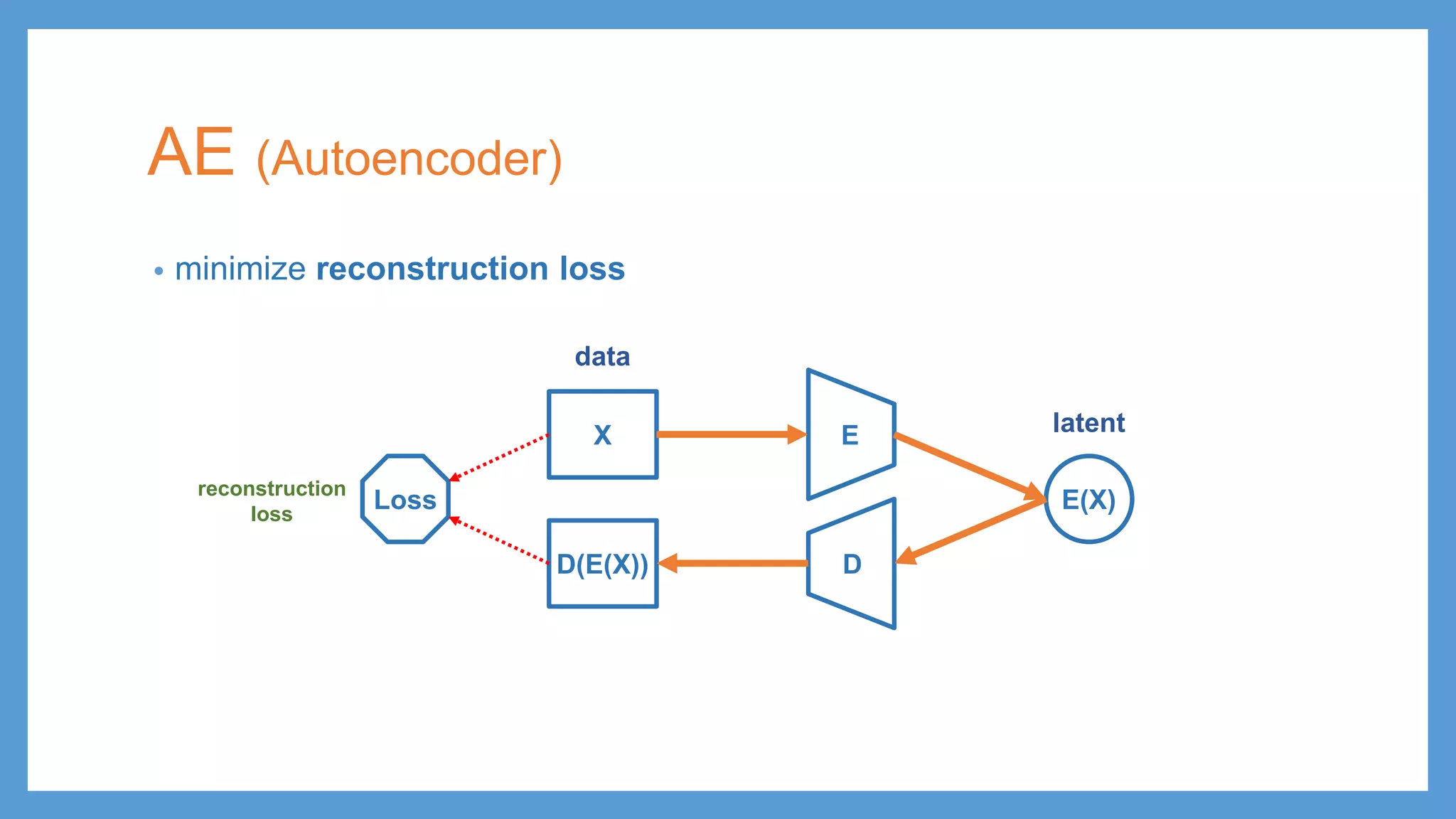
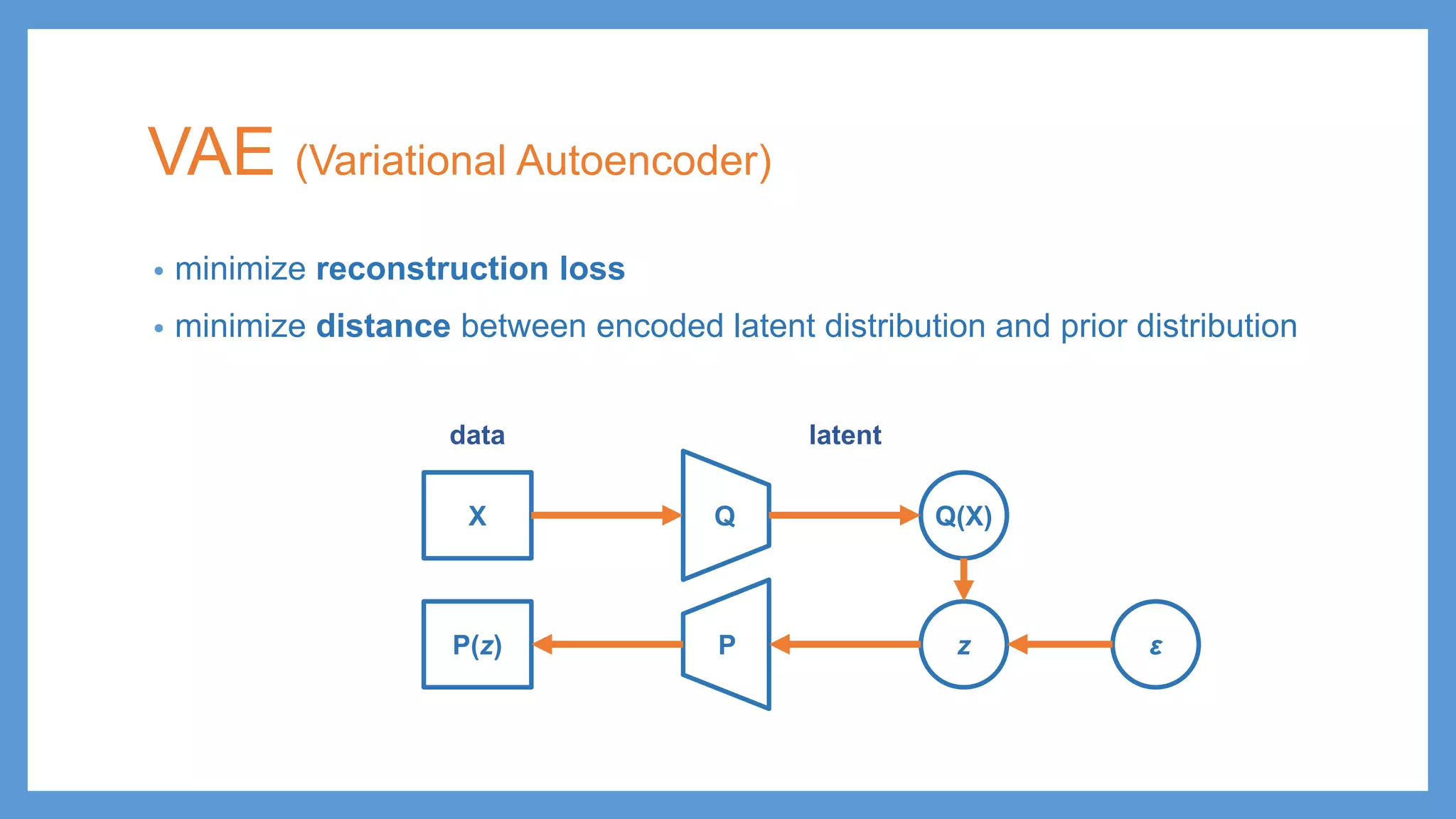
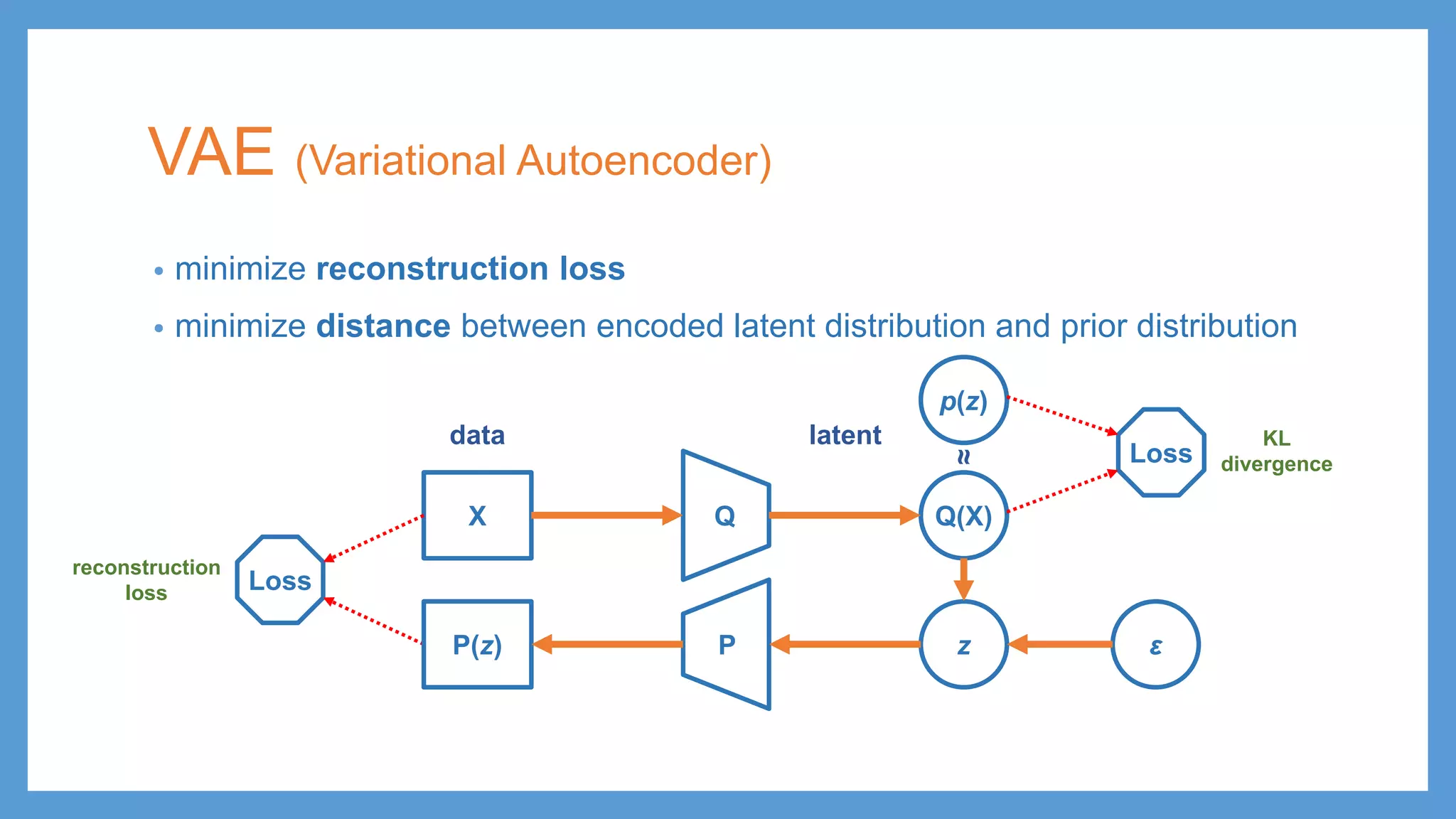
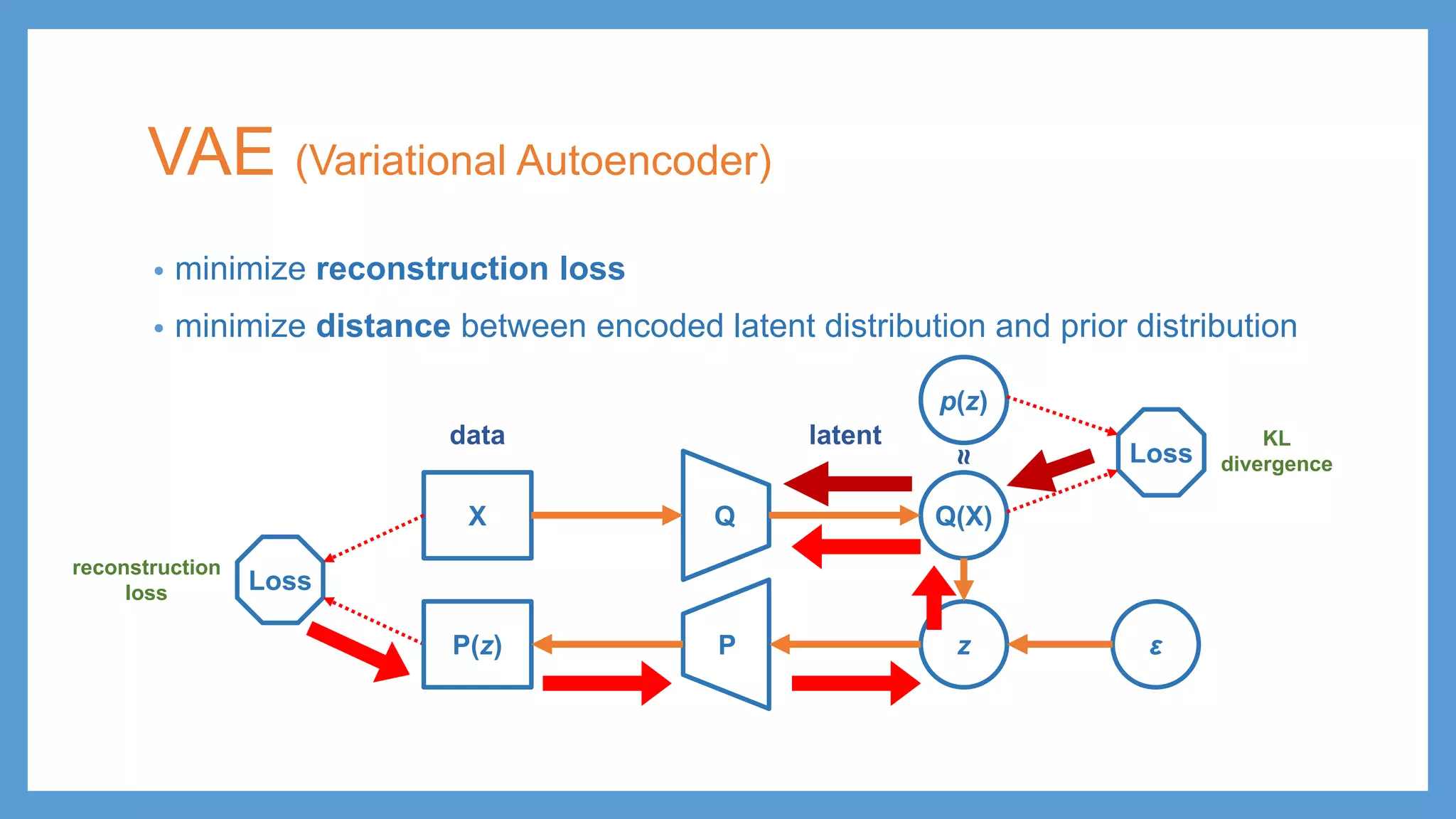
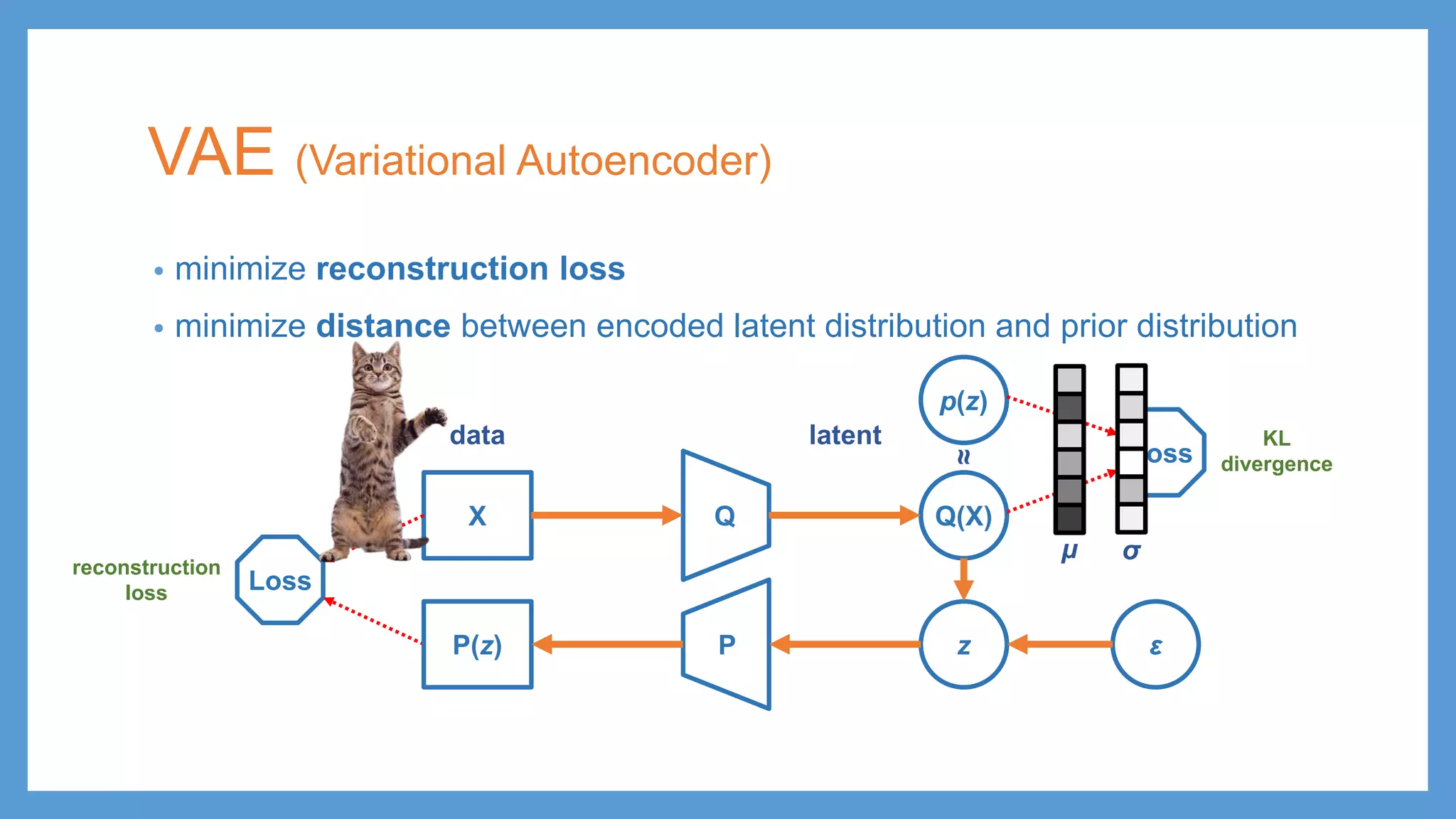
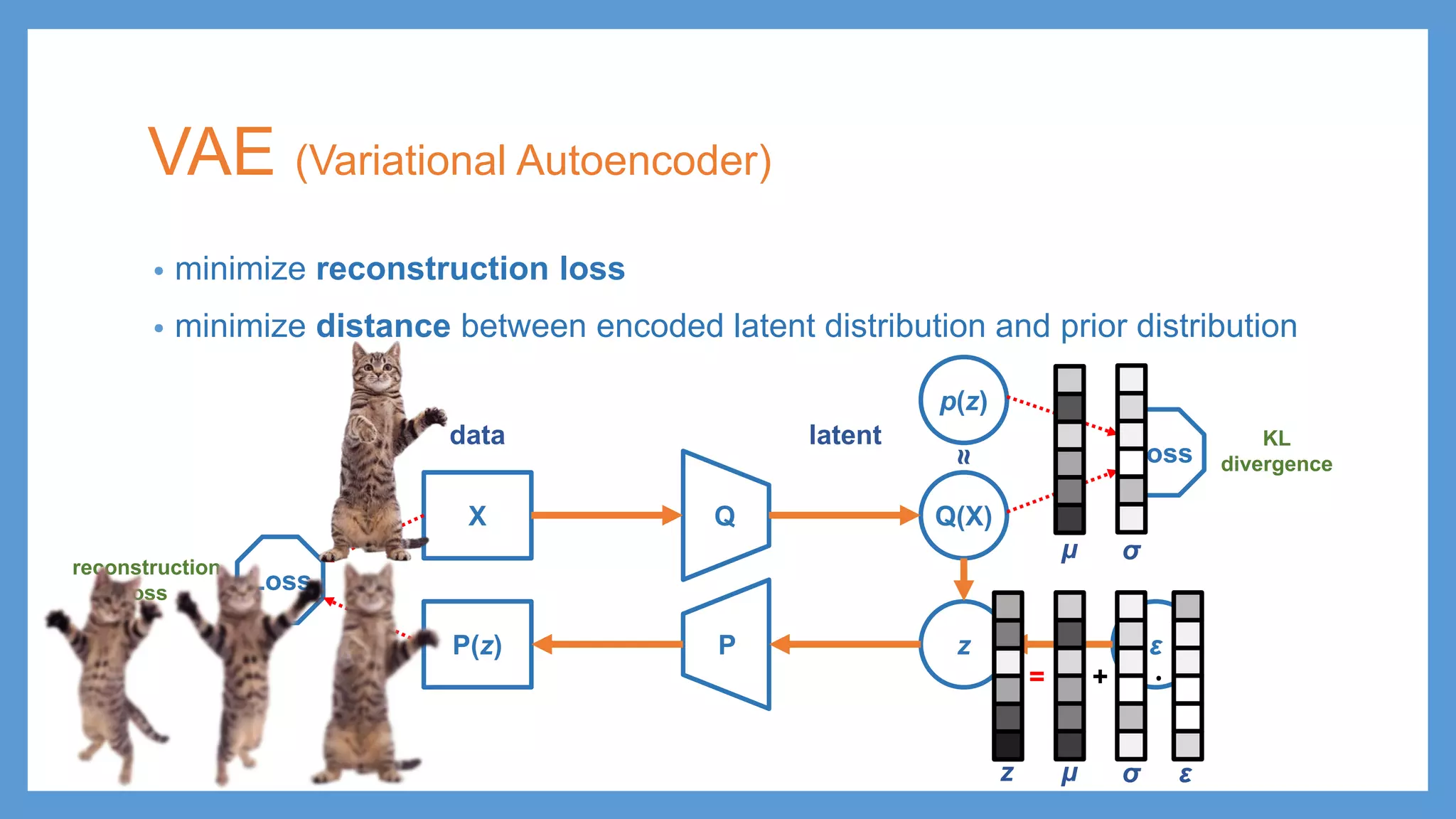
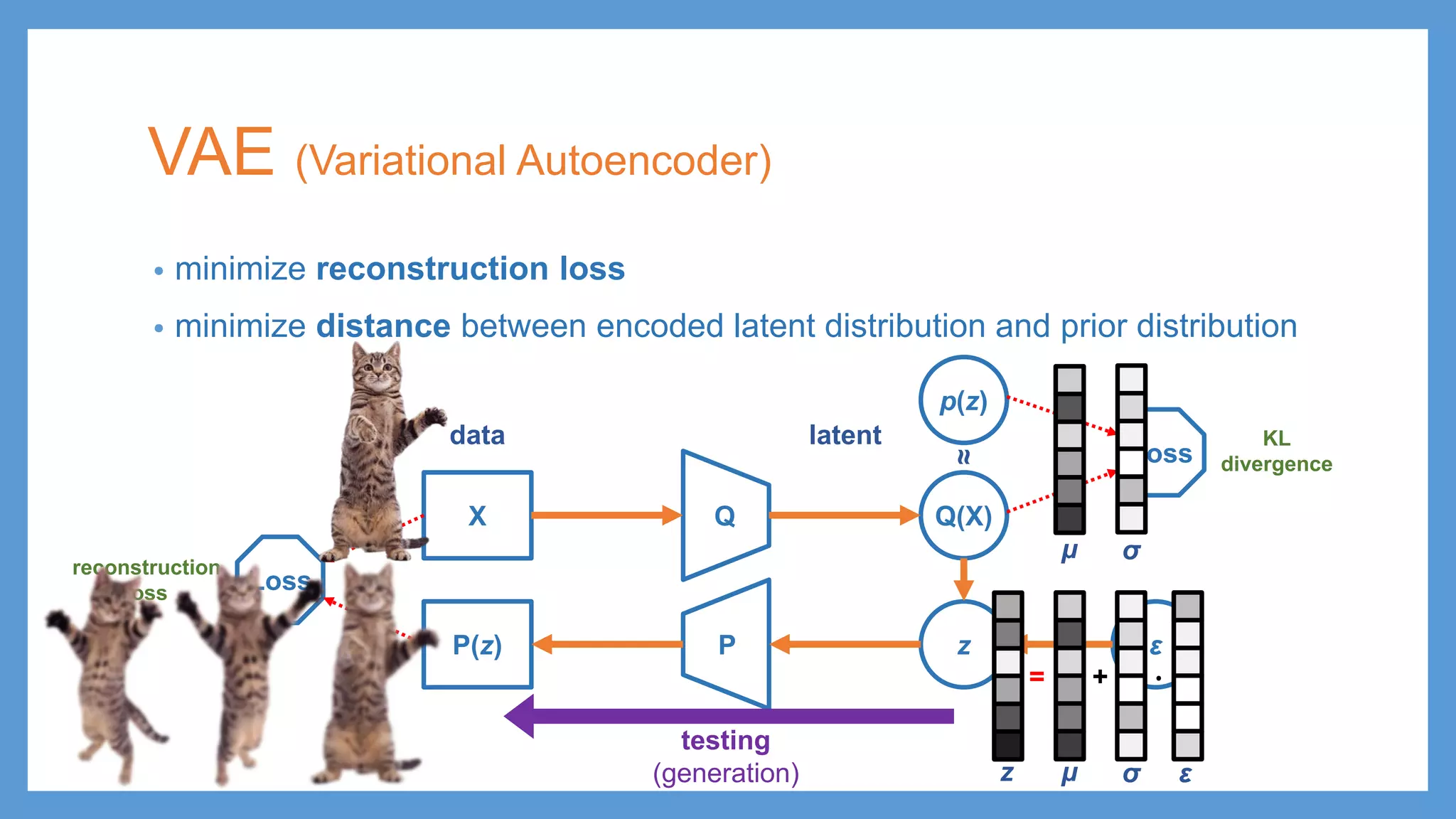
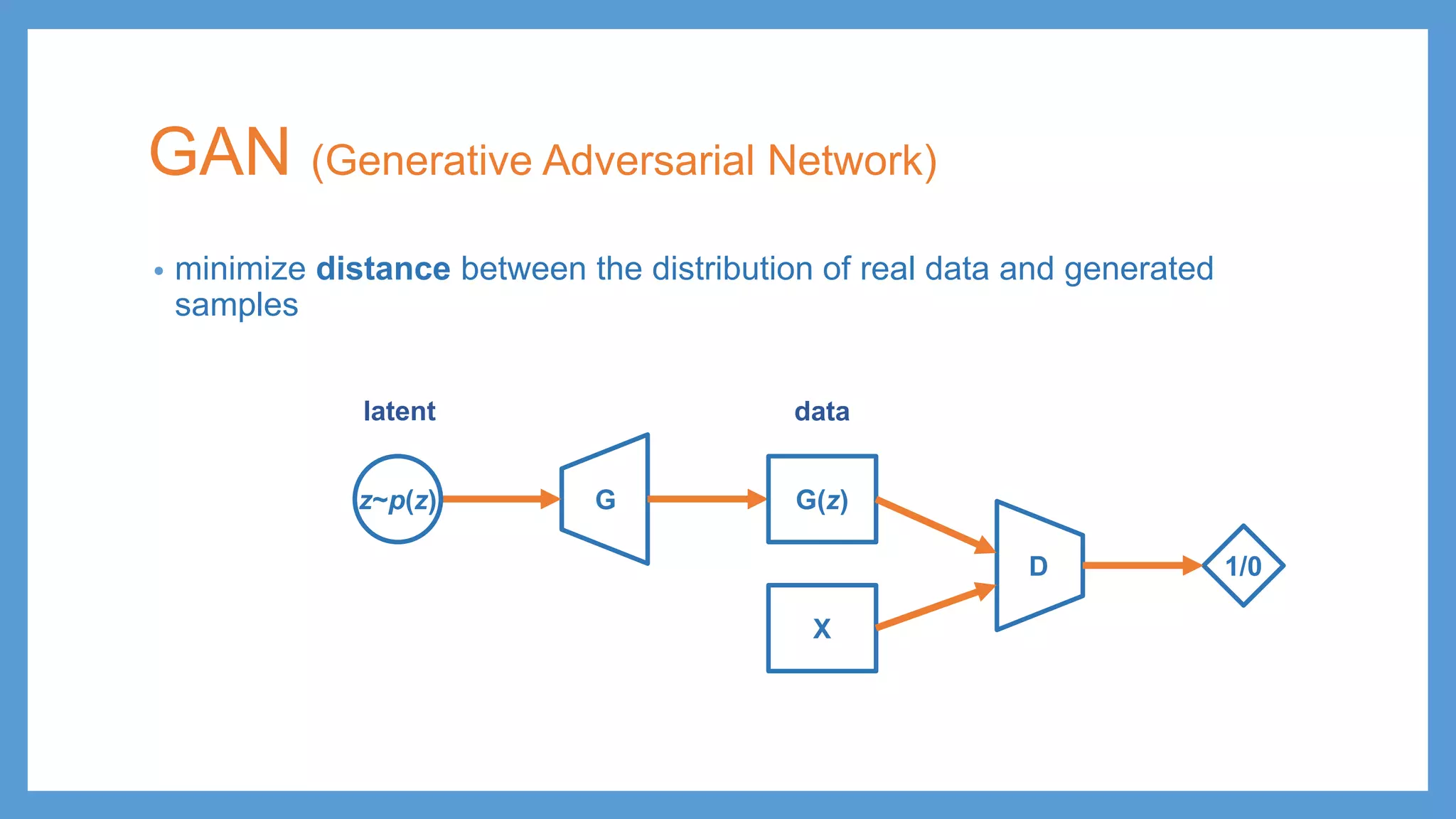
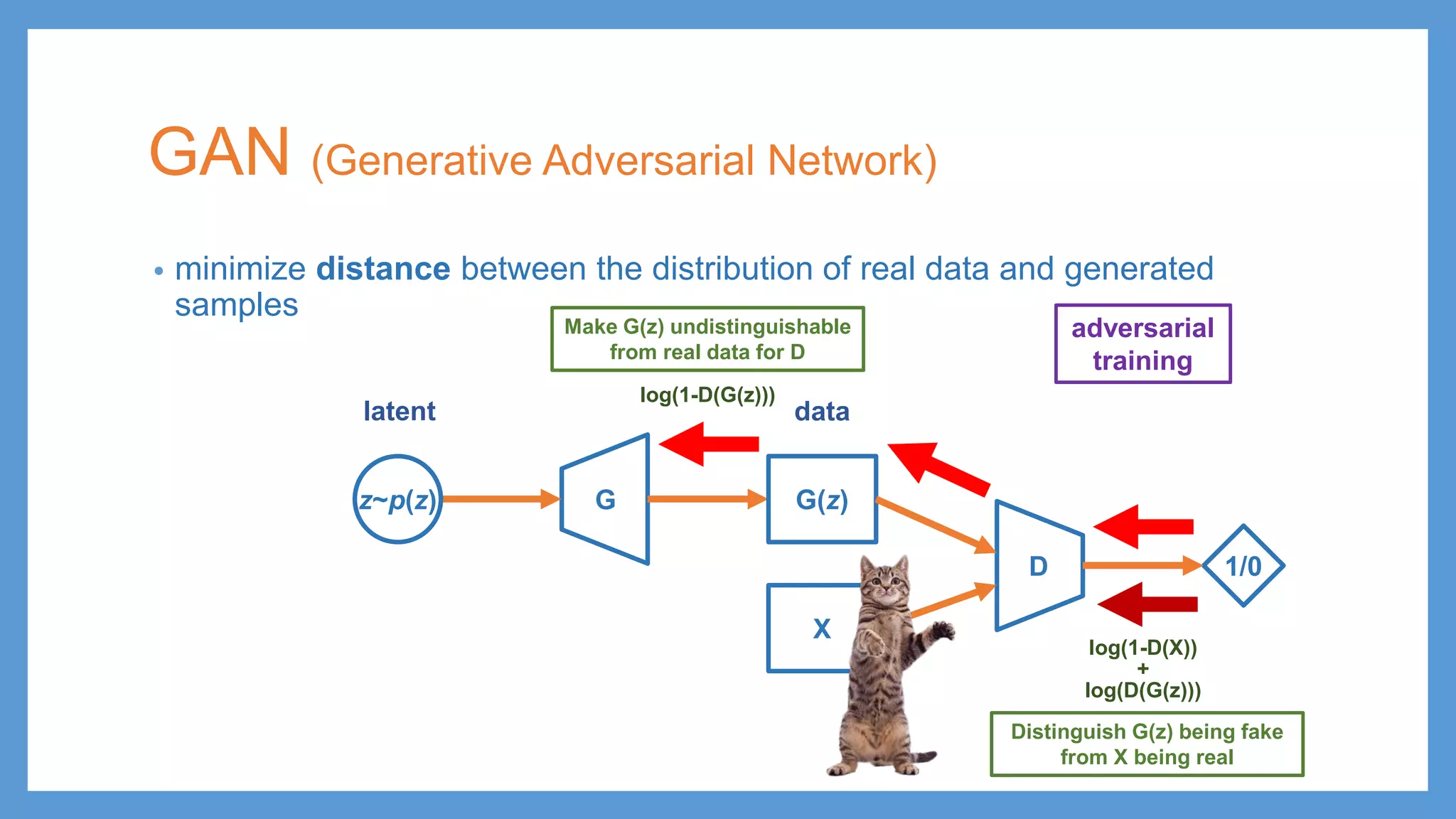
