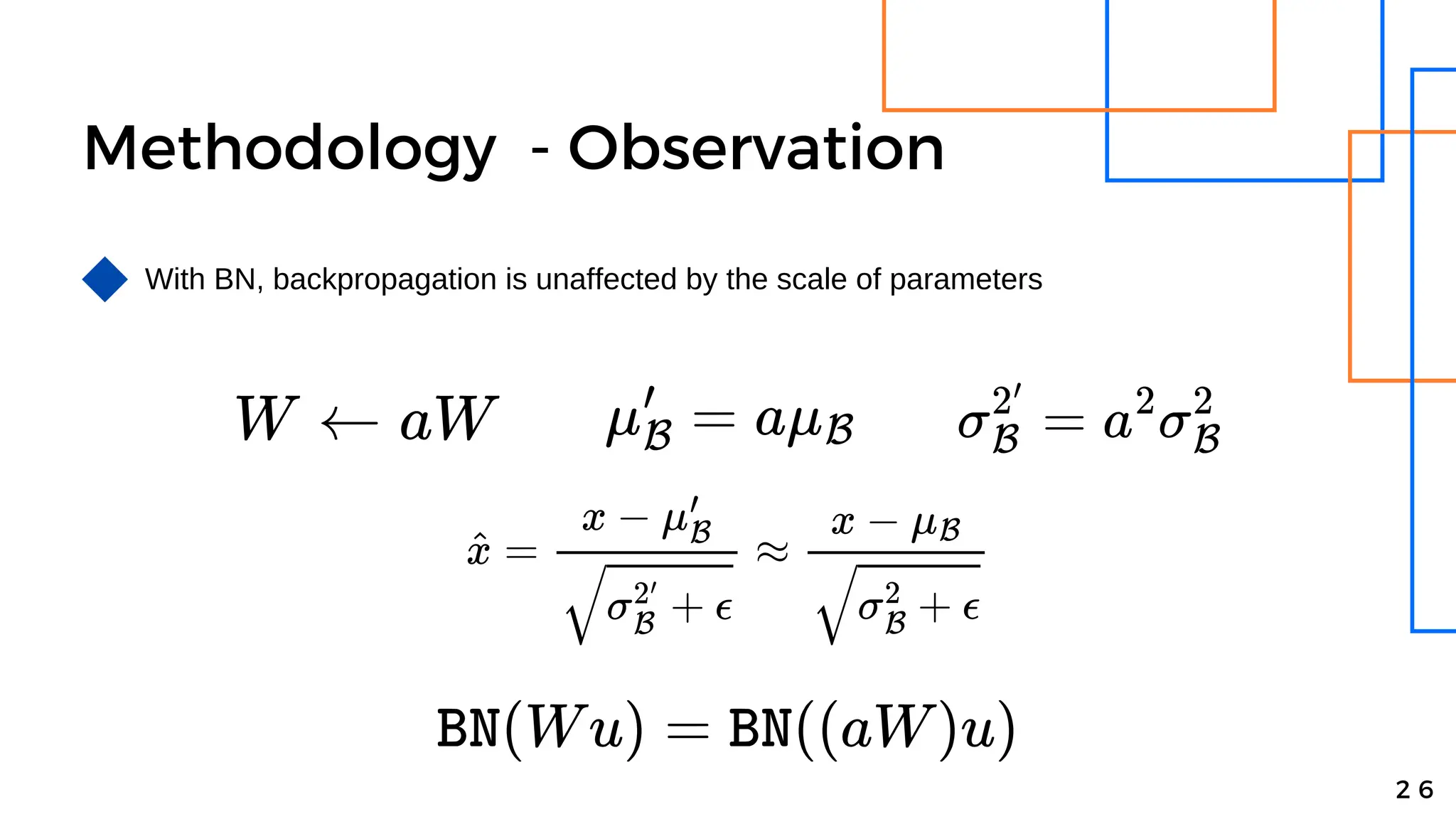
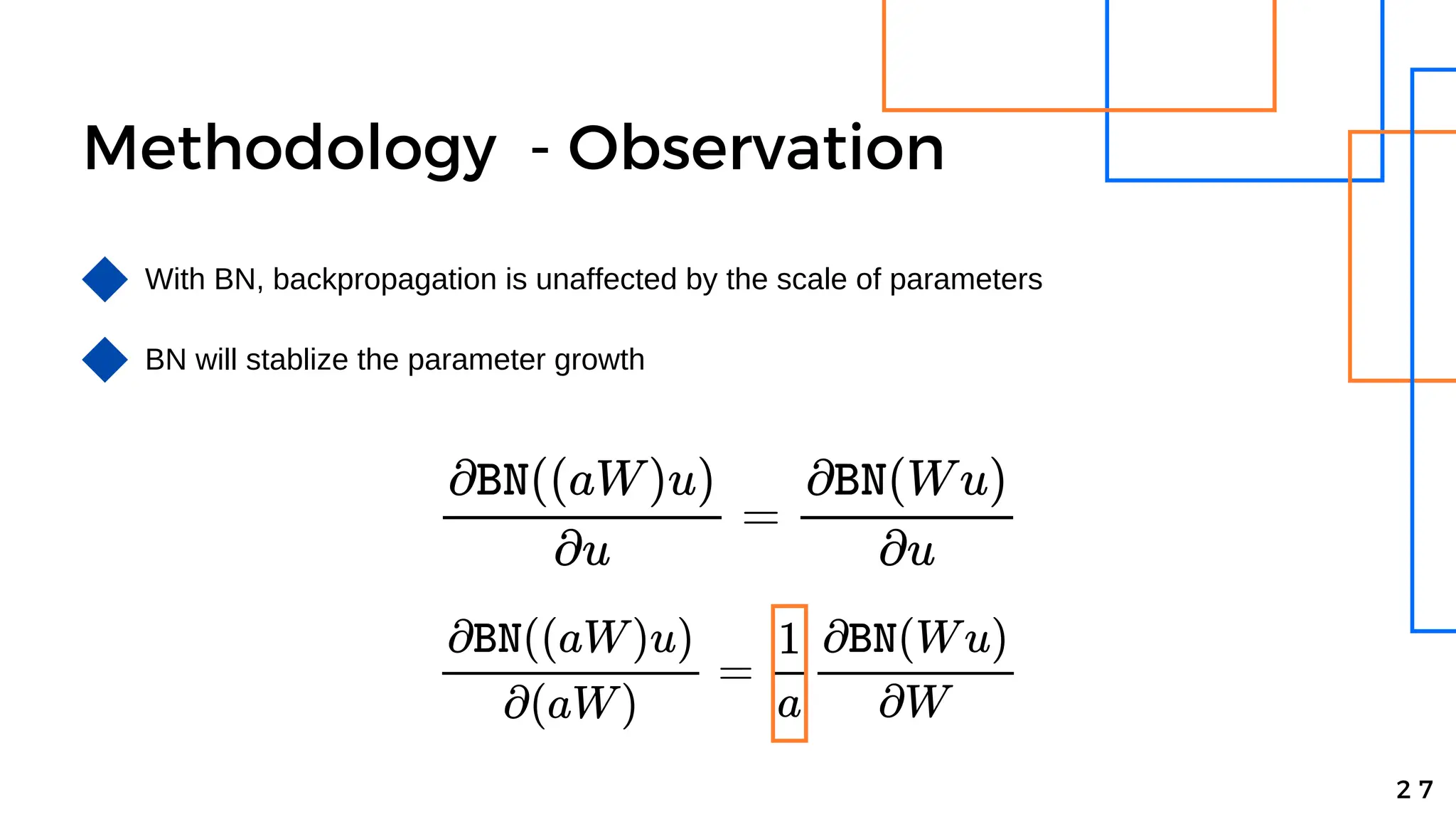
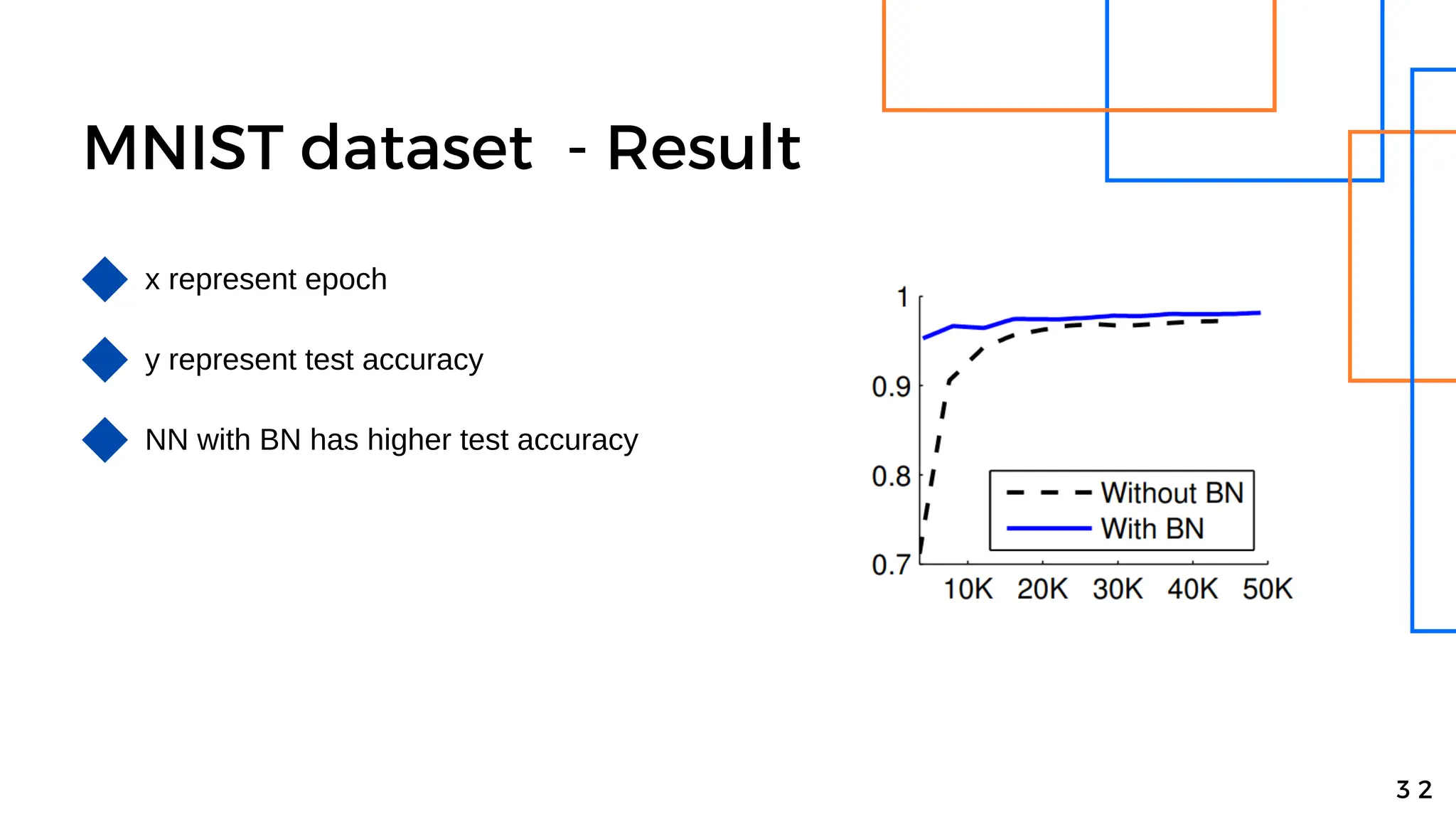
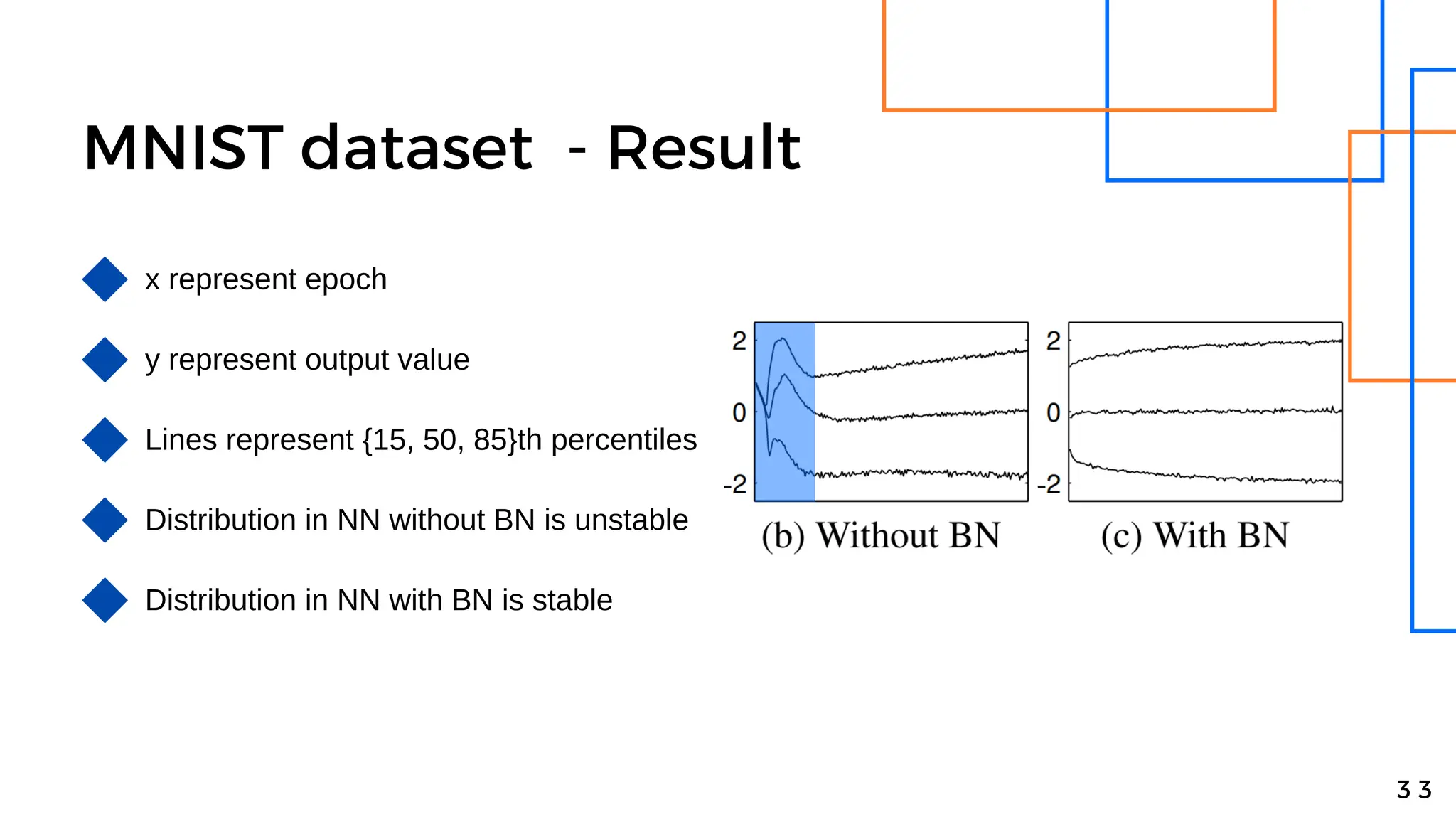
