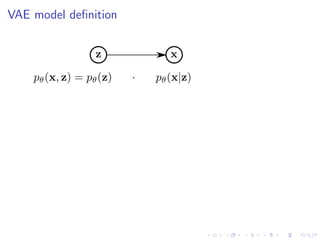
The document discusses variational autoencoders (VAEs) as a generative model for high-dimensional objects like speech and images, comparing them to autoregressive models and GANs in terms of sampling efficiency and likelihood estimation. It details the structure and challenges of VAEs, including the intractable nature of key probabilities, and explores modifications for improved latent variable representation such as β-VAEs and factor-VAEs. The document also references various studies and techniques related to disentangled representation in latent variables.









![The fundamental VAE equation
Start with the definition of KL-divergence and then use Bayes’ Law:
D (q(z | x) p(z | x))
= Ez∼q(z|x)[log q(z | x) − log p(z | x)]
= Ez∼q(z|x)[log q(z | x) − log p(x | z) − log p(z)] + log p(x)
Rearranging terms and using the definition of KL-divergence,
OELBO
:= log p(x) − D (q(z | x) p(z | x))
= Ez∼q(z|x)[log p(x | z)]
tractable to optimize
− D (q(z | x) p(z))
tractable to optimize](https://image.slidesharecdn.com/variationalautoencodersforspeechprocessingd-180503092301/85/Variational-autoencoders-for-speech-processing-d-bielievtsov-dataconf-21-04-18-15-320.jpg)
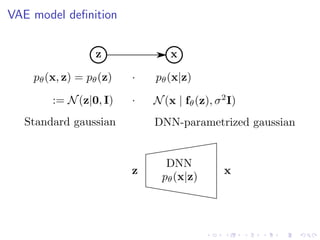
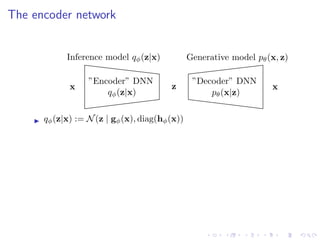
![Recap
pθ(x | z) := N(x | fθ(z), σ2
I)
p(z) := N(z | 0, I)
qφ(z | x) := N(x | gφ(x), diag(hφ(x))
OELBO(x; θ, φ) := Ez∼qφ(z|x)[log pθ(x | z)] − D (qφ(z | x) p(z))](https://image.slidesharecdn.com/variationalautoencodersforspeechprocessingd-180503092301/85/Variational-autoencoders-for-speech-processing-d-bielievtsov-dataconf-21-04-18-16-320.jpg)
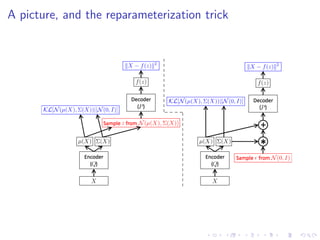