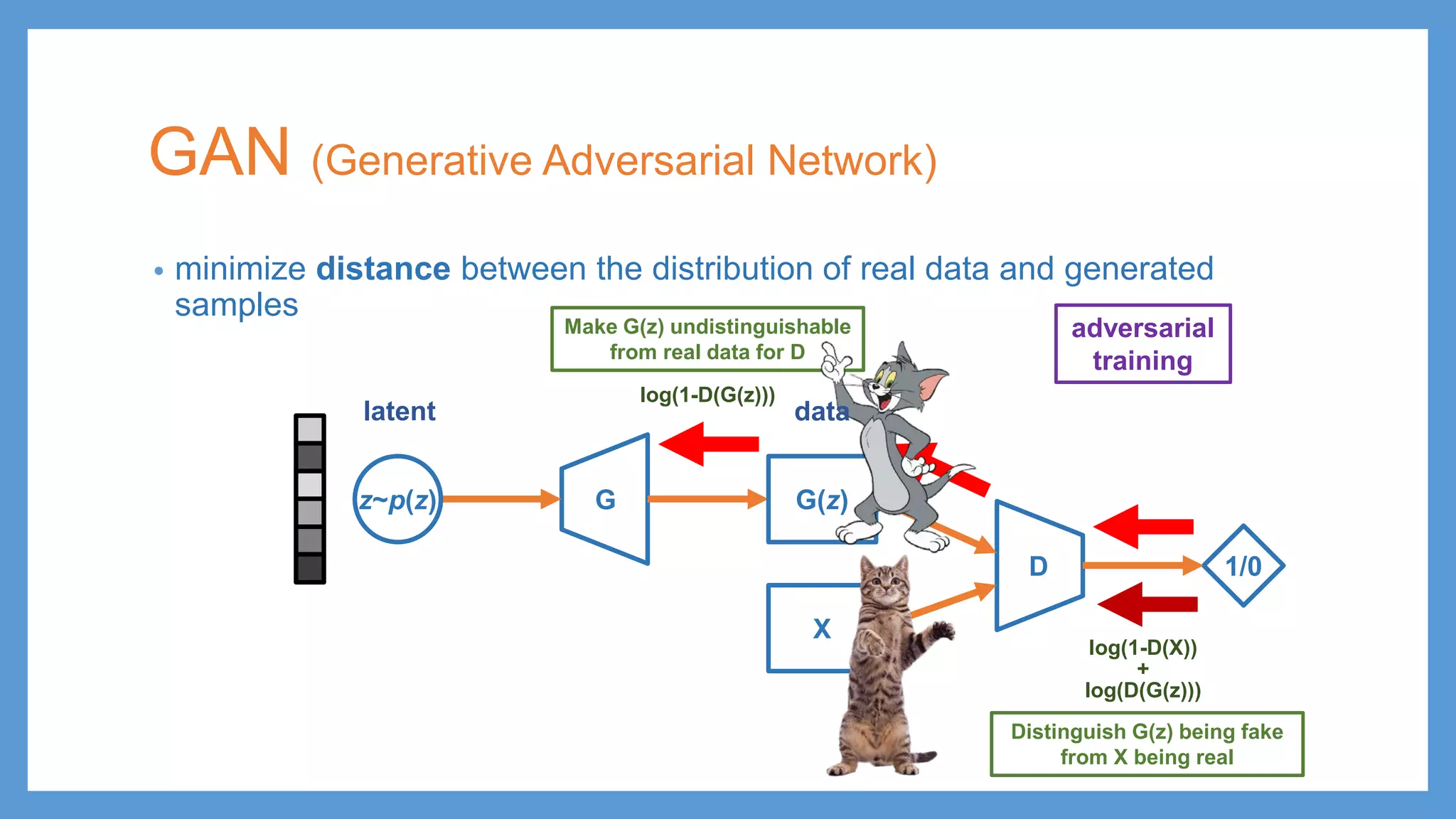
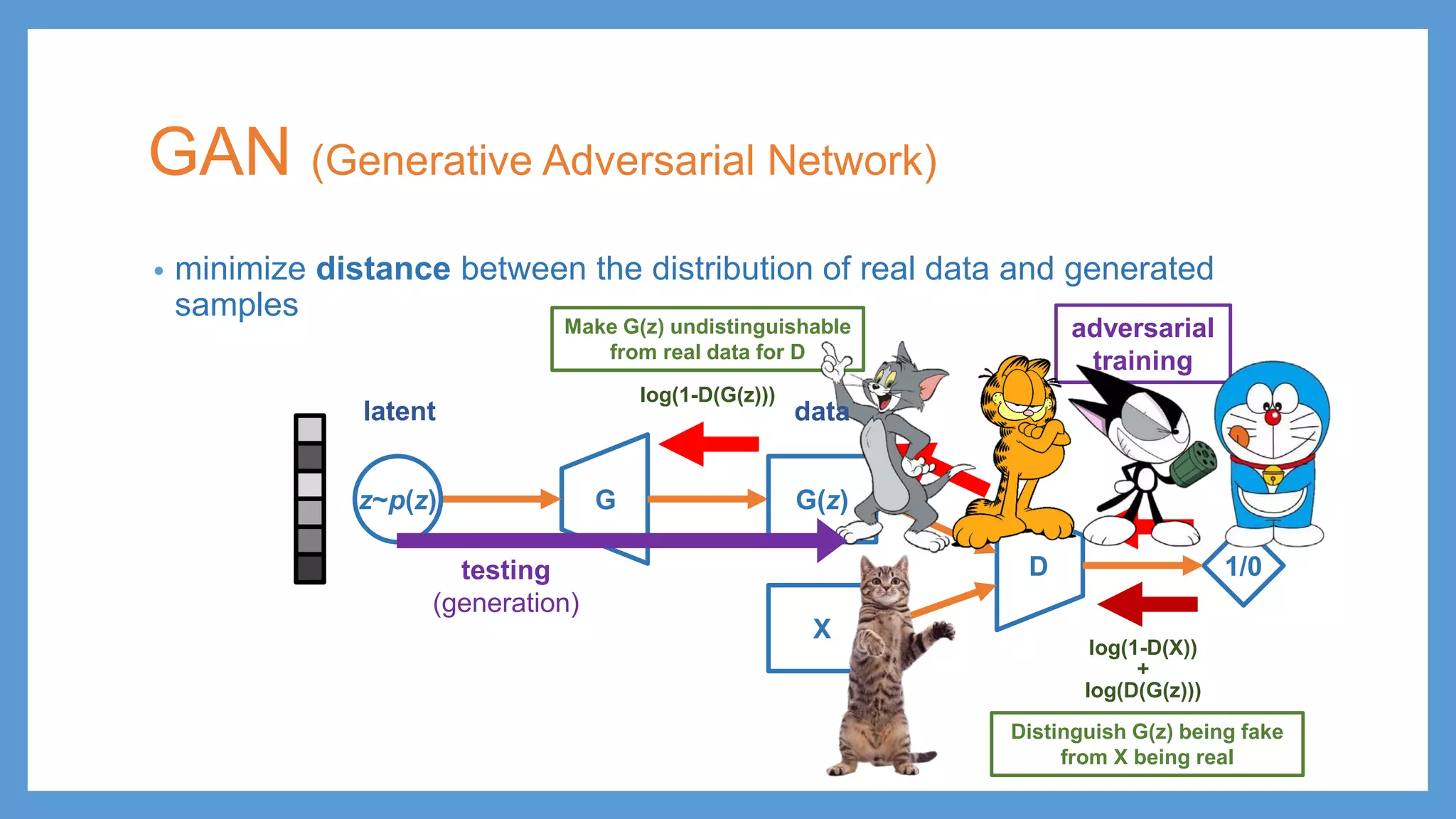
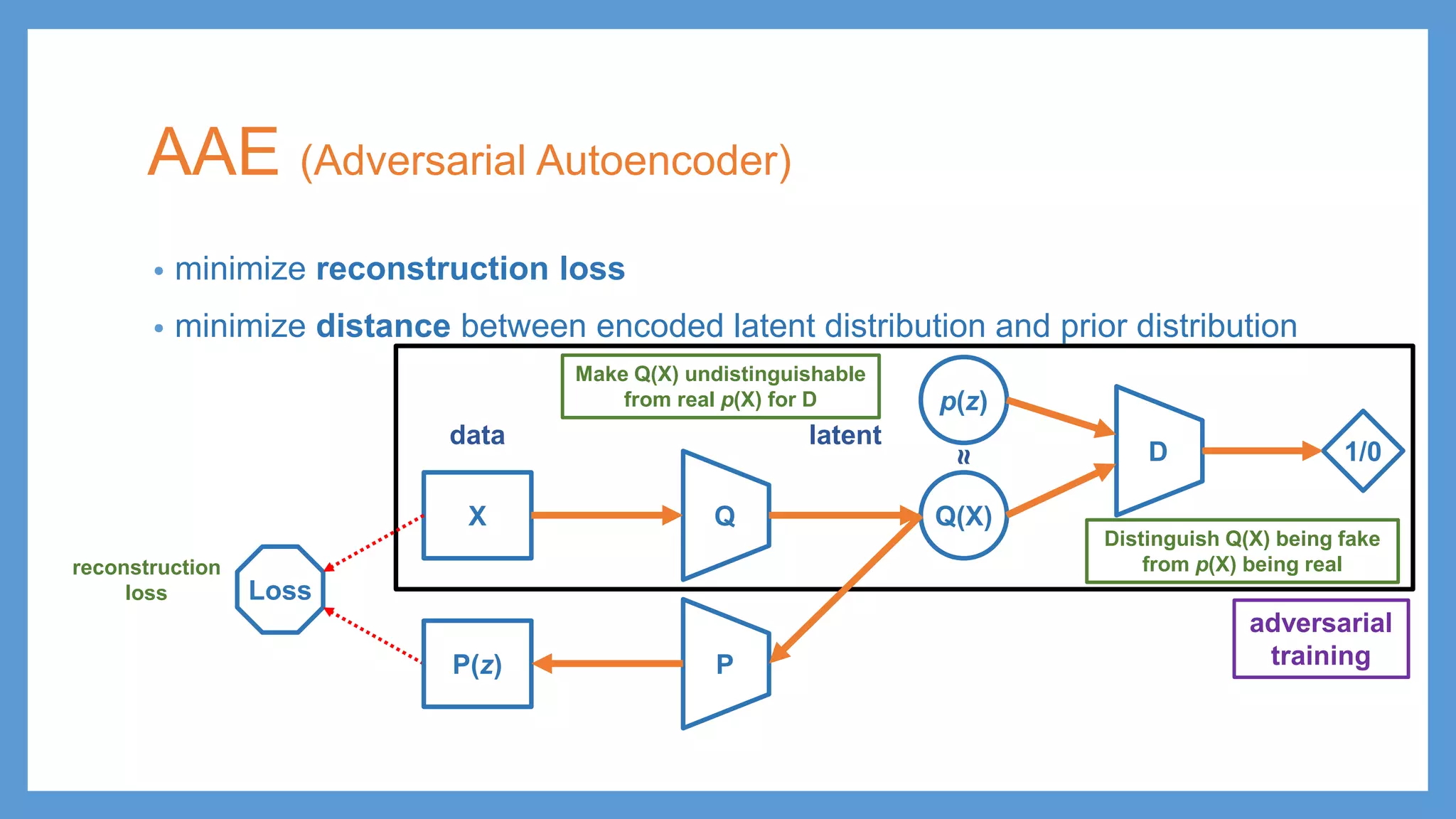
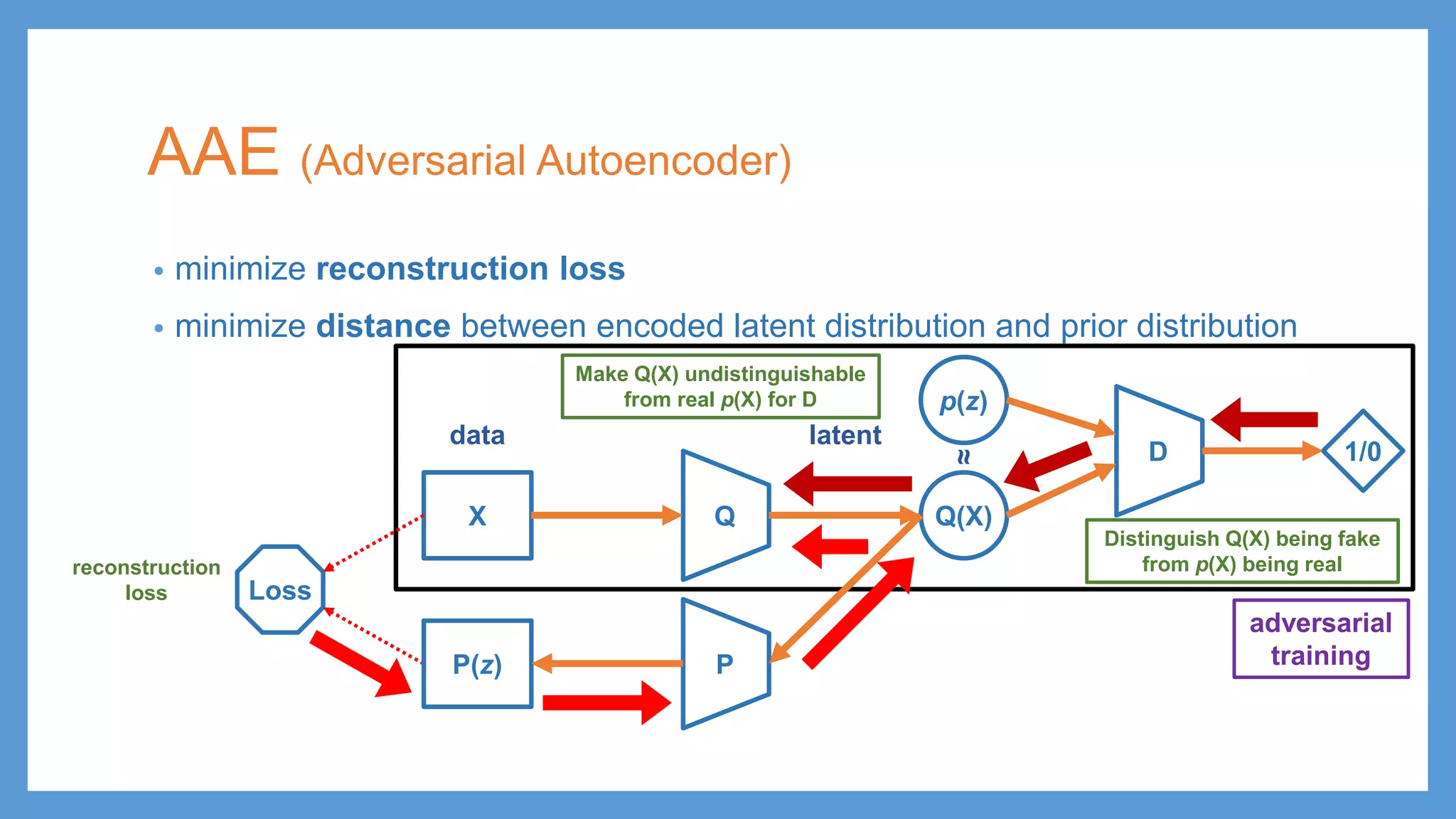
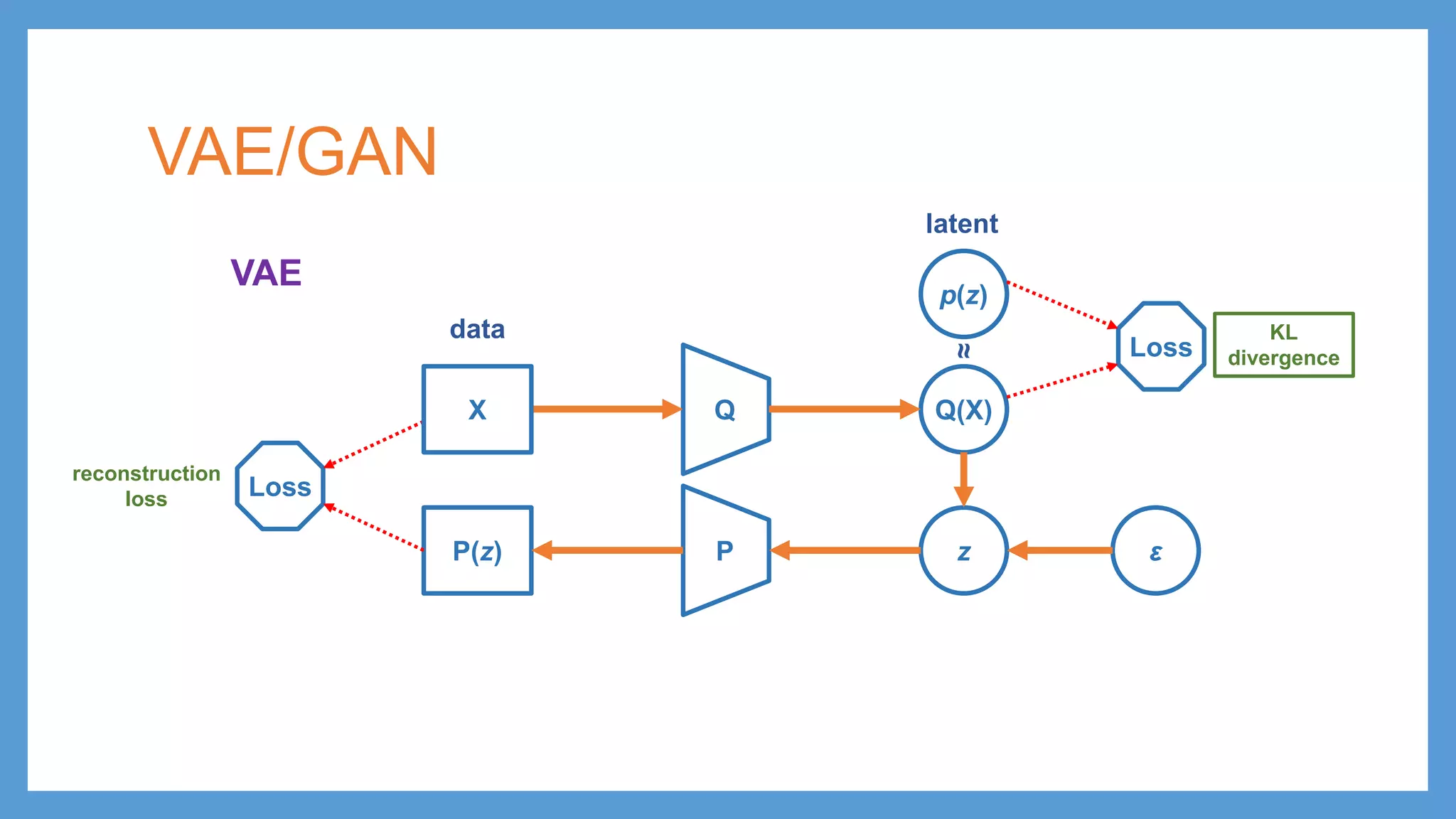
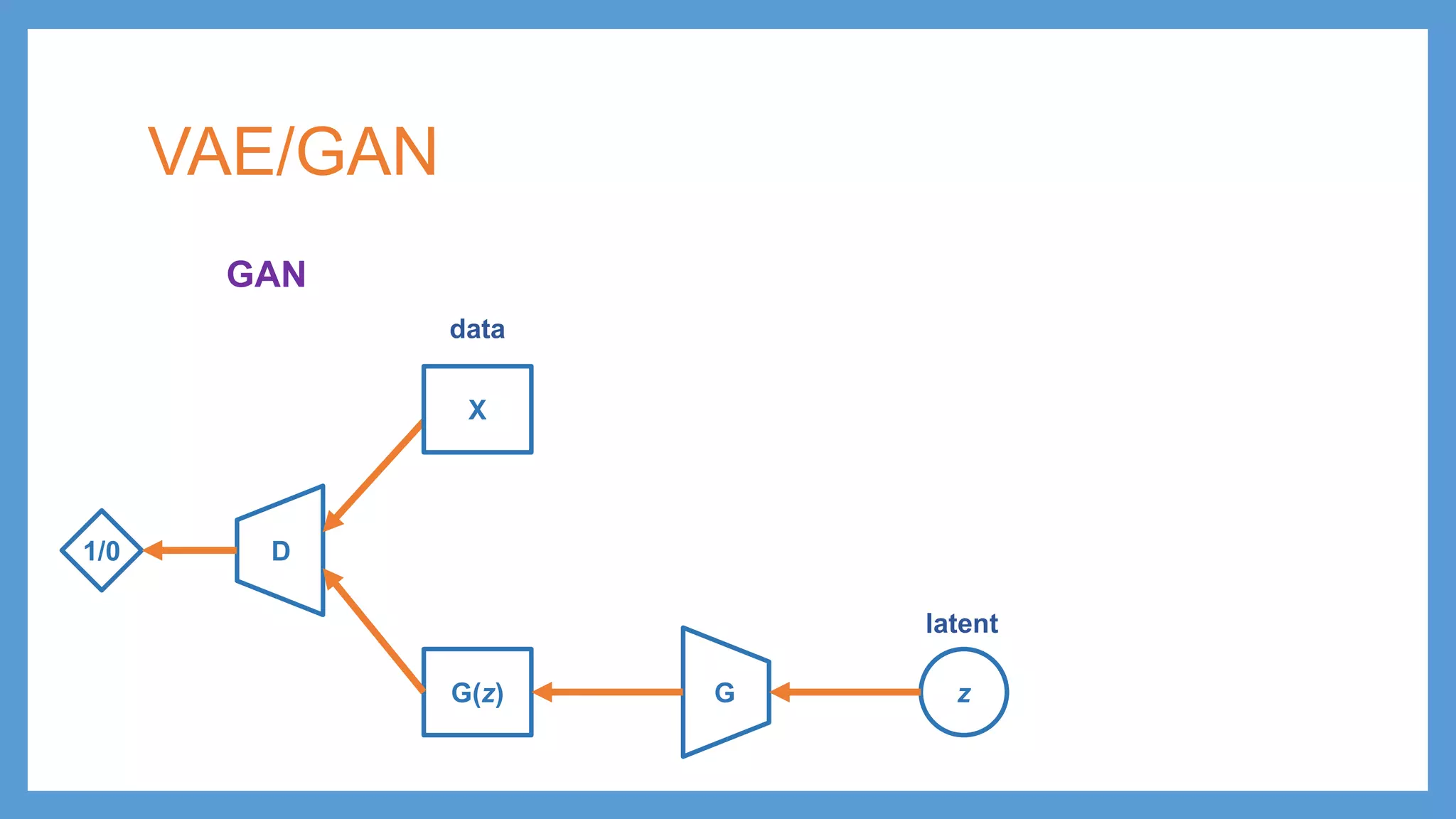
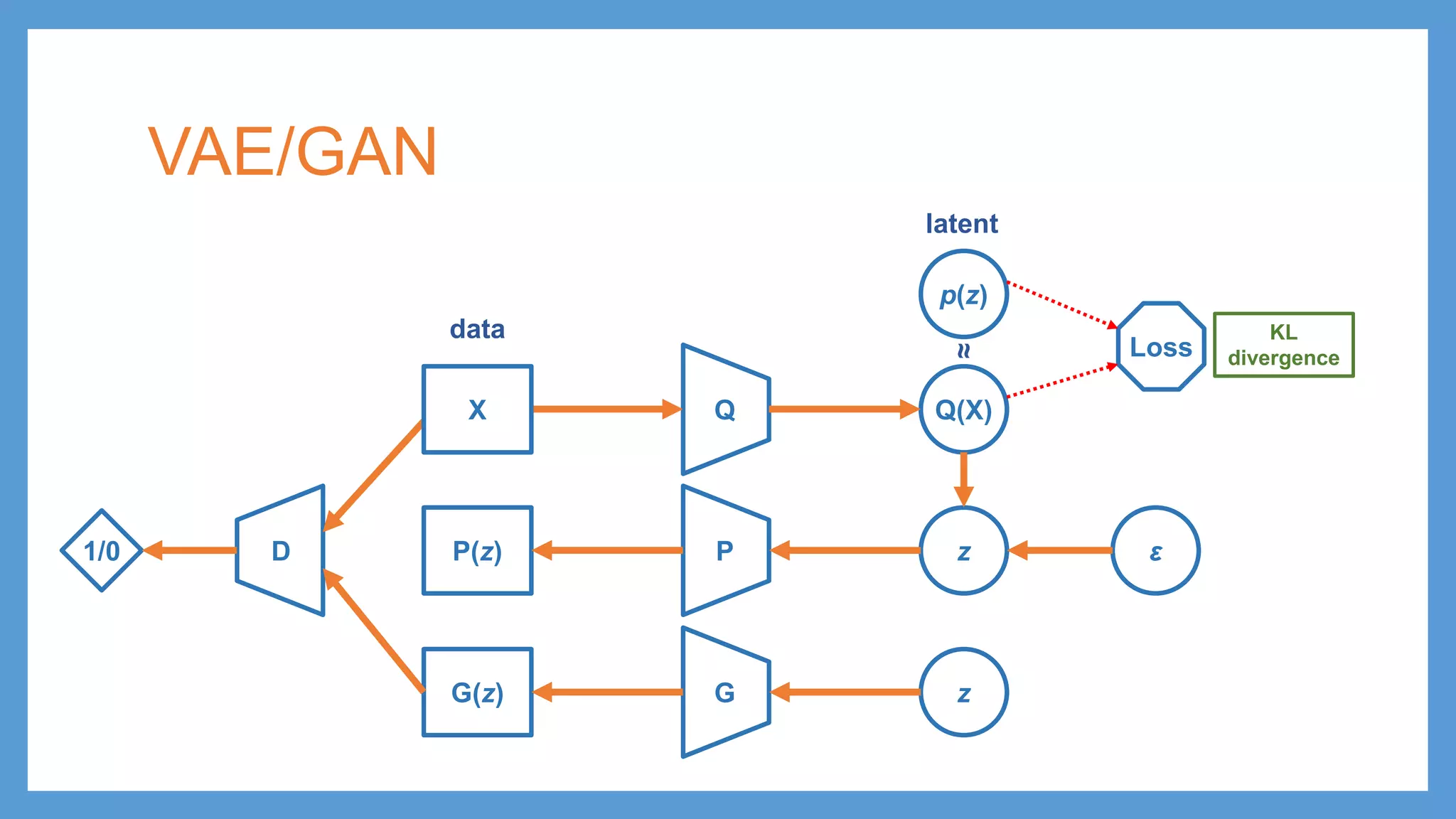
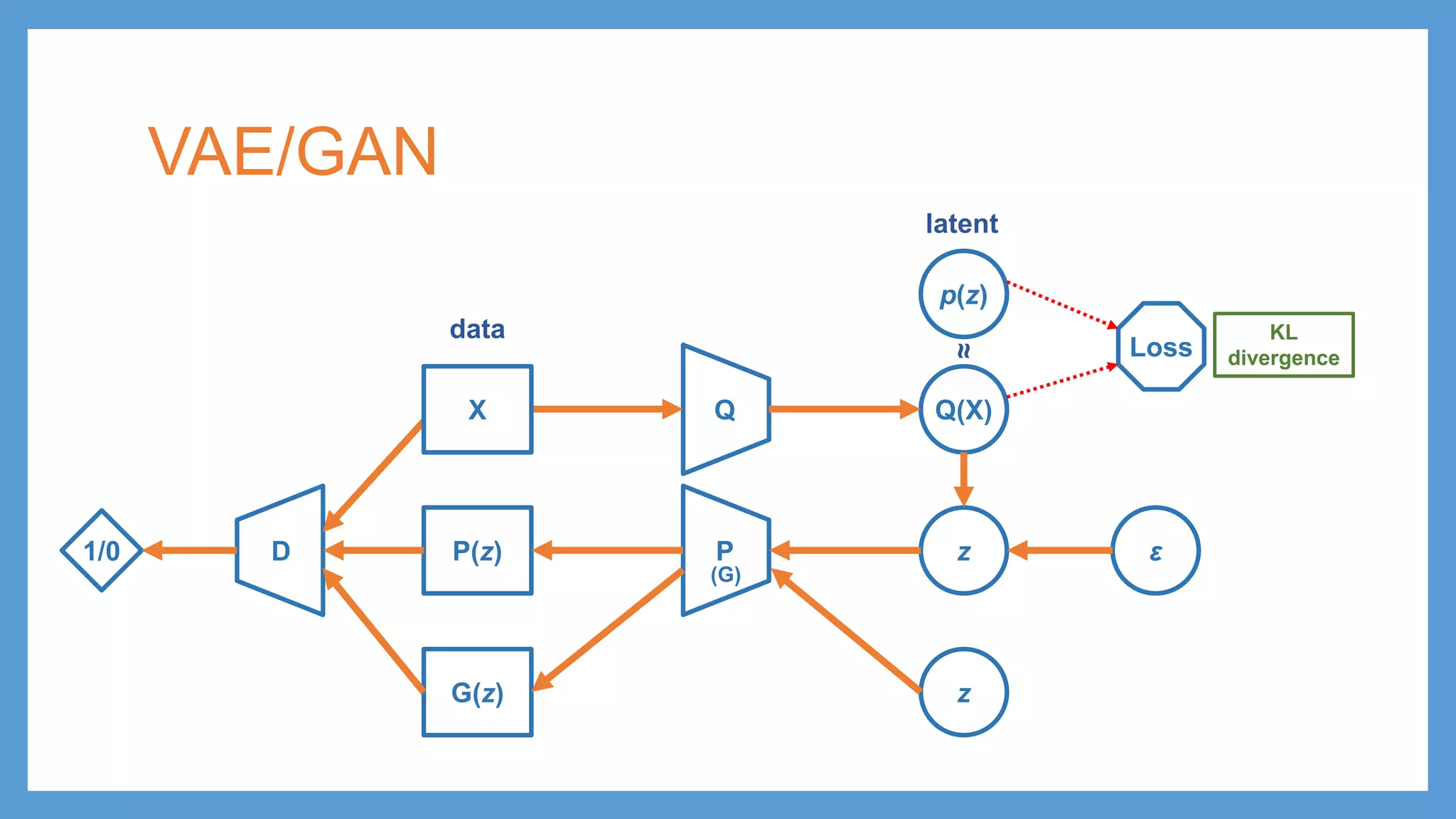
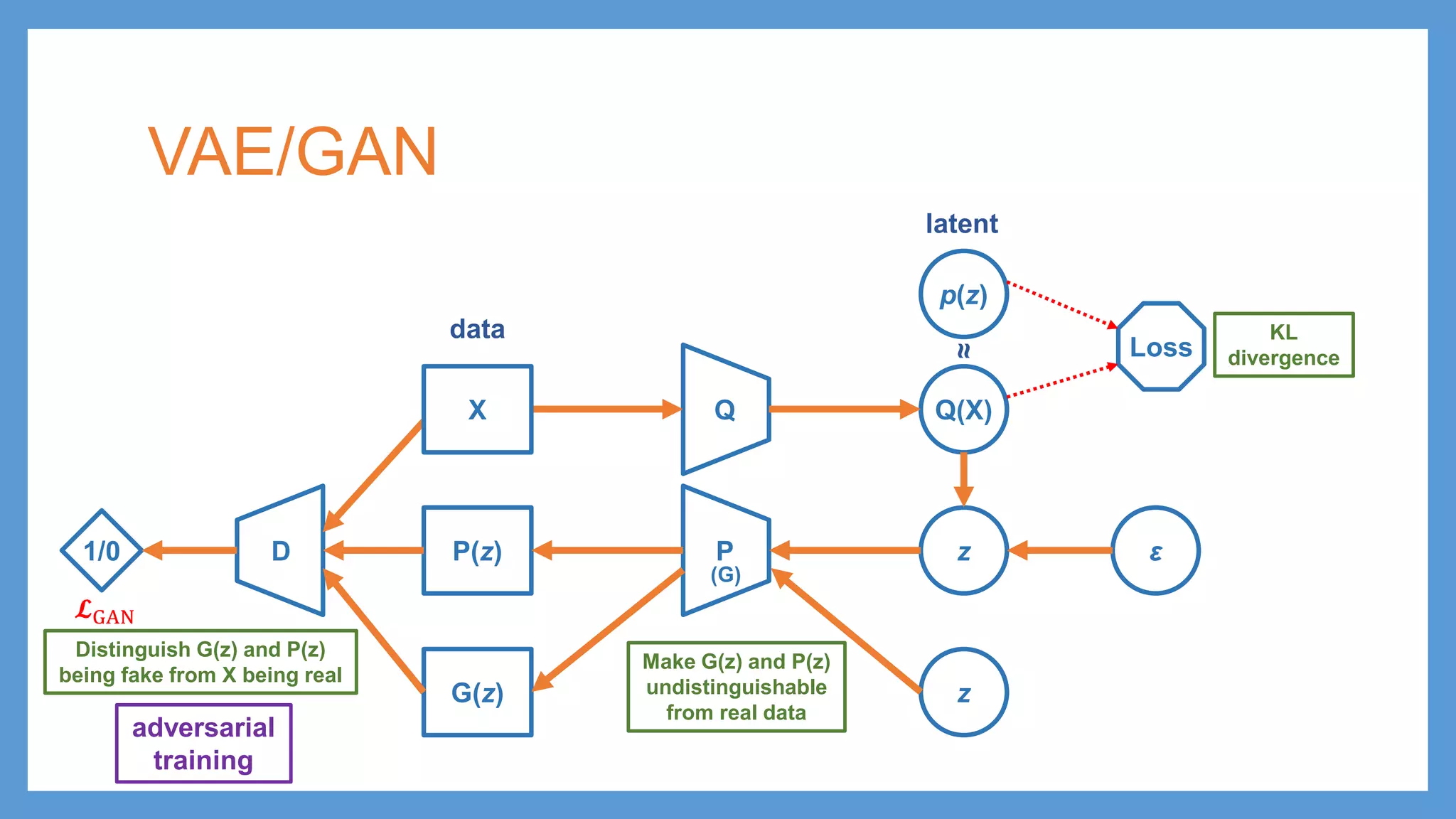
