Download as PDF, PPTX











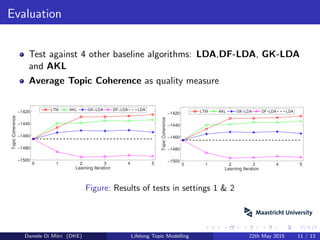



The document reviews a paper on lifelong topic modeling by Chen and Liu, which uses knowledge to enhance topic modeling beyond traditional LDA. It discusses the limitations of LDA, presents a lifelong learning approach to incorporate prior knowledge automatically, and evaluates the proposed method against various baseline algorithms. The presentation concludes with suggestions for improving the text corpora and further testing with big data.
















































![[Yang, Downey and Boyd-Graber 2015] Efficient Methods for Incorporating Knowl...](https://cdn.slidesharecdn.com/ss_thumbnails/sparse-constrained-lda-151024072334-lva1-app6891-thumbnail.jpg?width=640&height=640&fit=bounds)






























![Getting Started with Apache Spark: Big Data Made Simple [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/apachesparkgettingstarted-260203175547-8361bcc3-thumbnail.jpg?width=640&height=640&fit=bounds)
