![Disentangling variables: β-VAE
Original objective function (ELBO):
OELBO = Ez∼q(z|x)[log p(x | z)] − D (q(z | x) p(z))](https://image.slidesharecdn.com/variationalautoencodersforspeechprocessingd-180503092301/85/Variational-autoencoders-for-speech-processing-d-bielievtsov-dataconf-21-04-18-20-320.jpg)
![Disentangling variables: β-VAE
Original objective function (ELBO):
OELBO = Ez∼q(z|x)[log p(x | z)] − D (q(z | x) p(z))
New objective function:
Oβ = Ez∼q(z|x)[log p(x | z)] − β D (q(z | x) p(z))](https://image.slidesharecdn.com/variationalautoencodersforspeechprocessingd-180503092301/85/Variational-autoencoders-for-speech-processing-d-bielievtsov-dataconf-21-04-18-21-320.jpg)
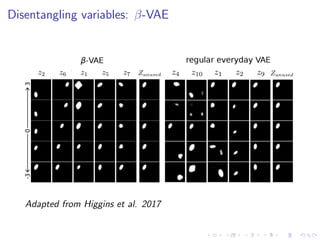
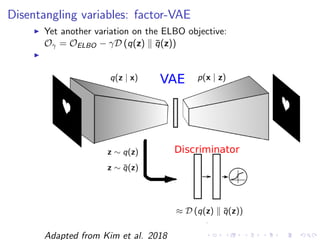
![Disentangling variables: factor-VAE
Upon closer inspection, β-VAE creates some tradeoff between
disentanglement and reconstruction:
β-VAE objective:
Oβ = Ez∼q(z|x)[log p(x | z)] − β D (q(z | x) p(z))](https://image.slidesharecdn.com/variationalautoencodersforspeechprocessingd-180503092301/85/Variational-autoencoders-for-speech-processing-d-bielievtsov-dataconf-21-04-18-23-320.jpg)
![Disentangling variables: factor-VAE
Upon closer inspection, β-VAE creates some tradeoff between
disentanglement and reconstruction:
β-VAE objective:
Oβ = Ez∼q(z|x)[log p(x | z)] − β D (q(z | x) p(z))
Let’s look closer at that regularizer:
Ex∼pdata(x)[D (q(z | x) p(z))] = Ienc(x; z) + D (q(z) p(z))](https://image.slidesharecdn.com/variationalautoencodersforspeechprocessingd-180503092301/85/Variational-autoencoders-for-speech-processing-d-bielievtsov-dataconf-21-04-18-24-320.jpg)
![Disentangling variables: factor-VAE
Upon closer inspection, β-VAE creates some tradeoff between
disentanglement and reconstruction:
β-VAE objective:
Oβ = Ez∼q(z|x)[log p(x | z)] − β D (q(z | x) p(z))
Let’s look closer at that regularizer:
Ex∼pdata(x)[D (q(z | x) p(z))] = Ienc(x; z) + D (q(z) p(z))
We don’t want to hurt that mutual information term!](https://image.slidesharecdn.com/variationalautoencodersforspeechprocessingd-180503092301/85/Variational-autoencoders-for-speech-processing-d-bielievtsov-dataconf-21-04-18-25-320.jpg)

![References
Doersch, Carl. “Tutorial on Variational Autoencoders.” ArXiv:1606.05908 [Cs, Stat], June 19, 2016.
http://arxiv.org/abs/1606.05908.
Higgins, Irina, Loic Matthey, Arka Pal, Christopher Burgess, Xavier Glorot, Matthew Botvinick, Shakir
Mohamed, and Alexander Lerchner. “β-VAE: LEARNING BASIC VISUAL CONCEPTS WITH A
CONSTRAINED VARIATIONAL FRAMEWORK,” 2017, 22.
Hsu, Wei-Ning, Yu Zhang, and James Glass. “Learning Latent Representations for Speech Generation and
Transformation.” ArXiv:1704.04222 [Cs, Stat], April 13, 2017. http://arxiv.org/abs/1704.04222.
———. “Unsupervised Learning of Disentangled and Interpretable Representations from Sequential Data.”
ArXiv:1709.07902 [Cs, Eess, Stat], September 22, 2017. http://arxiv.org/abs/1709.07902.
Kim, Hyunjik, and Andriy Mnih. “Disentangling by Factorising.” ArXiv:1802.05983 [Cs, Stat], February 16,
2018. http://arxiv.org/abs/1802.05983.
Kingma, Diederik P., and Max Welling. “Auto-Encoding Variational Bayes.” ArXiv:1312.6114 [Cs, Stat],
December 20, 2013. http://arxiv.org/abs/1312.6114.
Oord, Aaron van den, Oriol Vinyals, and Koray Kavukcuoglu. “Neural Discrete Representation Learning.”
ArXiv:1711.00937 [Cs], November 2, 2017. http://arxiv.org/abs/1711.00937.](https://image.slidesharecdn.com/variationalautoencodersforspeechprocessingd-180503092301/85/Variational-autoencoders-for-speech-processing-d-bielievtsov-dataconf-21-04-18-30-320.jpg)



























![[DL輪読会]Recent Advances in Autoencoder-Based Representation Learning](https://cdn.slidesharecdn.com/ss_thumbnails/20190119dljournalclubweb-190401063633-thumbnail.jpg?width=640&height=640&fit=bounds)
















![[DL輪読会]Disentangling by Factorising](https://cdn.slidesharecdn.com/ss_thumbnails/20180720disentanglingbyfactorising-180720000930-thumbnail.jpg?width=640&height=640&fit=bounds)



































