Reinforcement Learning with few reward is challenge subject. This slide provides same method for reinforce learning with few reward and some latent variable model by VAE.











![2020-5-6
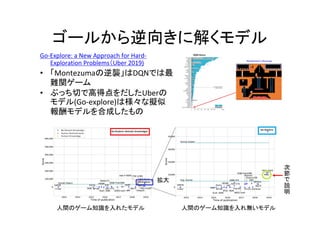
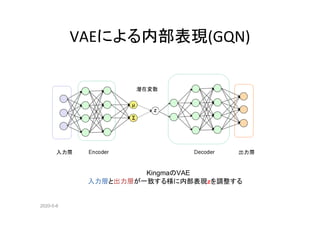
時系列のVAE(TD_VAE)
• GQNの時系列版
Temporal Difference Variational Auto-Encoder(ICLR 2018)
• 観察の時系列[x1,,xN]から内部構造[z1,,zN]をEncodeする変分ベイズ](https://image.slidesharecdn.com/rlwithfewreward-200505222316/85/slide-19-320.jpg)
![2020-5-6
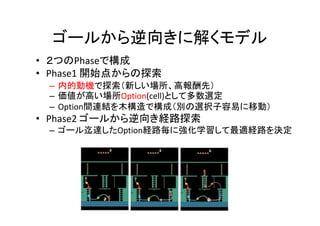
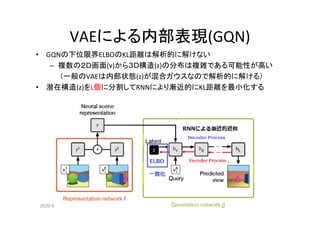
時系列のVAE(TD_VAE)
• 観察(x)の履歴をRNNの記憶(b)にして2時点[z1,z2]毎に逐次的に解く
• Encoder Decoder以外に Transformer Smootherを使ってモデル[z]を精緻化
• 損失関数を最小化するためEncoder q(φ)とDecoder p(θ)のパラメータ更新
②Next
③Encode
⑤Smoother
⑥Transformer
⑦Decode
④Mix
③Encode
⑧Optimeze](https://image.slidesharecdn.com/rlwithfewreward-200505222316/85/slide-20-320.jpg)
![2020-5-6
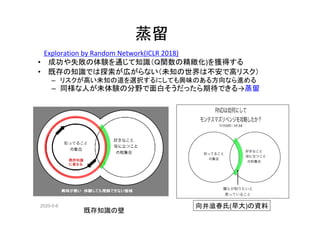
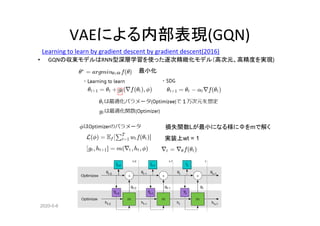
時系列のVAE(TD_VAE)
• 実体[z1,,,,zN]の推移は観察[x1,,,,xN]から変分ベイズで推定できる
• 損失関数は Smoother Encoder Transformer Decodeの和で表現できる](https://image.slidesharecdn.com/rlwithfewreward-200505222316/85/slide-21-320.jpg)
























![[DL輪読会]Learning to Act by Predicting the Future](https://cdn.slidesharecdn.com/ss_thumbnails/20171113dl-171114045641-thumbnail.jpg?width=640&height=640&fit=bounds)























