








![char cb[40];
unsigned int len,
data_len,
mac_len,
csum;
unsigned char local_df,
cloned,
pkt_type,
ip_summed;
__u32 priority;
unsigned short protocol,
security;
void (*destructor)(struct sk_buff *skb);
#ifdef CONFIG_NETFILTER
unsigned long nfmark;
__u32 nfcache;
__u32 nfctinfo;
struct nf_conntrack *nfct;
//control buffer, used internally
// Length of actual data
//checksum
//head may be cloned
//packet class
//driver fed us ip checksum
//packet queuing priority
//packet protocol from driver
// security level of packet
//destructor function](https://image.slidesharecdn.com/skbppt-160331101144/75/Sockets-and-Socket-Buffer-12-2048.jpg)

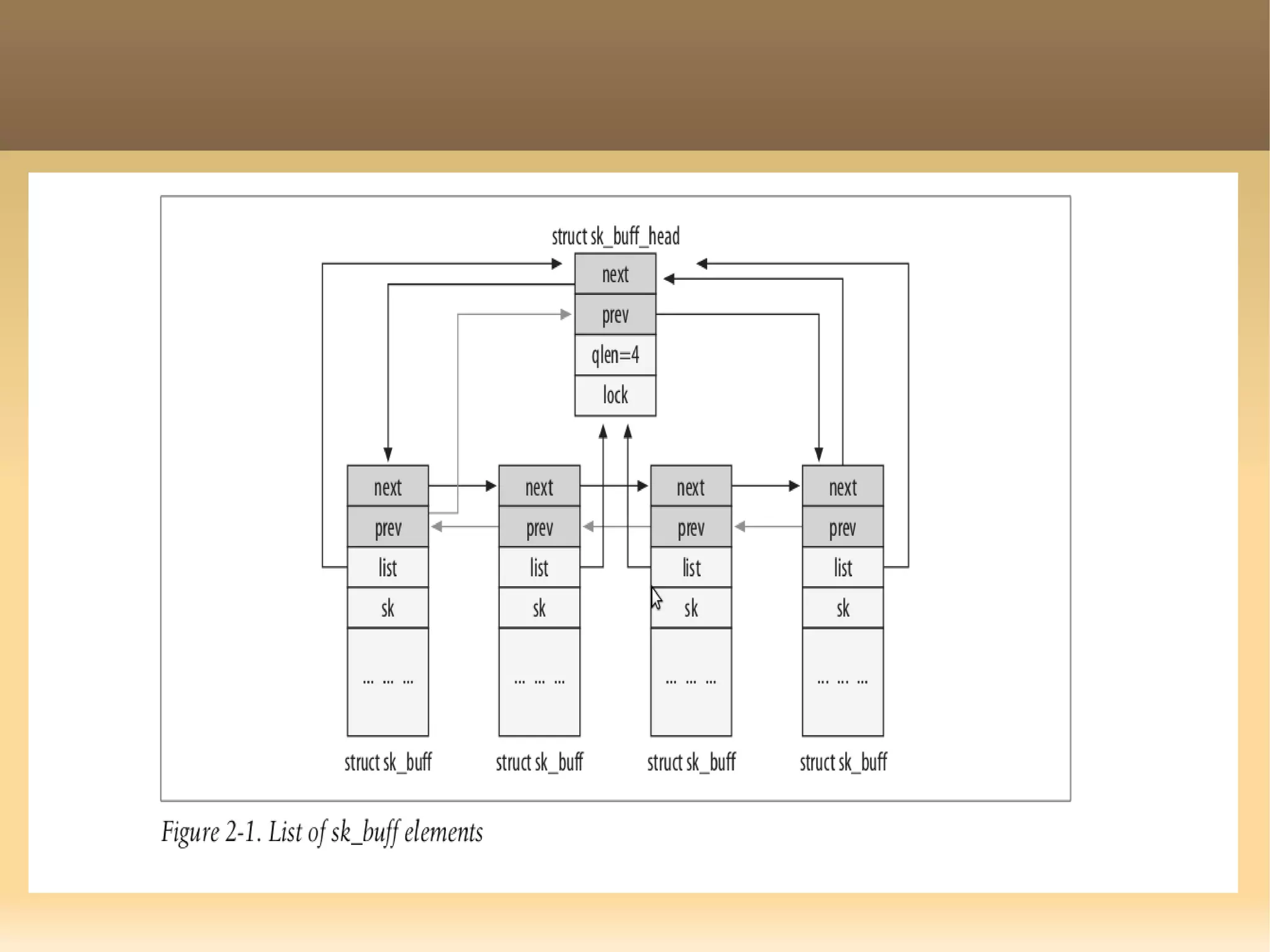


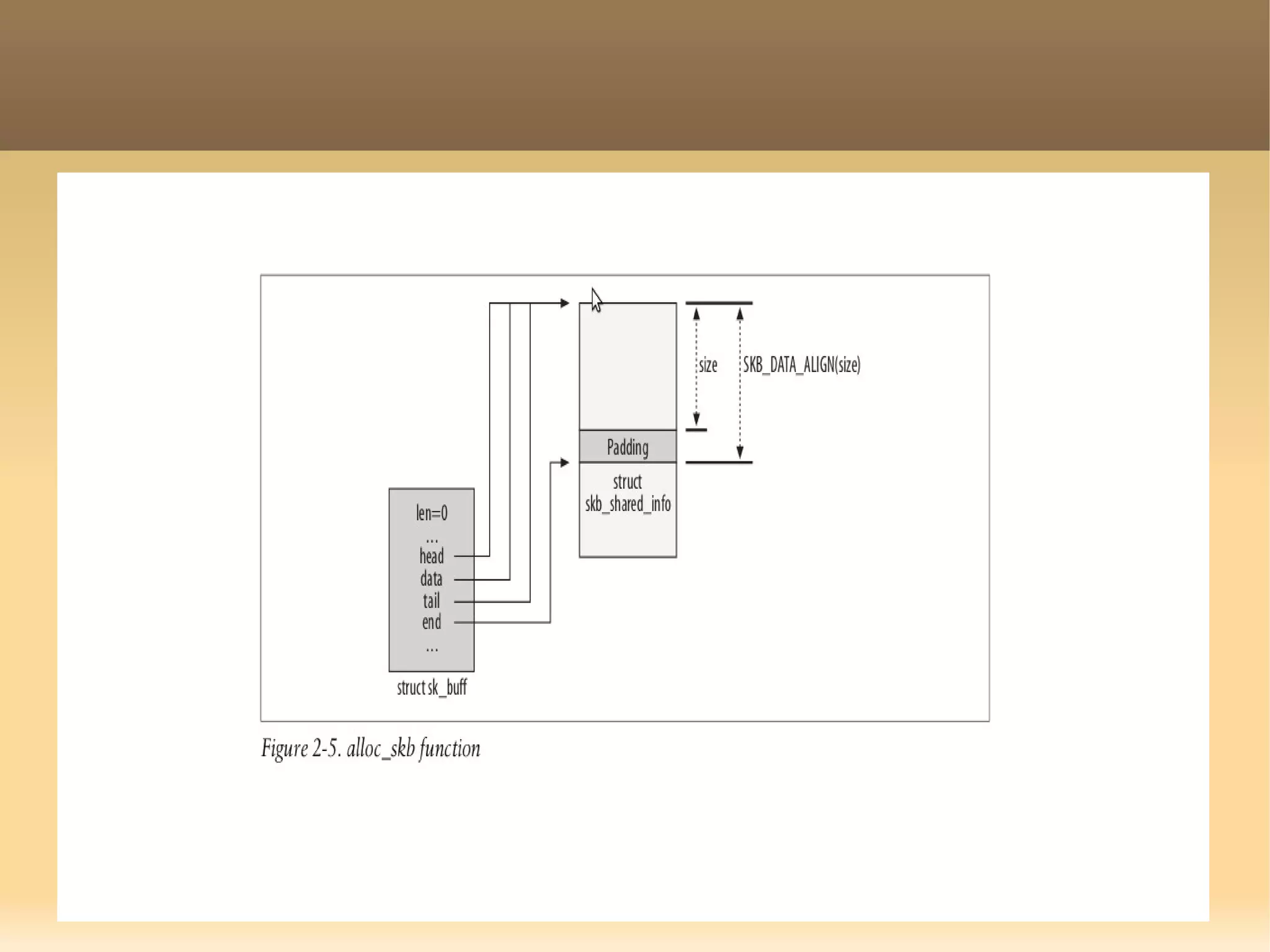
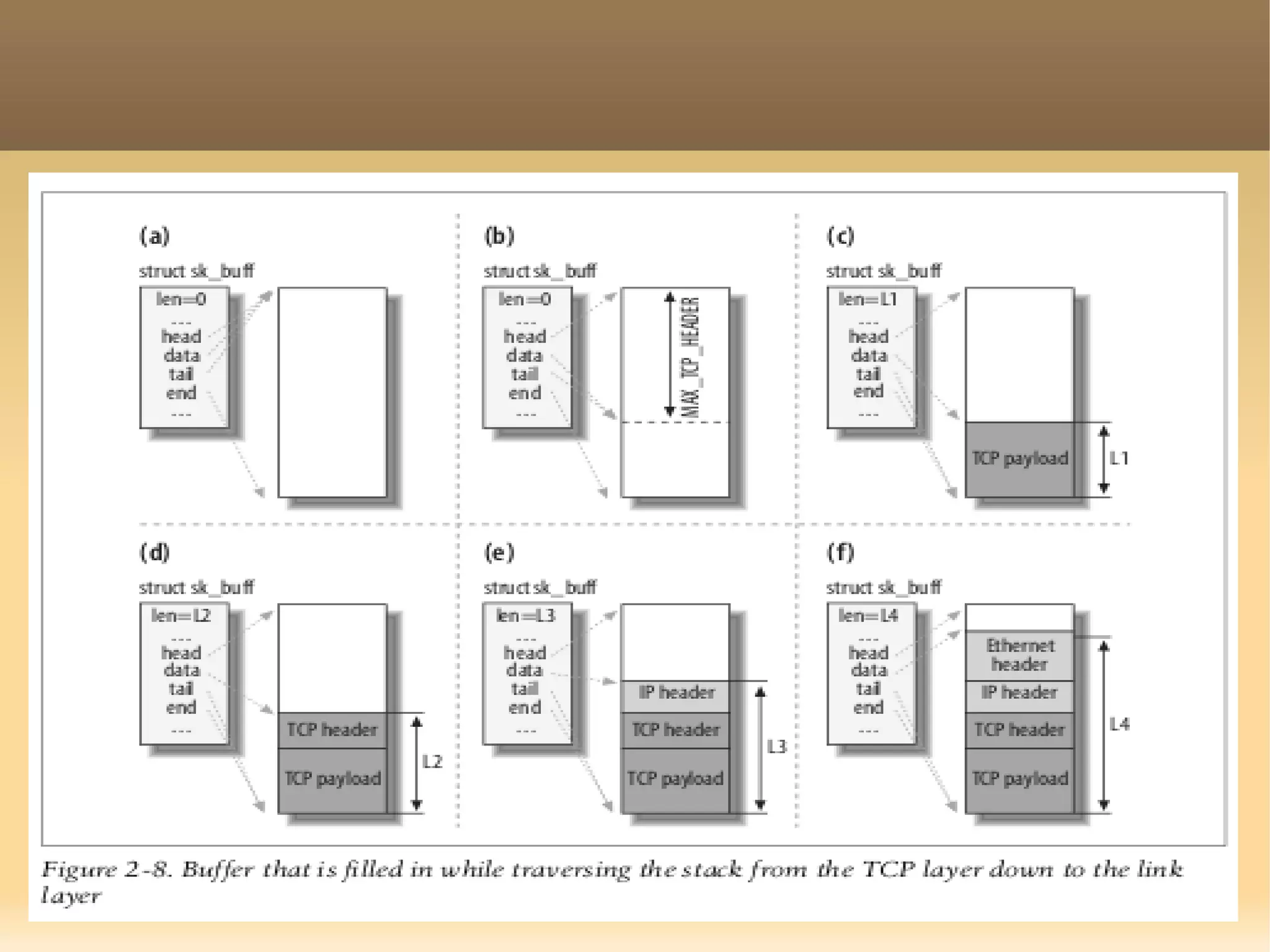

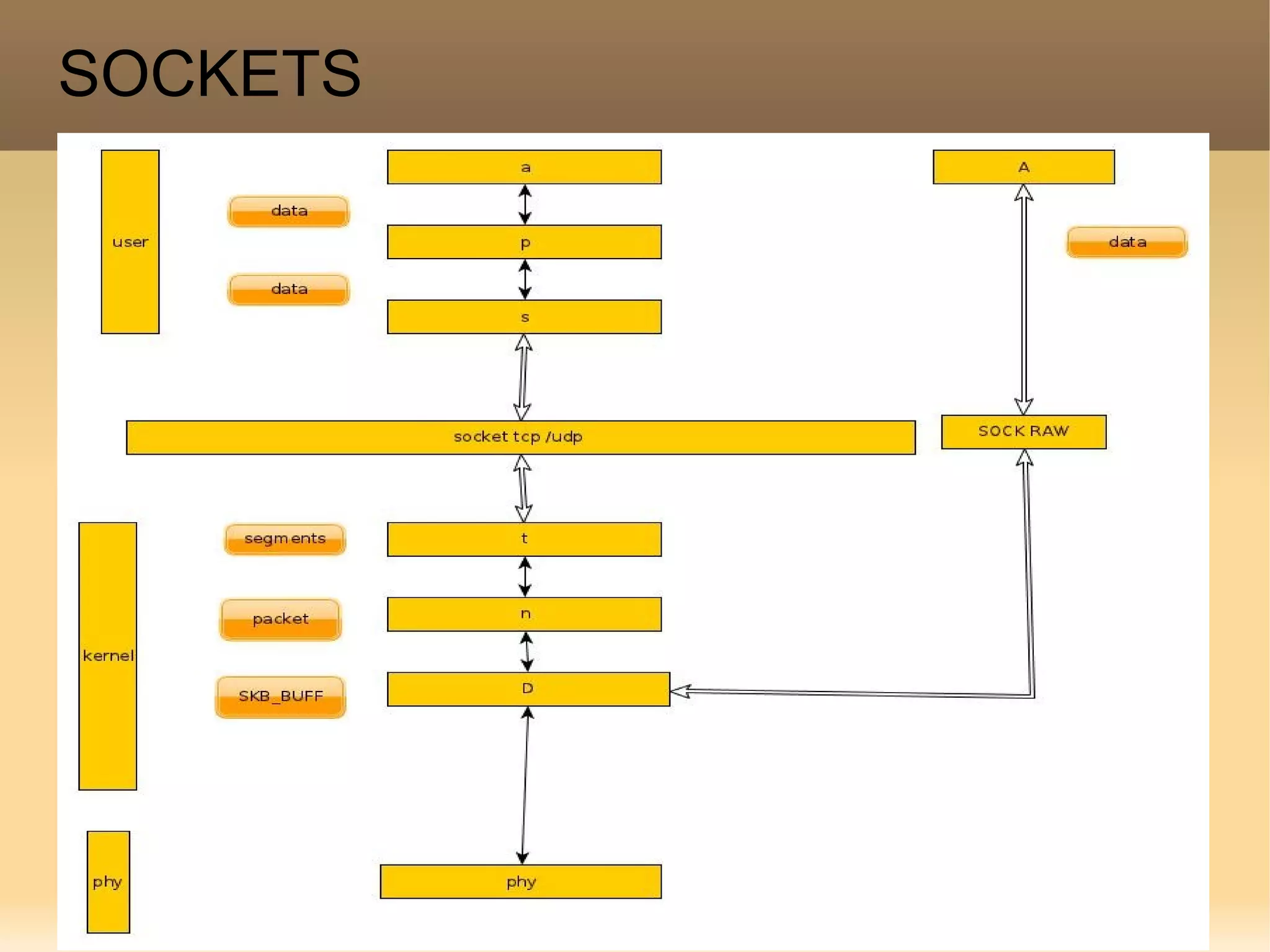
