Learning Spark Lightningfast Data Analytics 2nd Edition Jules S Damji
Learning Spark Lightningfast Data Analytics 2nd Edition Jules S Damji
Learning Spark Lightningfast Data Analytics 2nd Edition Jules S Damji
Learning Spark Lightningfast Data Analytics 2nd Edition Jules S Damji
Learning Spark Lightningfast Data Analytics 2nd Edition Jules S Damji
1.
Learning Spark LightningfastData Analytics 2nd
Edition Jules S Damji download
https://ebookbell.com/product/learning-spark-lightningfast-data-
analytics-2nd-edition-jules-s-damji-11185516
Explore and download more ebooks at ebookbell.com
2.
Here are somerecommended products that we believe you will be
interested in. You can click the link to download.
Learning Spark Hamstra Markzaharia Matei
https://ebookbell.com/product/learning-spark-hamstra-markzaharia-
matei-22092182
Learning Spark Sql Aurobindo Sarkar
https://ebookbell.com/product/learning-spark-sql-aurobindo-
sarkar-6723986
Learning Spark Sql Aurobindo Sarkar Sarkar Aurobindo
https://ebookbell.com/product/learning-spark-sql-aurobindo-sarkar-
sarkar-aurobindo-23136636
Learning Spark Holden Karau Andy Konwinski Patrick Wendell And Matei
Zaharia
https://ebookbell.com/product/learning-spark-holden-karau-andy-
konwinski-patrick-wendell-and-matei-zaharia-47981086
3.
Learning Apache Spark2 Muhammad Asif Abbasi
https://ebookbell.com/product/learning-apache-spark-2-muhammad-asif-
abbasi-11251962
Spark Learning 3 Keys To Embracing The Power Of Student Curiosity Dr
Ramsey Musallam
https://ebookbell.com/product/spark-learning-3-keys-to-embracing-the-
power-of-student-curiosity-dr-ramsey-musallam-51226182
Machine Learning With Spark And Python 2nd Edition Michael Bowles
https://ebookbell.com/product/machine-learning-with-spark-and-
python-2nd-edition-michael-bowles-57017502
Machine Learning With Spark Nick Pentreath
https://ebookbell.com/product/machine-learning-with-spark-nick-
pentreath-5108498
Machine Learning With Spark 2nd Ed Nick Pentreath Manpreet Singh
Ghotra
https://ebookbell.com/product/machine-learning-with-spark-2nd-ed-nick-
pentreath-manpreet-singh-ghotra-10812184
5.
Learning
Spark
Lightning-Fast Data Analytics
JulesS. Damji,
Brooke Wenig,
Tathagata Das
& Denny Lee
Foreword by Matei Zaharia
2
n
d
E
d
i
t
i
o
n
C
o
v
e
r
s
A
p
a
c
h
e
S
p
a
r
k
3
.
0
Compliments of
7.
Praise for LearningSpark,Second Edition
This book offers a structured approach to learning Apache Spark,
covering new developments in the project. It is a great way for Spark developers
to get started with big data.
—Reynold Xin, Databricks Chief Architect and
Cofounder and Apache Spark PMC Member
For data scientists and data engineers looking to learn Apache Spark and how to build
scalable and reliable big data applications, this book is an essential guide!
—Ben Lorica, Databricks Chief Data Scientist,
Past Program Chair O’Reilly Strata Conferences,
Program Chair for Spark + AI Summit
9.
