1 4 72
32 4 5 3.3 60
18 9 2 2.5 34
42 3 2.5 5 100
21 10 1.5 3 42
22.
22
일반적인 방법
• 기존의data와 경험을 바탕으로 한 정보
평수는 클수록 비싸다
층수는 높은 층이 낮은 층보다 비싸다
지하철 역까지의 거리는 가까울수록 비싸다
그 지역의 소득수준이 높을수록 비싸다
• 위 정보들 간의 중요도에 따라 가중치를 주어서 최종 가격
을 추론한다
평수가 가장 중요함
층 수는 평수에 비해서 덜 중요함
지하철 역까지의 거리는 중요하지만 거리값이 작을수록 가격이 비
싸짐
그 지역의 소득수준은 아파트 가격 결정에 가장 덜 중요함 등
• 예) 평수 x 2 + 층수 x 0.3 + 지하철 역까지 거리 x (-1) + 소득
수준 x 0.1 = 아파트 가격(천만원)
23.
23
기계학습을 이용하는 방법
•기존의 data를 이용하여 각 항목별로 □,△,○,☆에 들어갈 값을
기계 스스로 학습하게 한다.
평수 x □ + 층수 x △ + 지하철 역까지 거리 x ○ + 소득수준 x ☆
= 아파트 가격(천만원)
• 어떻게?
맨 처음 □,△,○,☆ 값을 random으로 정한 후 실제 가격과 비교하여
그 (차이값)2의 평균 계산한다
□,△,○,☆를 모두 1로 했을 경우, (실제가격 – 추론가격)2 의 평균 = 287.524
이제 □,△,○,☆를 기계 스스로 조금씩 조정하여 (차이값)2의 평균이 0
이 되게 할 수 있다면, 프로그램이 완성된다
평수 층수
지하철
역까지의 거리
(km)
해당지역
1인당 소득
(천만원)
아파트가격
(천만원)
추론한
아파트 가격
(천만원)
34 15 1 4 72 54
32 4 5 3.3 60 44.3
18 9 2 2.5 34 31.5
42 3 2.5 5 100 52.5
21 10 1.5 3 42 35.5
24.
24
Multi Layer Perceptron(MLP)
•아파트 가격 결정에 소득수준이 높은 지역에서는 낮은 지역보다
지하철 역까지의 거리가 덜 중요하다면?
• 아파트 가격을 우선 여러가지로 예측하고 그 예측한 값들을 다시
잘 조합하여 더 잘 예측해보자(regression)
• 선을 잘 긋고 input 공간을 잘 왜곡하고 합하는 과정을 반복해서
데이터들을 잘 구분해보자(classification)
• 이렇게 perceptron을 여러층으로 쌓으면 더 복잡한 문제를 풀 수
있다
• Linear fitting과 Non-linear transform의 반복
26
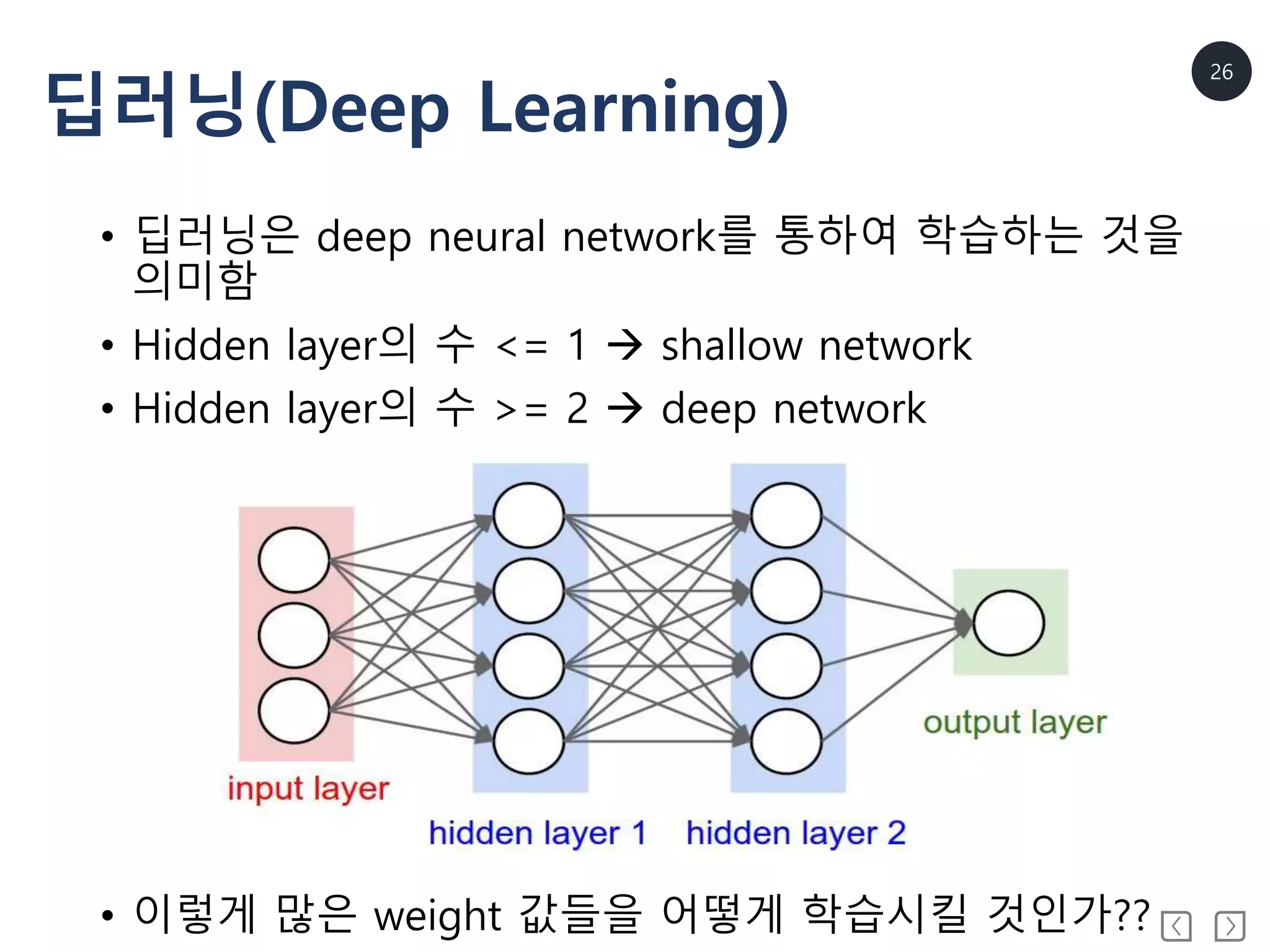
딥러닝(Deep Learning)
• 딥러닝은deep neural network를 통하여 학습하는 것을
의미함
• Hidden layer의 수 <= 1 shallow network
• Hidden layer의 수 >= 2 deep network
• 이렇게 많은 weight 값들을 어떻게 학습시킬 것인가??
