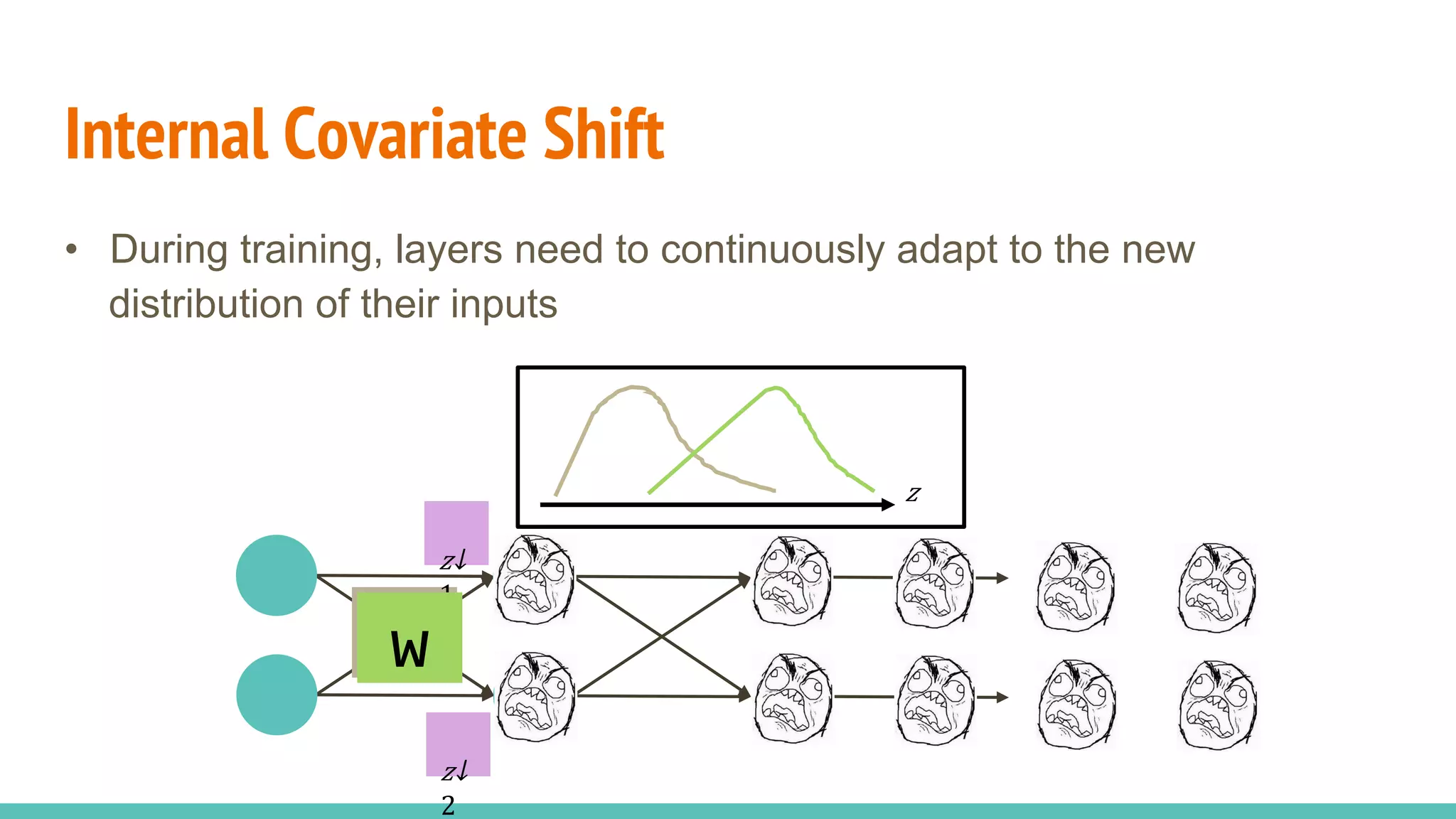
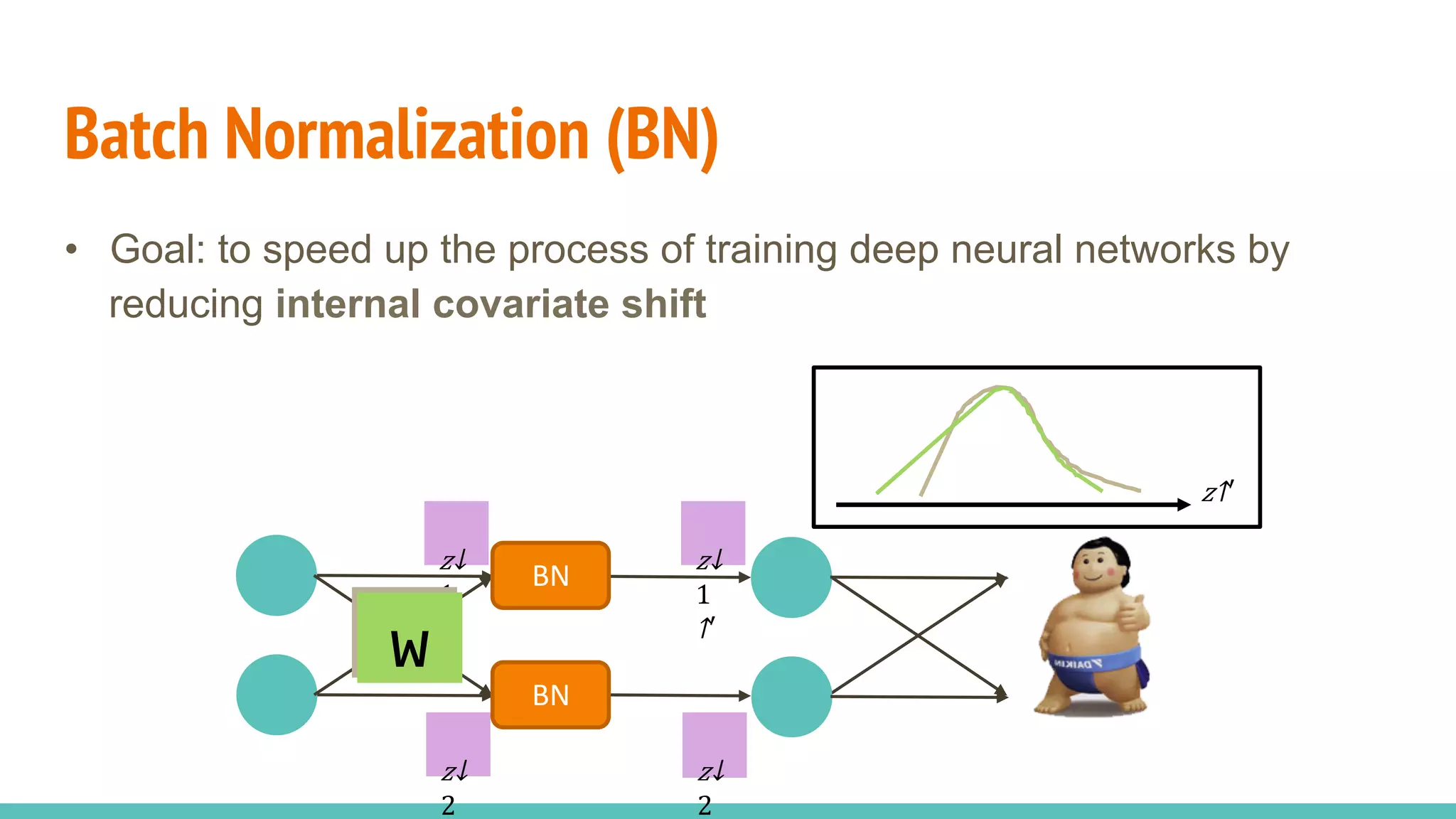
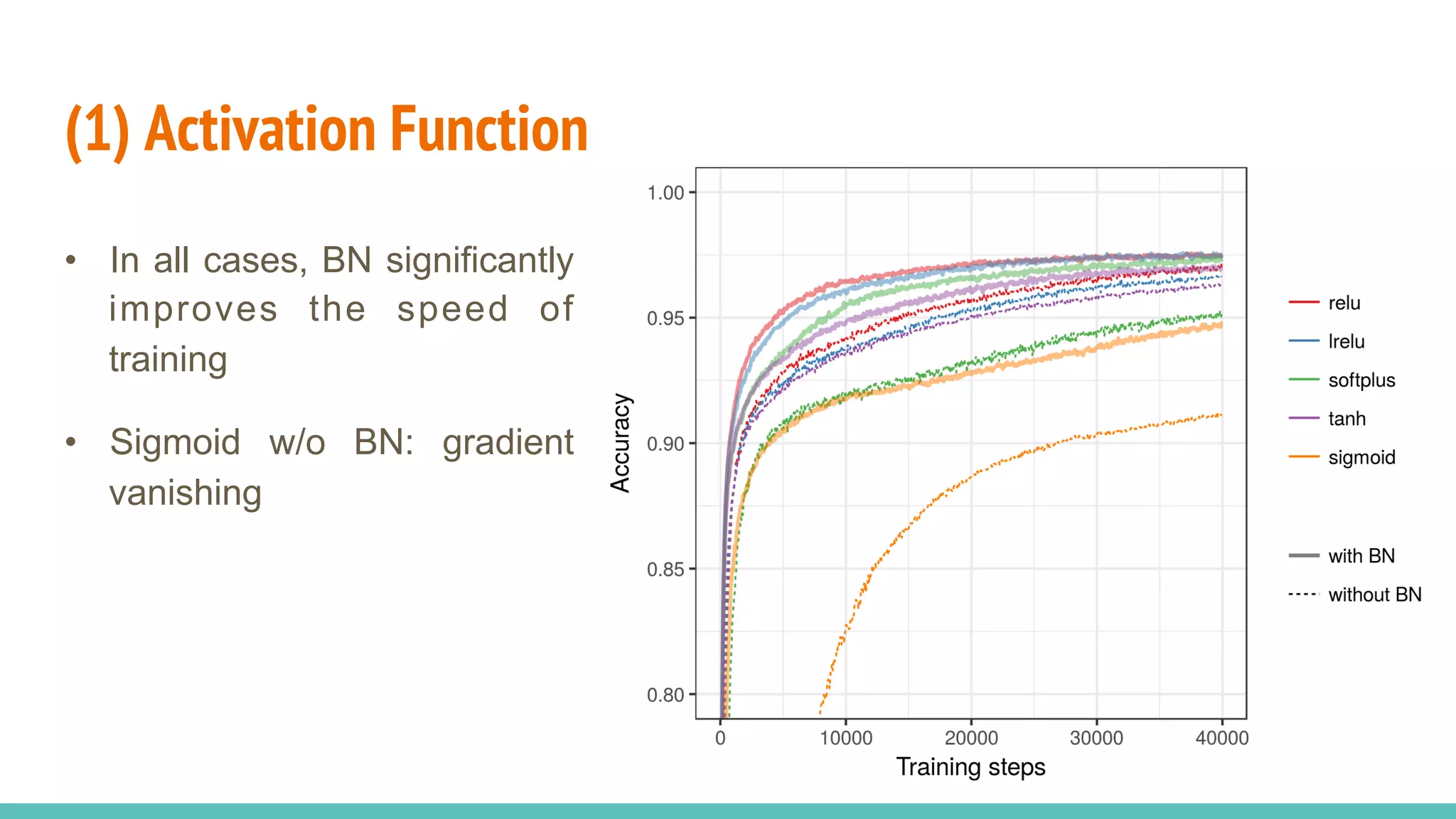