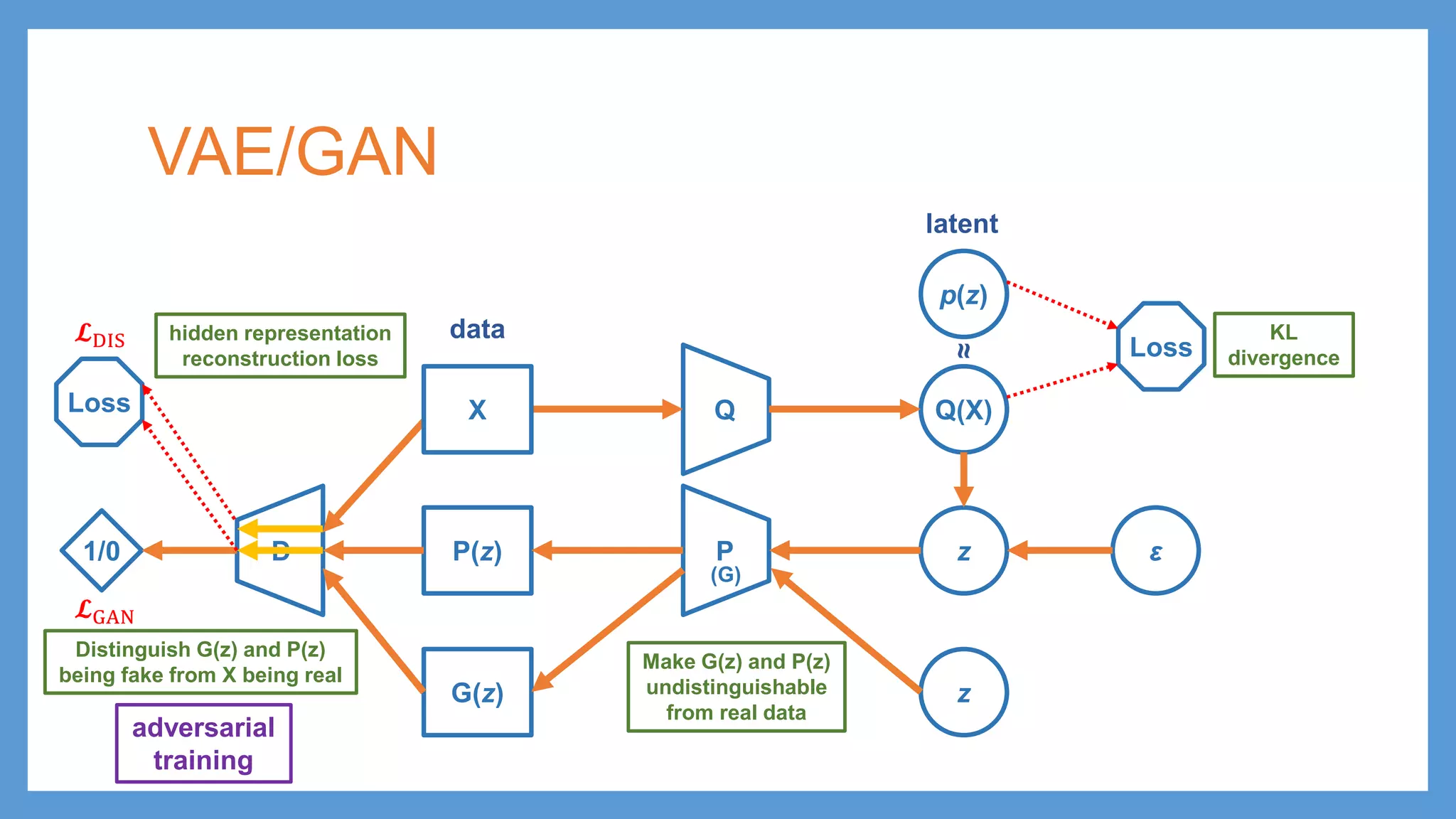
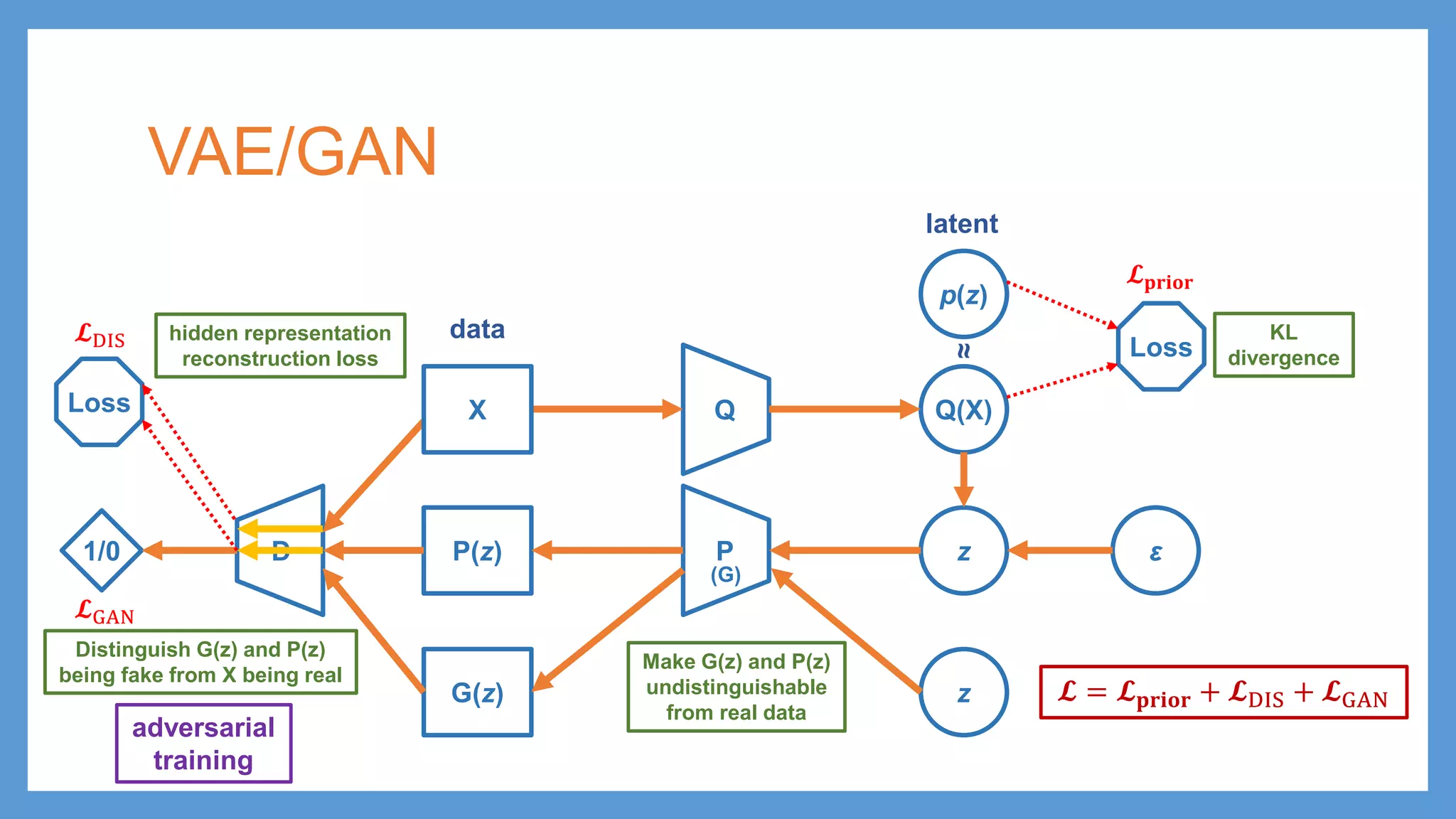
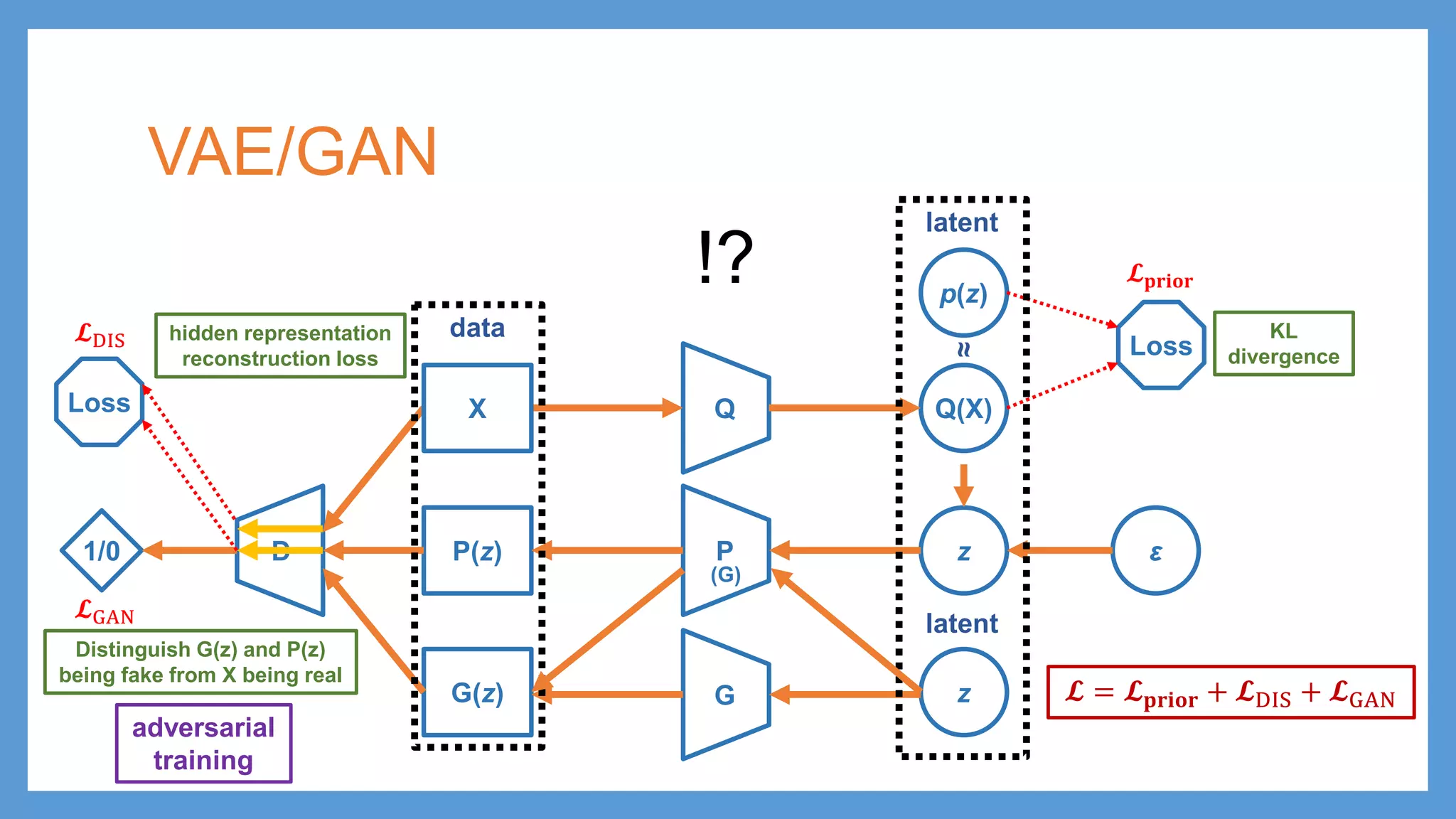
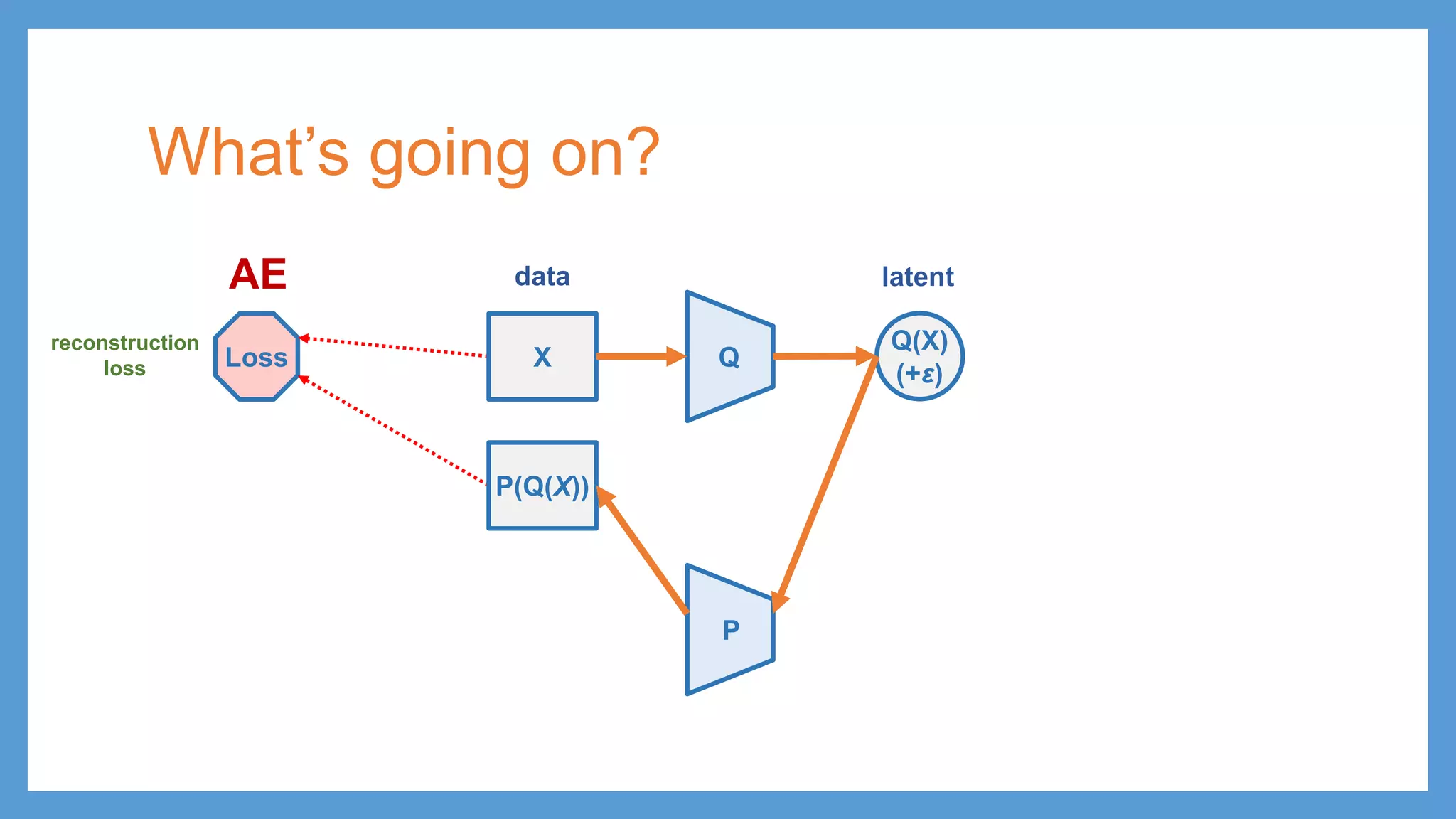
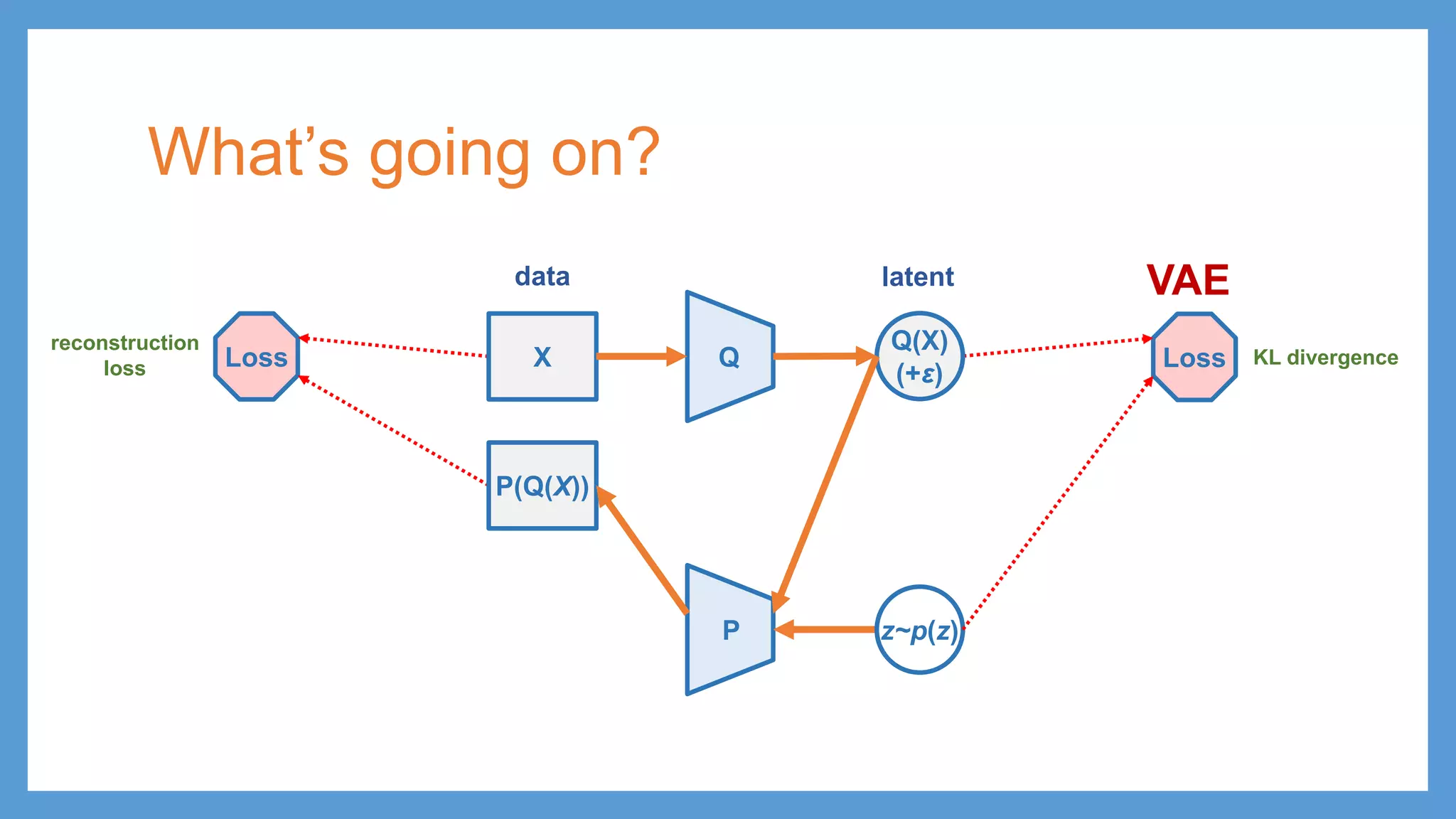
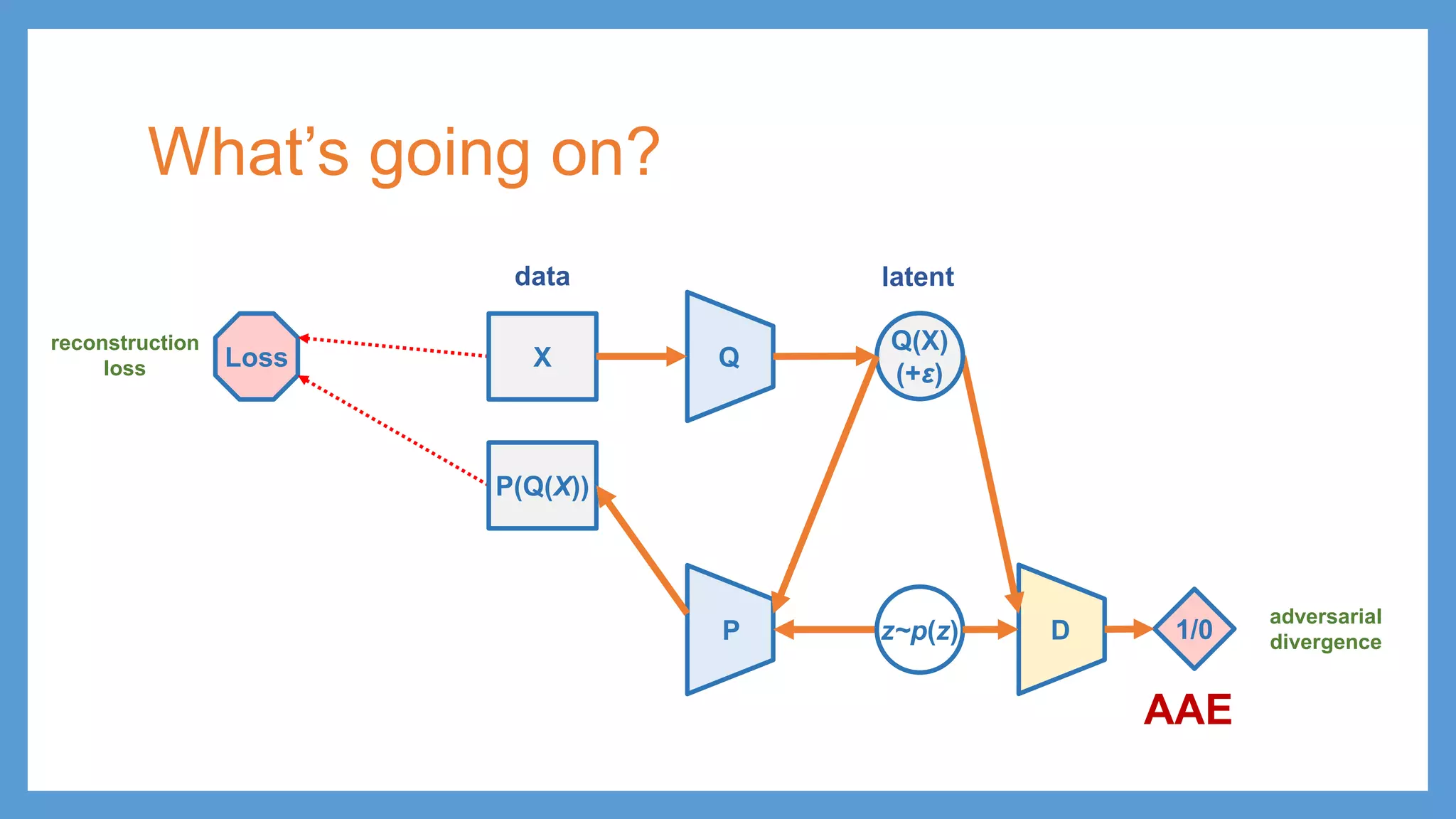
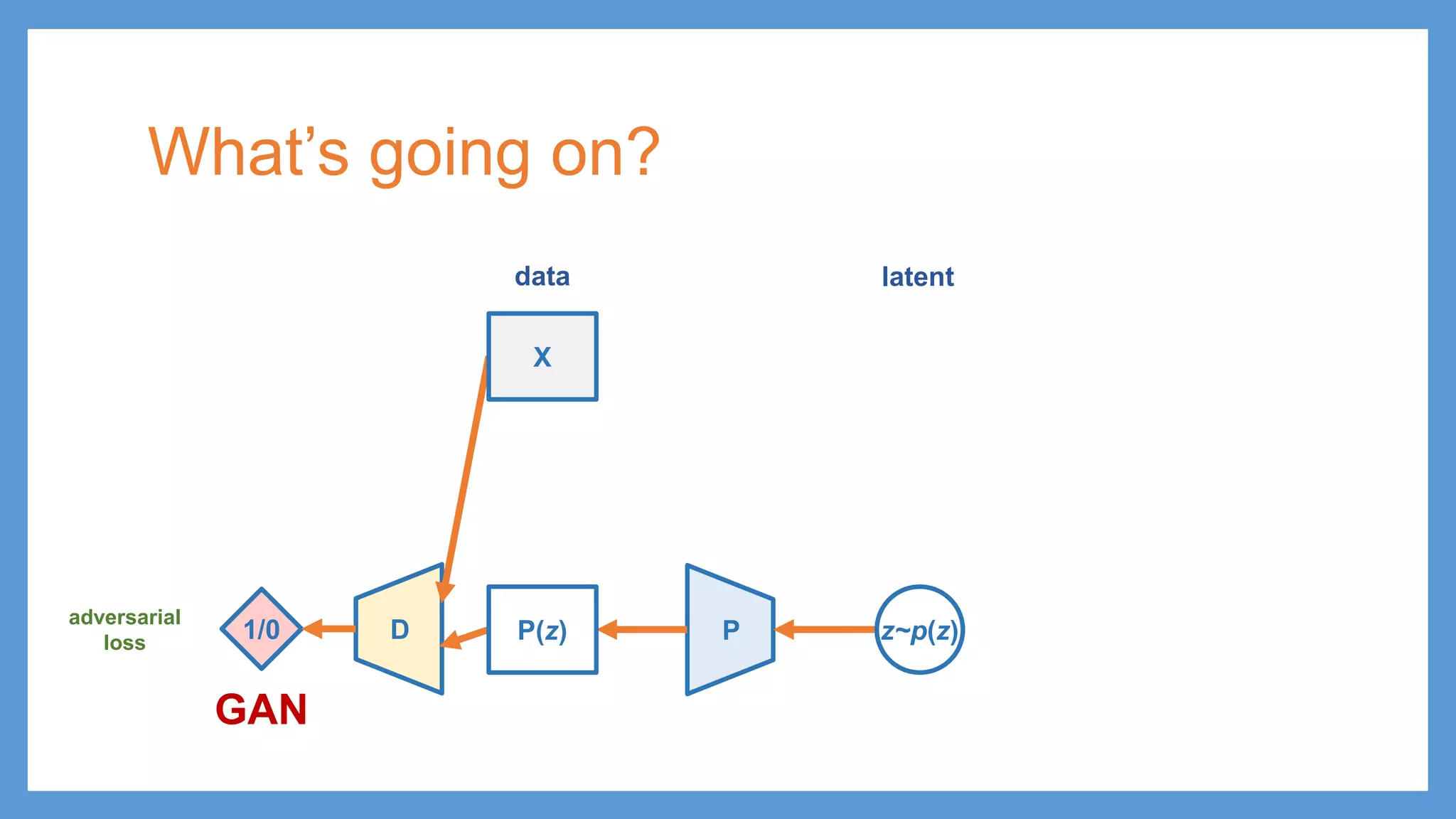
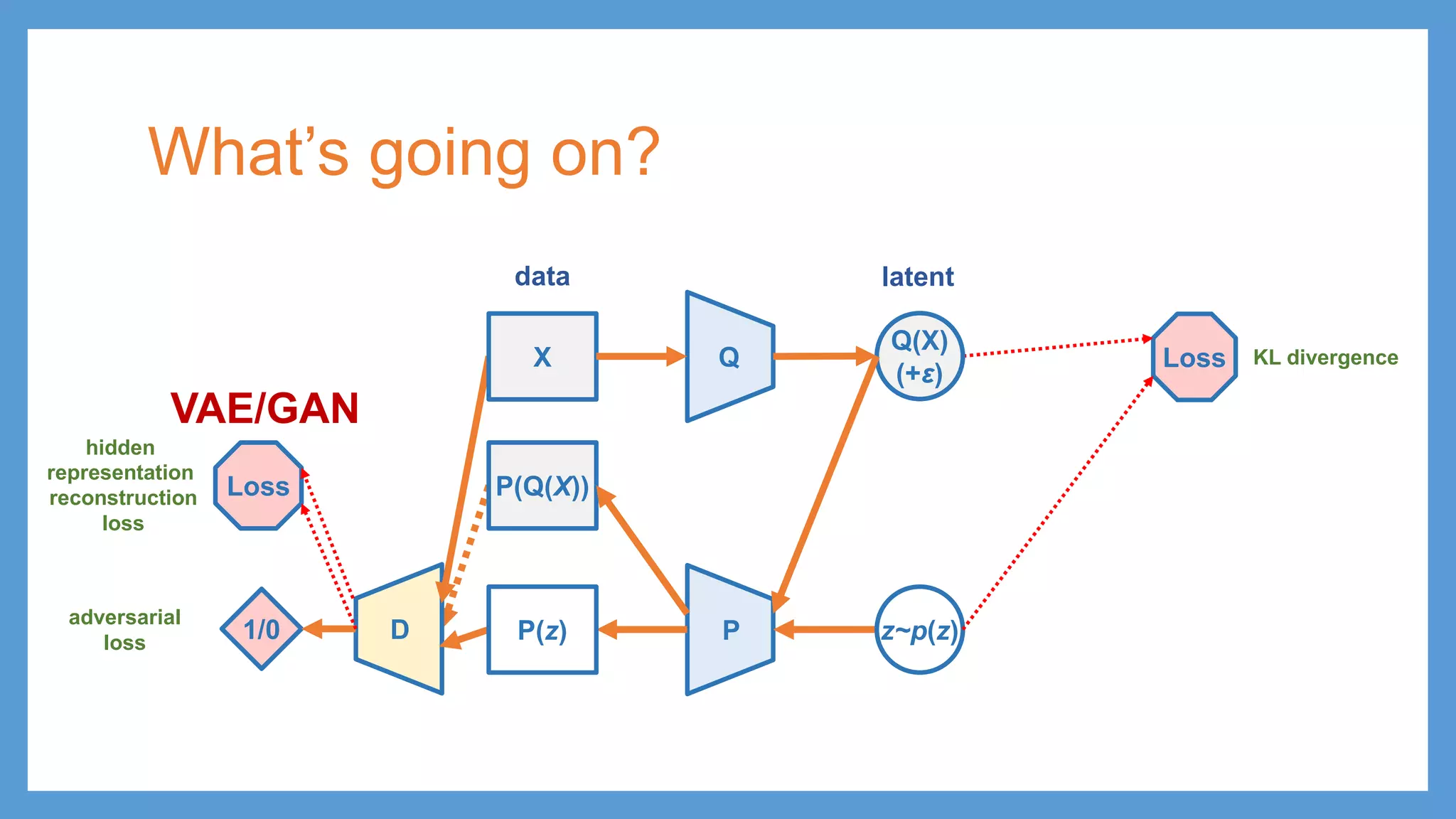
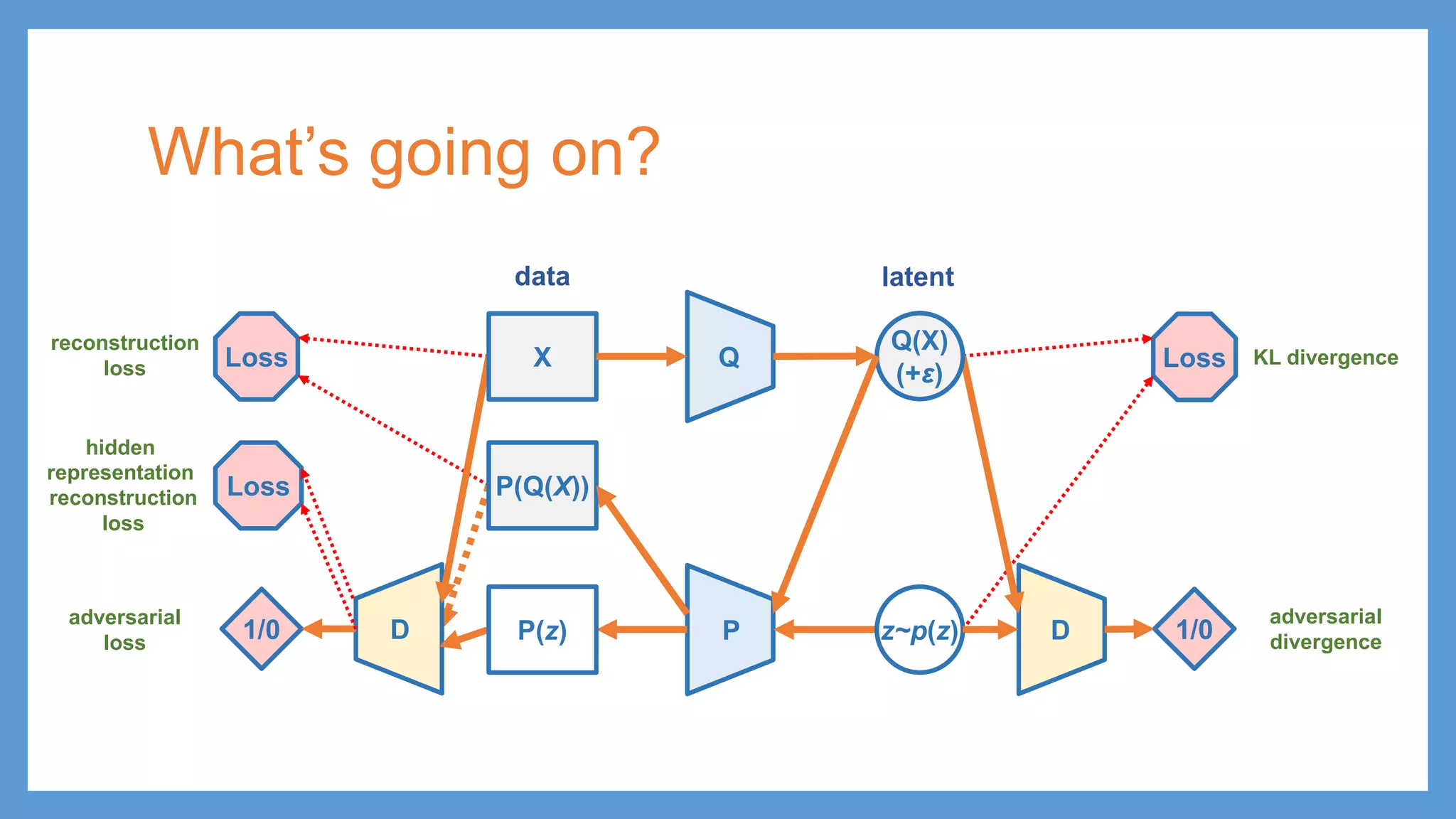
