Download as PDF, PPTX


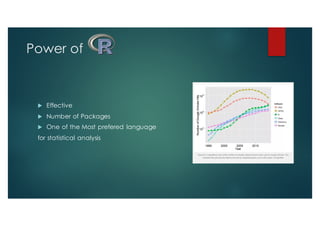
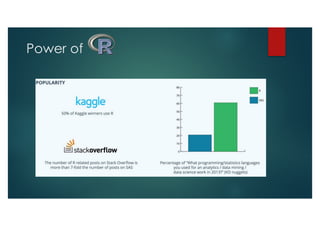










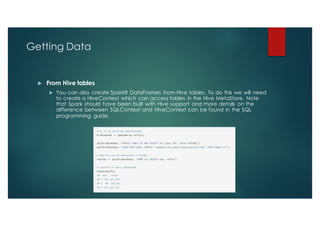
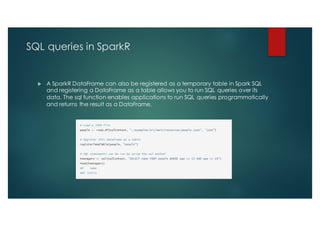




SparkR is an R package that provides an interface to Apache Spark to enable large scale data analysis from R. It introduces the concept of distributed data frames that allow users to manipulate large datasets using familiar R syntax. SparkR improves performance over large datasets by using lazy evaluation and Spark's relational query optimizer. It also supports over 100 functions on data frames for tasks like statistical analysis, string manipulation, and date operations.
























































![제 23회 보아즈(BOAZ) 빅데이터 컨퍼런스 - [MBOAX] : ABSA를 활용한 소비자 반응 분석 기반 운영 효율화 대시보드 설계](https://cdn.slidesharecdn.com/ss_thumbnails/3-1boaz23rdconferencemboax-260203102709-9d519923-thumbnail.jpg?width=640&height=640&fit=bounds)