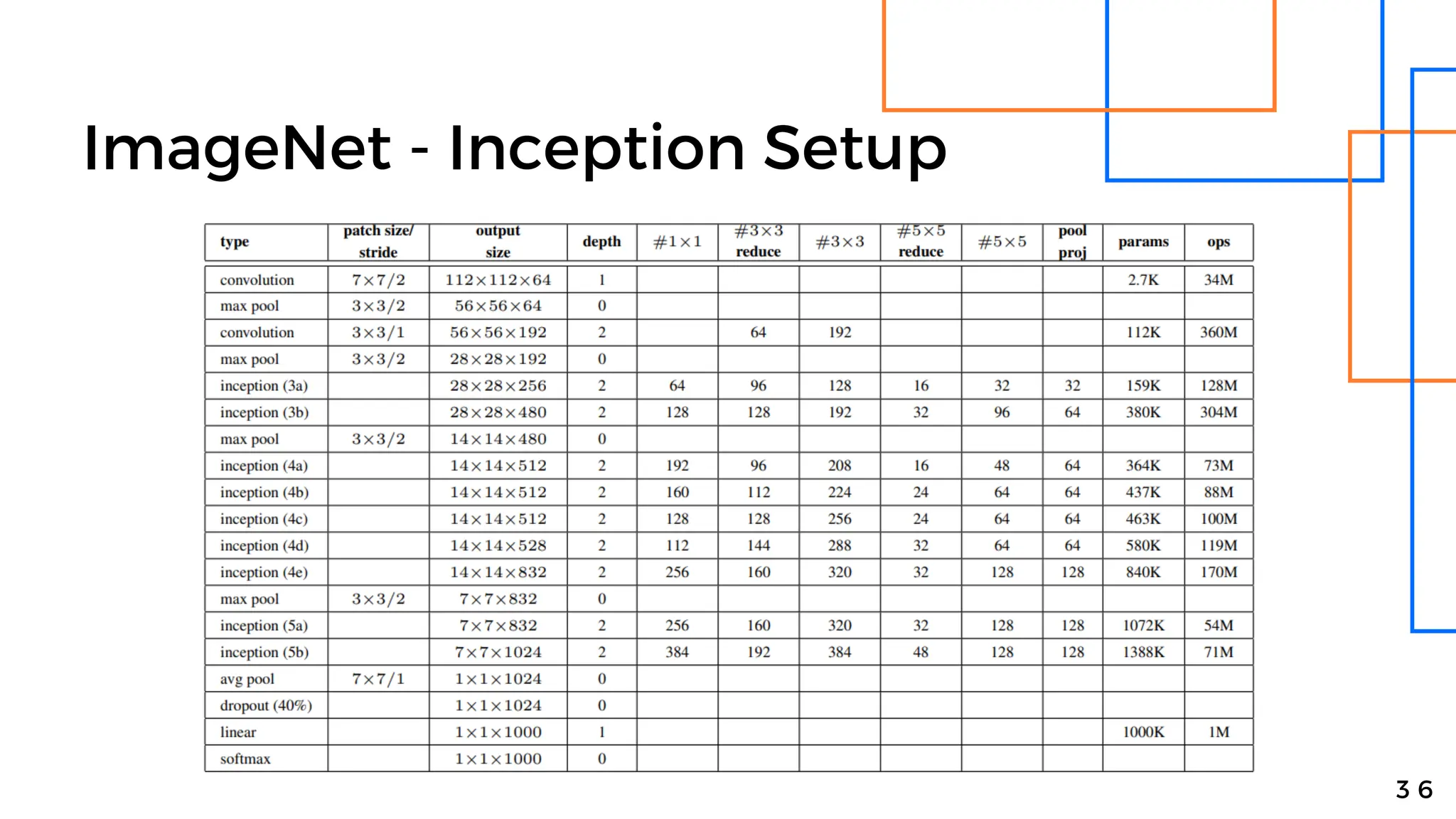
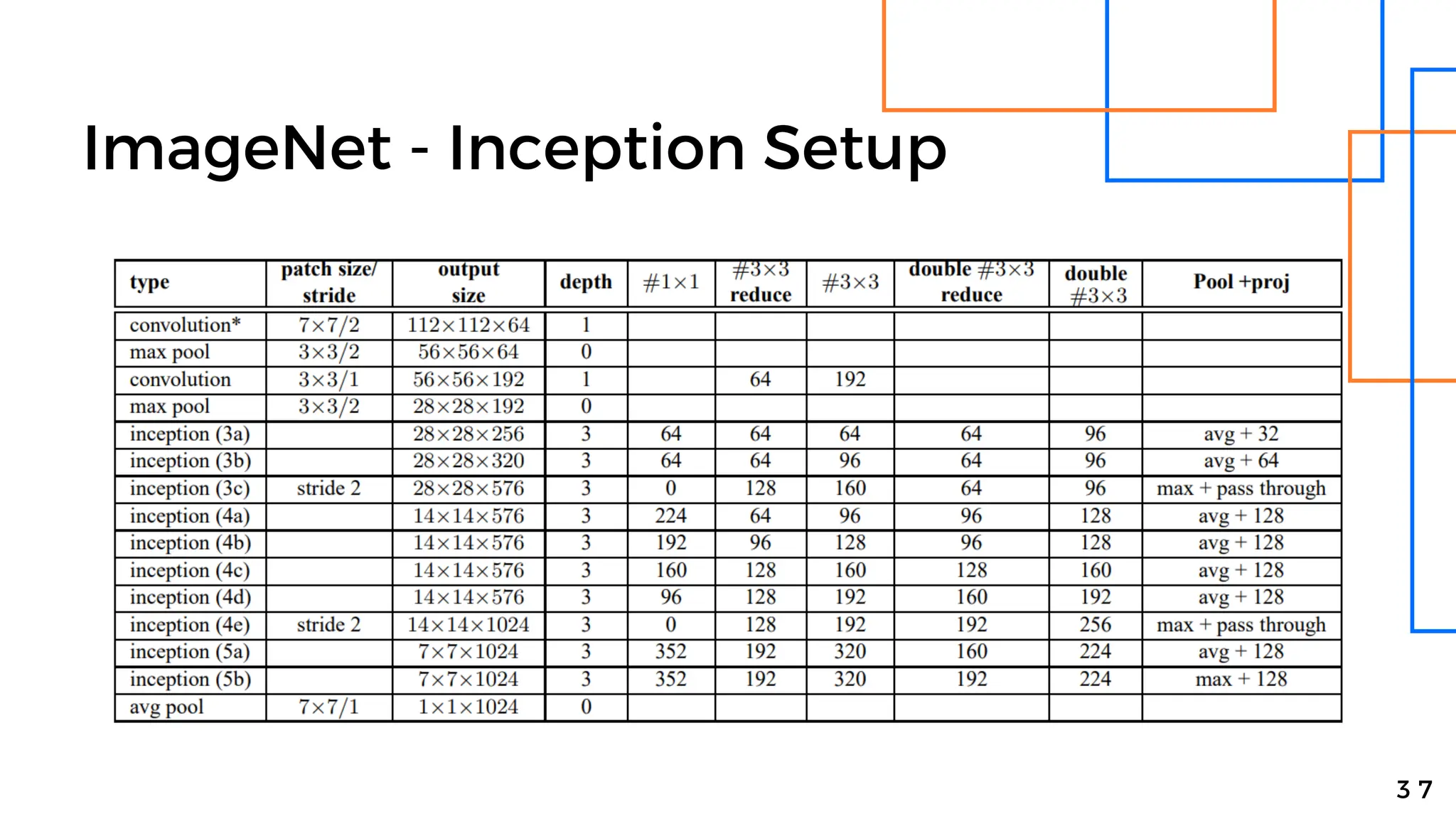
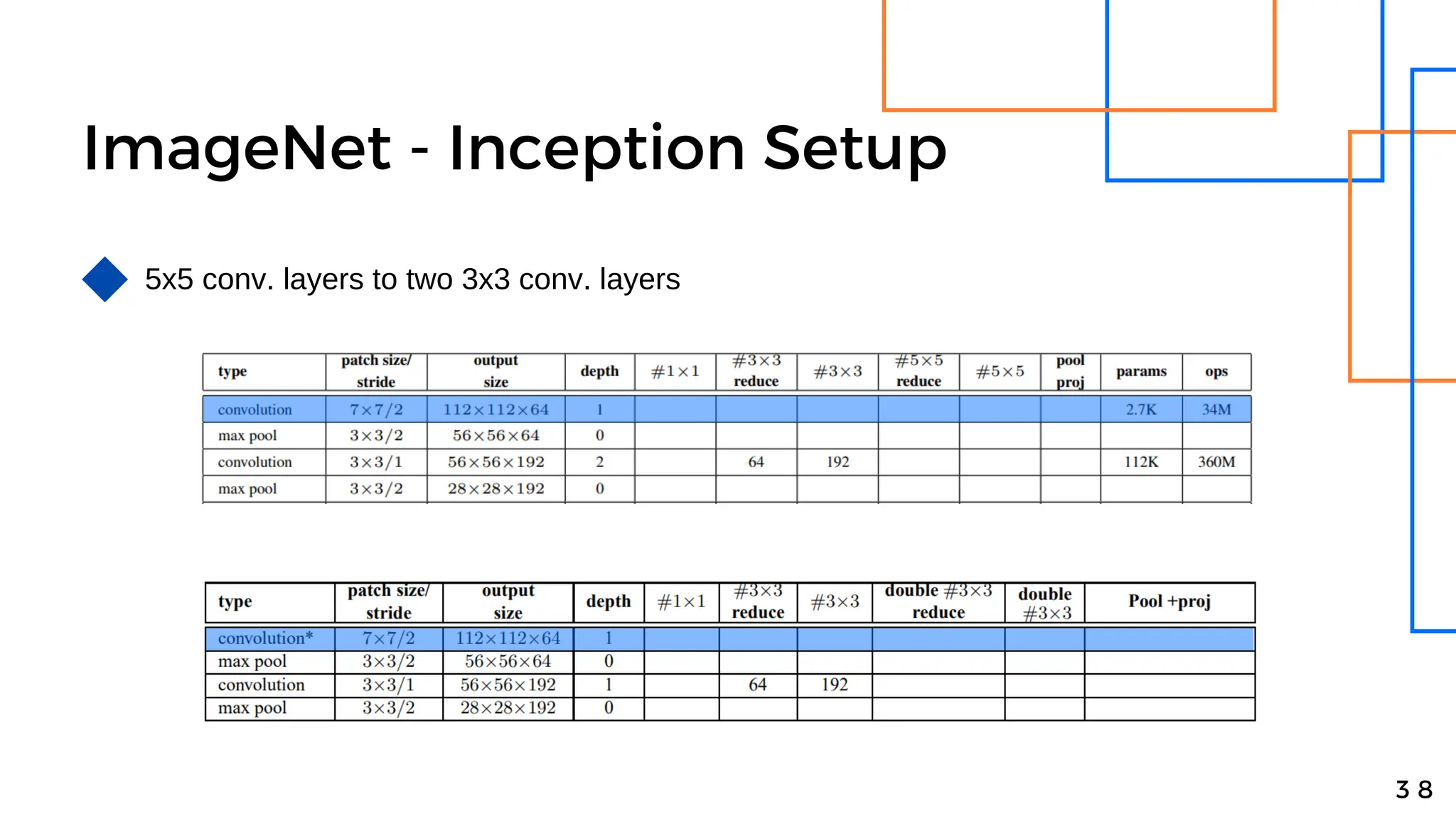
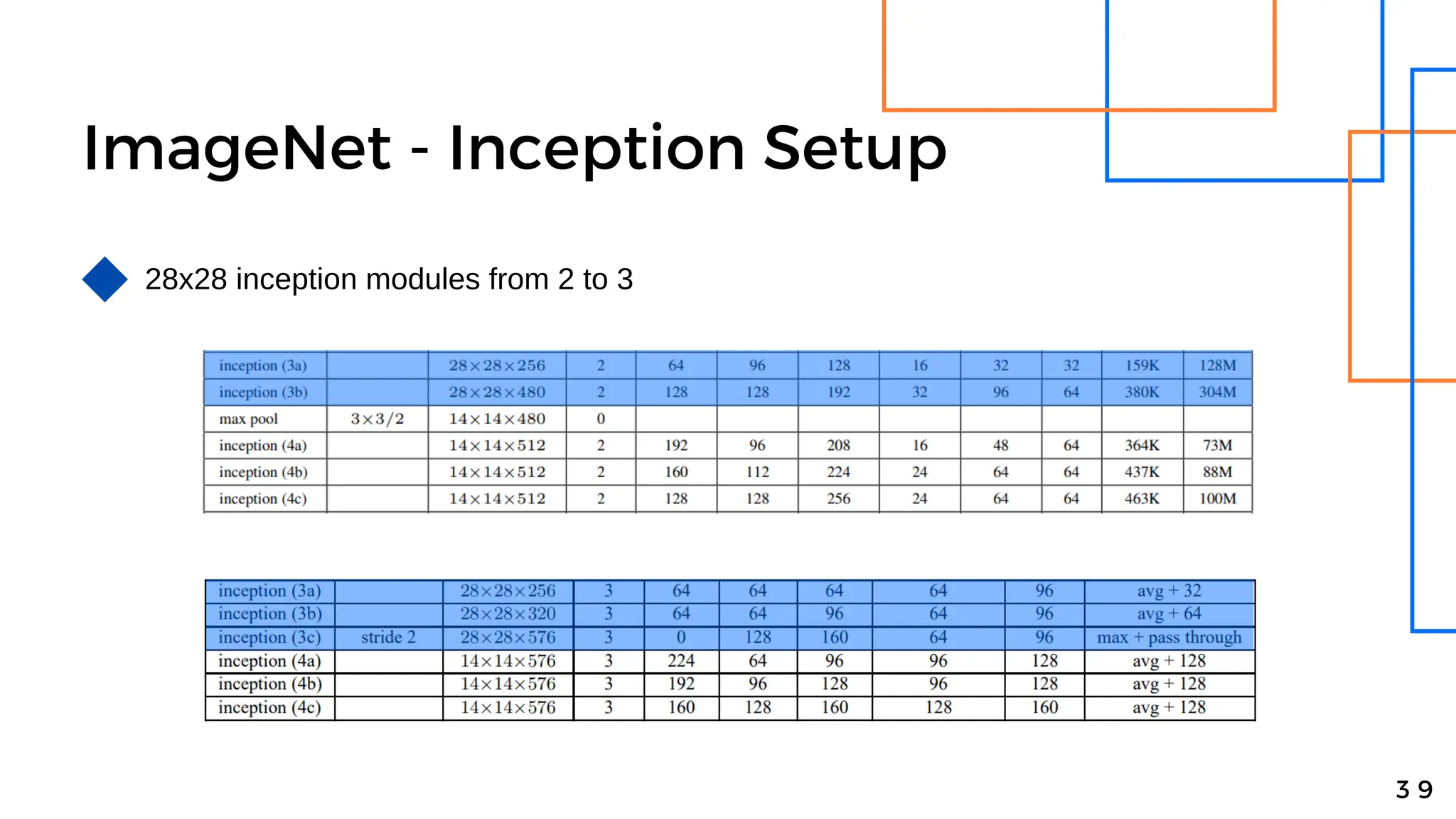
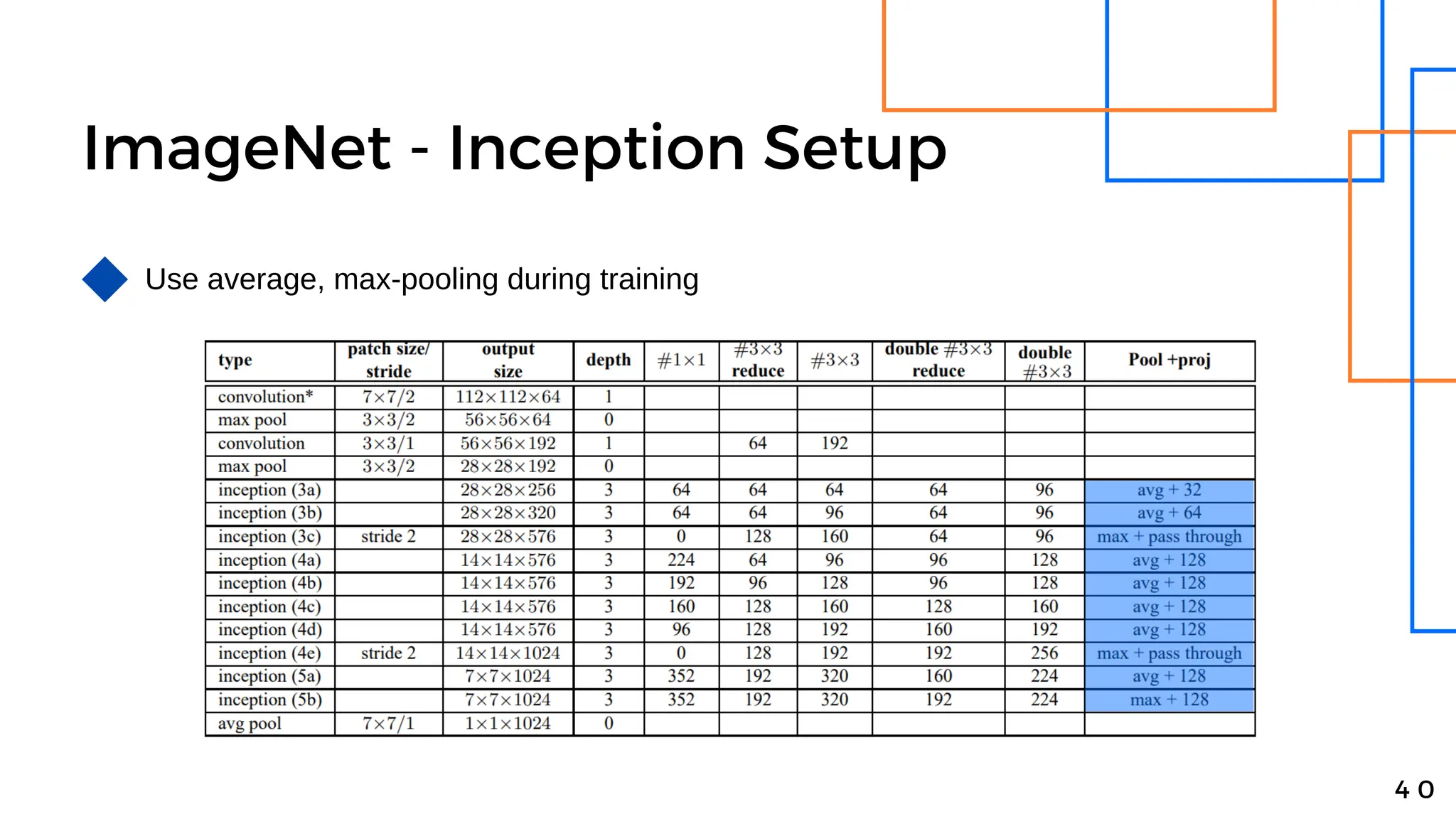