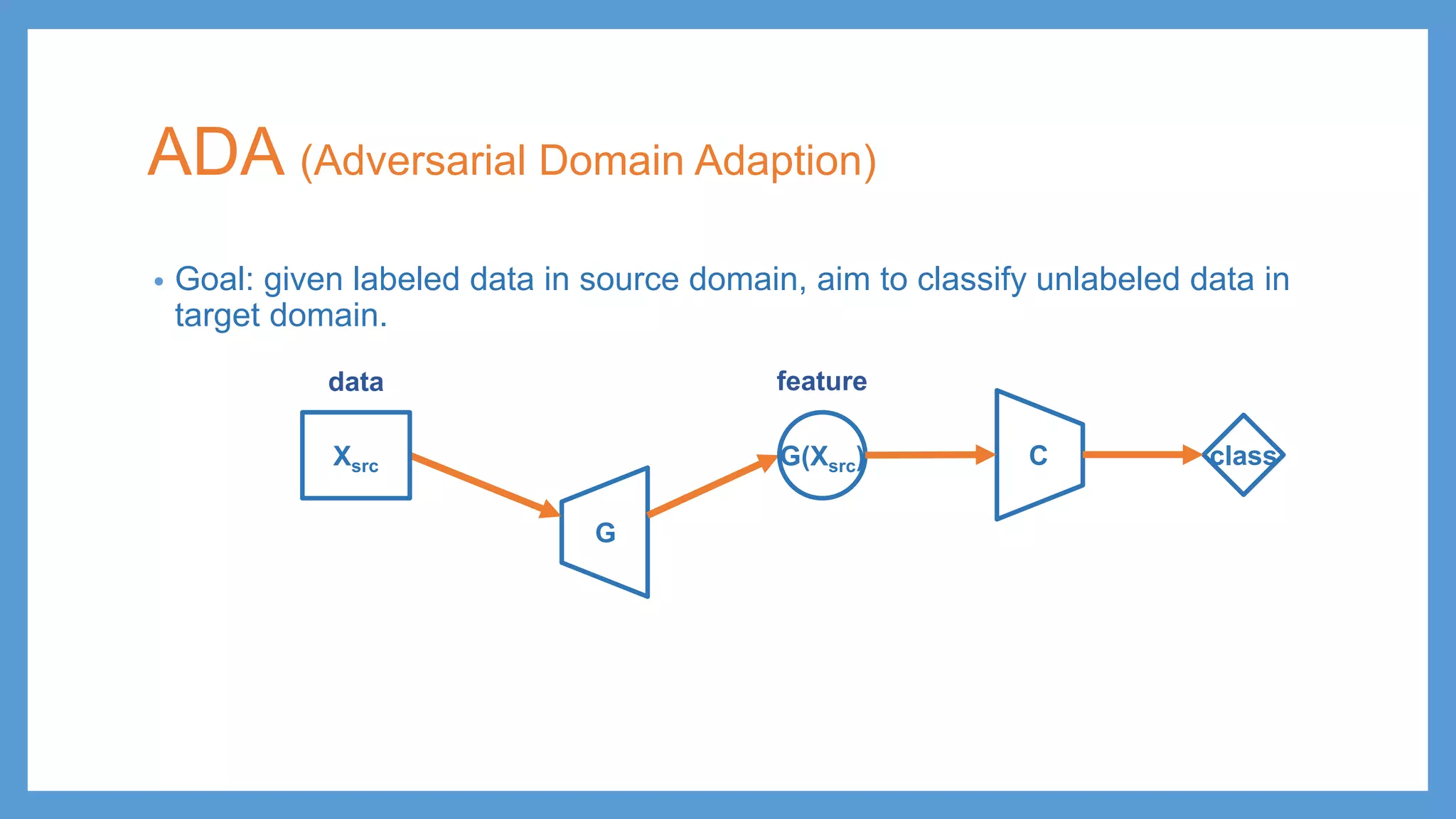
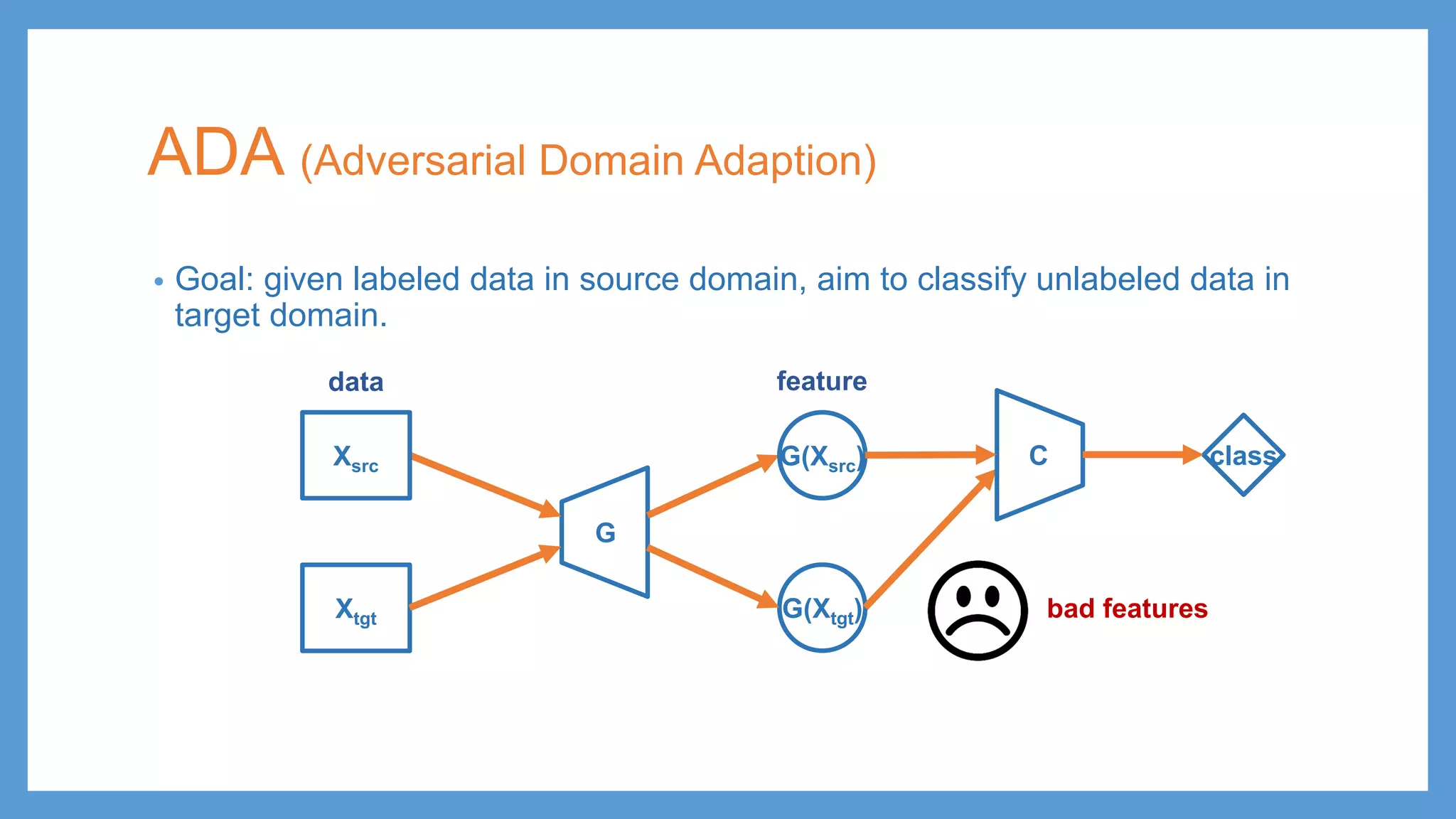
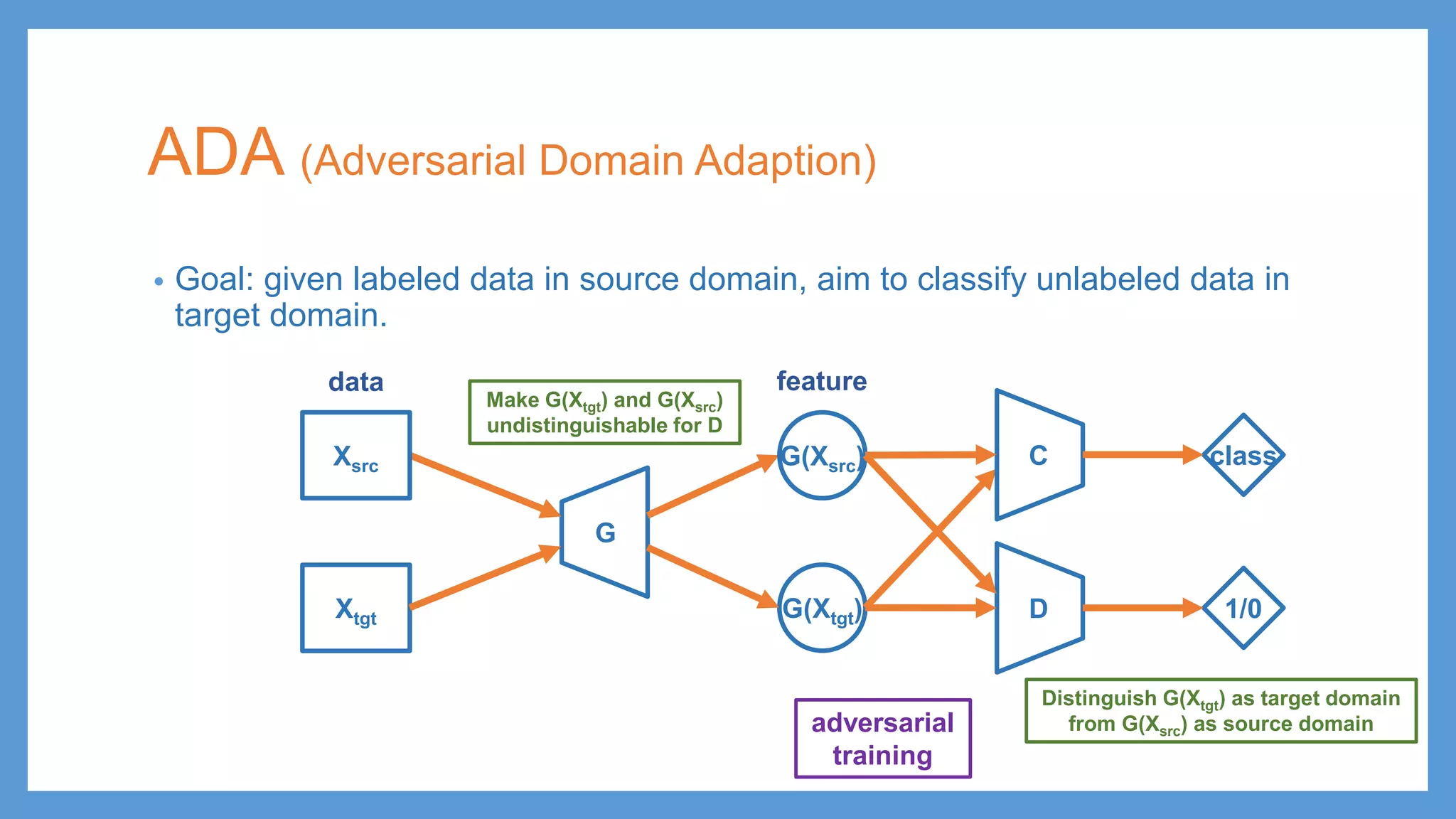
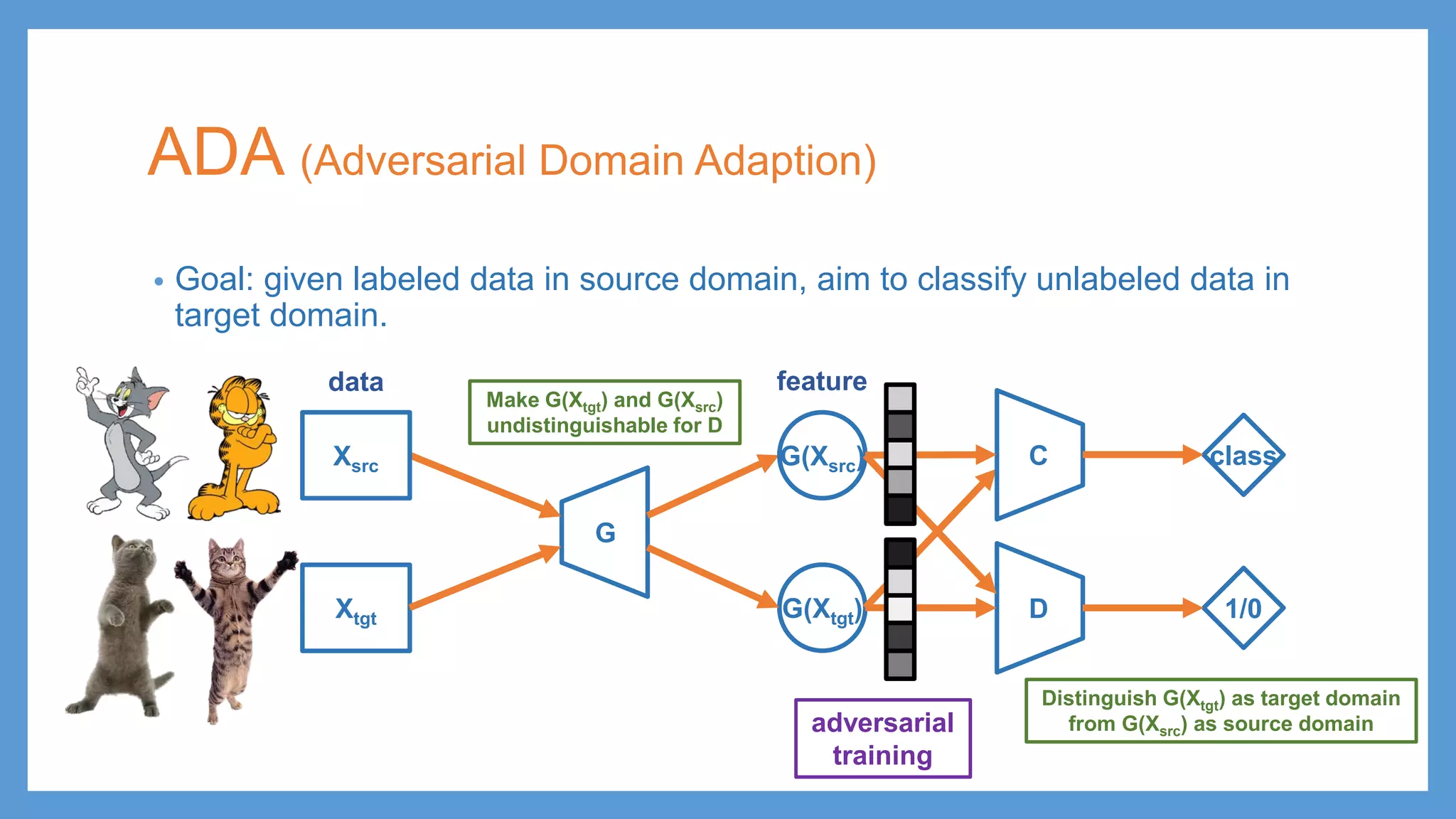
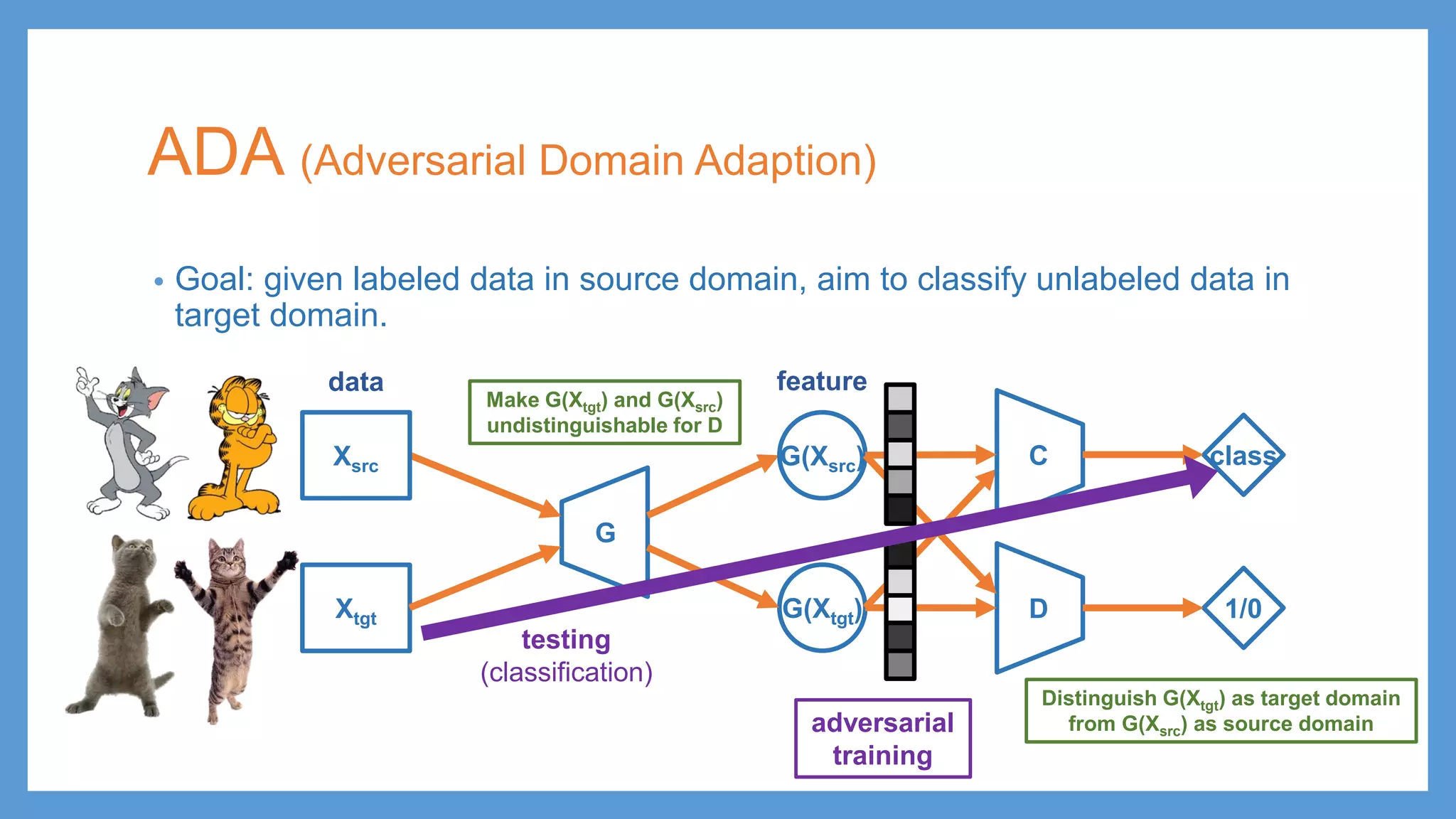
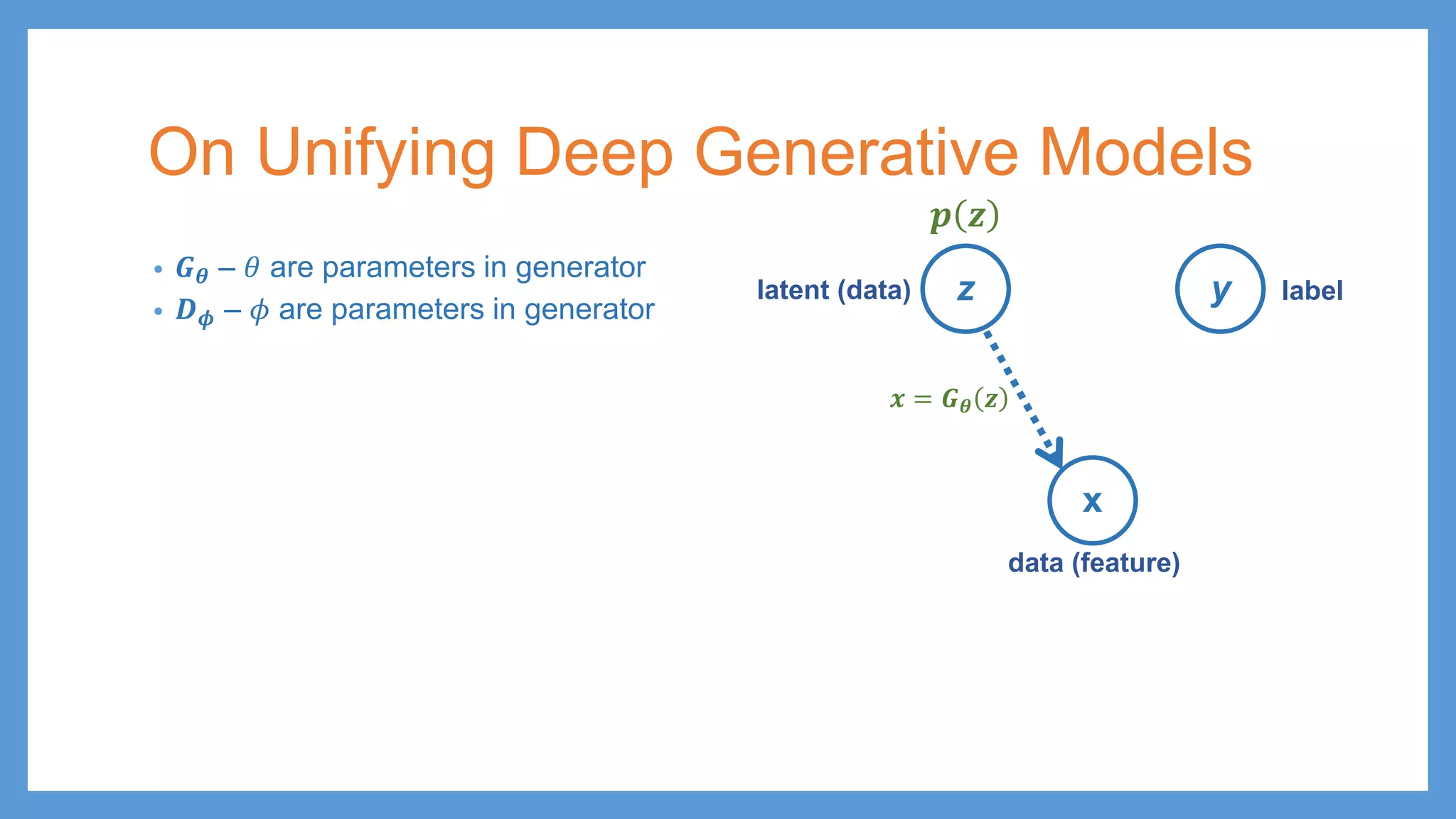
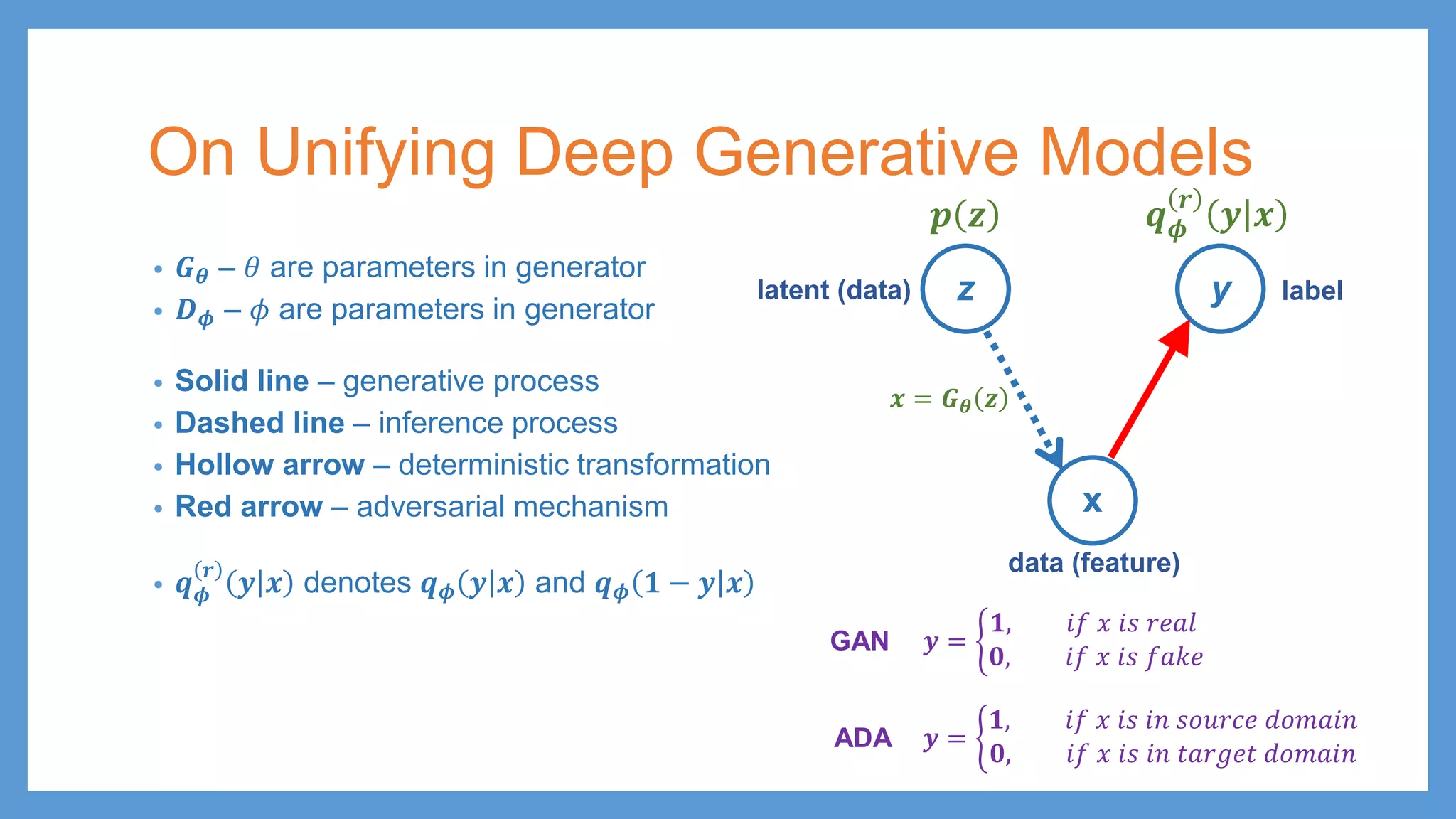
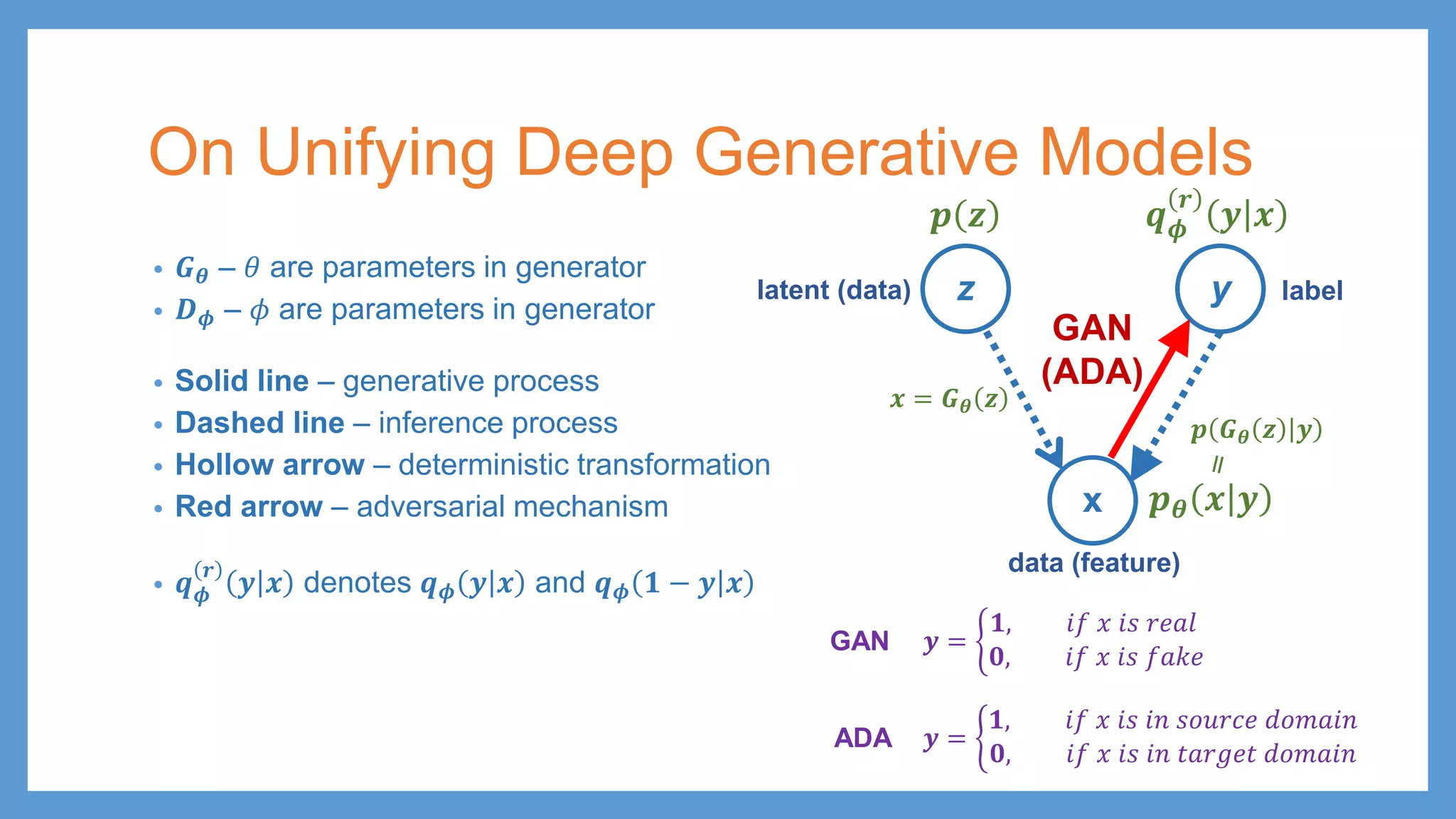
