Download as PDF, PPTX



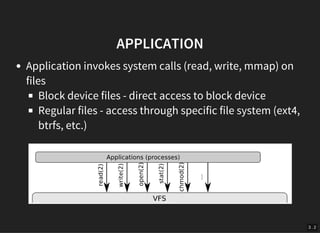

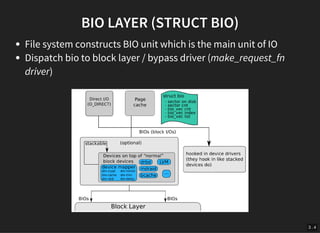

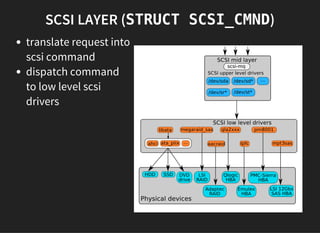


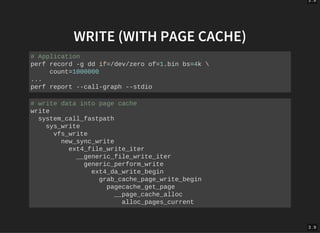




























The document discusses the evolution and architecture of storage devices, focusing on high-performance block devices and the transition from traditional hard drives to NVMe SSDs. It details the limitations of the old storage stack and introduces the blk-mq multiqueue architecture that enhances performance by exploiting concurrency. Key advancements include improved IOPS and reduced latency through modern interfaces and lock-less designs.




![[232] 성능어디까지쥐어짜봤니 송태웅](https://cdn.slidesharecdn.com/ss_thumbnails/232-161025013504-thumbnail.jpg?width=640&height=640&fit=bounds)


















































