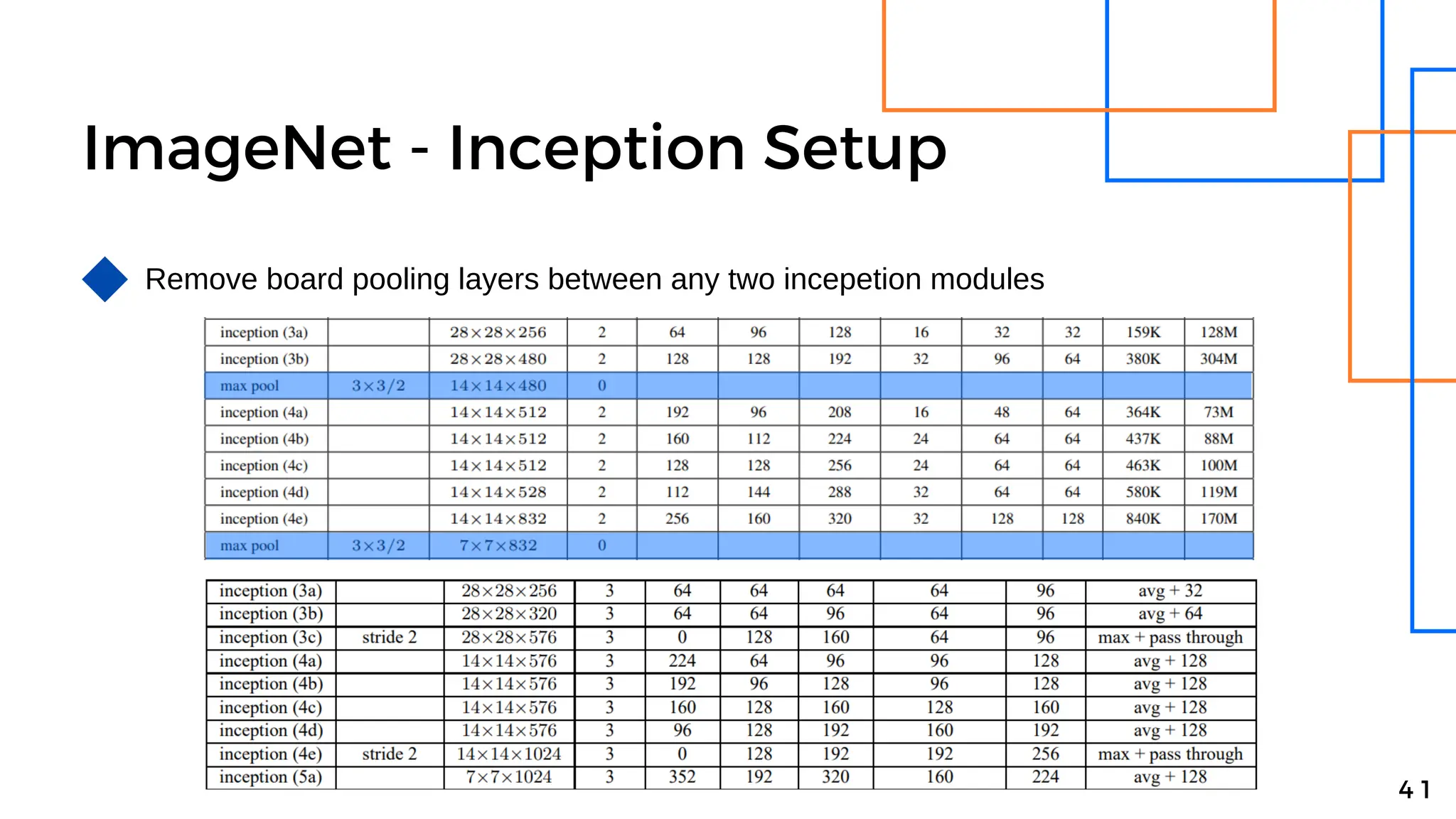
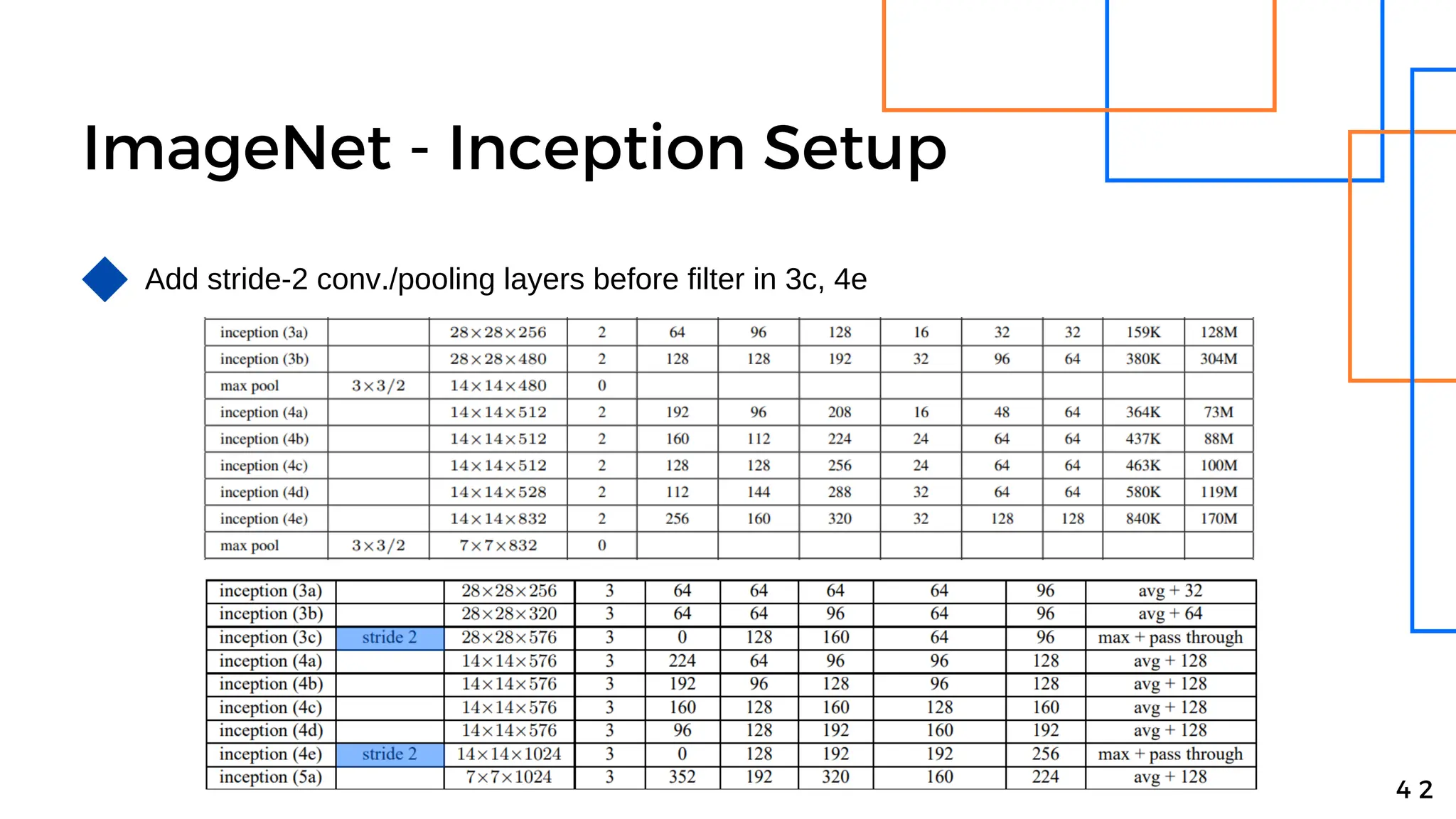
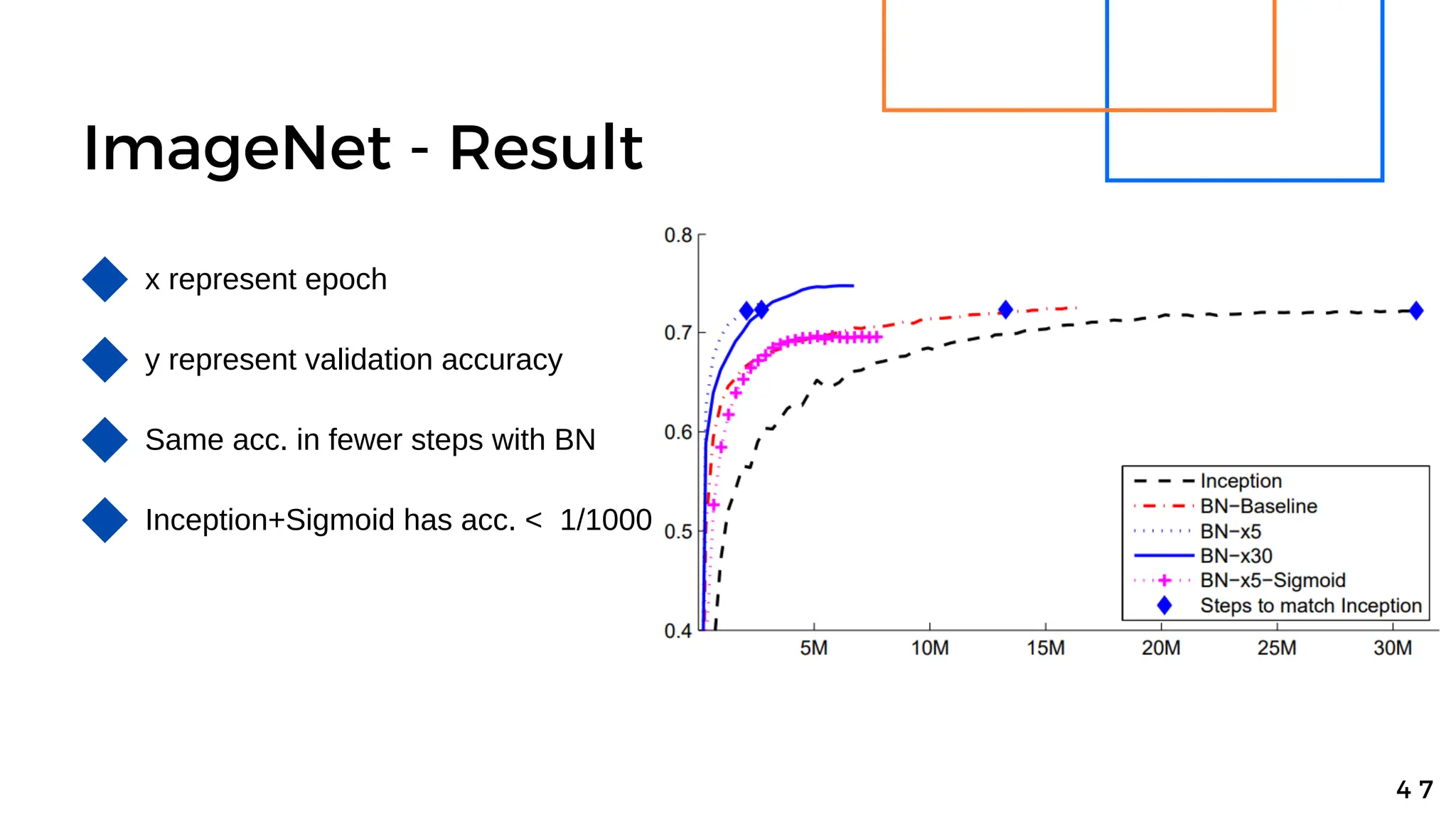
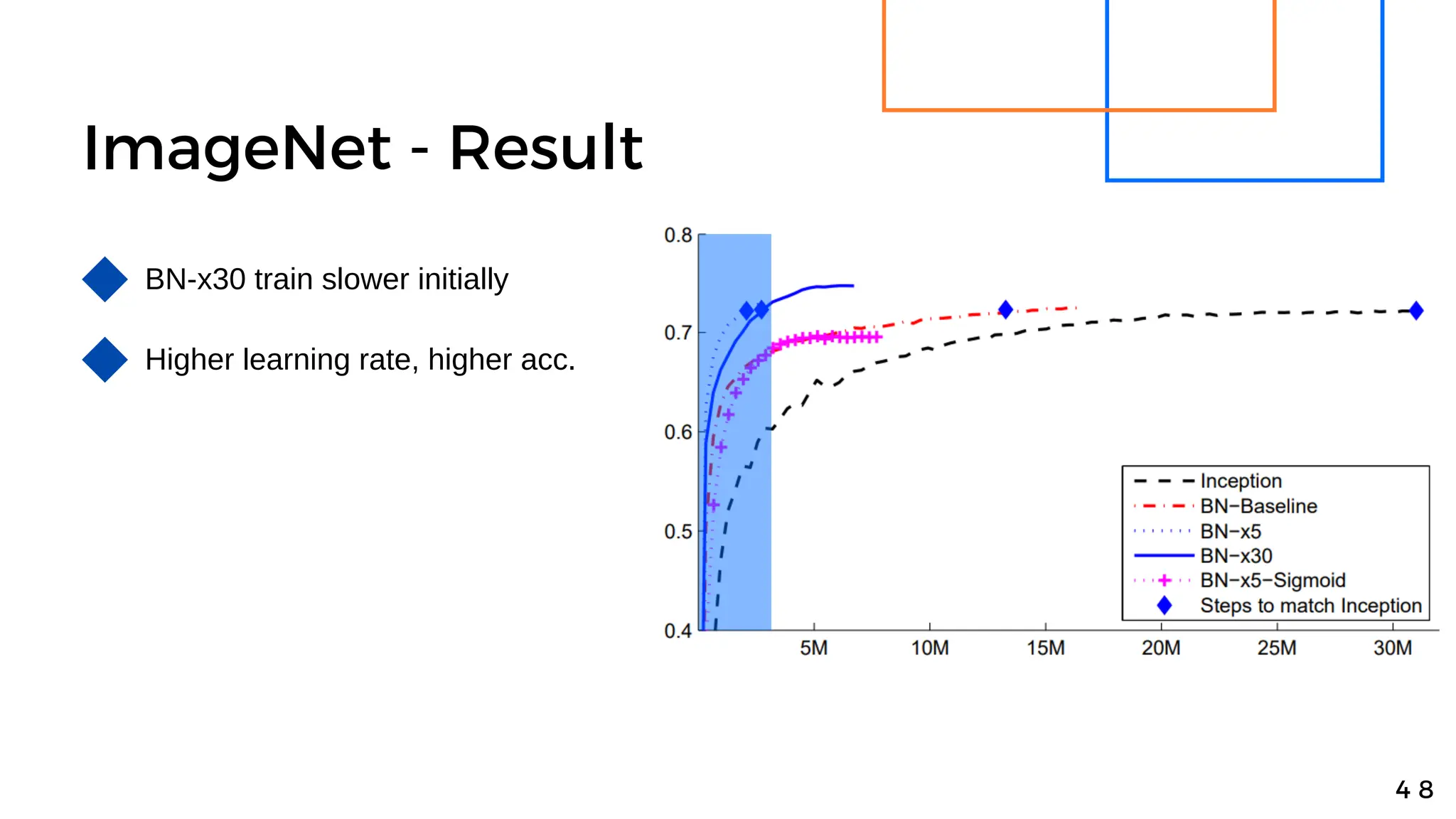