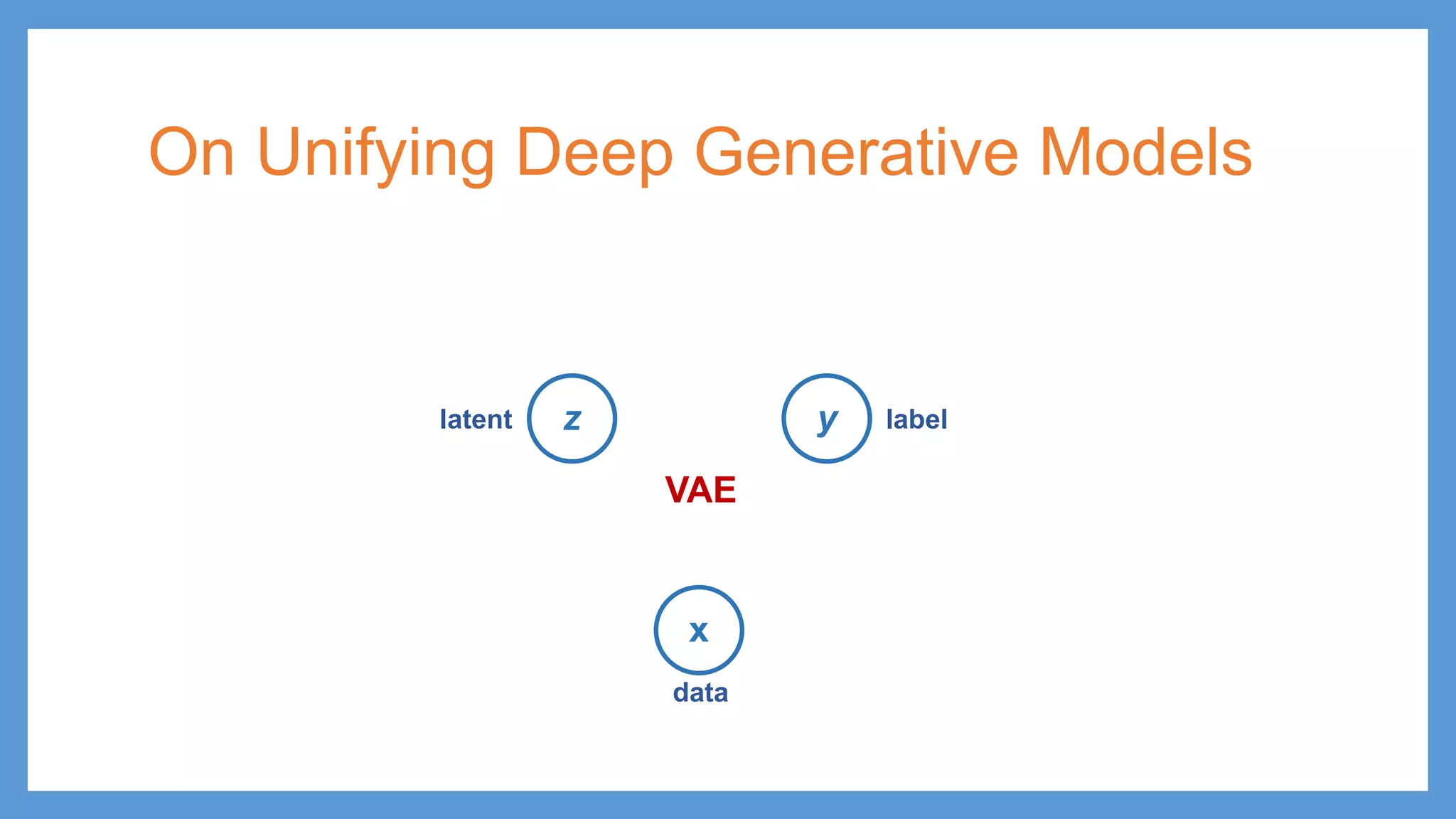
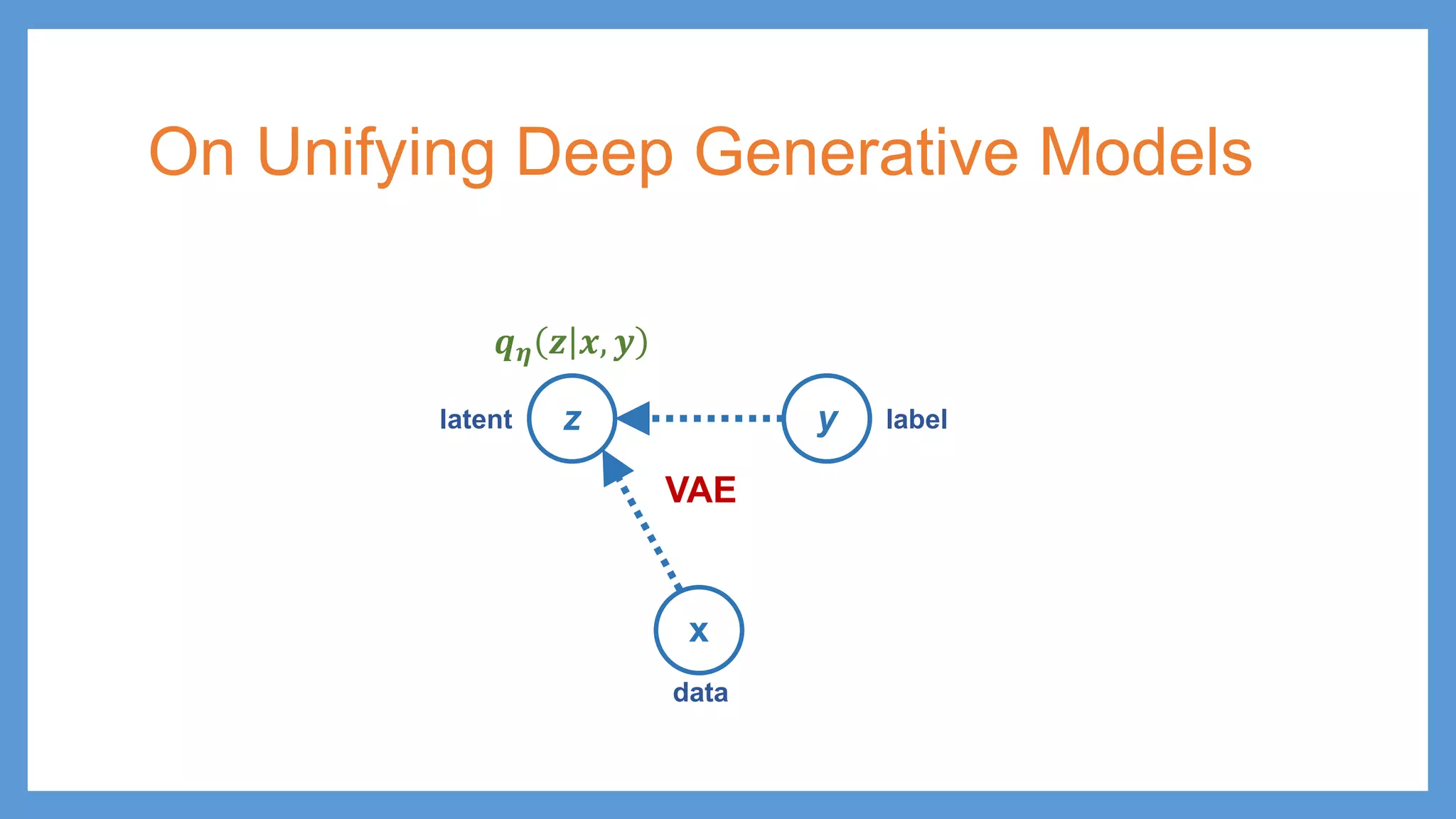
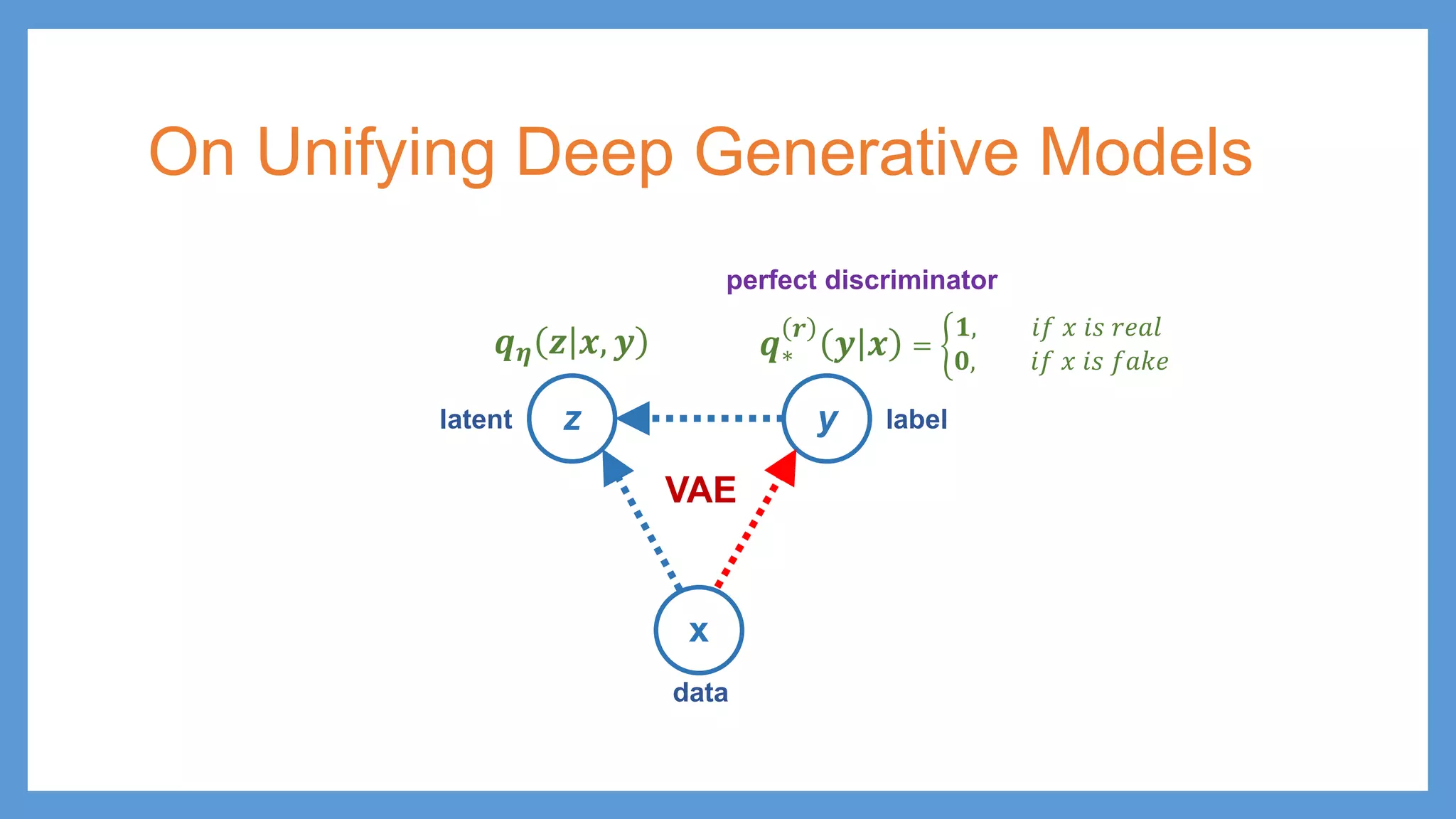
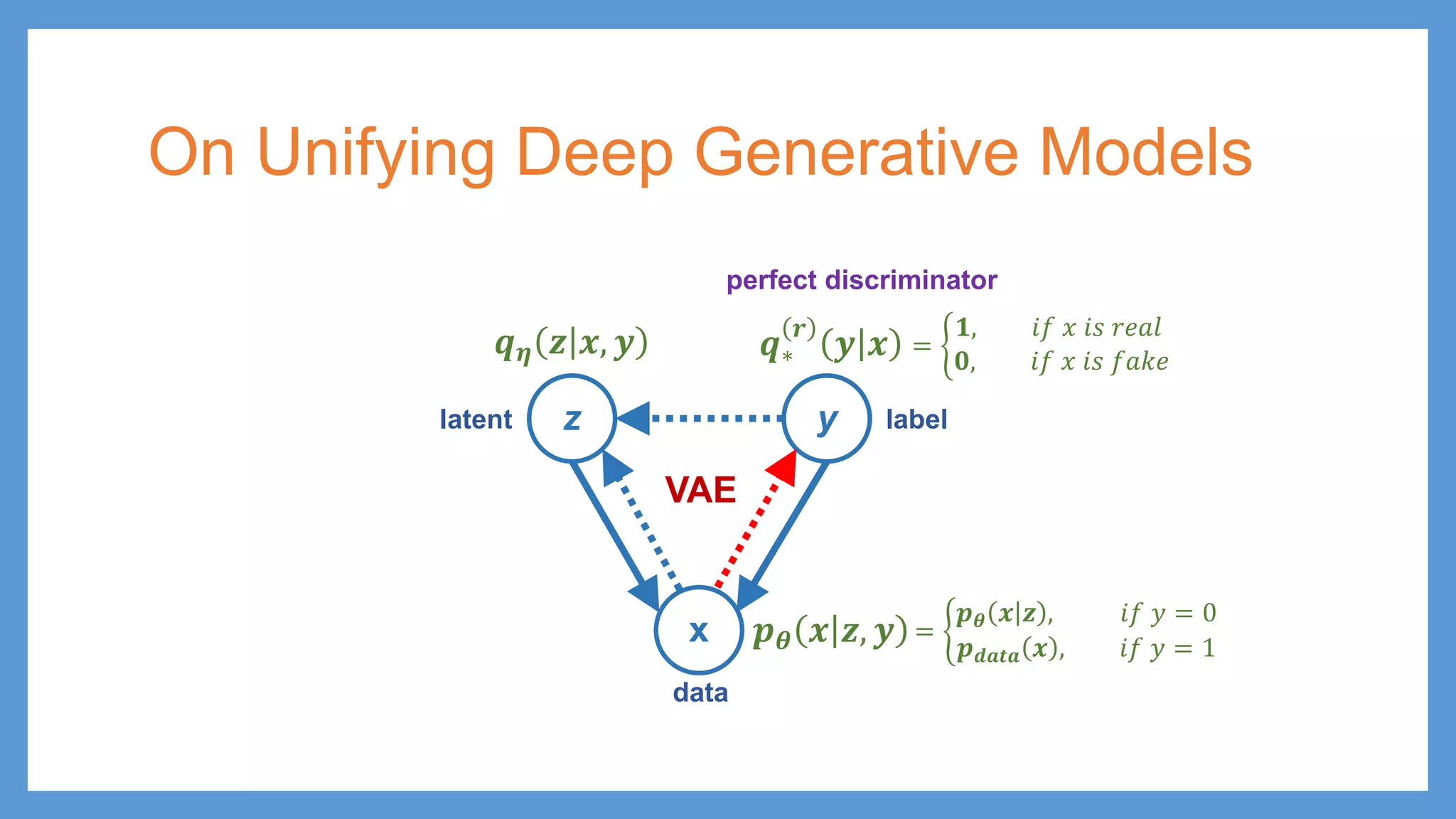
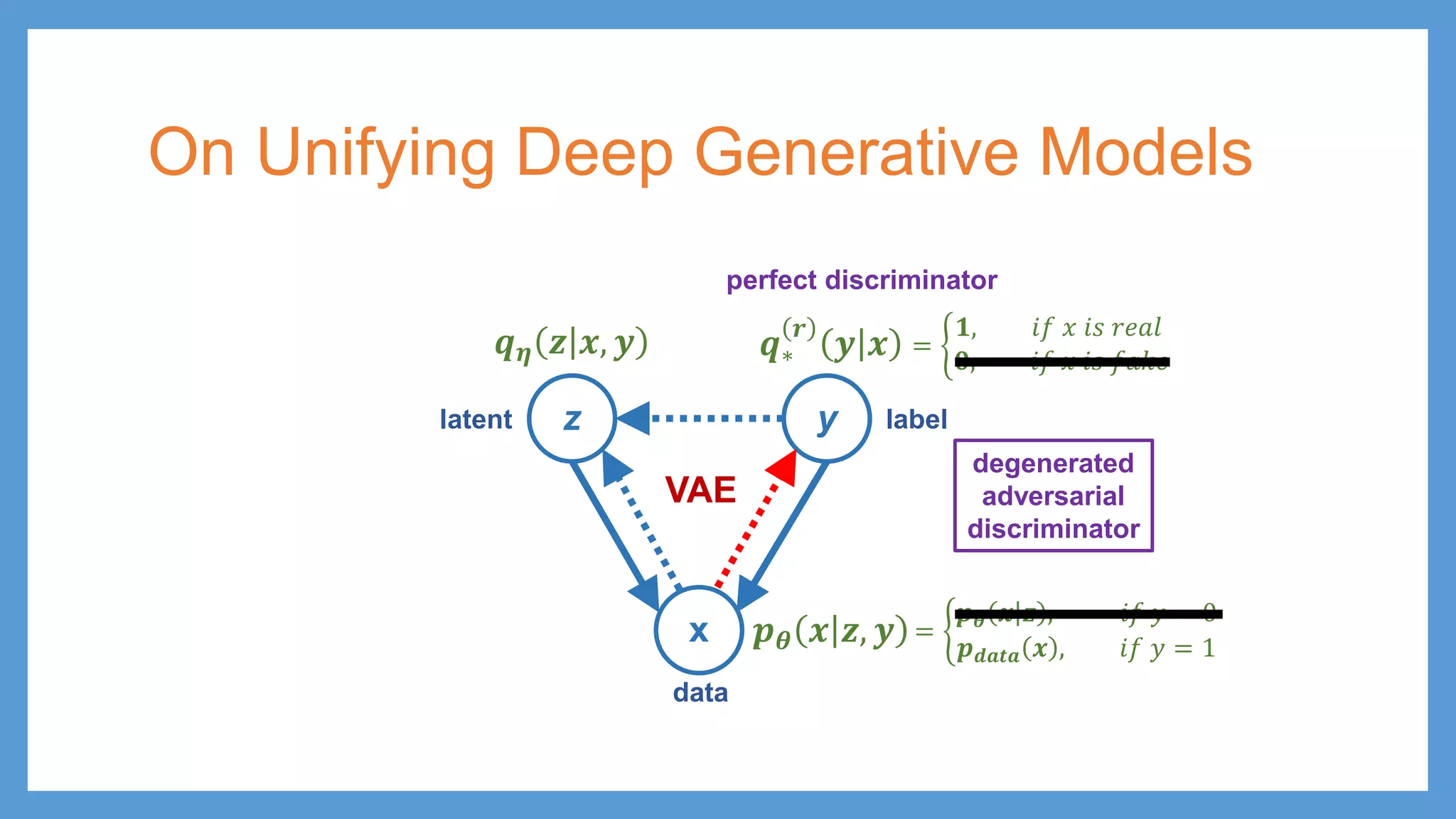
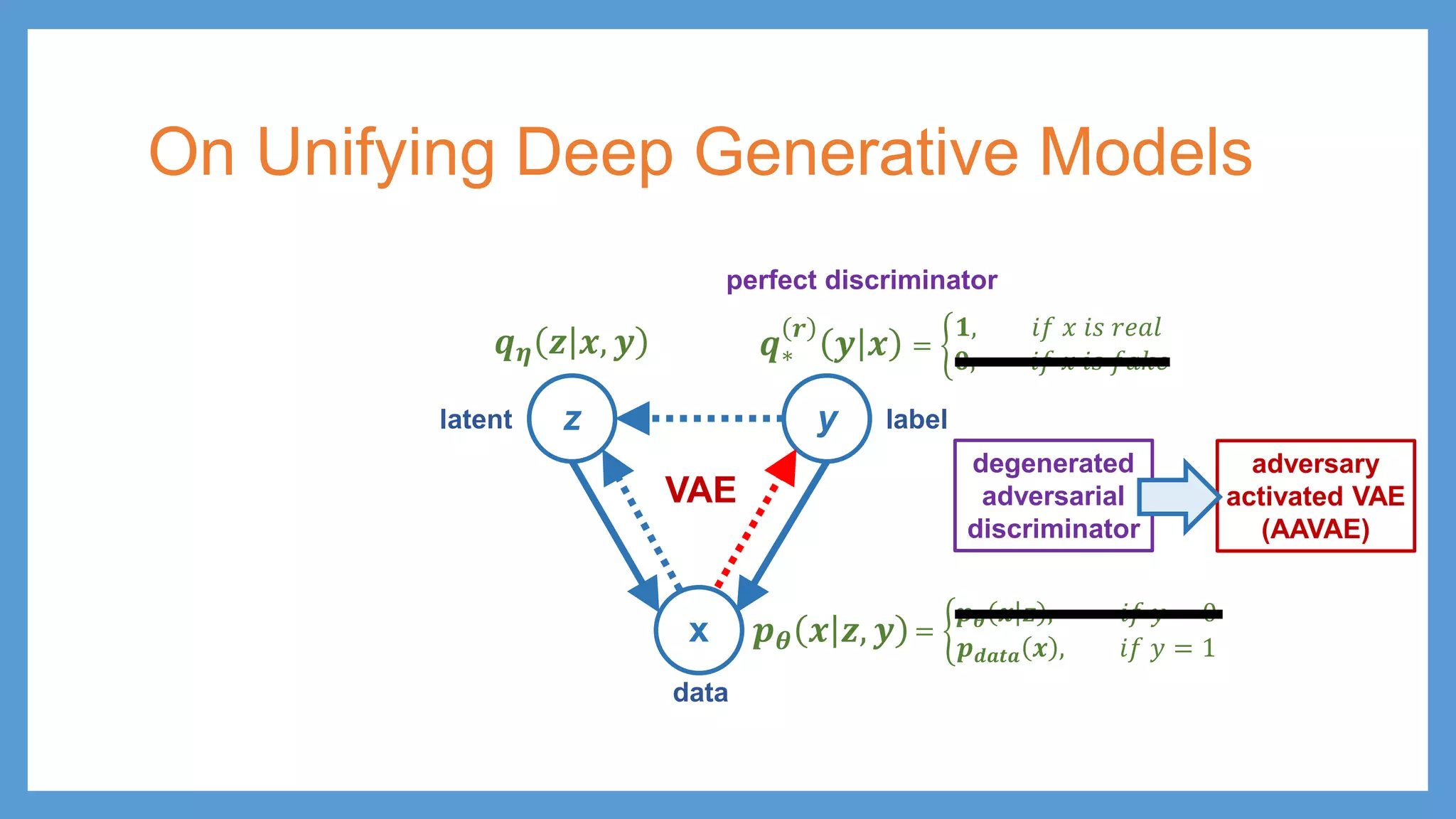
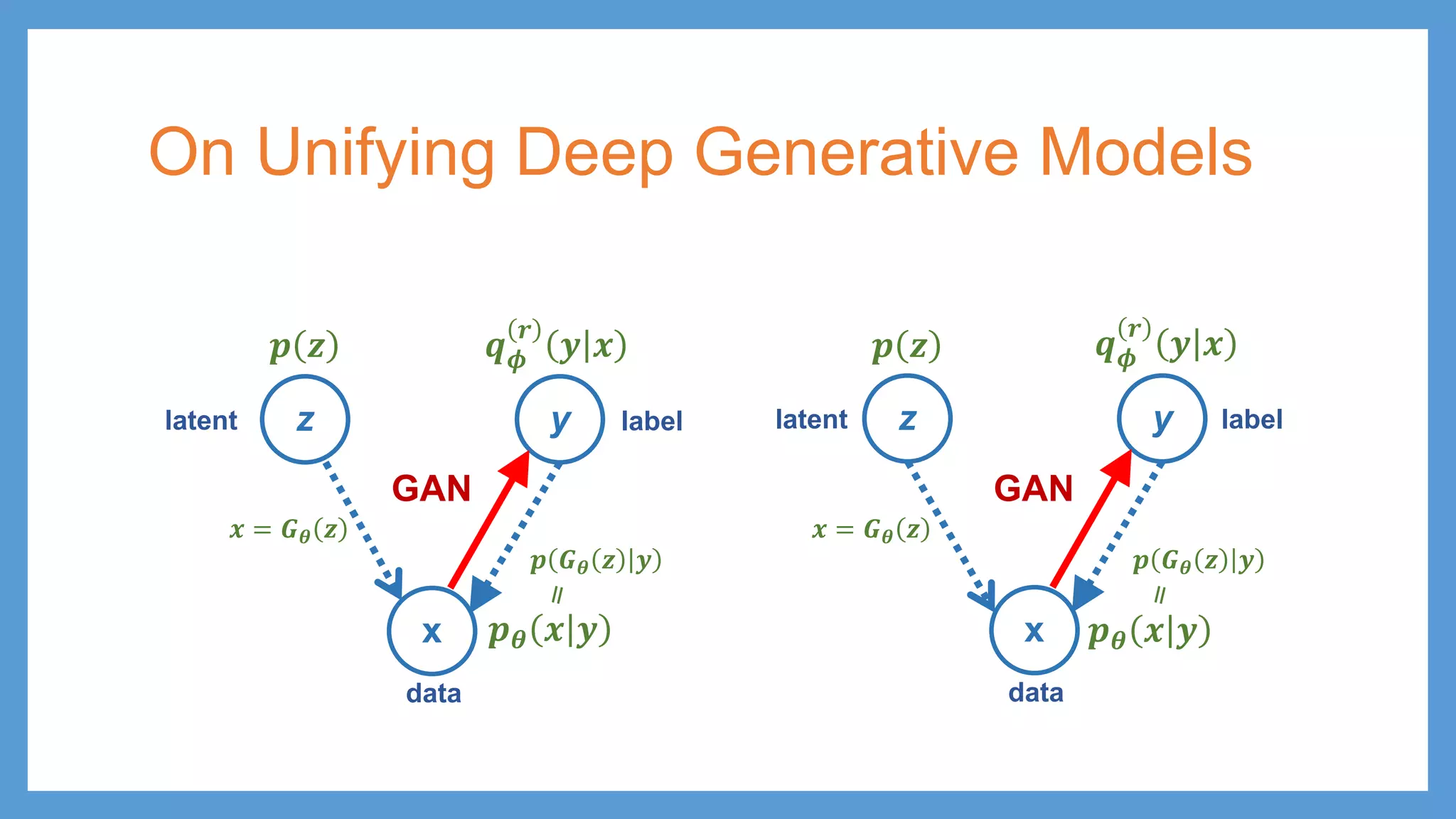
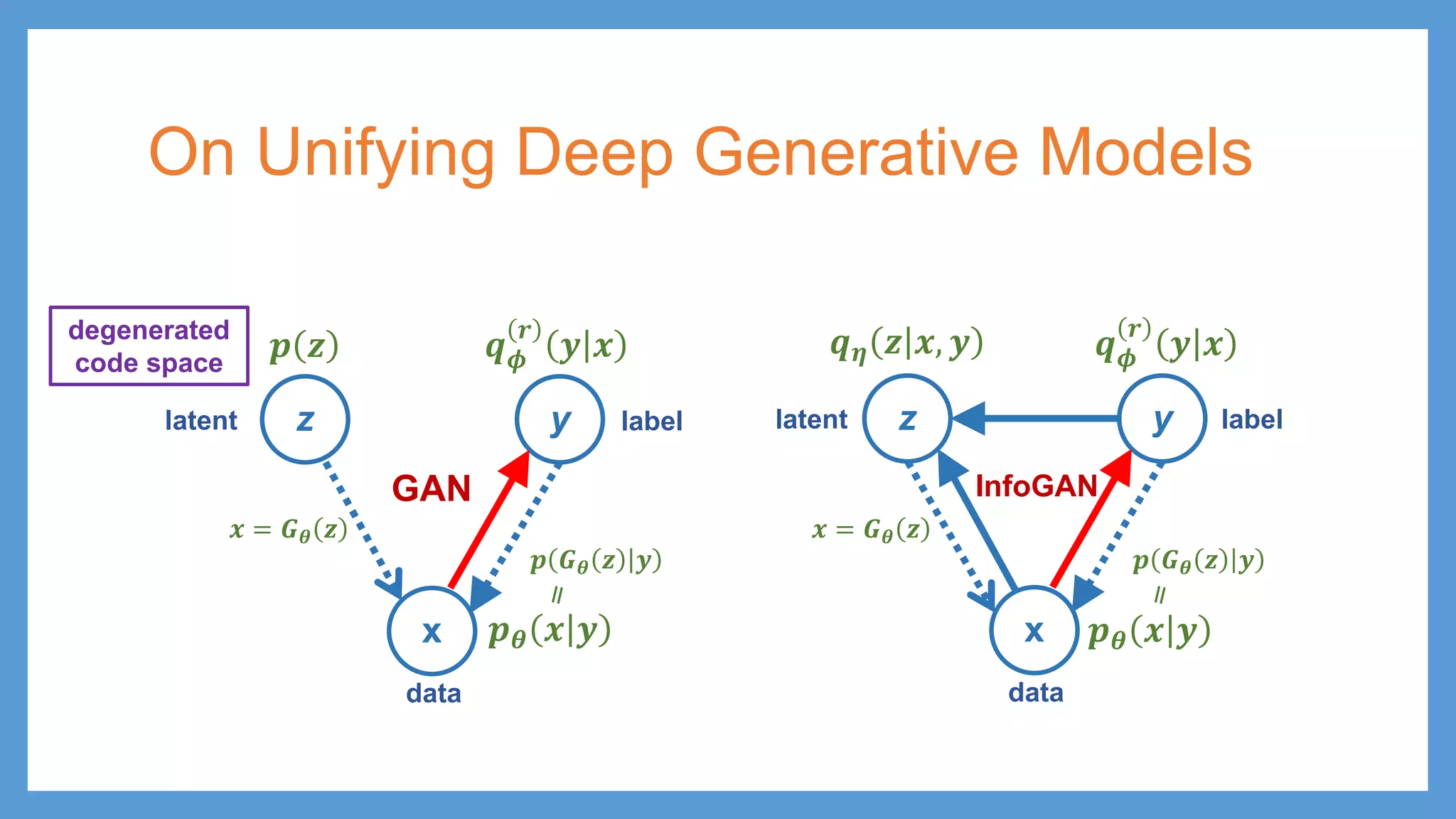
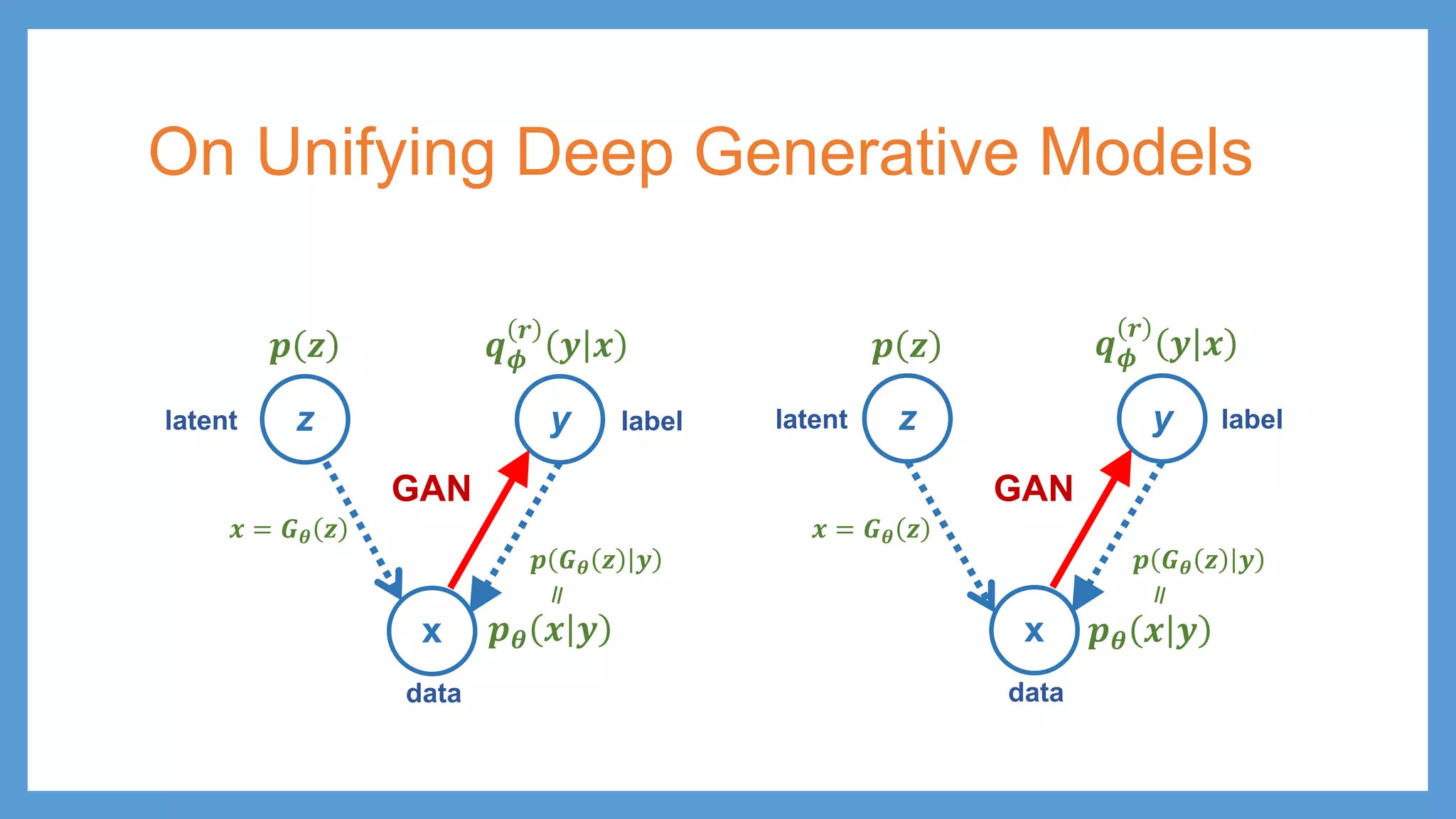
