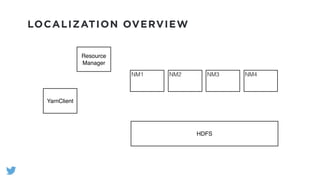
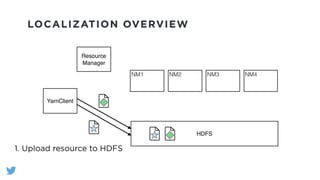
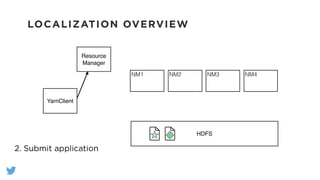
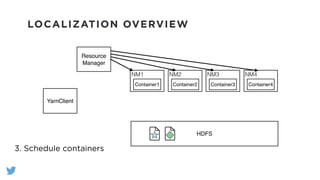
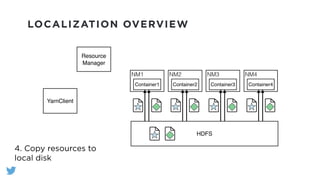
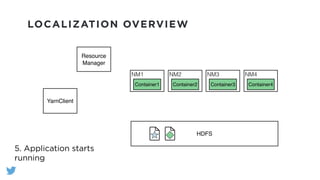
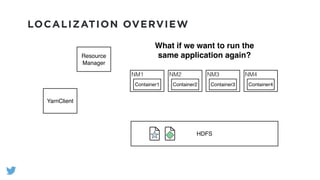
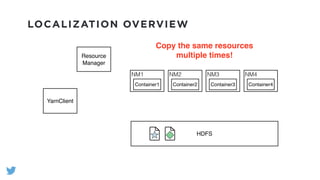
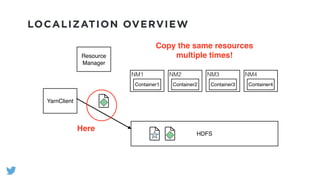
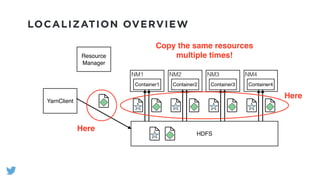
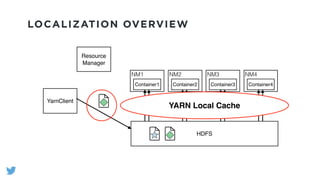
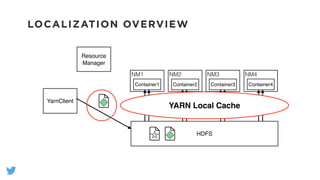
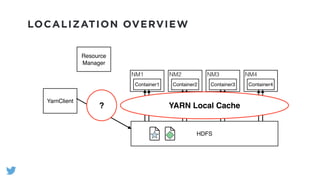
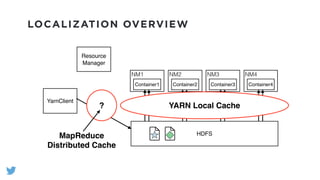
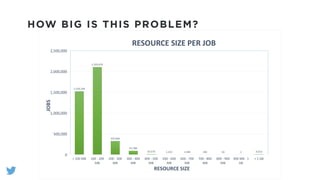
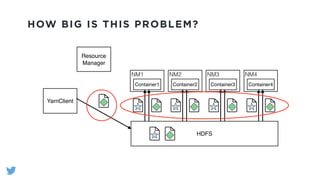
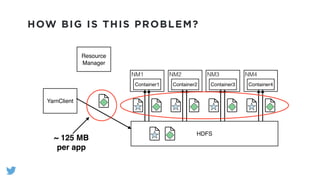
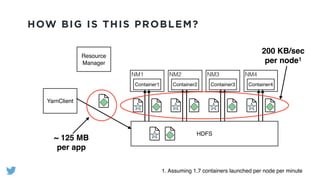
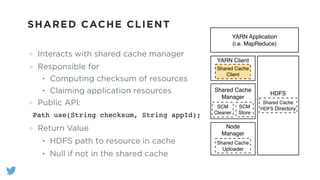
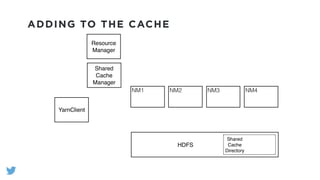
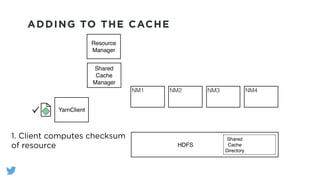
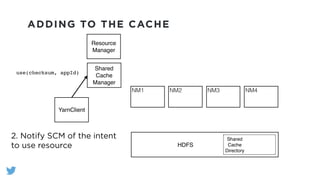
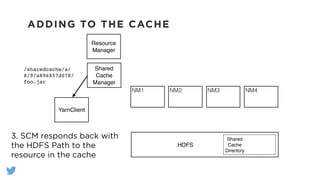
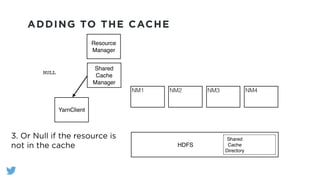
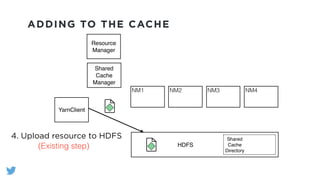
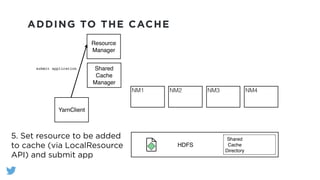
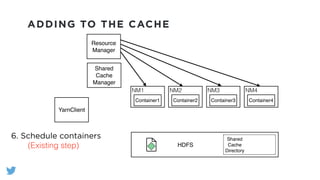
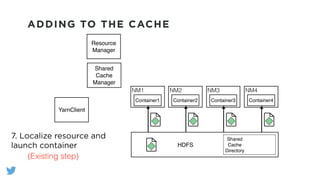