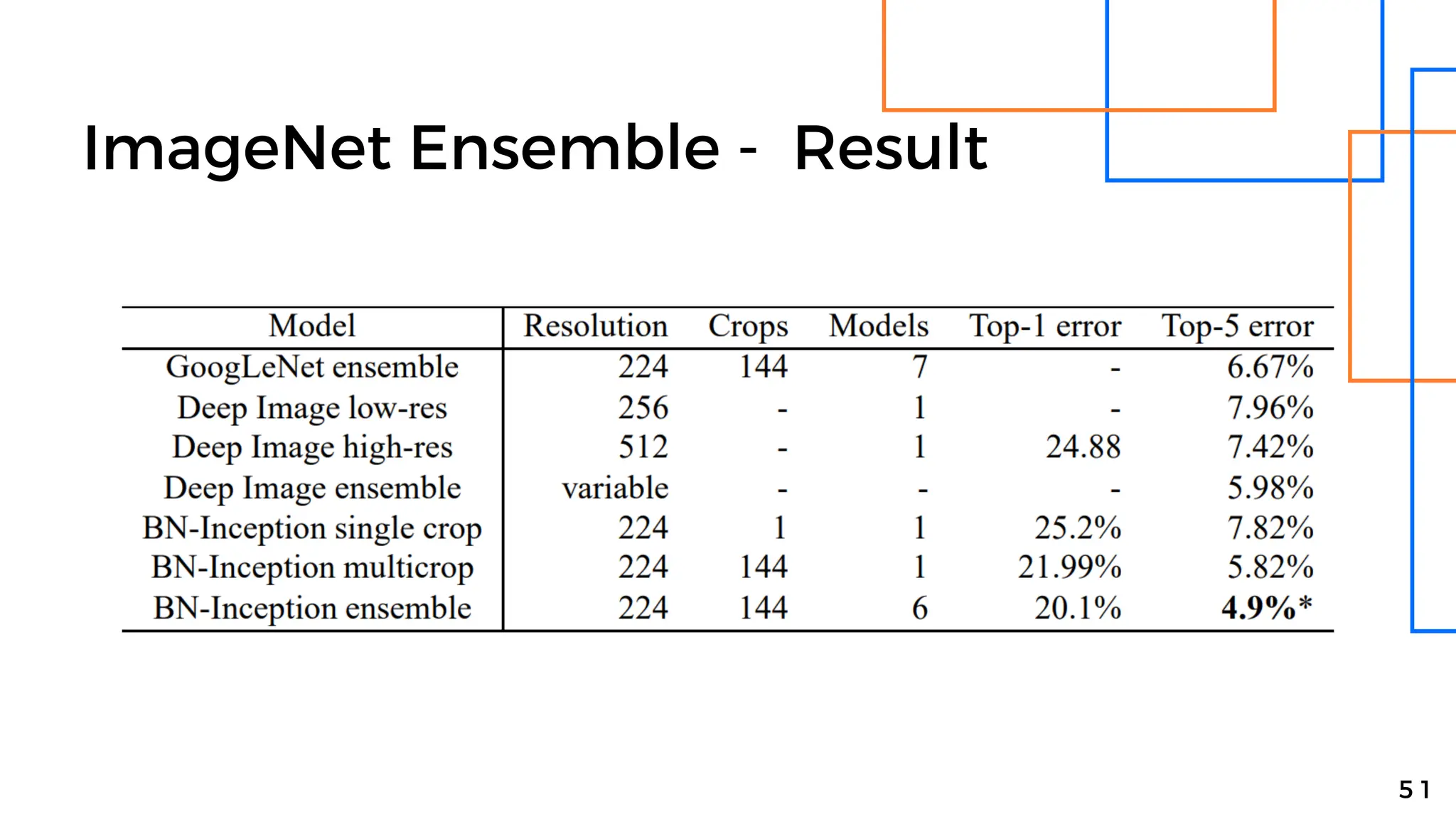
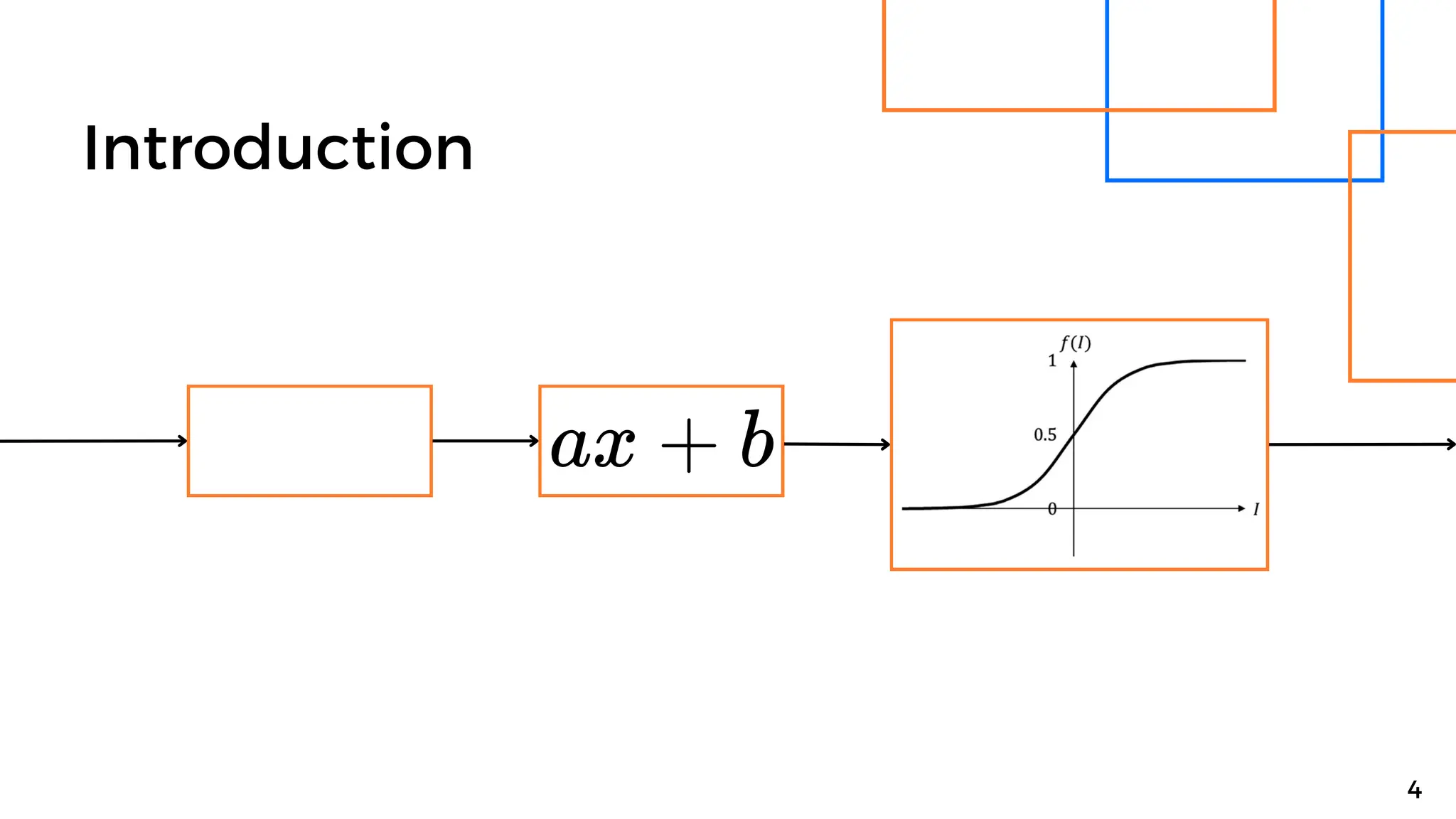
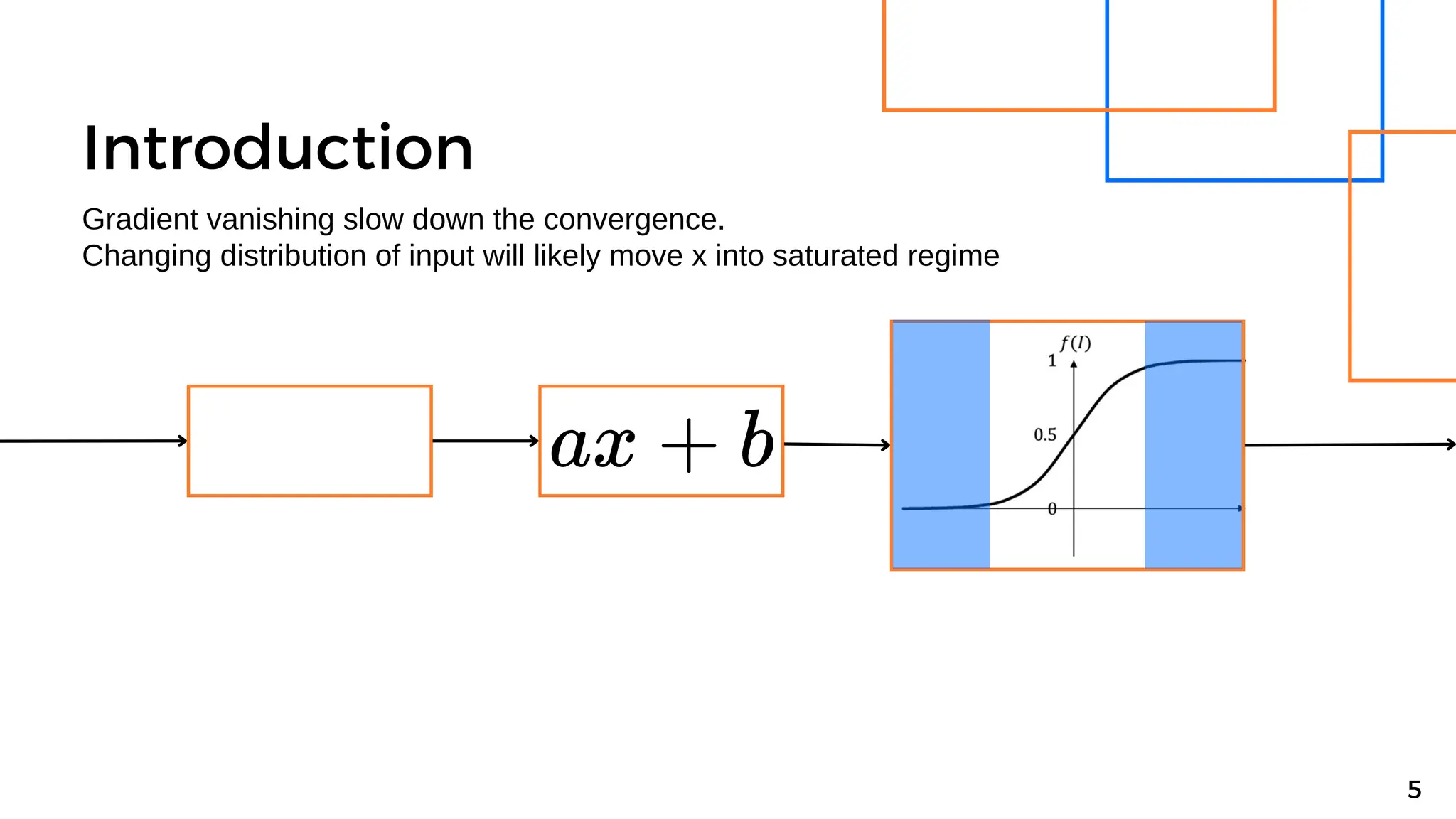
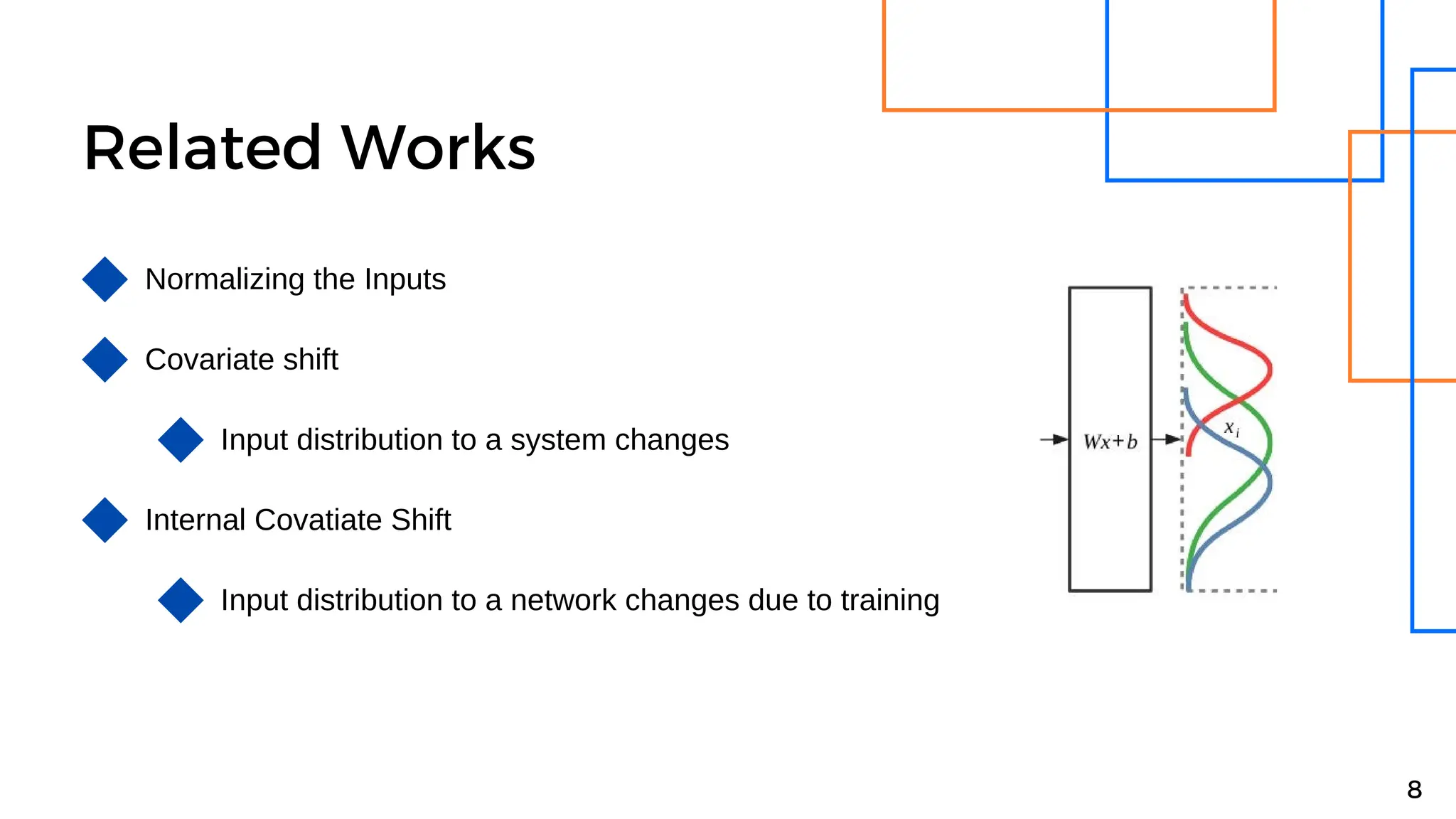
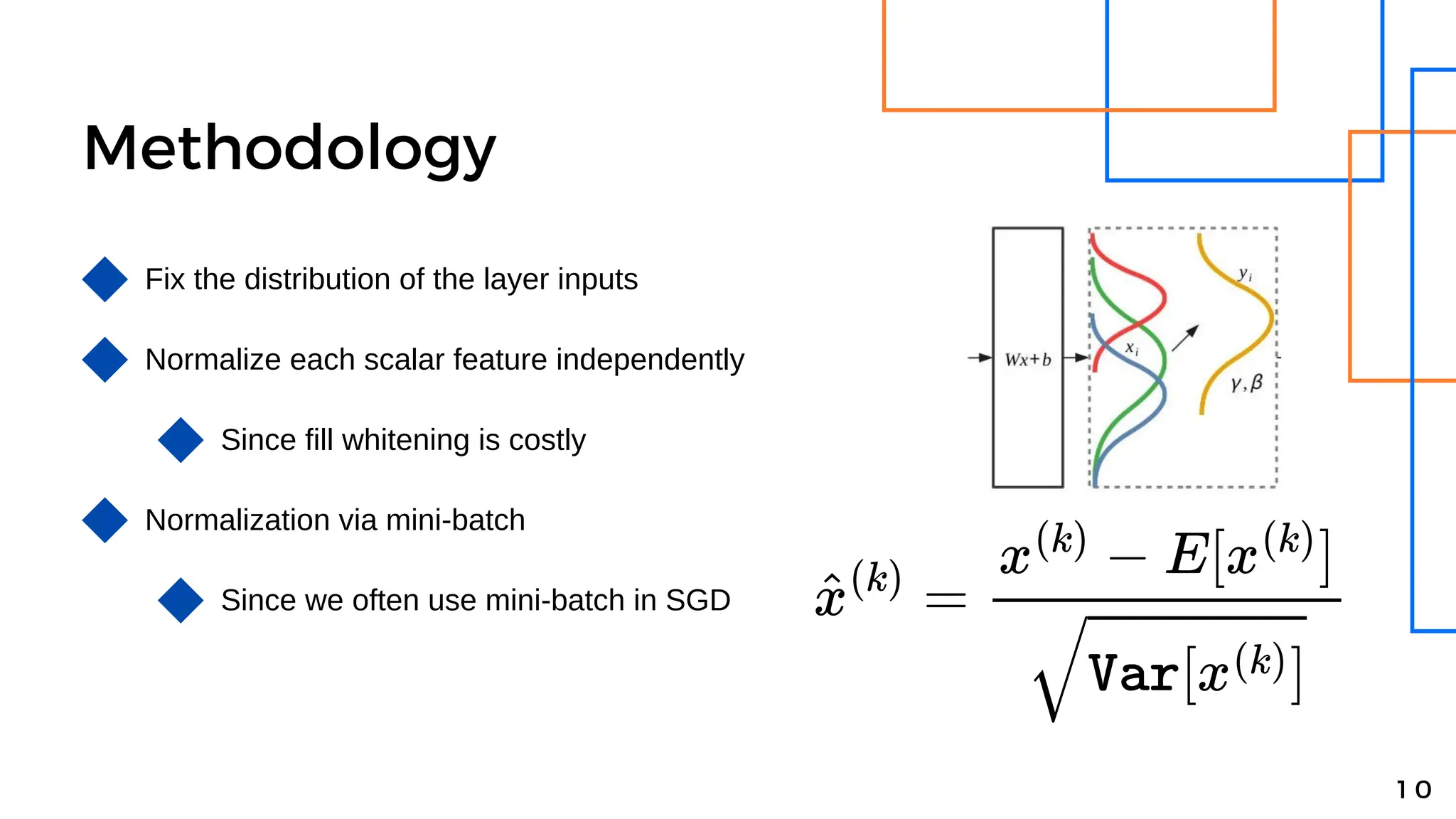
Batch normalization is a technique that normalizes the inputs to each node in a neural network layer. It reduces internal covariate shift and allows higher learning rates to be used, speeding up training. The method normalizes each feature by subtracting the batch mean and dividing by the batch standard deviation. It was shown to significantly accelerate training of state-of-the-art models on MNIST and ImageNet, requiring only a fraction of the training steps to reach the same level of accuracy compared to models without batch normalization.