27.
27
Back Propagation
• 학습과정: back propagation of error
Output layer에서 error(cost)를 계산
Error의 미분값을 back propagation
미분값에 𝛼를 곱한 만큼 w를 보정(학습!)
𝛼는 learning rate를 의미함
gradient descent
28.
28
딥러닝을 어렵게 하는것들
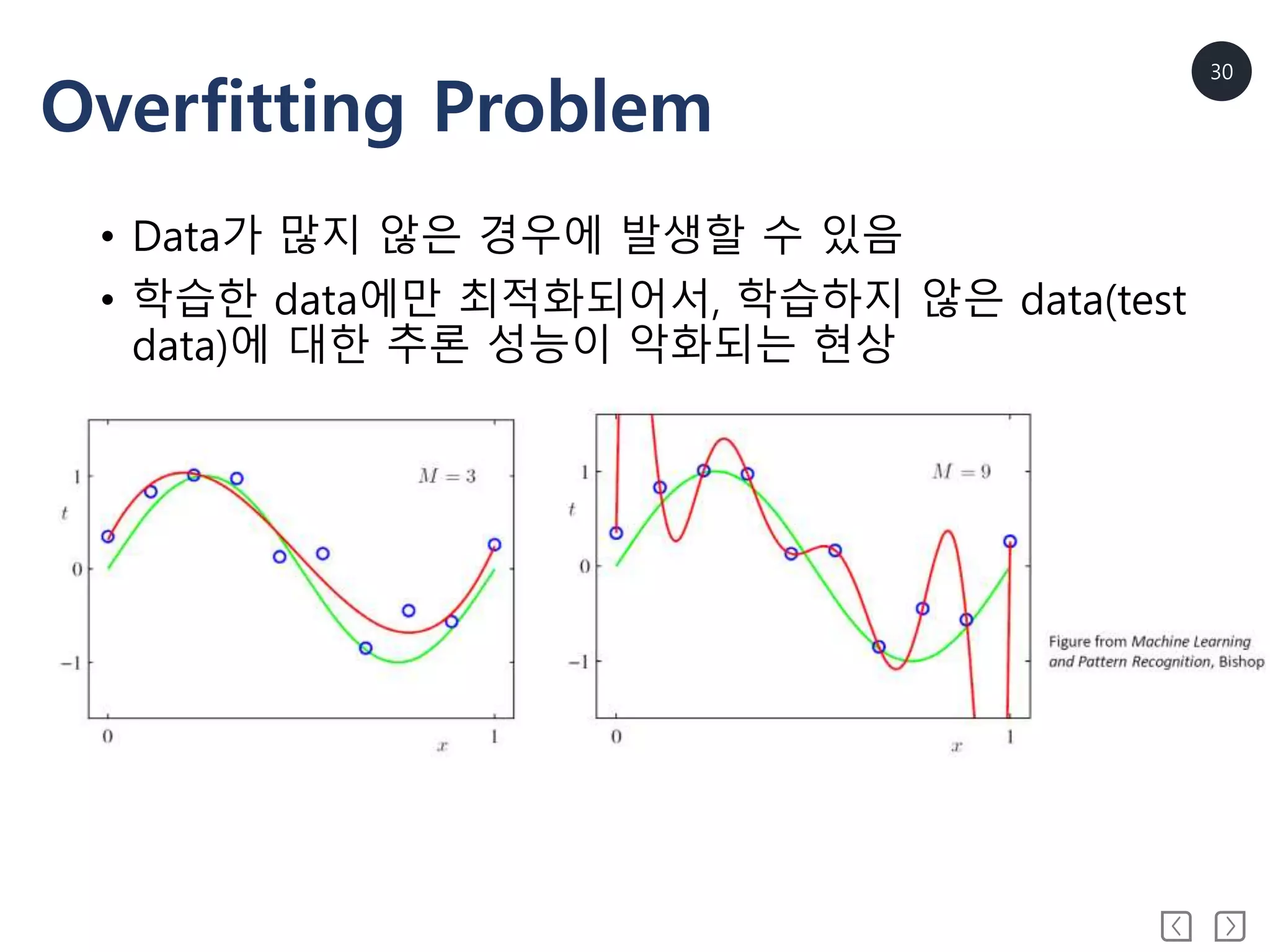
• Vanishing gradient problem
• Overfitting problem
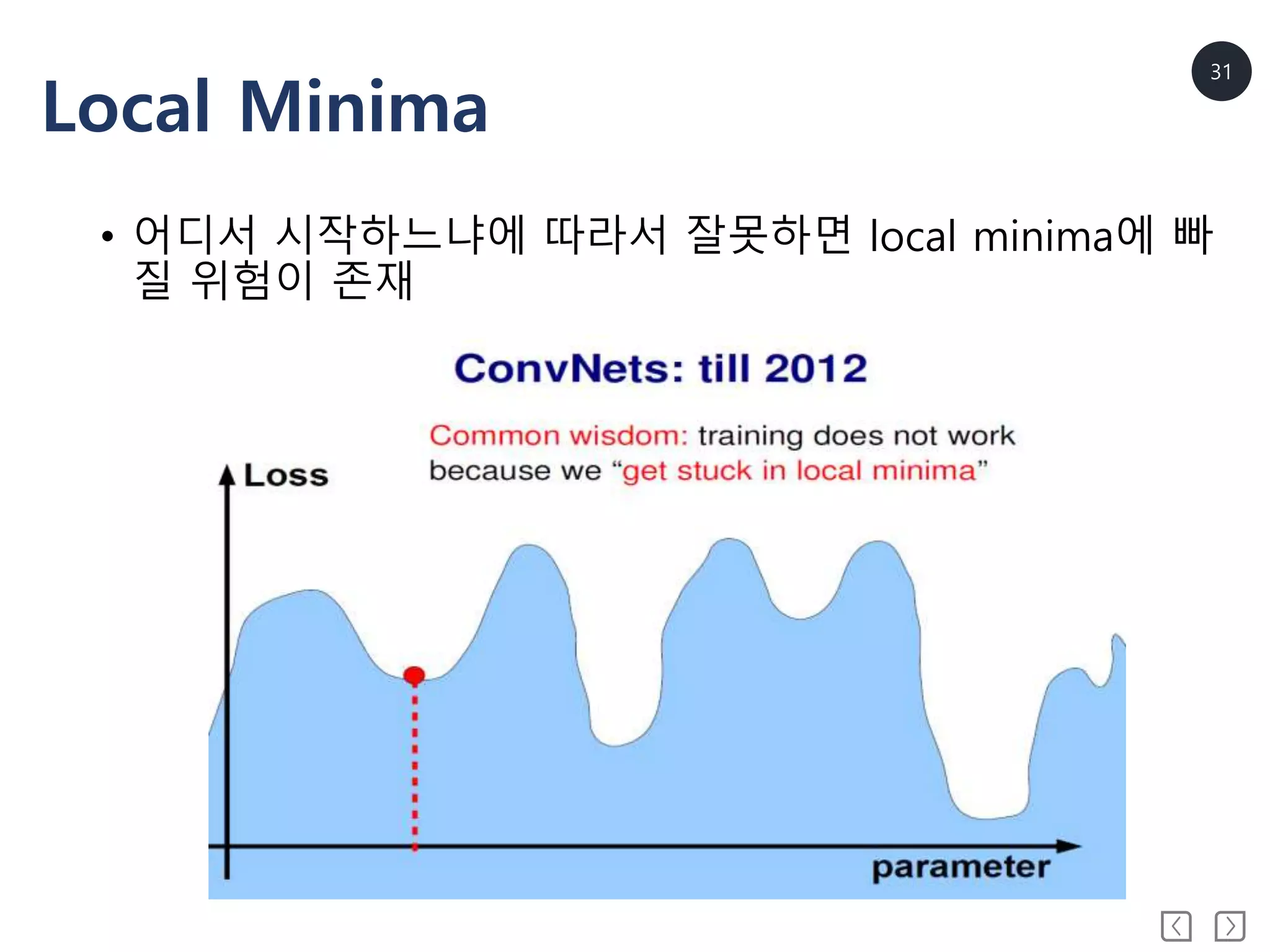
• Get stuck in local minima
32
어떻게 해결할까?