Jules S. Damji,Brooke Wenig,
Tathagata Das, and Denny Lee
Learning Spark
Lightning-Fast Data Analytics
SECOND EDITION
Boston Farnham Sebastopol Tokyo
Beijing Boston Farnham Sebastopol Tokyo
Beijing
Table of Contents
Foreword.. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . xiii
Preface. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . xv
1. Introduction to Apache Spark: A Unified Analytics Engine. . . . . . . . . . . . . . . . . . . . . . . . . . 1
The Genesis of Spark 1
Big Data and Distributed Computing at Google 1
Hadoop at Yahoo! 2
Spark’s Early Years at AMPLab 3
What Is Apache Spark? 4
Speed 4
Ease of Use 5
Modularity 5
Extensibility 5
Unified Analytics 6
Apache Spark Components as a Unified Stack 6
Apache Spark’s Distributed Execution 10
The Developer’s Experience 14
Who Uses Spark, and for What? 14
Community Adoption and Expansion 16
2. Downloading Apache Spark and Getting Started. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 19
Step 1: Downloading Apache Spark 19
Spark’s Directories and Files 21
Step 2: Using the Scala or PySpark Shell 22
Using the Local Machine 23
Step 3: Understanding Spark Application Concepts 25
Spark Application and SparkSession 26
v
12.
Spark Jobs 27
SparkStages 28
Spark Tasks 28
Transformations, Actions, and Lazy Evaluation 28
Narrow and Wide Transformations 30
The Spark UI 31
Your First Standalone Application 34
Counting M&Ms for the Cookie Monster 35
Building Standalone Applications in Scala 40
Summary 42
3. Apache Spark’s Structured APIs. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 43
Spark: What’s Underneath an RDD? 43
Structuring Spark 44
Key Merits and Benefits 45
The DataFrame API 47
Spark’s Basic Data Types 48
Spark’s Structured and Complex Data Types 49
Schemas and Creating DataFrames 50
Columns and Expressions 54
Rows 57
Common DataFrame Operations 58
End-to-End DataFrame Example 68
The Dataset API 69
Typed Objects, Untyped Objects, and Generic Rows 69
Creating Datasets 71
Dataset Operations 72
End-to-End Dataset Example 74
DataFrames Versus Datasets 74
When to Use RDDs 75
Spark SQL and the Underlying Engine 76
The Catalyst Optimizer 77
Summary 82
4. Spark SQL and DataFrames: Introduction to Built-in Data Sources. . . . . . . . . . . . . . . . . 83
Using Spark SQL in Spark Applications 84
Basic Query Examples 85
SQL Tables and Views 89
Managed Versus UnmanagedTables 89
Creating SQL Databases and Tables 90
Creating Views 91
Viewing the Metadata 93
vi | Table of Contents
13.
Caching SQL Tables93
Reading Tables into DataFrames 93
Data Sources for DataFrames and SQL Tables 94
DataFrameReader 94
DataFrameWriter 96
Parquet 97
JSON 100
CSV 102
Avro 104
ORC 106
Images 108
Binary Files 110
Summary 111
5. Spark SQL and DataFrames: Interacting with External Data Sources. . . . . . . . . . . . . . . 113
Spark SQL and Apache Hive 113
User-Defined Functions 114
Querying with the Spark SQL Shell, Beeline, and Tableau 119
Using the Spark SQL Shell 119
Working with Beeline 120
Working with Tableau 122
External Data Sources 129
JDBC and SQL Databases 129
PostgreSQL 132
MySQL 133
Azure Cosmos DB 134
MS SQL Server 136
Other External Sources 137
Higher-Order Functions in DataFrames and Spark SQL 138
Option 1: Explode and Collect 138
Option 2: User-Defined Function 138
Built-in Functions for Complex Data Types 139
Higher-Order Functions 141
Common DataFrames and Spark SQL Operations 144
Unions 147
Joins 148
Windowing 149
Modifications 151
Summary 155
6. Spark SQL and Datasets. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 157
Single API for Java and Scala 157
Table of Contents | vii
14.