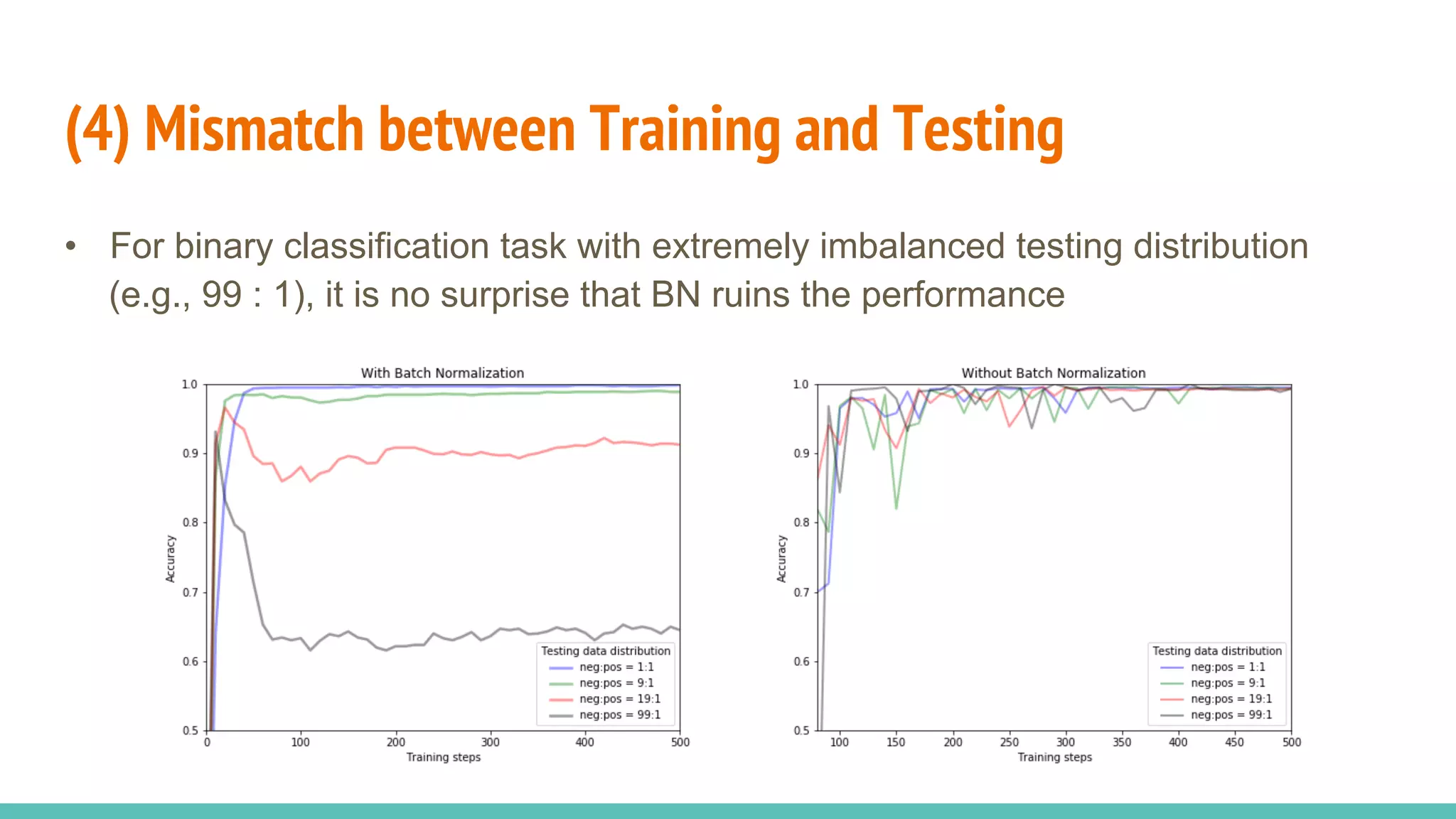
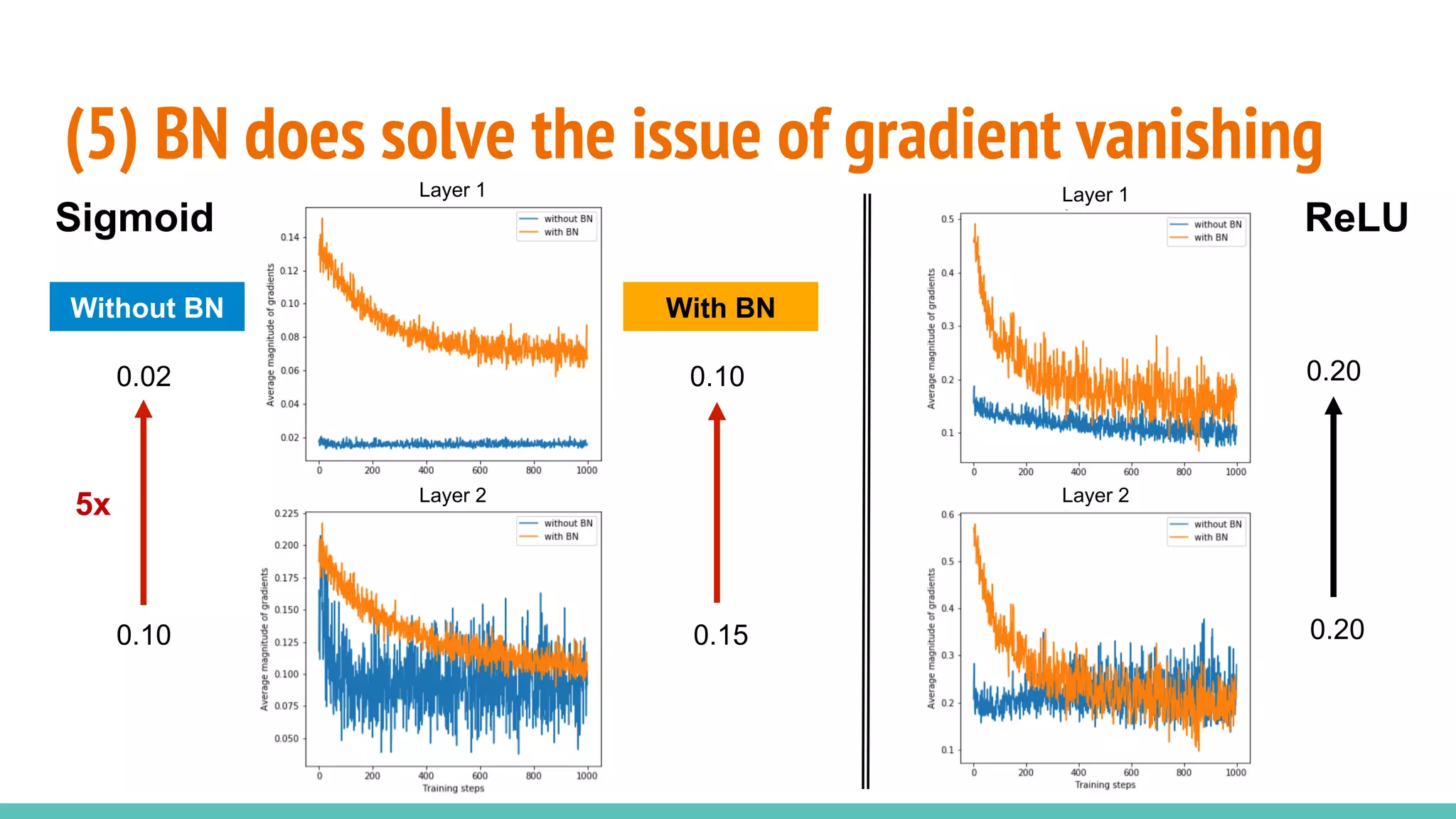
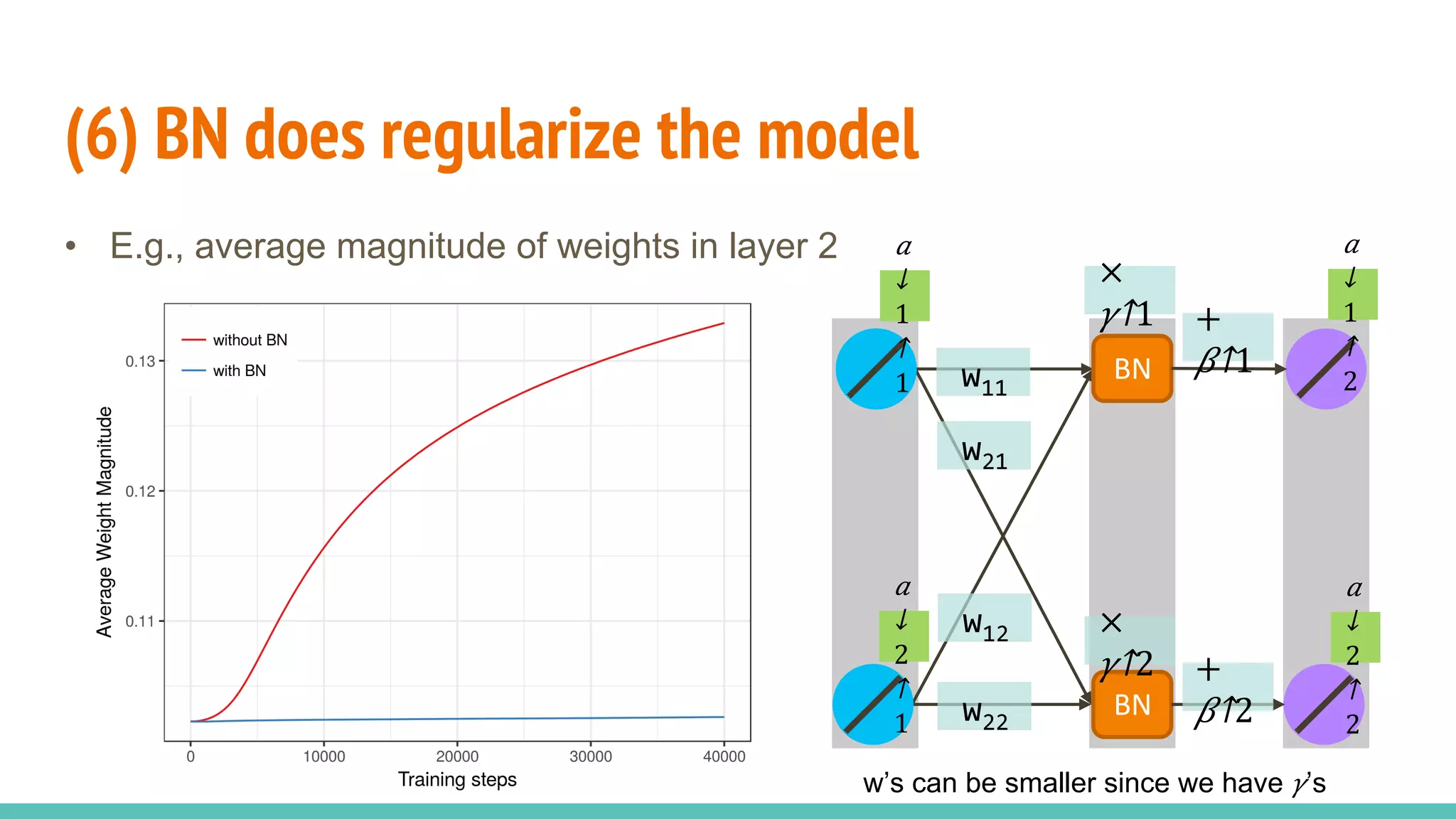
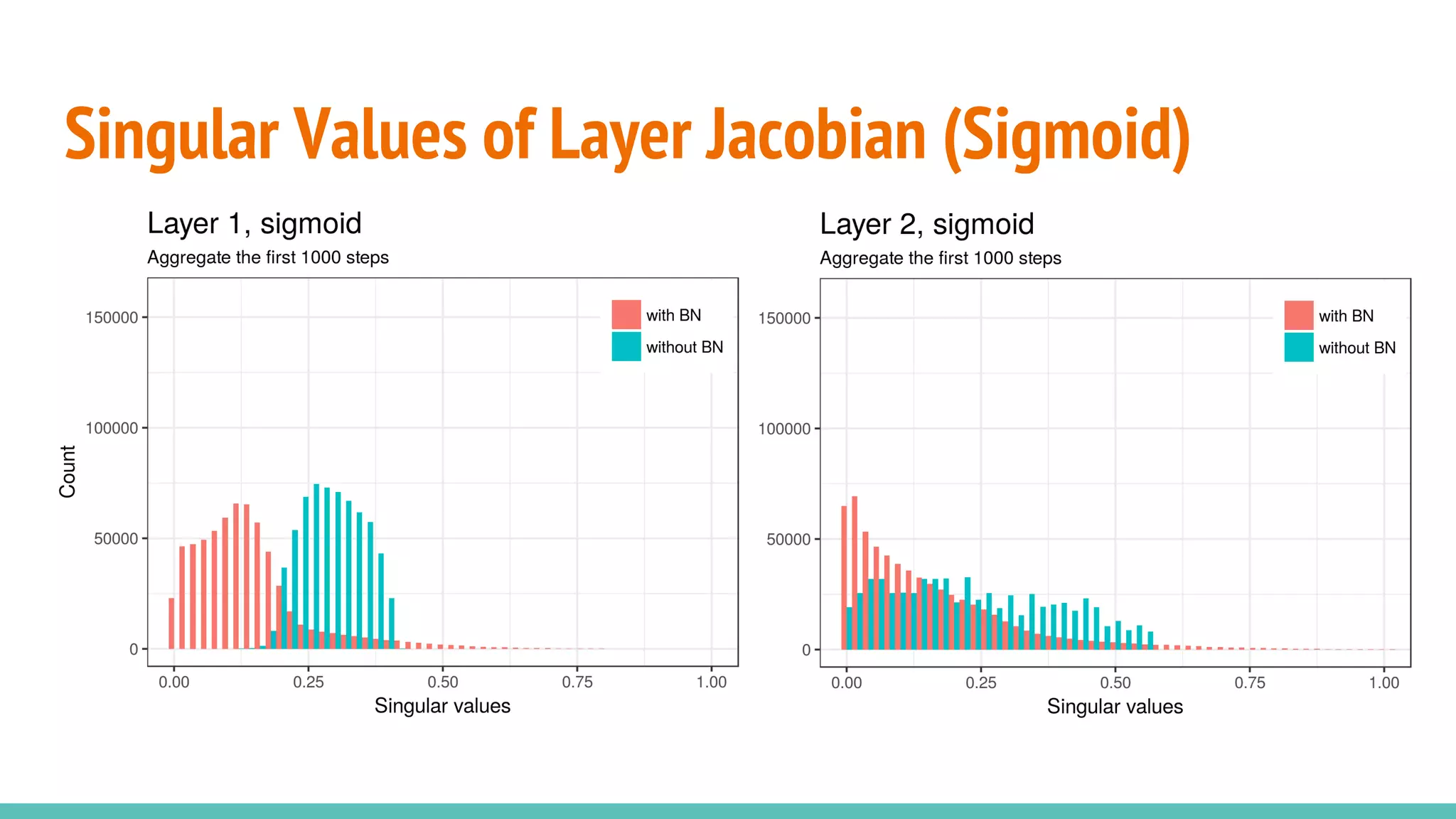
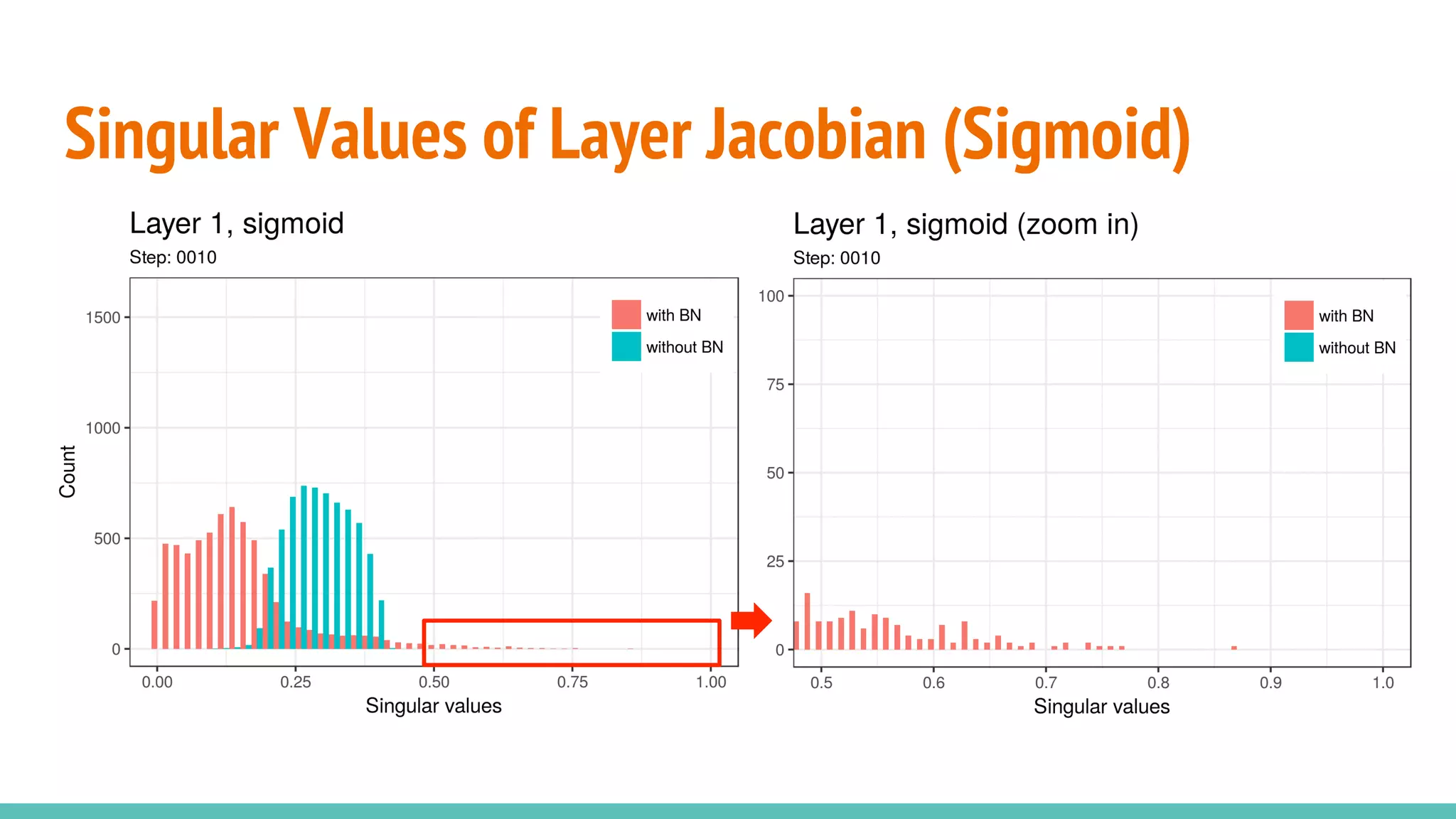
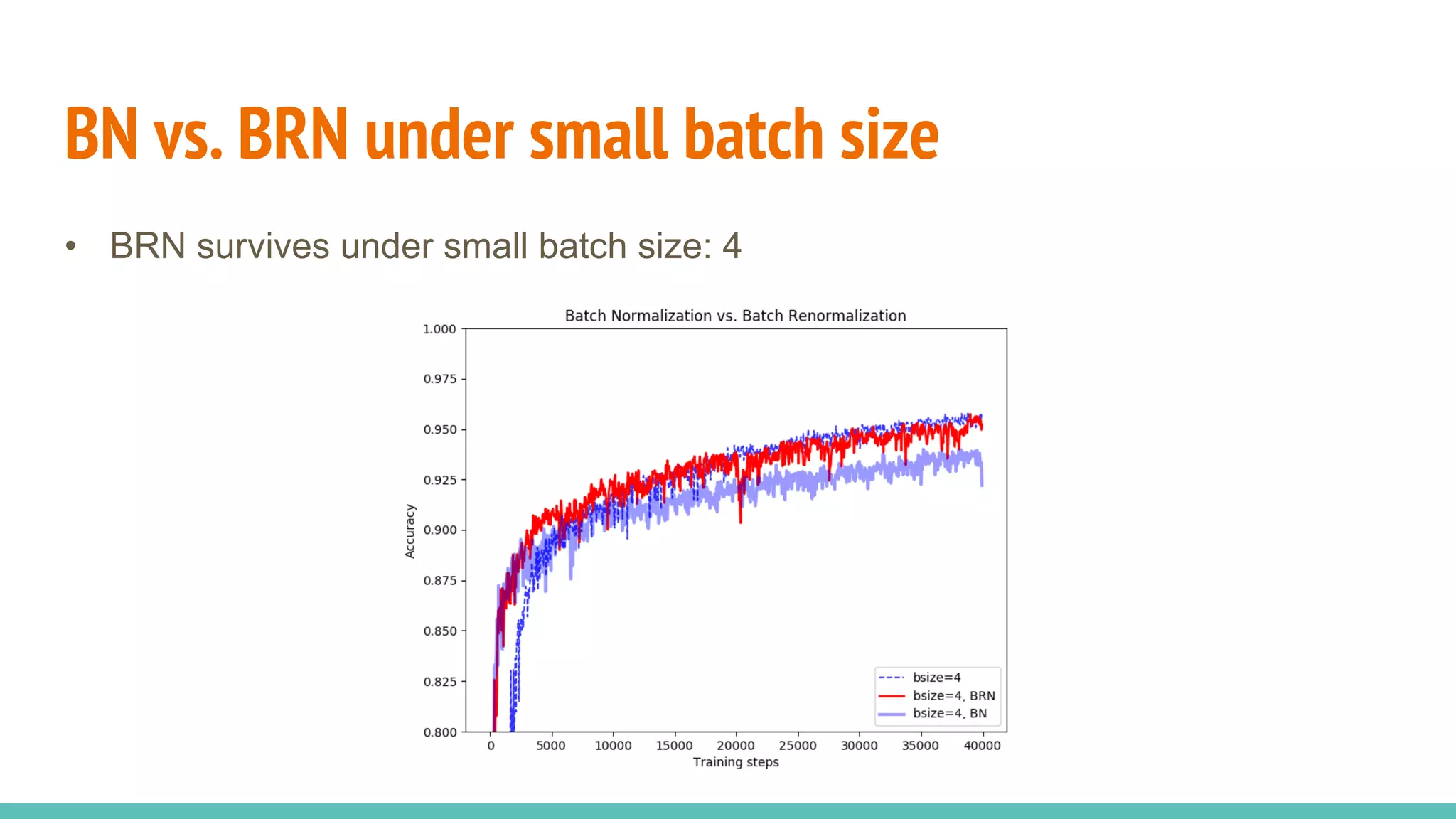
The document discusses the effectiveness of Batch Normalization (BN) in training deep neural networks, highlighting how it reduces internal covariate shift and addresses issues like gradient vanishing. Key findings show that BN accelerates training and enhances performance across various activation functions and optimizers, although it may degrade performance with small batch sizes or mismatched data distributions. Additionally, it compares BN with Batch Renormalization (BRN), emphasizing BRN's capability to handle small batch sizes and mismatched training/testing distributions more effectively.