• Vanishinggradient problem
Sigmoid 말고 ReLU를 쓰자
• Overfitting problem
Regularization method를 쓰자(예 : dropout)
• Get stuck in local minima
Local minima에 빠져도 괜찮다
33.
33
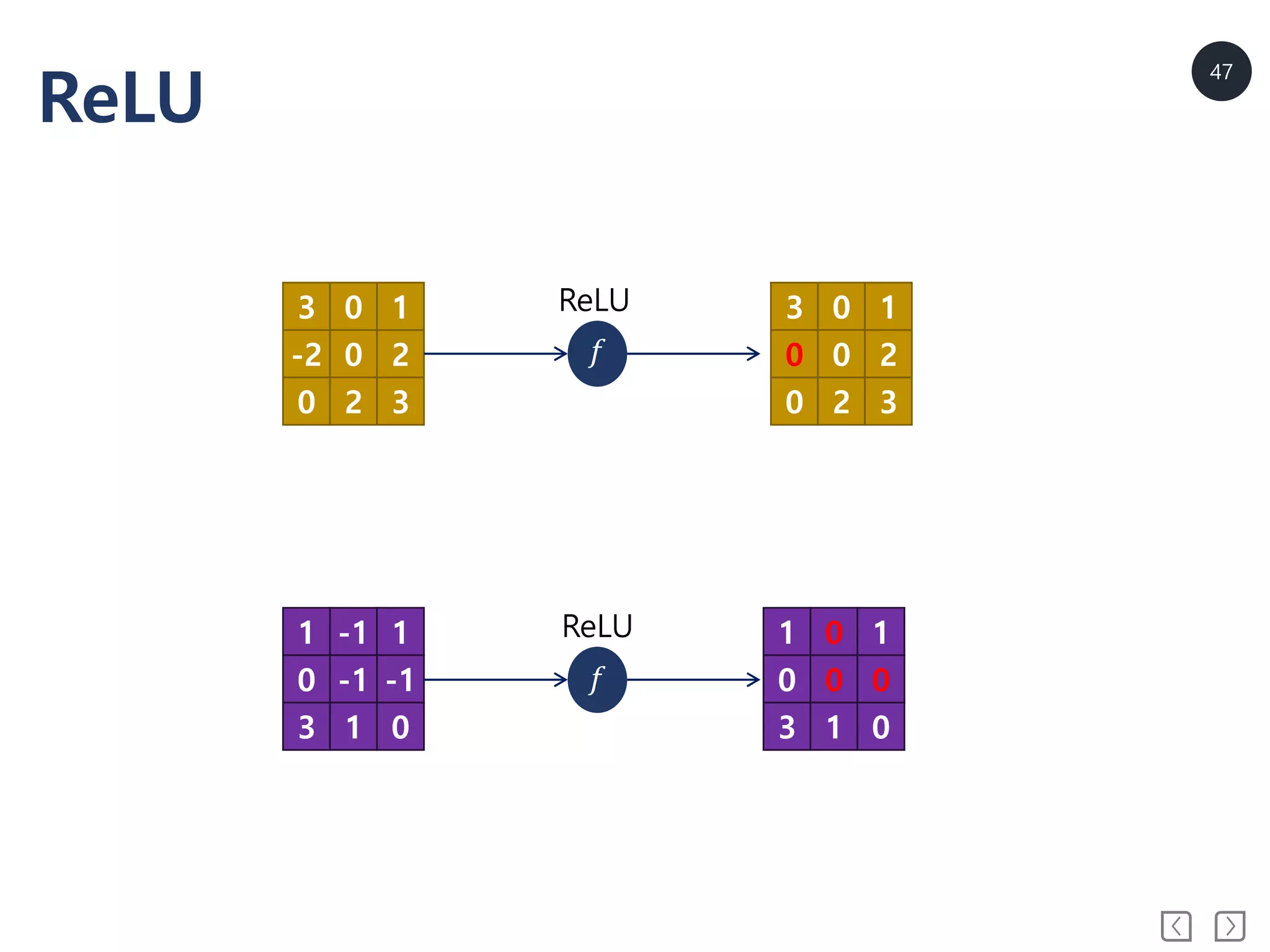
ReLU : RectifiedLinear Unit
• ReLU를 activation function으로 사용 sparse activation
• ReLU는 미분값이 0 아니면 1 vanishing gradient 해결
35
Dropout(Regularization Method)
• 각학습 단계마다, 특정 확률로(예 : 50%) random하게
hidden layer에 있는 unit들을 없애고 학습하는 방법
• Ensemble 개념을 적용
여러 개의 model을 사용하여 평균값을 쓰면 하나의 model을 쓰
는 경우보다 좋음
하나의 model로 비슷한 효과를 낼 수 있는 방법
36.
