Download as PDF, PPTX







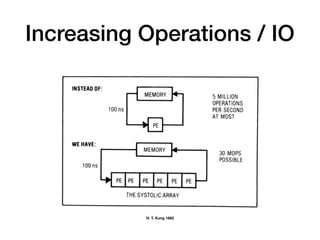

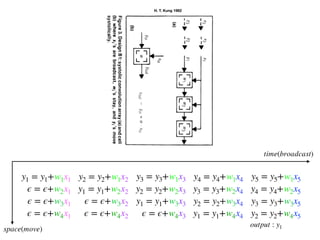
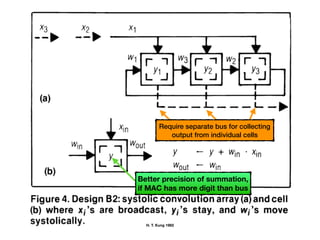
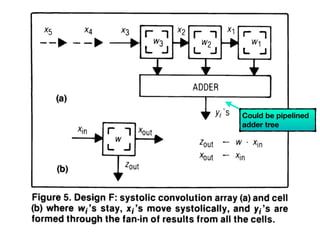
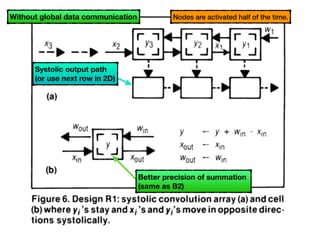
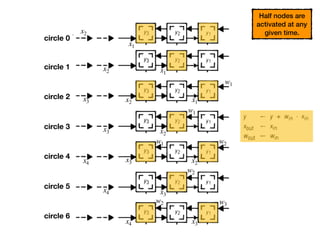
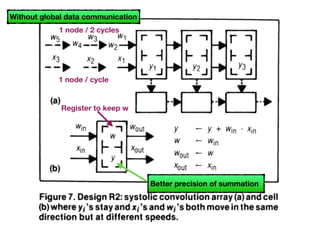
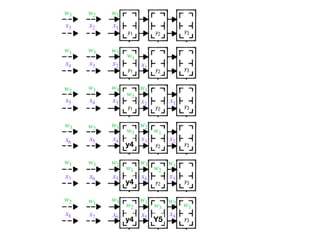
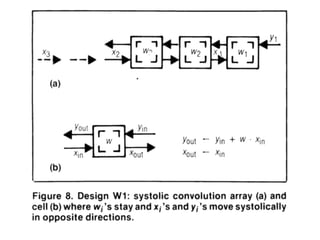
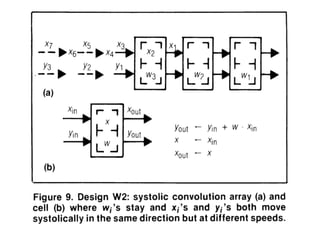
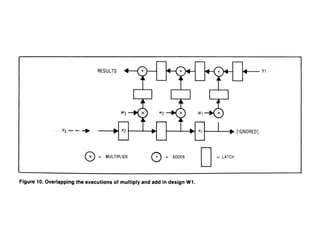

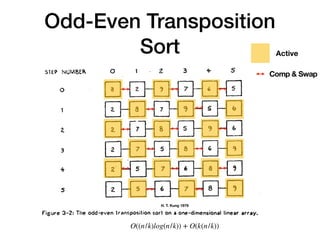


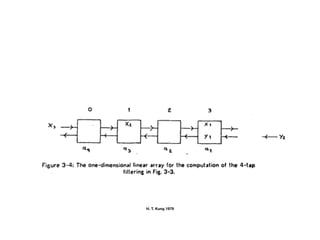
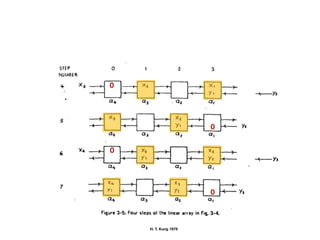

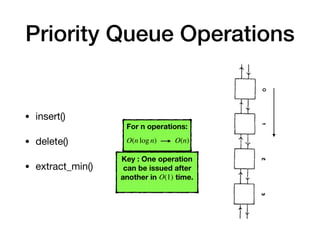
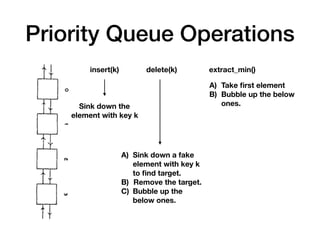

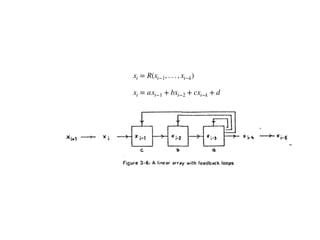
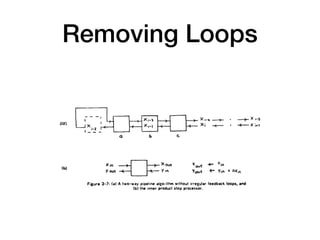

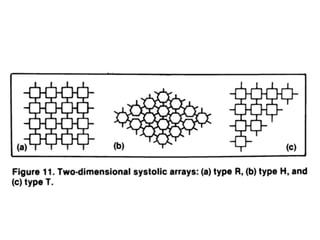
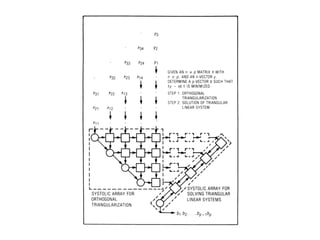


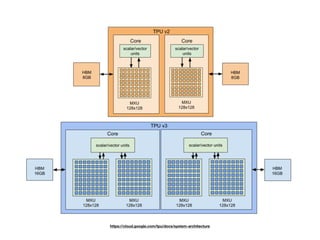








The document discusses systolic arrays and their use in hardware acceleration. It describes how systolic arrays can be used to efficiently implement algorithms like convolution, sorting, filtering, and priority queues in a massively parallel manner. Systolic arrays arrange processing elements in a grid and propagate data through the grid to perform computations. They are well-suited for hardware due to their regular structure and local data movement. The document also discusses Google's Tensor Processing Unit (TPU) which uses a systolic array design to accelerate deep learning workloads.

















![Data Structures - Lecture 1 [introduction]](https://cdn.slidesharecdn.com/ss_thumbnails/lecture-1introduction-141217054305-conversion-gate02-thumbnail.jpg?width=640&height=640&fit=bounds)














![[Harvard CS264] 03 - Introduction to GPU Computing, CUDA Basics](https://cdn.slidesharecdn.com/ss_thumbnails/cs264201103-cudabasicsshare-110209024624-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)
![[Harvard CS264] 02 - Parallel Thinking, Architecture, Theory & Patterns](https://cdn.slidesharecdn.com/ss_thumbnails/cs264201102-archtheorypatternshare-110206154047-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)














































