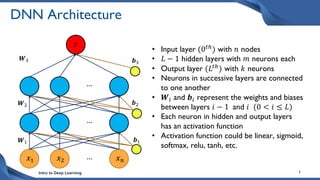
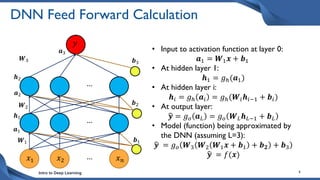
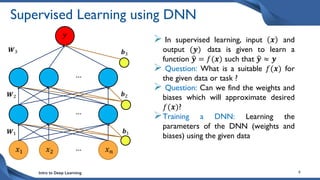
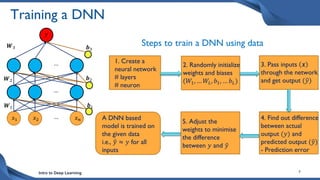
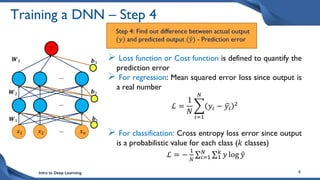
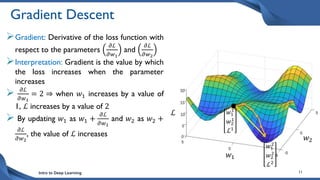
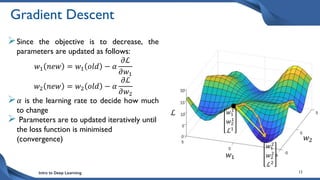
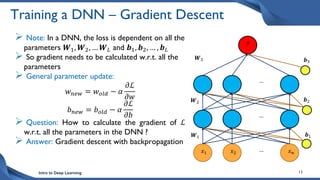
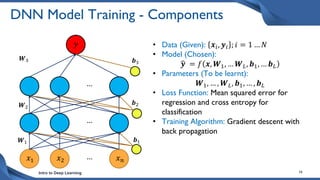
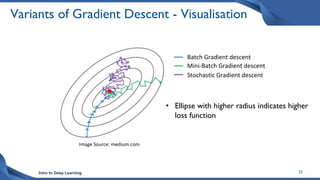
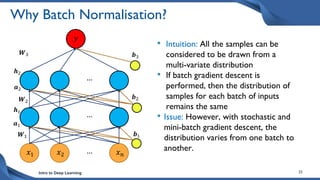
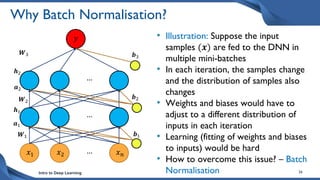
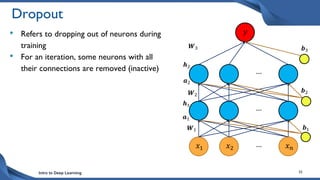
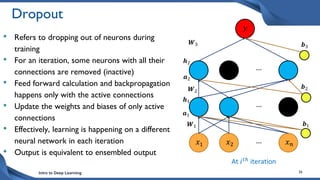
This document discusses training deep neural network (DNN) models. It explains that DNNs have an input layer, multiple hidden layers, and an output layer connected by weights and biases. Training a DNN involves initializing the weights and biases randomly, passing inputs through the network to get outputs, calculating the loss between actual and predicted outputs, and updating the weights to minimize loss using gradient descent and backpropagation. Gradient descent with backpropagation calculates the gradient of the loss with respect to each weight and bias by applying the chain rule to propagate loss backwards through the network.





















































![[DSC 2016] 系列活動:李宏毅 / 一天搞懂深度學習](https://cdn.slidesharecdn.com/ss_thumbnails/1-160521014039-thumbnail.jpg?width=640&height=640&fit=bounds)





















![5G Explained! A High Level Overview [Introduction]](https://cdn.slidesharecdn.com/ss_thumbnails/5gexplainedahighleveloverview-260119165306-cc137a3e-thumbnail.jpg?width=640&height=640&fit=bounds)











