Downloaded 74 times




















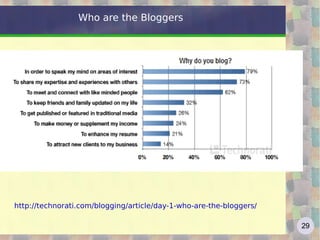










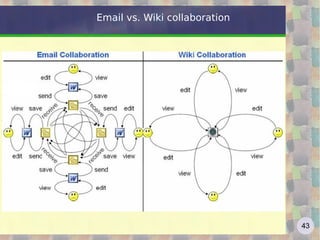





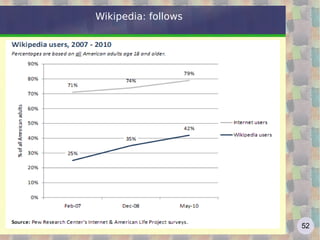
























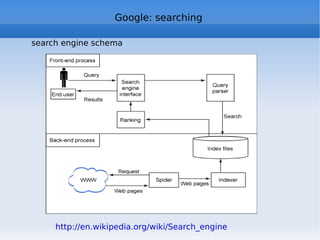










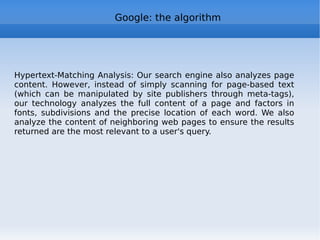



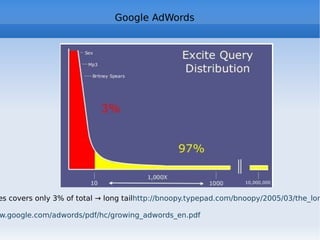


































































![Google: the algorithm The simplified formula http://en.wikipedia.org/wiki/PageRank Where: * PR[A] is PageRank value for A page * PR[B] ... PR[n] are PageRank values for pages B ... n linking to A * L[B] ... L[n] is the total numer of links in pages B ... n * d (damping factor) is the probability that an imaginary surfer who is randomly clicking on links will go on clicking. it is generally assumed that the damping factor will be set around 0.85. It represents the PageRank percentage passing from one page to another.](https://image.slidesharecdn.com/web2-0-2011-eng-110613041641-phpapp01/85/Web-2-0-a-course-181-320.jpg)



The document discusses the topics of Web 2.0 including blogs, wikis, tags, and social networks. It provides an introduction and program for a course on Web 2.0 that will cover definitions of key concepts, examples like blogs and wikis, technical specifications, tagging and social bookmarking, and social networking sites. The course will also discuss theories related to Web 2.0 and evaluate students based on exercises and a final presentation.











































































































