Download to read offline



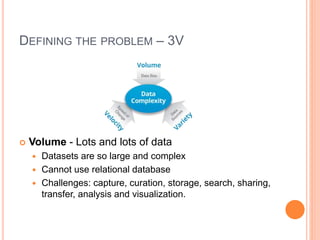


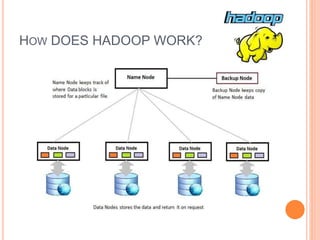
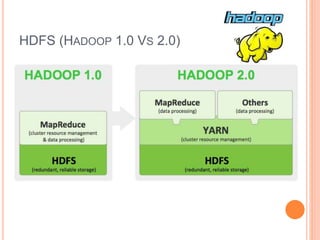
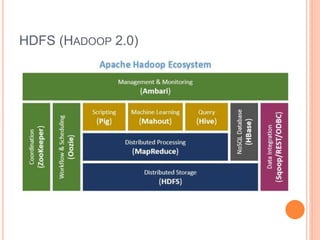

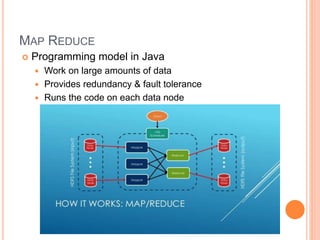

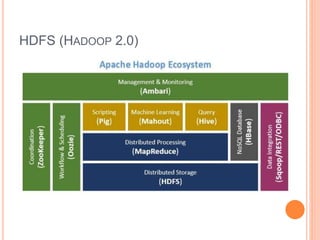








This document discusses big data solutions and introduces Hadoop. It defines common big data problems related to volume, velocity, and variety of data. Traditional storage does not work well for this type of unstructured data. Hadoop provides solutions through HDFS for storage, MapReduce for processing, and additional tools like HBase, Pig, Hive, Zookeeper, and Spark to handle different data and analytic needs. Each tool is described briefly in terms of its purpose and how it works with Hadoop.




































































![제 23회 보아즈(BOAZ) 빅데이터 컨퍼런스 - [MBOAX] : ABSA를 활용한 소비자 반응 분석 기반 운영 효율화 대시보드 설계](https://cdn.slidesharecdn.com/ss_thumbnails/3-1boaz23rdconferencemboax-260203102709-9d519923-thumbnail.jpg?width=640&height=640&fit=bounds)