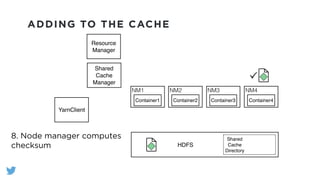
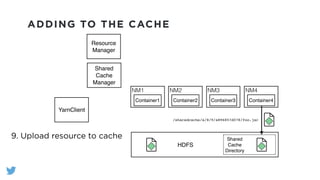
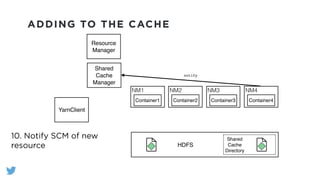
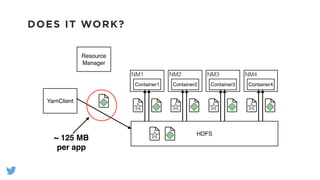
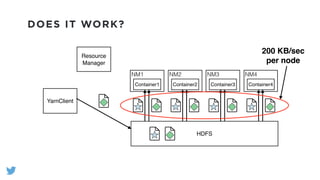
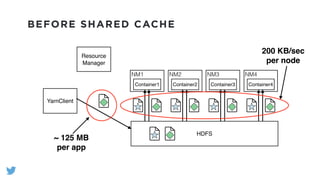
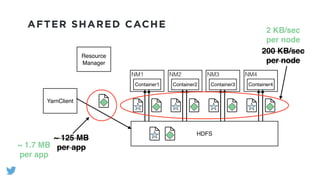
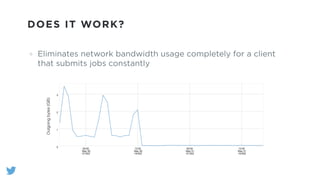
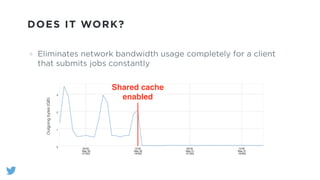
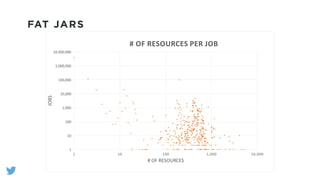
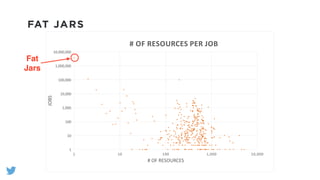
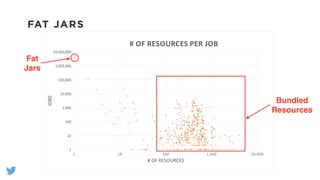
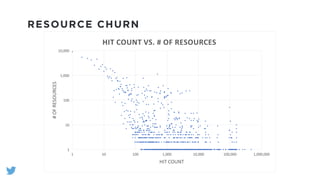
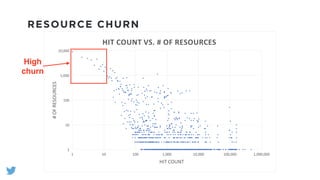
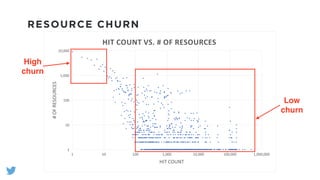
The document outlines the design and functionality of a shared resource cache for YARN applications, detailing the process of managing resources from upload to application execution. It discusses the benefits of using a shared cache, including significant reductions in bandwidth consumption and improved resource management, while also presenting challenges such as resource churn and admin tips to mitigate issues. Key design goals include scalability, security, fault tolerance, and transparency for developers.