Downloaded 16 times


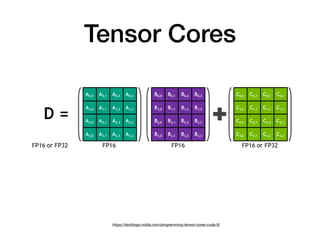
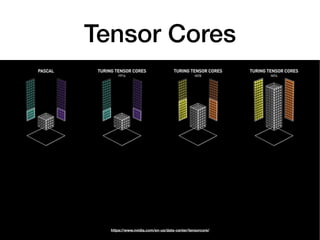


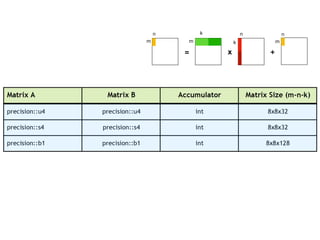
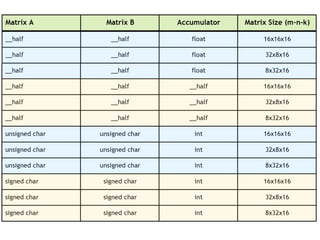
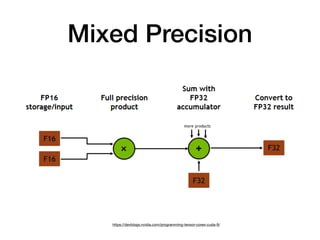

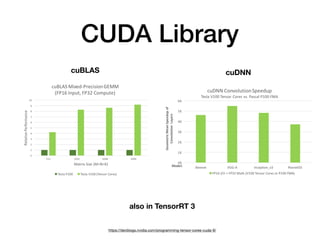









Tensor cores are a new type of core introduced by Nvidia for deep learning and linear algebra workloads. They provide increased performance and throughput over GPUs for matrix multiplication and mixed precision work. Programming tensor cores can be done through CUDA libraries, the CUDA WMMA API, or directly with low-level warp-level instructions to initialize values, calculate tile outputs, and store results. Tensor cores are available on the V100, Titan V, RTX 2070, RTX 2080 and other Nvidia GPUs.















































