36
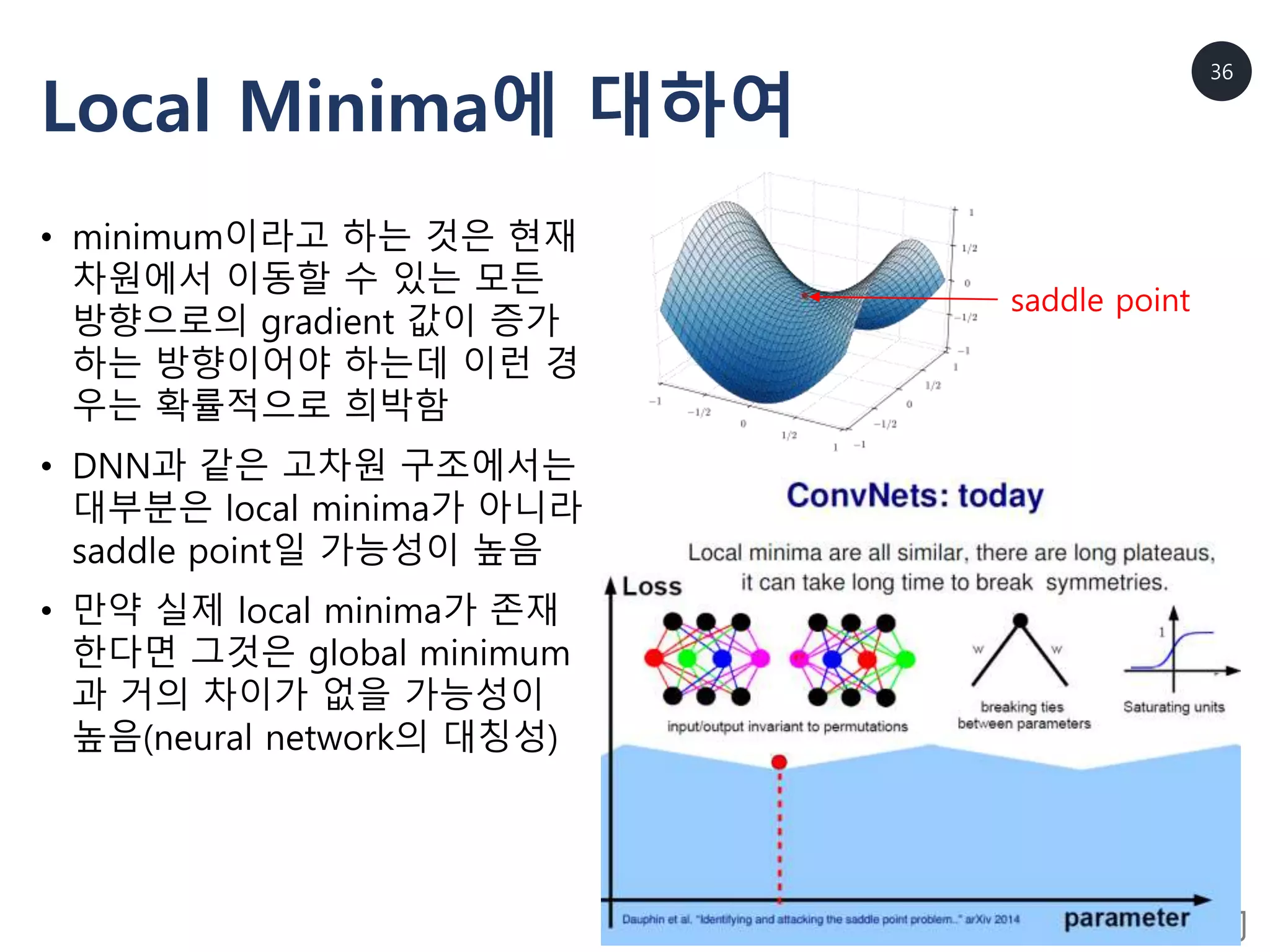
Local Minima에 대하여
•minimum이라고 하는 것은 현재
차원에서 이동할 수 있는 모든
방향으로의 gradient 값이 증가
하는 방향이어야 하는데 이런 경
우는 확률적으로 희박함
• DNN과 같은 고차원 구조에서는
대부분은 local minima가 아니라
saddle point일 가능성이 높음
• 만약 실제 local minima가 존재
한다면 그것은 global minimum
과 거의 차이가 없을 가능성이
높음(neural network의 대칭성)
saddle point
38
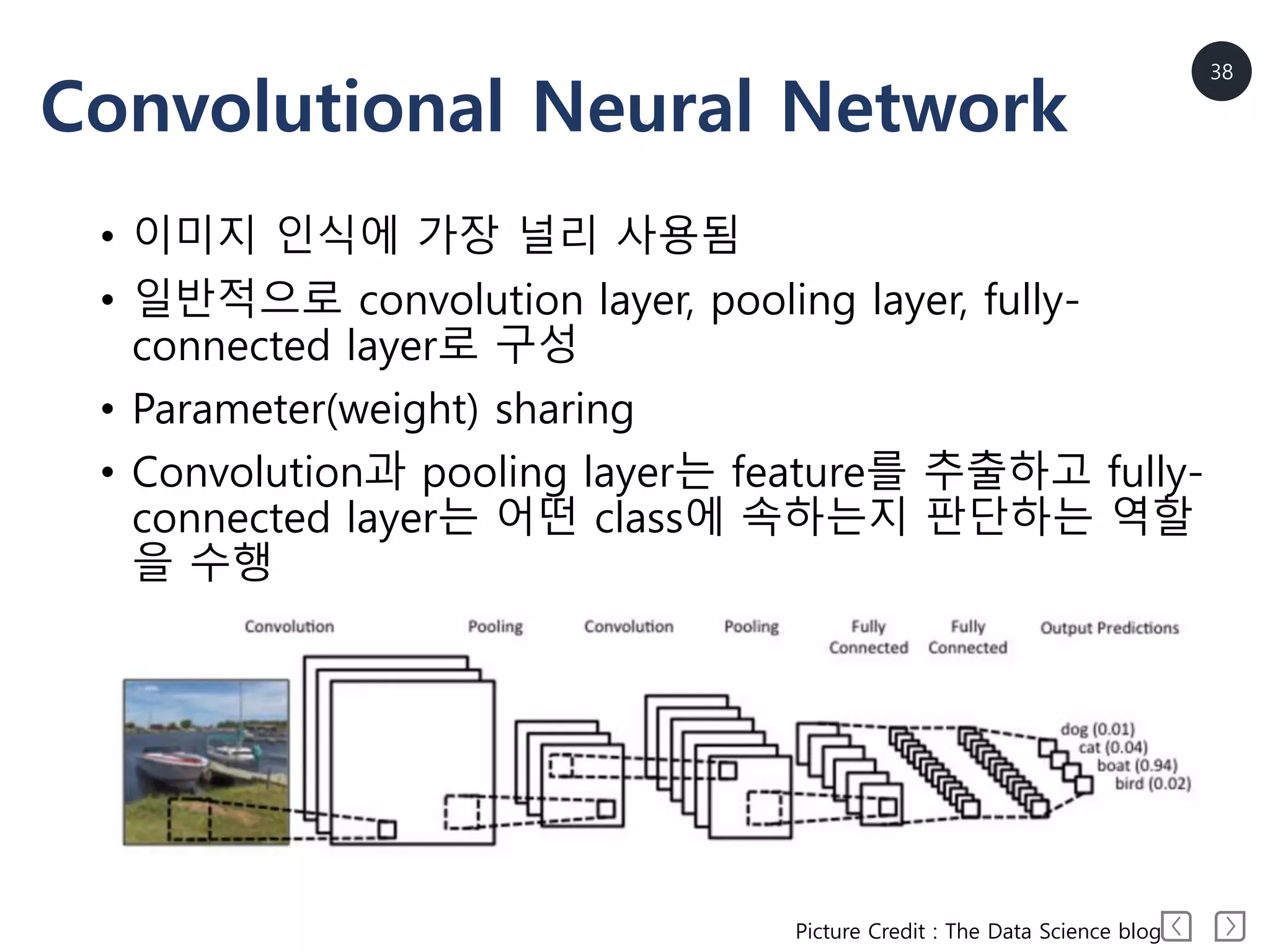
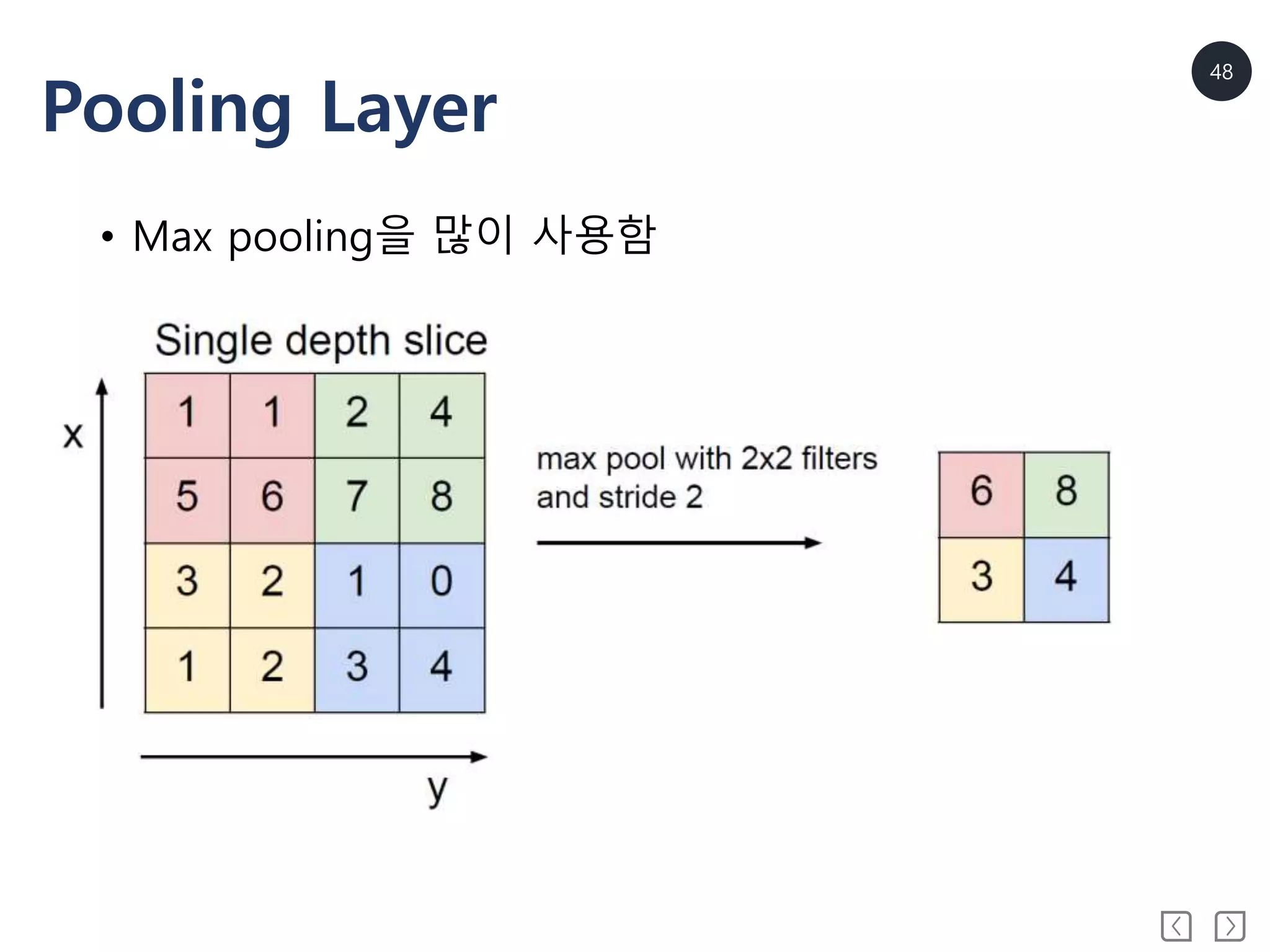
Convolutional Neural Network
•이미지 인식에 가장 널리 사용됨
• 일반적으로 convolution layer, pooling layer, fully-
connected layer로 구성
• Parameter(weight) sharing
• Convolution과 pooling layer는 feature를 추출하고 fully-
connected layer는 어떤 class에 속하는지 판단하는 역할
을 수행
Picture Credit : The Data Science blog
39.
39
CNN의 동작원리
• 이미지를작은 tile로 나
누고, 작은 network를 통
해 tile에서 특정 feature
를 추출(예: 귀)
• Newtork가 다음 tile로 이
동하면서 같은 방법으로
feature를 추출(동일한
weight 사용)
• 다른 feature(예: 눈)를 추
출하는 network를 추가
로 만들고 위와 같은 방
법으로 tile을 하나씩
network에 적용
• 추출된 모든 feature들을
잘 조합하여 최종적으로
이미지를 판단
40.
