Downloaded 74 times



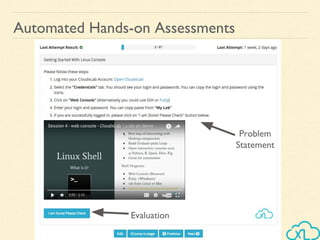
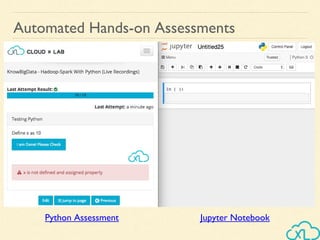
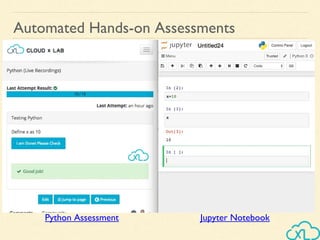



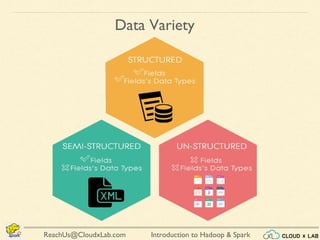
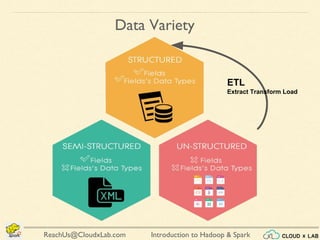
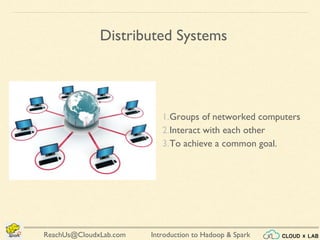




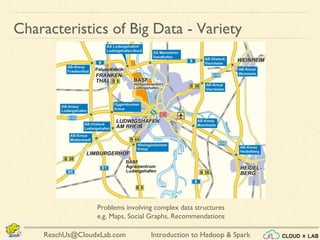



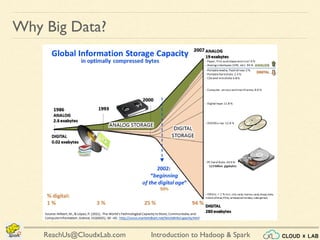
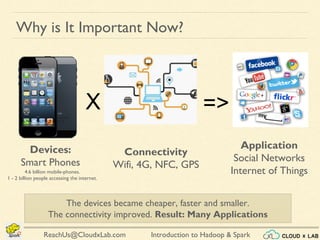
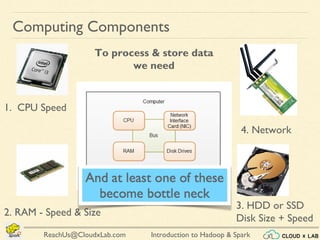



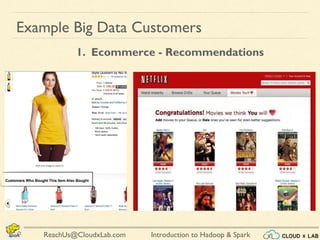
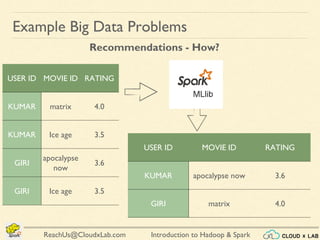

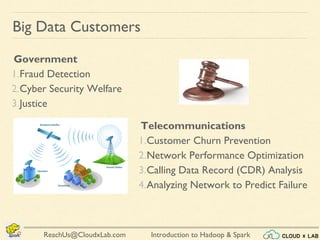



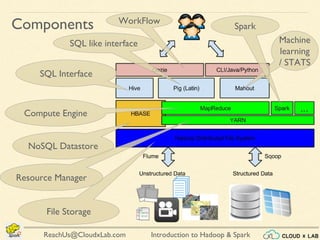

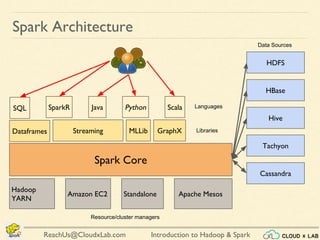


The document provides an overview of a course on big data using Hadoop and Spark, consisting of 18 sessions. It covers introductory topics such as big data characteristics, distributed systems, and computing components, along with various applications and use cases in sectors like ecommerce and healthcare. Key tools and technologies mentioned include Apache Hadoop, Apache Spark, and several big data solutions.












































































![5G Explained! A High Level Overview [Introduction]](https://cdn.slidesharecdn.com/ss_thumbnails/5gexplainedahighleveloverview-260119165306-cc137a3e-thumbnail.jpg?width=640&height=640&fit=bounds)