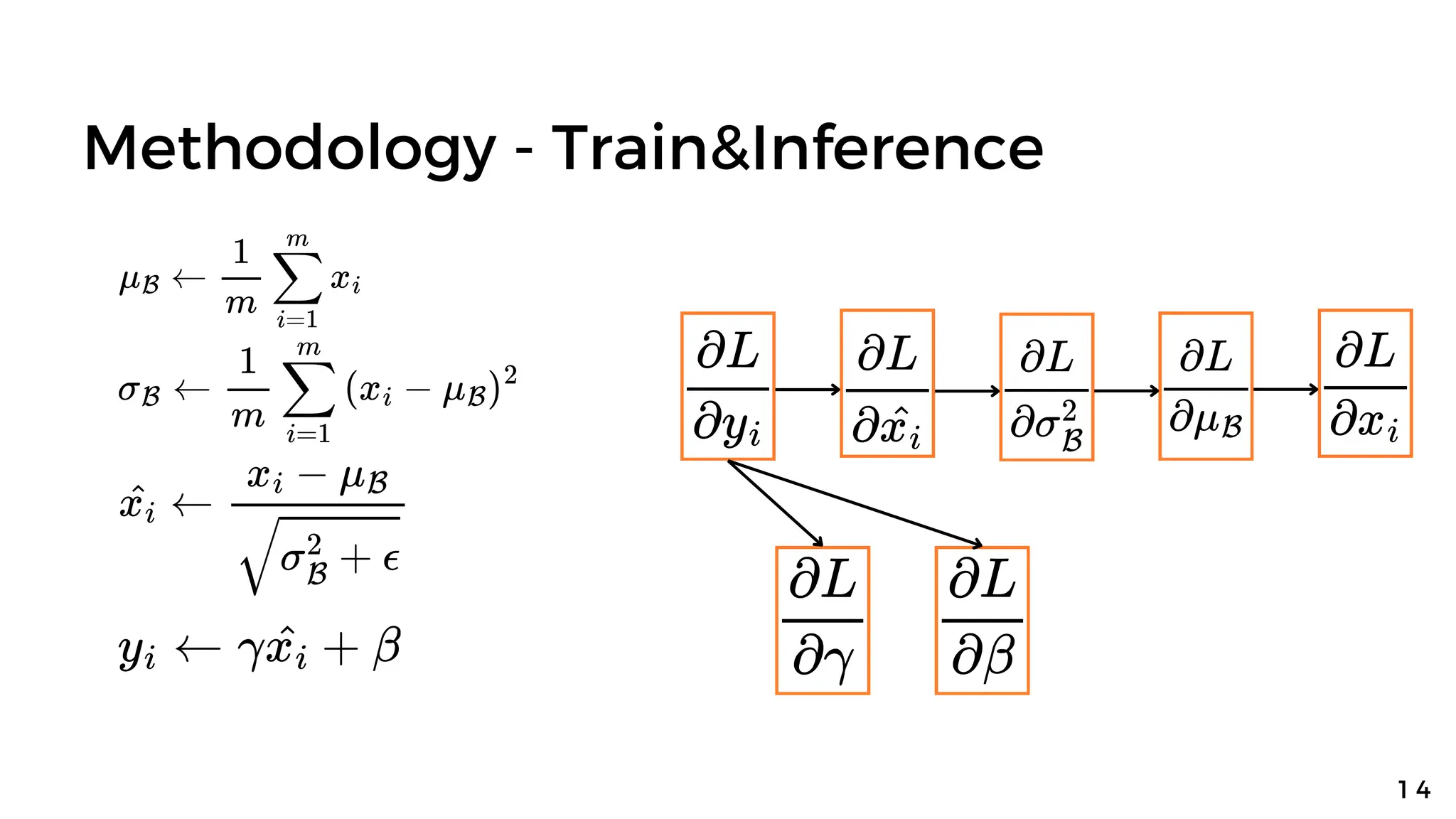


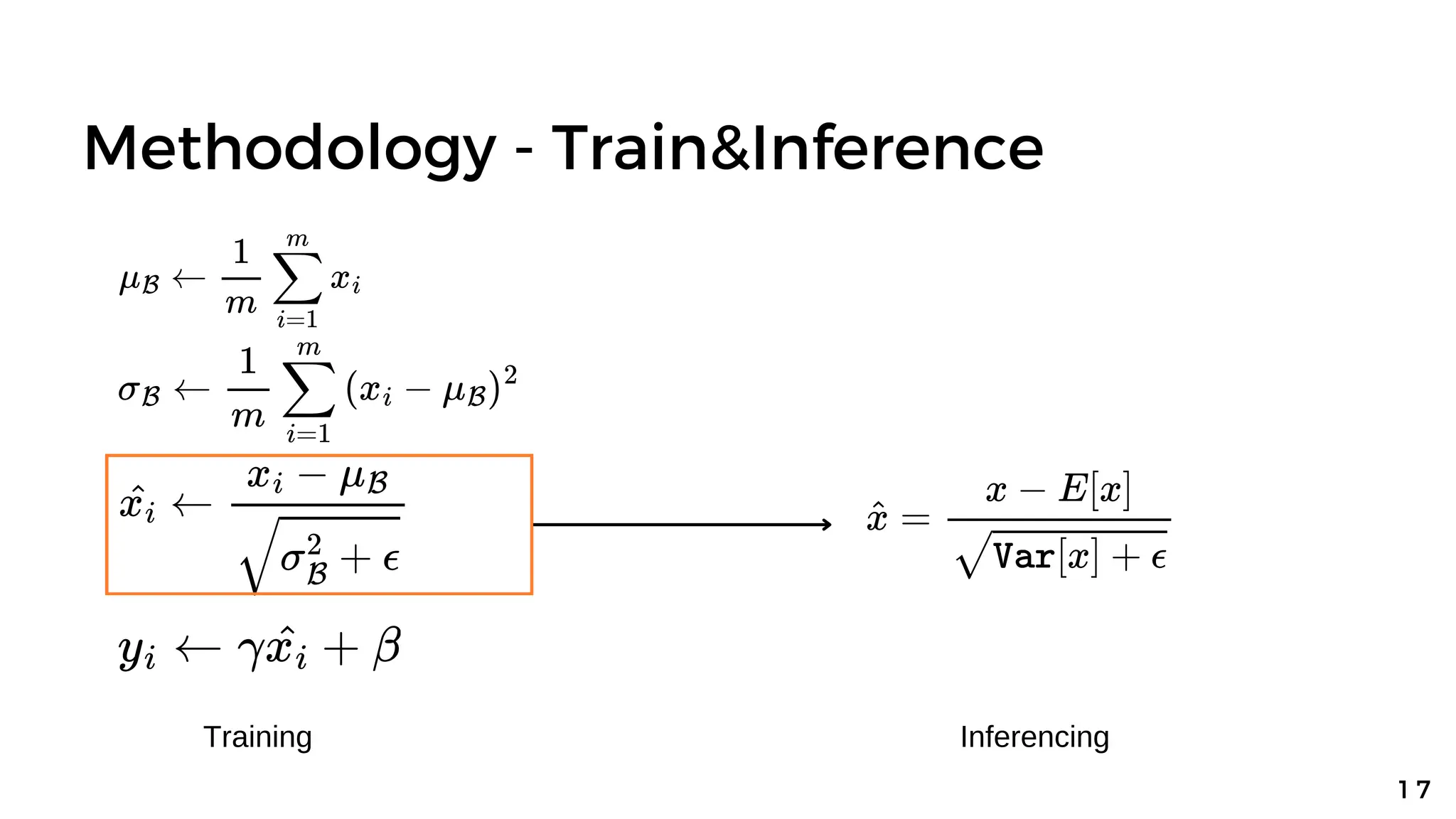
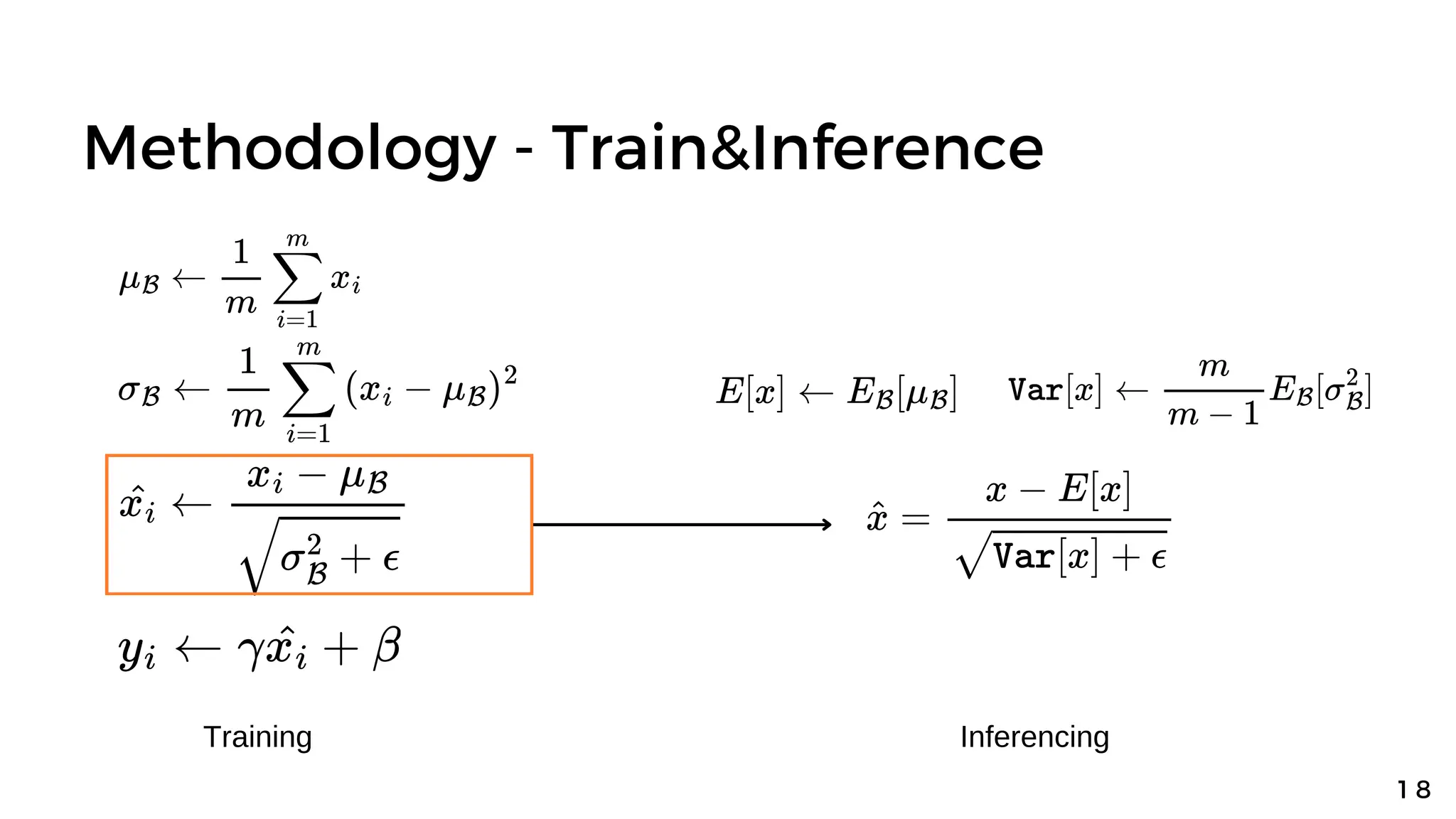
![Methodology - Train&Inference
1 9
Training Batch Normalization Network Find E[x], Var[x] and inference](https://image.slidesharecdn.com/batchnormalization-240318060431-7a70035a/75/Batch-normalization-Accelerating-Deep-Network-Training-by-Reducing-Internal-Covariate-Shift-19-2048.jpg)
![Methodology - Train&Inference
2 0
Training Batch Normalization Network Find E[x], Var[x] and inference](https://image.slidesharecdn.com/batchnormalization-240318060431-7a70035a/75/Batch-normalization-Accelerating-Deep-Network-Training-by-Reducing-Internal-Covariate-Shift-20-2048.jpg)
![Methodology - Train&Inference
2 1
Training Batch Normalization Network Find E[x], Var[x] and inference](https://image.slidesharecdn.com/batchnormalization-240318060431-7a70035a/75/Batch-normalization-Accelerating-Deep-Network-Training-by-Reducing-Internal-Covariate-Shift-21-2048.jpg)
![Methodology - Train&Inference
2 2
Training Batch Normalization Network Find E[x], Var[x] and inference](https://image.slidesharecdn.com/batchnormalization-240318060431-7a70035a/75/Batch-normalization-Accelerating-Deep-Network-Training-by-Reducing-Internal-Covariate-Shift-22-2048.jpg)