40
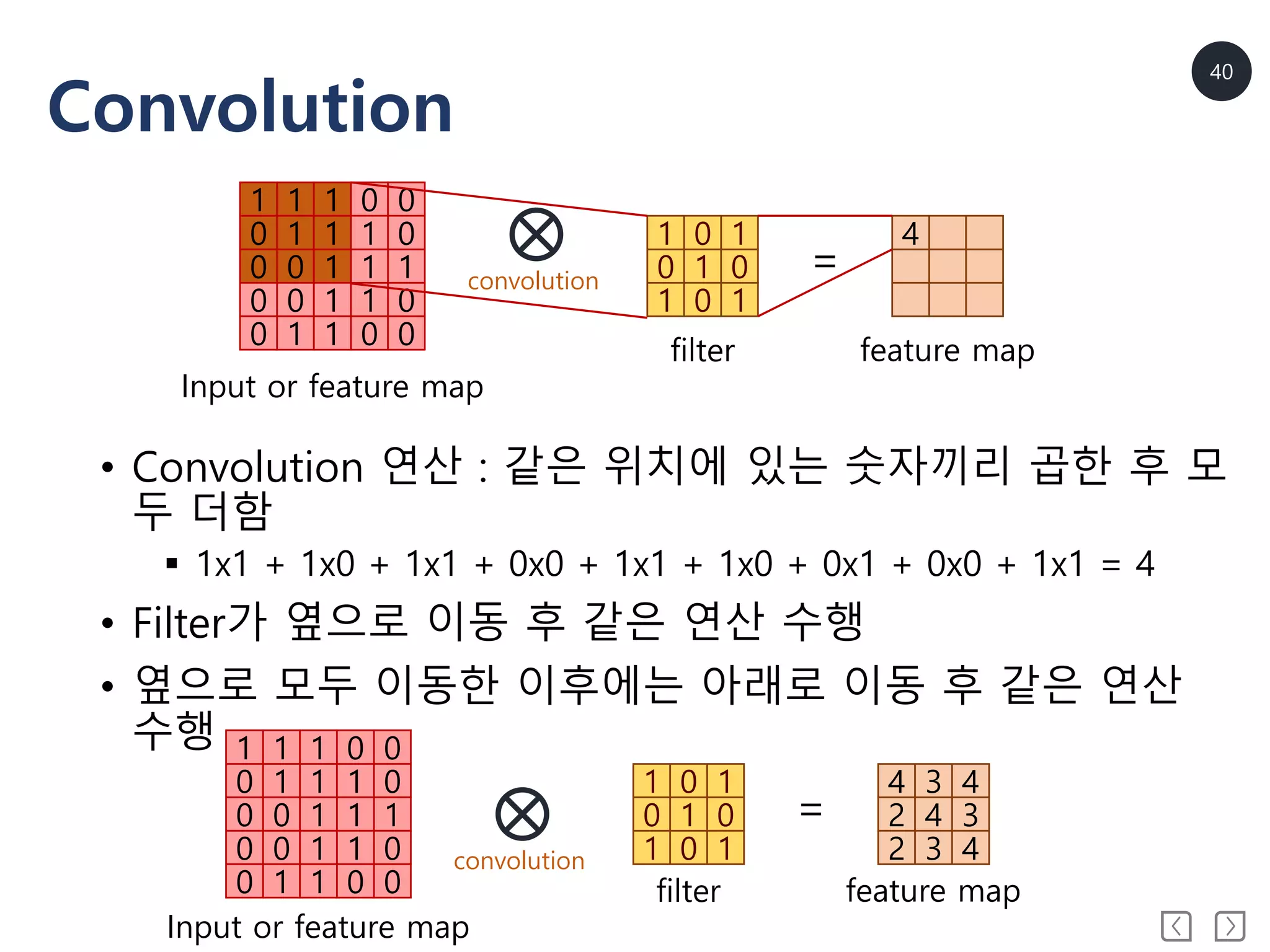
Convolution
1 1 10 0
0 1 1 1 0
0 0 1 1 1
0 0 1 1 0
0 1 1 0 0
1 0 1
0 1 0
1 0 1
4 3 4
2 4 3
2 3 4
=
convolution
1 1 1 0 0
0 1 1 1 0
0 0 1 1 1
0 0 1 1 0
0 1 1 0 0
1 0 1
0 1 0
1 0 1
4
=convolution
filter feature map
Input or feature map
filter feature map
Input or feature map
• Convolution 연산 : 같은 위치에 있는 숫자끼리 곱한 후 모
두 더함
1x1 + 1x0 + 1x1 + 0x0 + 1x1 + 1x0 + 0x1 + 0x0 + 1x1 = 4
• Filter가 옆으로 이동 후 같은 연산 수행
• 옆으로 모두 이동한 이후에는 아래로 이동 후 같은 연산
수행
52
Large Scale ImageClassification
• ImageNet
Over 15
• ImageNet
Over 15 million labeled high-
resolution images
Roughly 22,000 categories
Collected from the web
Labeled by human labelers using
Amazon’s Mechanical Turk crowd-
sourcing tool
• ImageNet Large-Scale Visual
Recognition Challenge (ILSVRC)
Uses a subset of ImageNet
1,000 categories
1.2 million training images
50,000 validation images
150,000 test images
Report two error rates:
Top-1 and top-5
53.