Scala Case Classesand JavaBeans for Datasets 158
Working with Datasets 160
Creating Sample Data 160
Transforming Sample Data 162
Memory Management for Datasets and DataFrames 167
Dataset Encoders 168
Spark’s Internal Format Versus Java Object Format 168
Serialization and Deserialization (SerDe) 169
Costs of Using Datasets 170
Strategies to Mitigate Costs 170
Summary 172
7. Optimizing and Tuning Spark Applications. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 173
Optimizing and Tuning Spark for Efficiency 173
Viewing and Setting Apache Spark Configurations 173
Scaling Spark for Large Workloads 177
Caching and Persistence of Data 183
DataFrame.cache() 183
DataFrame.persist() 184
When to Cache and Persist 187
When Not to Cache and Persist 187
A Family of Spark Joins 187
Broadcast Hash Join 188
Shuffle Sort Merge Join 189
Inspecting the Spark UI 197
Journey Through the Spark UI Tabs 197
Summary 205
8. Structured Streaming. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 207
Evolution of the Apache Spark Stream Processing Engine 207
The Advent of Micro-Batch Stream Processing 208
Lessons Learned from Spark Streaming (DStreams) 209
The Philosophy of Structured Streaming 210
The Programming Model of Structured Streaming 211
The Fundamentals of a Structured Streaming Query 213
Five Steps to Define a Streaming Query 213
Under the Hood of an Active Streaming Query 219
Recovering from Failures with Exactly-Once Guarantees 221
Monitoring an Active Query 223
Streaming Data Sources and Sinks 226
Files 226
Apache Kafka 228
viii | Table of Contents
15.
Custom Streaming Sourcesand Sinks 230
Data Transformations 234
Incremental Execution and Streaming State 234
Stateless Transformations 235
Stateful Transformations 235
Stateful Streaming Aggregations 238
Aggregations Not Based on Time 238
Aggregations with Event-Time Windows 239
Streaming Joins 246
Stream–Static Joins 246
Stream–Stream Joins 248
Arbitrary Stateful Computations 253
Modeling Arbitrary Stateful Operations with mapGroupsWithState() 254
Using Timeouts to Manage Inactive Groups 257
Generalization with flatMapGroupsWithState() 261
Performance Tuning 262
Summary 264
9. Building Reliable Data Lakes with Apache Spark. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 265
The Importance of an Optimal Storage Solution 265
Databases 266
A Brief Introduction to Databases 266
Reading from and Writing to Databases Using Apache Spark 267
Limitations of Databases 267
Data Lakes 268
A Brief Introduction to Data Lakes 268
Reading from and Writing to Data Lakes using Apache Spark 269
Limitations of Data Lakes 270
Lakehouses: The Next Step in the Evolution of Storage Solutions 271
Apache Hudi 272
Apache Iceberg 272
Delta Lake 273
Building Lakehouses with Apache Spark and Delta Lake 274
Configuring Apache Spark with Delta Lake 274
Loading Data into a Delta Lake Table 275
Loading Data Streams into a Delta Lake Table 277
Enforcing Schema on Write to Prevent Data Corruption 278
Evolving Schemas to Accommodate Changing Data 279
Transforming Existing Data 279
Auditing Data Changes with Operation History 282
Querying Previous Snapshots of a Table with Time Travel 283
Summary 284
Table of Contents | ix
16.
10. Machine Learningwith MLlib. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 285
What Is Machine Learning? 286
Supervised Learning 286
Unsupervised Learning 288
Why Spark for Machine Learning? 289
Designing Machine Learning Pipelines 289
Data Ingestion and Exploration 290
Creating Training and Test Data Sets 291
Preparing Features with Transformers 293
Understanding Linear Regression 294
Using Estimators to Build Models 295
Creating a Pipeline 296
Evaluating Models 302
Saving and Loading Models 306
Hyperparameter Tuning 307
Tree-Based Models 307
k-Fold Cross-Validation 316
Optimizing Pipelines 320
Summary 321
11. Managing, Deploying, and Scaling Machine Learning Pipelines with Apache Spark. . 323
Model Management 323
MLflow 324
Model Deployment Options with MLlib 330
Batch 332
Streaming 333
Model Export Patterns for Real-Time Inference 334
Leveraging Spark for Non-MLlib Models 336
Pandas UDFs 336
Spark for Distributed Hyperparameter Tuning 337
Summary 341
12. Epilogue: Apache Spark 3.0. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 343
Spark Core and Spark SQL 343
Dynamic Partition Pruning 343
Adaptive Query Execution 345
SQL Join Hints 348
Catalog Plugin API and DataSourceV2 349
Accelerator-Aware Scheduler 351
Structured Streaming 352
PySpark, