Download to read offline










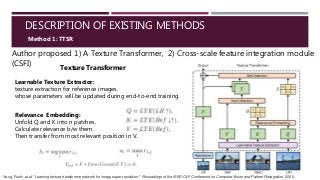
![DESCRIPTION OF EXISTING METHODS
Method 1: TTSR
lrsr
refsr
ref
Learnable Texture Extractor (LTE)
Normalize Input range:[-1,1], Output range:[0,1], f(x)=(x+1)/2
Equalize Data by fixing mean&std (MeanShift)
(Lv3,Lv2,Lv1)=VGG19 (2,7,12 layer output)
Embedding-Create Patches
UnFold (kernel(3,3),padding(1))
Lv3
Lv3
Lv3, Lv2, Lv1,
UnFold(k(3,3),p(1),s(1))
UnFold(k(6,6),p(2),s(2))
UnFold(k(12,12),p(4),s(4))
Transpose
Normalize patches
Matrix Multiplication (t.bmm)
Q
K
V
Attention weight
Max
MaxArg
h
s
S (soft attention map)
Value map
H (hard attention maps)
Fold values map
TIV3
TIV2
TIV1
Lr
F Conv+Relu+Res-block+Conv
Backbone DNN
Fout=F+Conv(F,TIVi)*S](https://image.slidesharecdn.com/generatingsuper-resolutionimagesusingtransformers-210930110353/85/Generating-super-resolution-images-using-transformers-12-320.jpg?cb=1684058196)










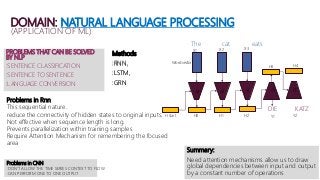
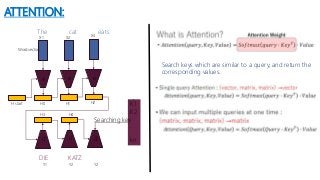
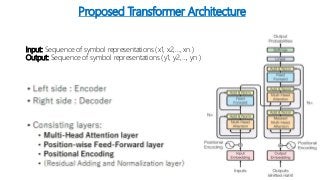
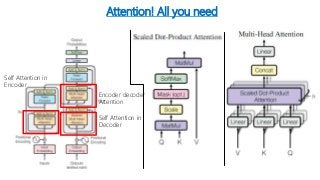
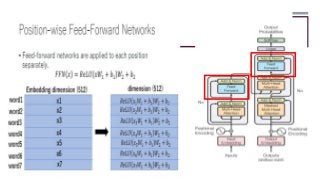

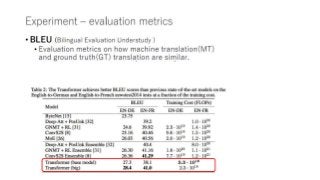


The document summarizes a research paper on using transformers for the task of natural language processing. Some key points: - Transformers use attention mechanisms to draw global dependencies between input and output without regard to sequence length, addressing limitations of RNNs and CNNs for NLP tasks. - The proposed transformer architecture contains self-attention layers in the encoder and decoder, as well as an attention mechanism between the encoder and decoder. - The transformer uses scaled dot-product attention and multi-head attention. Self-attention allows relating different positions of a single sequence to compute representations. - Other components include feedforward layers and positional encoding to inject information about the relative or absolute positions of the tokens in the sequence








![[OSGeo-KR Tech Workshop] Deep Learning for Single Image Super-Resolution](https://cdn.slidesharecdn.com/ss_thumbnails/osgeo-krdeeplearningforsingleimagesuper-resolution-180223175347-thumbnail.jpg?width=640&height=640&fit=bounds)

![ViT (Vision Transformer) Review [CDM]](https://cdn.slidesharecdn.com/ss_thumbnails/vitreviewcdm-201012184226-thumbnail.jpg?width=640&height=640&fit=bounds)


















