53
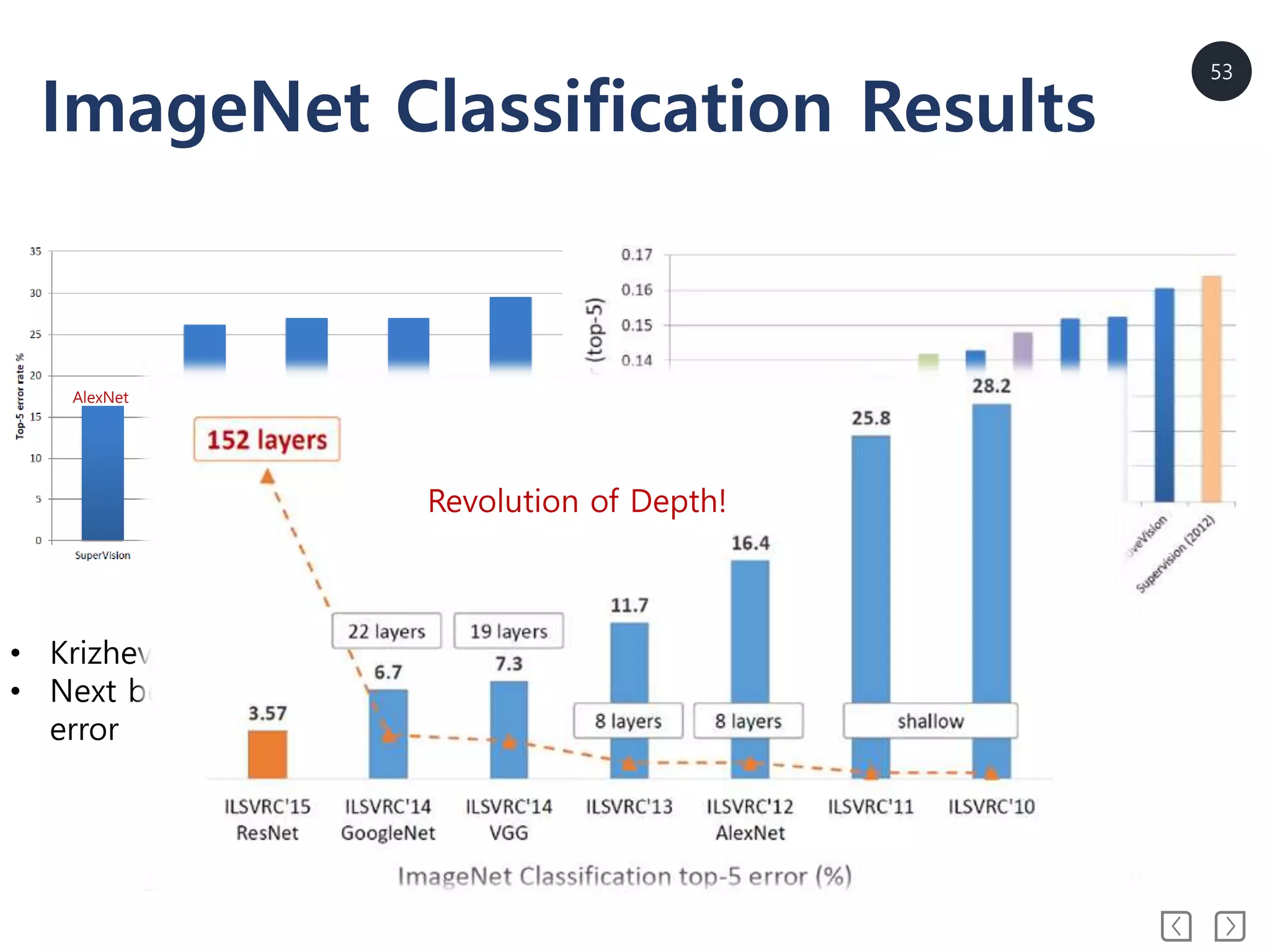
ImageNet Classification Results
<2012Result>
• Krizhevsky et al. – 16.4% error(top-5)
• Next best (non-convnet) – 26.2%
error
<2013 Result>
• All rankers use deep
learning(Convnet)
Revolution of Depth!
AlexNet
56
GoogLeNet(2014 winner)
• Inceptionmodul을 반복하여 사용
• 1x1 convolution을 사용하여 channel 수를 조절
• Fully connected layer 대신 global average pooling 사용
• 5M parameters, 1.5B operations/evaluation
Inception module
“Going Deeper With Convolutions”
57.
57
VGG(2nd place in2014)
• 3x3 filter만 반복해서 사용
• Why??
Convolution filter를 stack하면 더
큰 receptive field를 가질 수 있음
2개의 3x3 filter = 5x5 filter
3개의 3x3 filter = 7x7 filter
Parameter수는 큰 filter 사용하는
경우에 비하여 감소
regularization 효과
“Very Deep Convolutional Networks for Large-Scale Image Recognition”
60
ResNet
• Layer수가 많을수록항상 좋을까?
• 56개의 layer를 사용하는 경우가 20개의 layer를 사용하는
경우에 비해 training error가 더 큰 결과가 나옴
“Deep Residual Learning for Image Recognition”
61.
61
ResNet
• 더 deep한model은 training error가
더 낮아야 함
Shallow model의 parameter를 deeper
model에 copy
Extra layers가 identity function의 역할
만 해도 동일한 결과가 나올 수 있음
• Deep한 model은 optimization이 쉽
지 않다는 것을 발견(identity도 힘들
다)
A shallower model
(18 layers)
A deeper model
(34 layers)
“Deep Residual Learning for Image Recognition”
62.
62
Deep Residual Learning
•Identity는 그대로 상위 layer로 전달하고, 나머지 부분만
학습
“Deep Residual Learning for Image Recognition”
66
Tensorflow를 이용한 구현
•Tensorflow
Google에서 개발, 2015년 11월에 open source로 공개된 딥러닝
framework
Python기반, computational graph를 이용(theano와 비슷함)
CPU, GPU, multi-GPU를 모두 지원
https://tensorflow.org
67.
67
Tensorflow 동작 개념
•어떤 구슬을 넣을 것인지 : variable,
placeholder 선언
a = tf.placeholder(“float”)
• 못의 개수, 위치를 선정 : network 설
계
y = tf.mul(a, b)
• Insert coin : session 생성
sess = tf.Session()
• 구슬을 넣음 : network 실행
sess.run(y, feed_dict={a: 3, b: 3}
68.