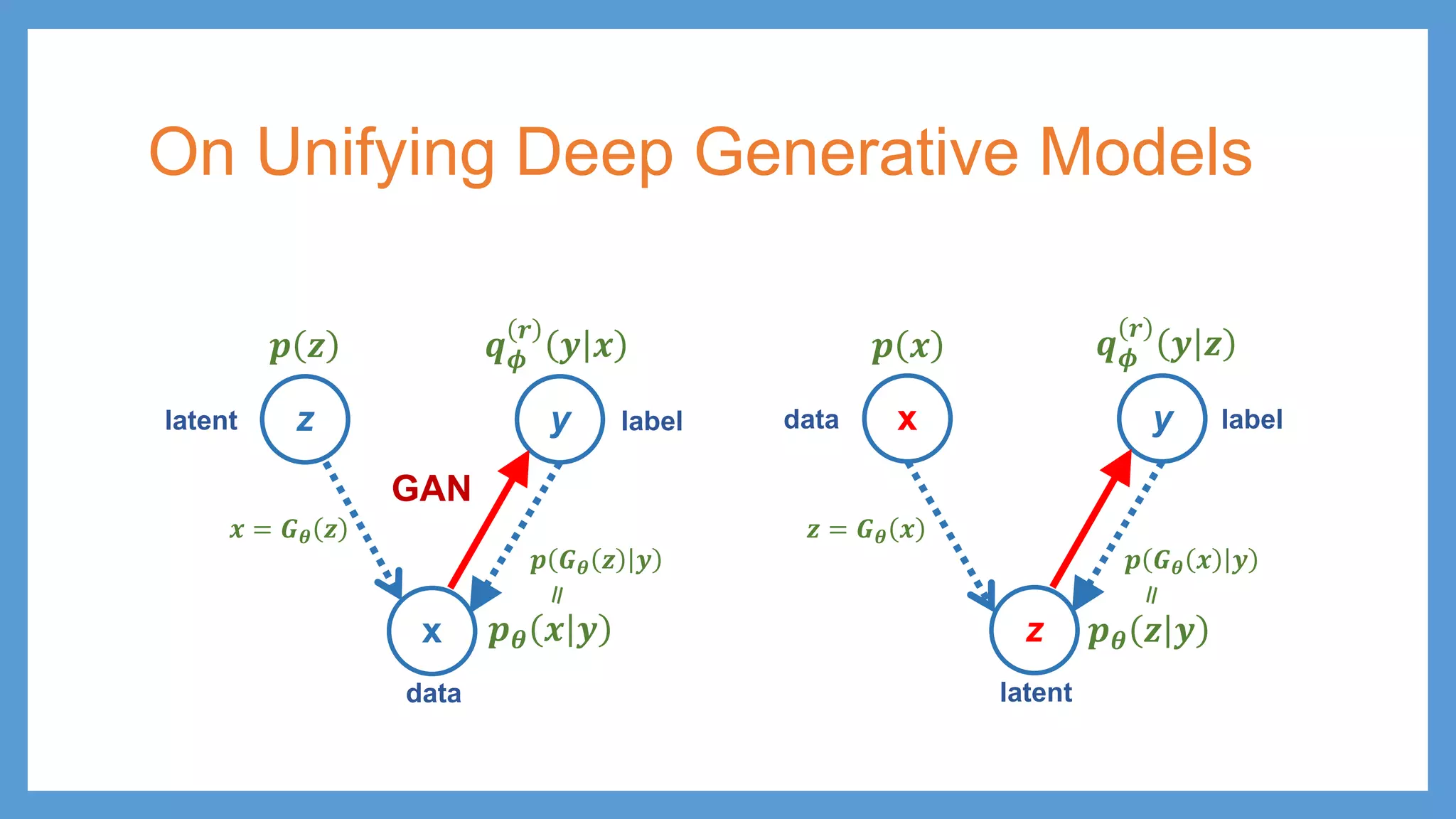
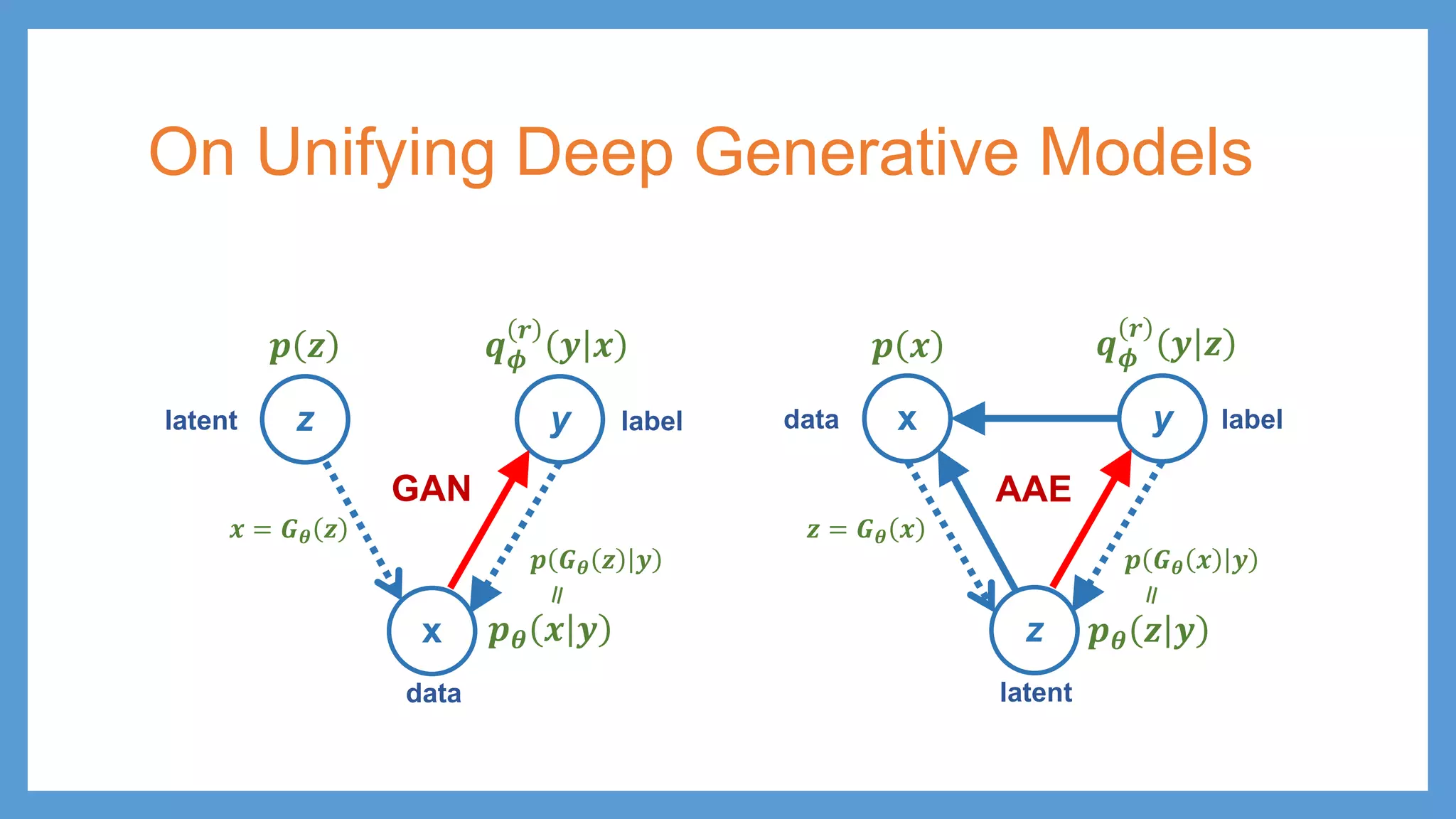
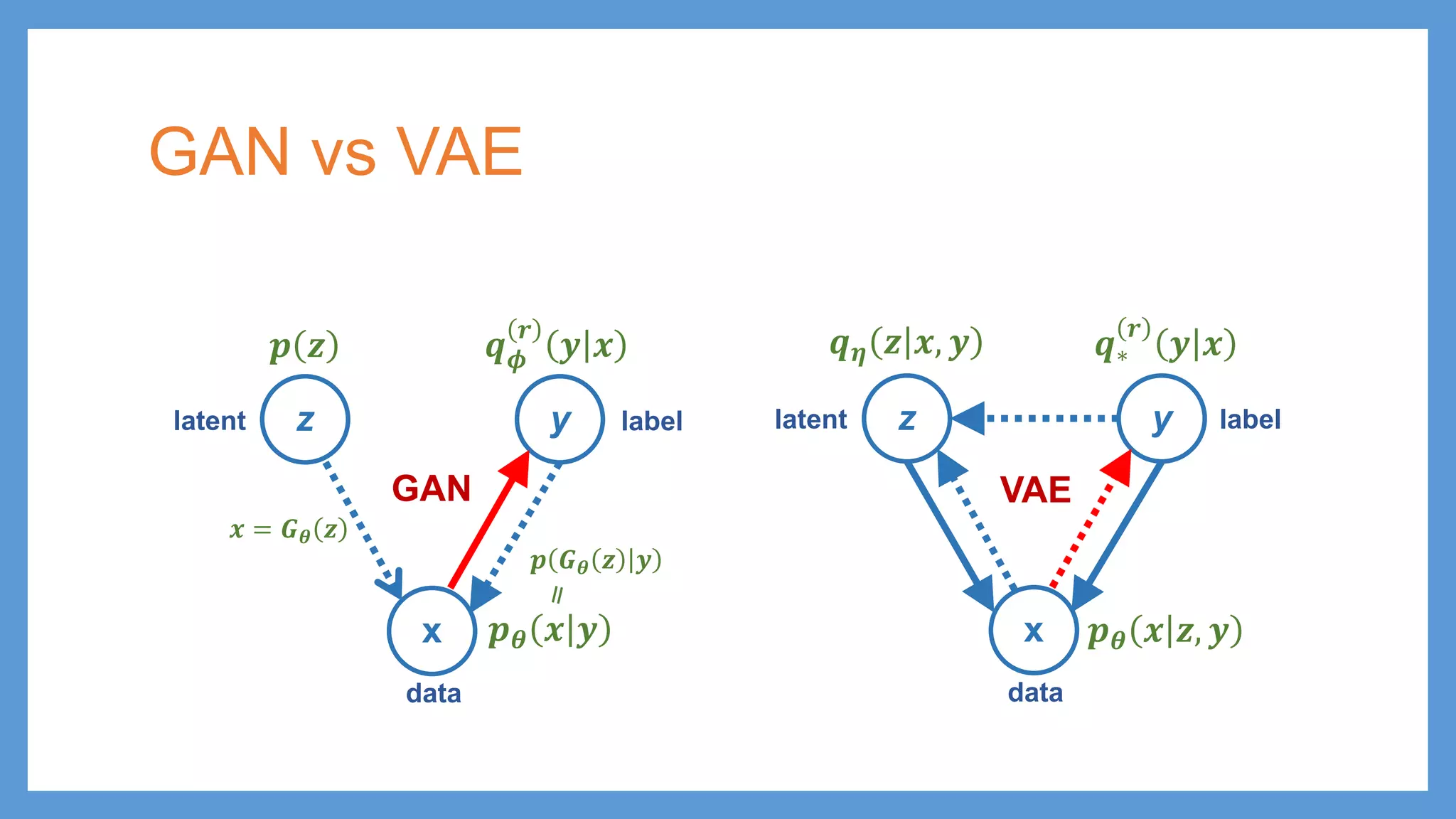
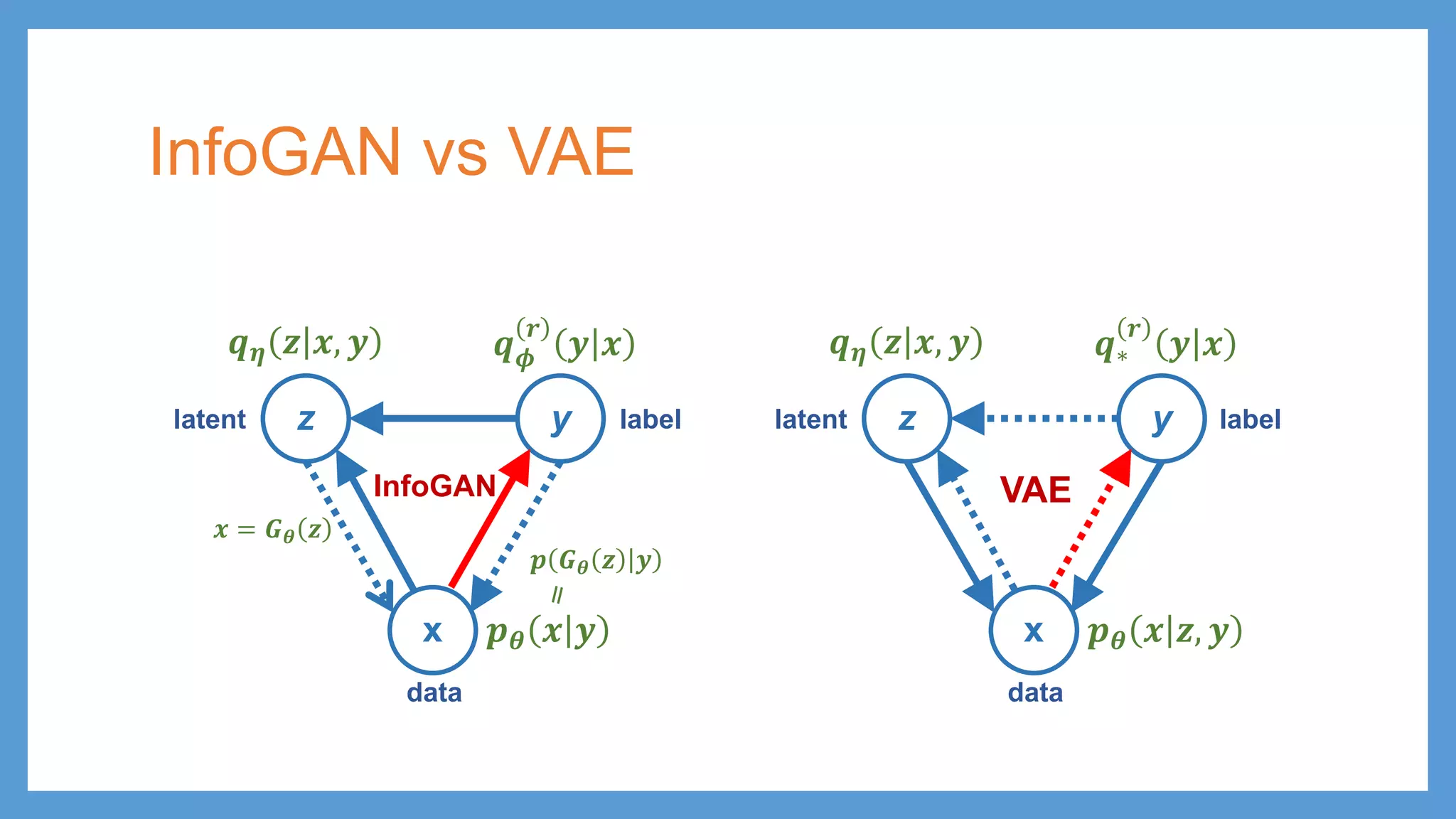
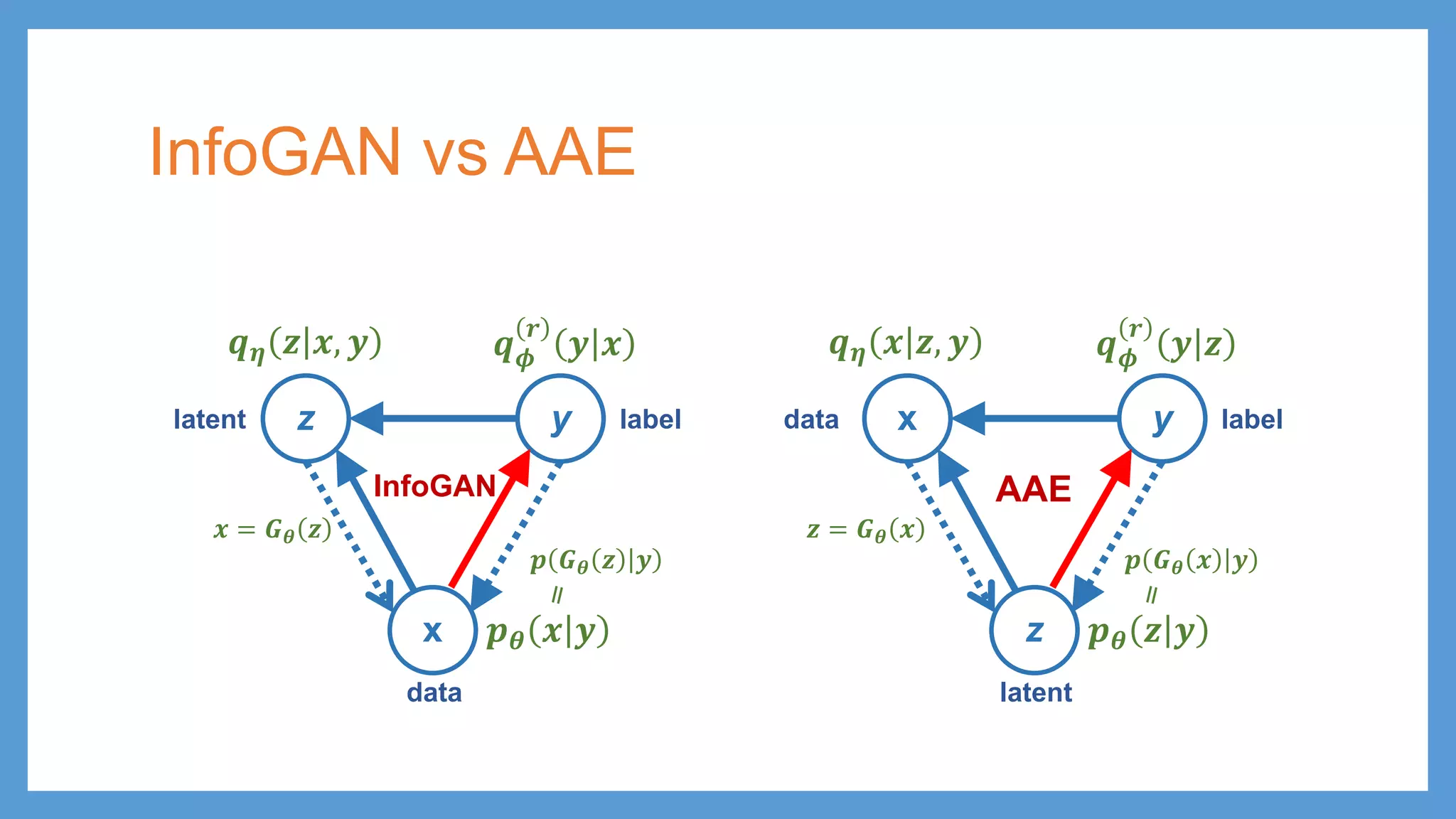
This document provides an overview of several deep generative models including autoencoders (AE), variational autoencoders (VAE), generative adversarial networks (GAN), adversarial autoencoders (AAE), VAE/GAN hybrid models, and adversarial domain adaptation (ADA). It describes the key objectives and training procedures of each model, such as minimizing reconstruction loss in AEs, matching the encoded latent distribution to a prior in VAEs, and making generated samples indistinguishable from real data for the discriminator in GANs. Graphical representations are also shown to illustrate how these models relate latent and observed variables.







































![Digital Signal Processor ( DSP ) [French]](https://cdn.slidesharecdn.com/ss_thumbnails/lesdsp-121002052639-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)














