![Idea of BN
• Full whitening? Too costly!
• 2 necessary simplifications
a. Normalize each feature dimention (no decorrelation)
b. Normalize each batch
• E.g., for the 𝑘-dim input vector:
• Also, “scale” and “shift” parameters are introduced to preserve network
capacity
batch mean
batch variance
𝑥 ↑( 𝑘) = 𝑥↑( 𝑘) −E[ 𝑥↑( 𝑘) ]/√Var[ 𝑥↑( 𝑘) ]
𝑦↑( 𝑘) = 𝛾↑( 𝑘) 𝑥 ↑( 𝑘) + 𝛽↑( 𝑘)](https://image.slidesharecdn.com/mldsfinalpresentation-170912145118/75/Why-Batch-Normalization-Works-so-Well-4-2048.jpg)















![References
• [S. Ioffe & C. Szegedy, 2015] Ioffe, Sergey, Szegedy, Christian. Batch normalization: Accelerating deep network
training by reducing internal covariate shift. arXiv preprint arXiv:1502.03167, 2015.
• [Saxe et al., 2013] Saxe, Andrew M., McClelland, James L., and Ganguli, Surya. Exact solutions to the nonlinear
dynamics of learning in deep linear neural networks. CoRR, abs/1312.6120, 2013.
• [Nair & Hinton, 2010] Nair, Vinod and Hinton, Geoffrey E. Rectified linear units improve restricted boltzmann
machines. In ICML, pp. 807–814. Omnipress, 2010.
• [Shimodaira, 2000] Shimodaira, Hidetoshi. Improving predictive inference under covariate shift by weighting the log-
likelihood function. Journal of Statistical Planning and Inference, 90(2):227–244, October 2000.
• [LeCun et al., 1998b] LeCun, Y., Bottou, L., Orr, G., and Muller, K. Efficient backprop. In Orr, G. and K., Muller (eds.),
Neural Networks: Tricks of the trade. Springer, 1998b.
• [Wiesler & Ney, 2011] Wiesler, Simon and Ney, Hermann. A convergence analysis of log-linear training. In Shawe-
Taylor, J., Zemel, R.S., Bartlett, P., Pereira, F.C.N., and Weinberger, K.Q. (eds.), Advances in Neural Information
Processing Systems 24, pp. 657–665, Granada, Spain, December 2011.](https://image.slidesharecdn.com/mldsfinalpresentation-170912145118/75/Why-Batch-Normalization-Works-so-Well-31-2048.jpg)
![References
• [Wiesler et al., 2014] Wiesler, Simon, Richard, Alexander, Schlu ̈ter, Ralf, and Ney, Hermann. Mean-normalized
stochastic gradient for large-scale deep learning. In IEEE International Conference on Acoustics, Speech, and Signal
Processing, pp. 180–184, Florence, Italy, May 2014.
• [Raiko et al., 2012] Raiko, Tapani, Valpola, Harri, and LeCun, Yann. Deep learning made easier by linear
transformations in perceptrons. In International Conference on Artificial In- telligence and Statistics (AISTATS), pp.
924–932, 2012.
• [Povey et al., 2014] Povey, Daniel, Zhang, Xiaohui, and Khudanpur, San- jeev. Parallel training of deep neural
networks with natural gradient and parameter averaging. CoRR, abs/1410.7455, 2014.
• [Wang et al., 2016] Wang, S., Mohamed, A. R., Caruana, R., Bilmes, J., Plilipose, M., Richardson, M., ... & Aslan, O.
(2016, June). Analysis of Deep Neural Networks with the Extended Data Jacobian Matrix. In Proceedings of The 33rd
International Conference on Machine Learning (pp. 718-726).
• [K. Jia, 2016] JIA, Kui. Improving training of deep neural networks via Singular Value Bounding. arXiv preprint arXiv:
1611.06013, 2016.
• [R2RT] Implementing Batch Normalization in Tensorflow:
https://r2rt.com/implementing-batch-normalization-in-tensorflow.html](https://image.slidesharecdn.com/mldsfinalpresentation-170912145118/75/Why-Batch-Normalization-Works-so-Well-32-2048.jpg)


































