68
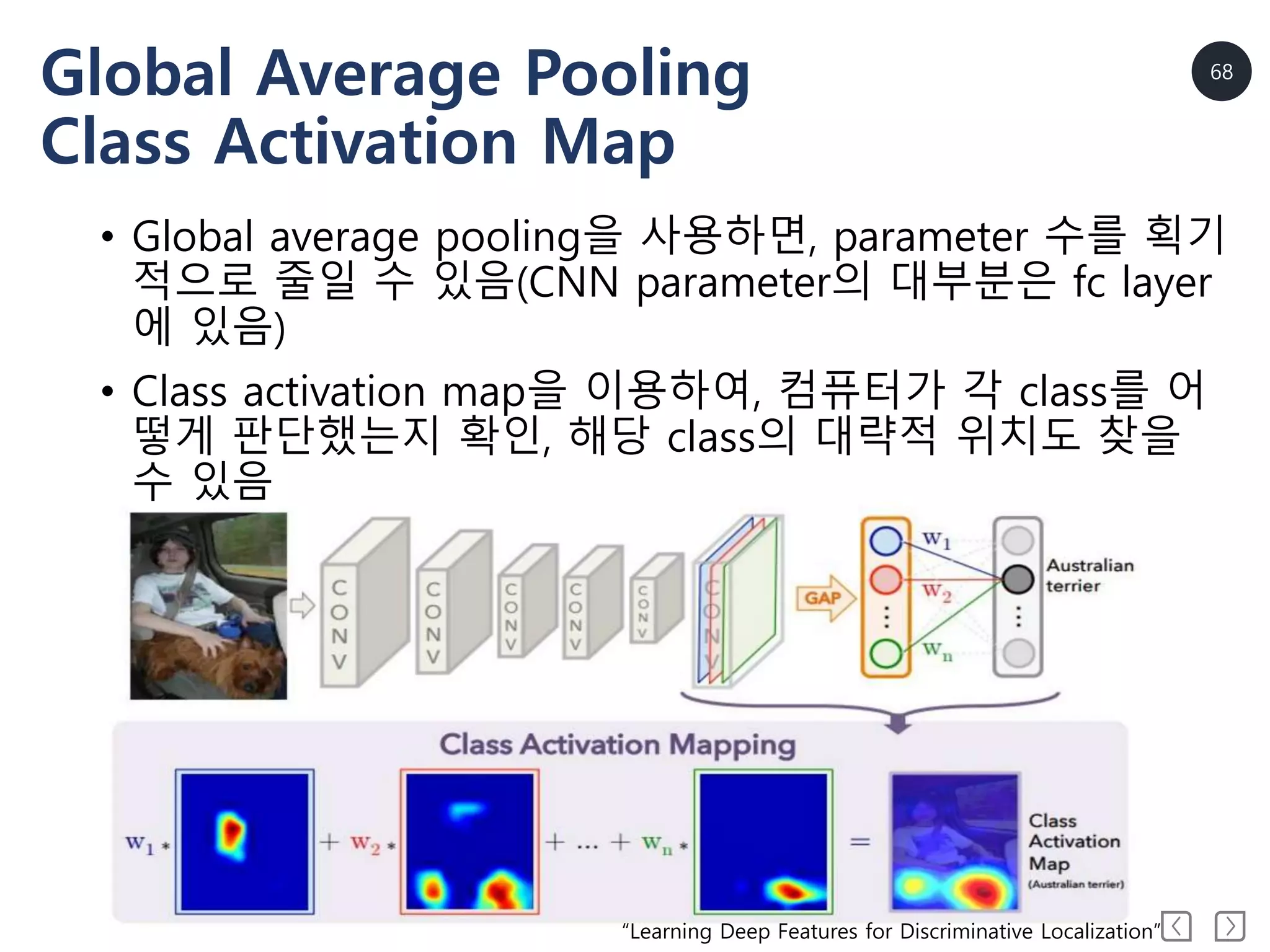
Global Average Pooling
ClassActivation Map
• Global average pooling을 사용하면, parameter 수를 획기
적으로 줄일 수 있음(CNN parameter의 대부분은 fc layer
에 있음)
• Class activation map을 이용하여, 컴퓨터가 각 class를 어
떻게 판단했는지 확인, 해당 class의 대략적 위치도 찾을
수 있음
“Learning Deep Features for Discriminative Localization”
79
Visual QnA
Q: Whatis the boy holding?
DPPnet: surfboard DPPnet: bat
Q: What is the animal doing?
DPPnet: resting (relaxing) DPPnet: swimming (fishing)
“Image Question Answering using Convolutional Neural Network with Dynamic Parameter Prediction”
83
Summary & Conclusion
•지능의 핵심은 학습이고, 기계학습은 사람의 학습과정을
모방하여 만들어졌다
• 기계학습(딥러닝)은 기계가 스스로 프로그램을 만들어내는
과정이다
• 기계학습(딥러닝)을 이용하면, 비슷한 유형의 문제의 경우
새로 network를 만들지 않고 data만 바꿔주면 그에 맞는
학습이 진행되어 문제를 풀 수 있다는 장점이 있다
• 딥러닝의 발달로 인하여 수많은 분야에서 딥러닝을 활용
하여 놀라운 성과를 얻어내고 있다
• 딥러닝을 이용하면 전문지식을 갖추지 않아도 그와 관련
된 많은 문제들을 해결할 수 있다
84.
84
인공지능, 딥러닝은 만능?
•동유럽국가 몬테네그로의 수도는 어
디인가?
• 바둑판을 1줄씩 늘려서 20x20으로 만
들고 지금 당장 이세돌과 알파고가 대
결한다면?
• 의료 data를 분석하여, 수명을 예측해
봅시다
평생 한번도 담배를 안피운 사람
현재 흡연을 하고 있는 사람
과거에 흡연을 했다가 끊은 사람
• 인공지능은 인류의 지능 향상에 도움
이 되는가?
• 인공지능의 능력이 커질수록 법적, 도
덕적 문제에 대한 해결이 필요















![19
Perceptron(Artificial Neural Network)
𝑦 = 𝑓(𝐰𝐱 + b)
𝒘 = [𝑤1 𝑤2 𝑤3 … 𝑤 𝑛]
𝒙 = [𝑥1 𝑥2 𝑥3 … 𝑥 𝑛] 𝑇
𝑦𝑓
𝑏
<Perceptron>
sigmoid activation function
𝑓 𝑥 =
1
1 + 𝑒−𝑥](https://image.slidesharecdn.com/random-161226133617/75/slide-19-2048.jpg)











































































![SSII2022 [TS1] Transformerの最前線〜 畳込みニューラルネットワークの先へ 〜](https://cdn.slidesharecdn.com/ss_thumbnails/ts120220608ssiitransformerr2-220607054025-3adacf07-thumbnail.jpg?width=640&height=640&fit=bounds)



![[기초개념] Graph Convolutional Network (GCN)](https://cdn.slidesharecdn.com/ss_thumbnails/agistdkimgcn190507-190507153736-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DL輪読会]Xception: Deep Learning with Depthwise Separable Convolutions](https://cdn.slidesharecdn.com/ss_thumbnails/2017-06-22-170623004409-thumbnail.jpg?width=640&height=640&fit=bounds)











![[모두의연구소] 쫄지말자딥러닝](https://cdn.slidesharecdn.com/ss_thumbnails/20160528-160529034614-thumbnail.jpg?width=640&height=640&fit=bounds)






















![[데이터 분석 소모임] Convolution Neural Network 김려린](https://cdn.slidesharecdn.com/ss_thumbnails/qjbtpgxtsksukja7q6eq-cnn-gimryeorin-240226120343-804ea096-thumbnail.jpg?width=640&height=640&fit=bounds)
