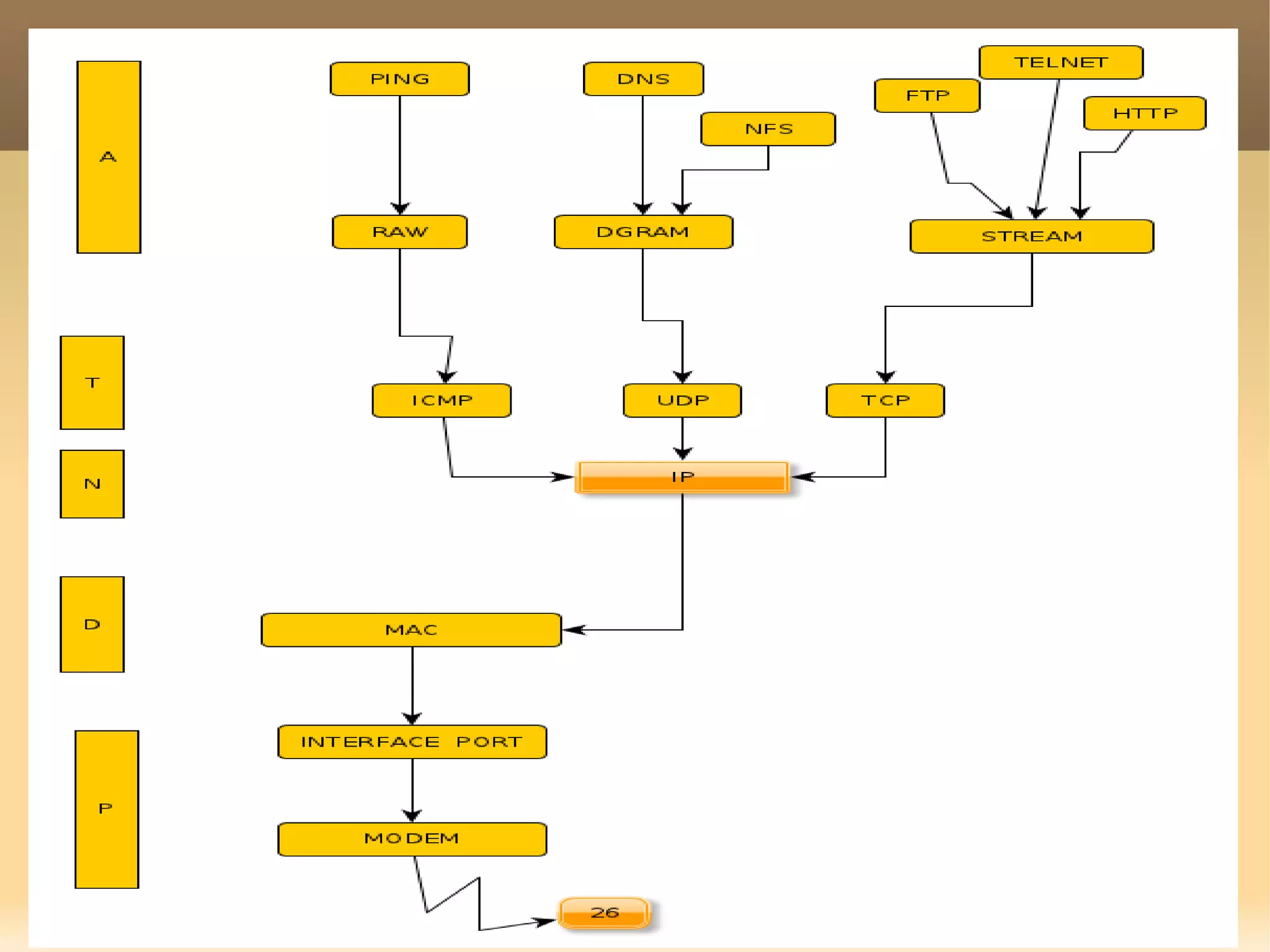
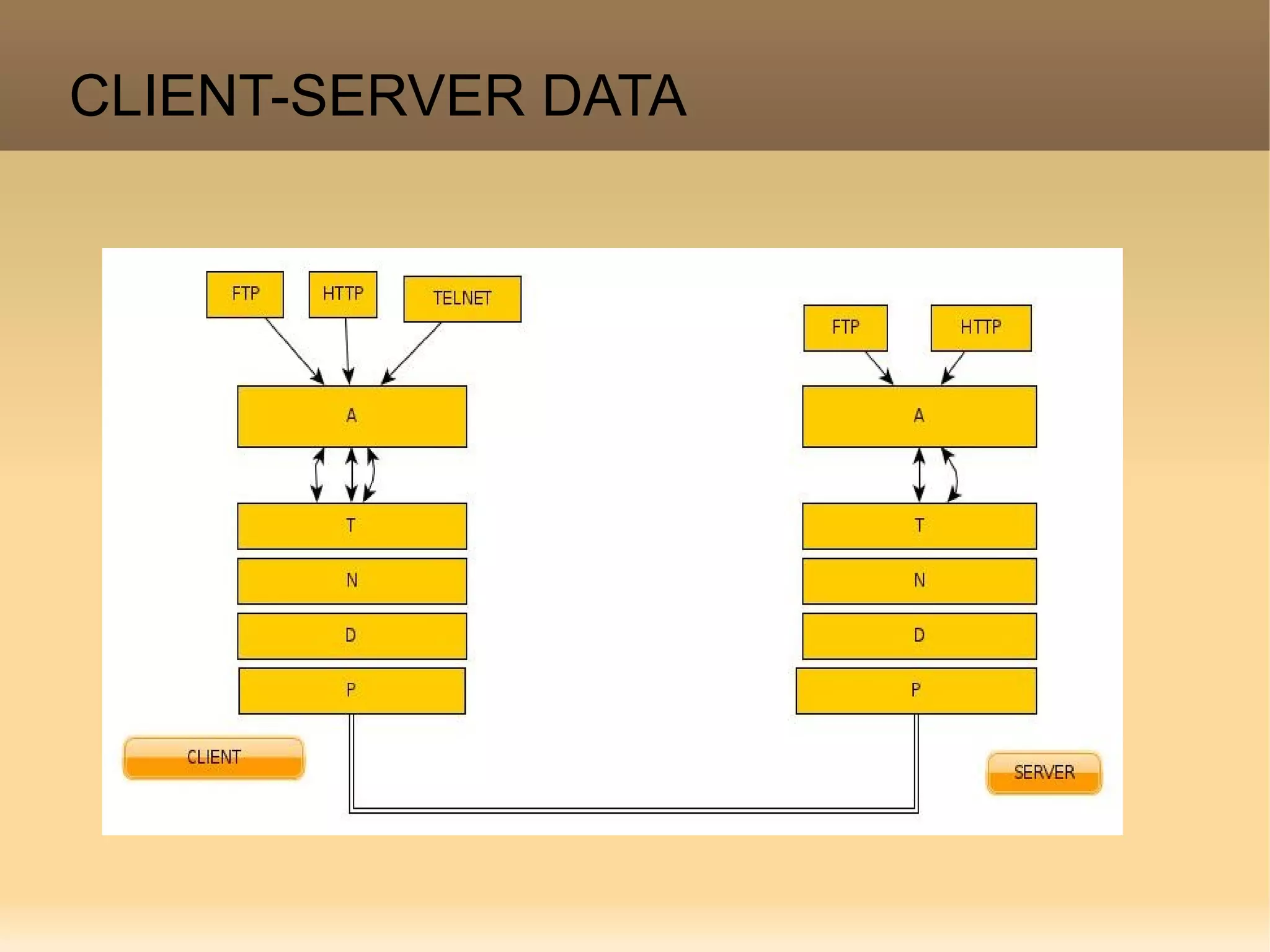


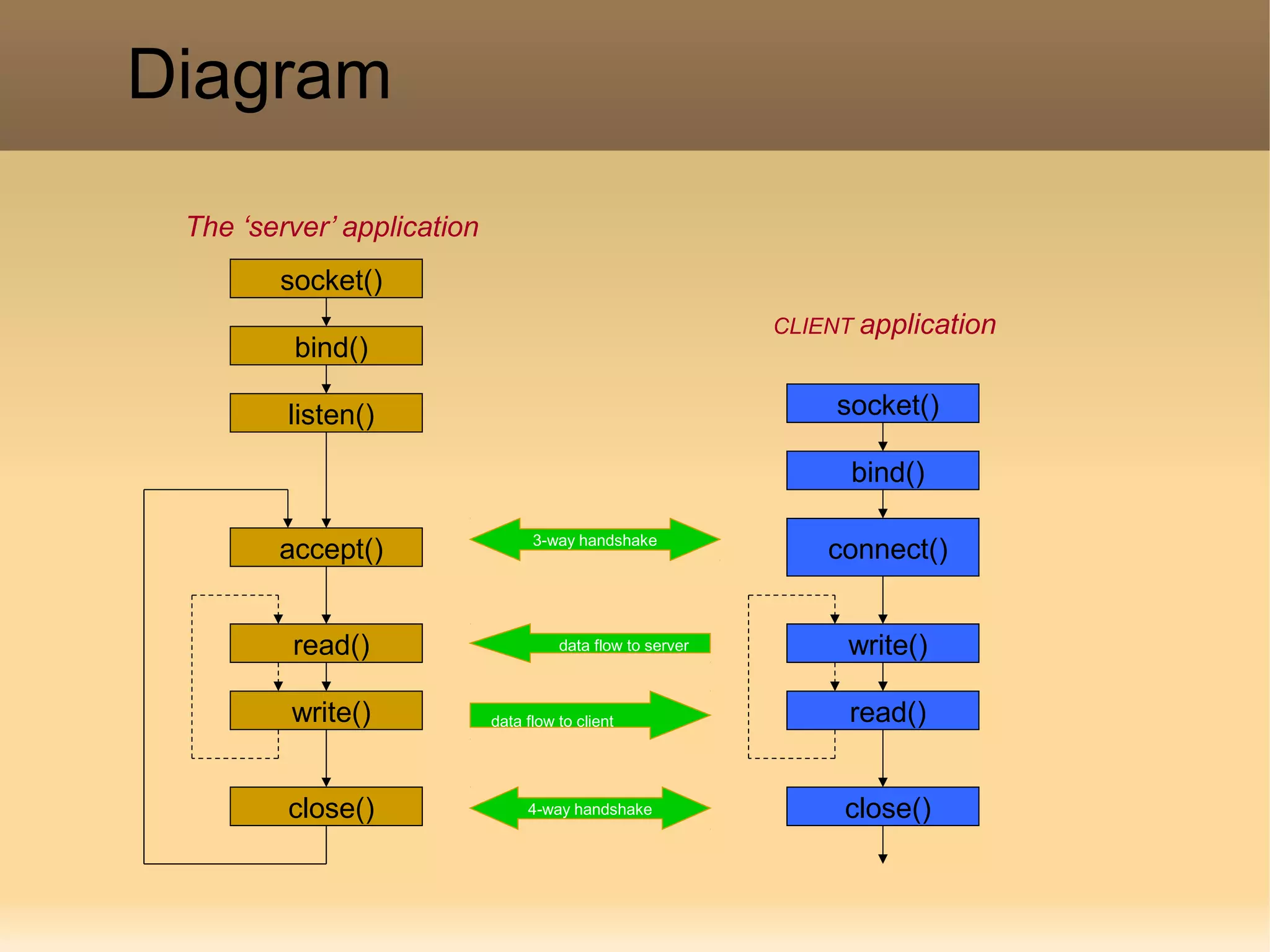
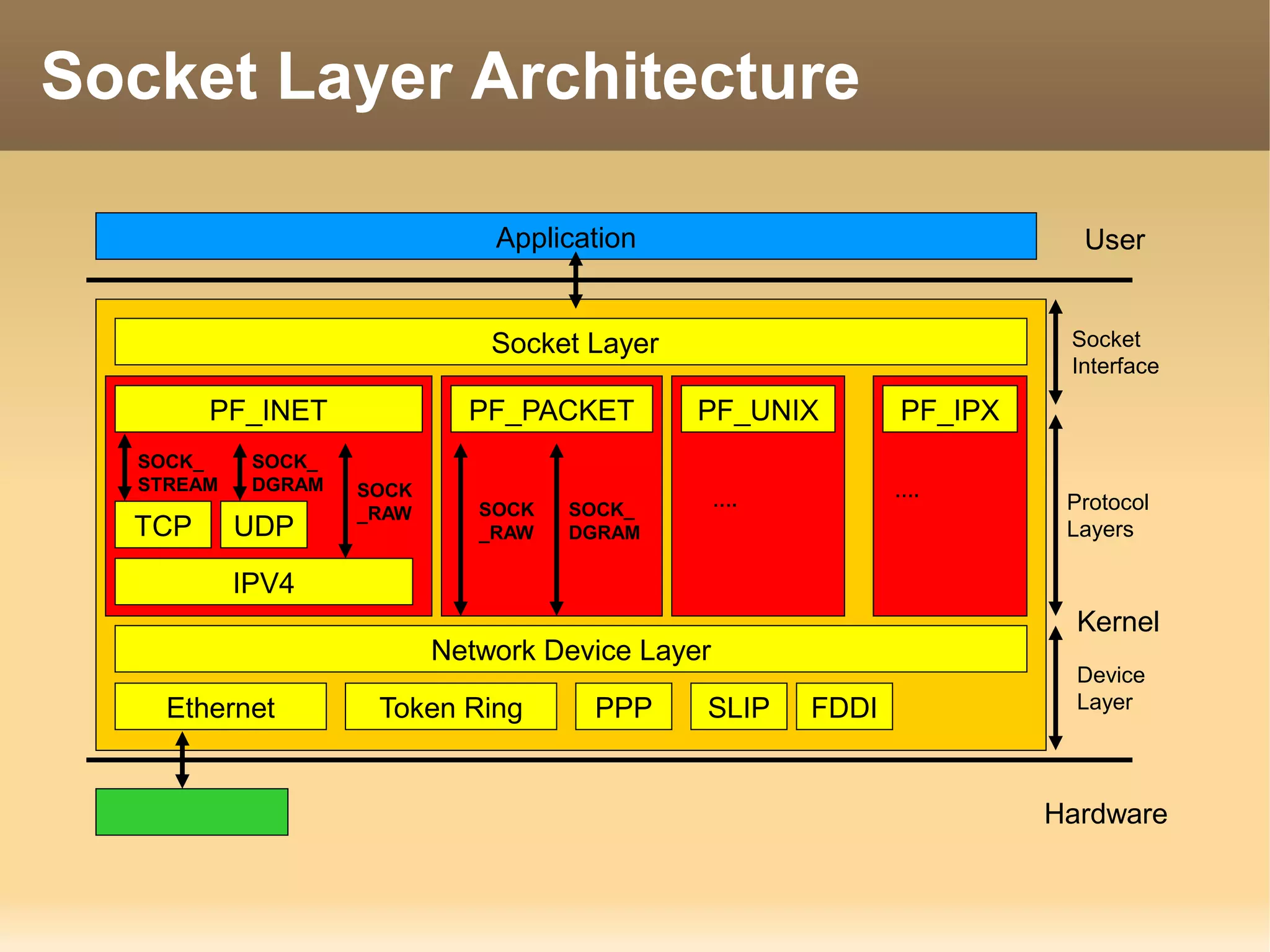
The document provides a detailed explanation of the socket API in Linux for network communication, including how to create sockets using the socket() system call and the various socket types and protocols supported. It describes the data structures involved, such as struct socket and struct sock, as well as the sk_buff structure, which is crucial for handling network packets. Additionally, the document outlines the basic functions required for network I/O and explains the client-server data flow in socket communication.























































































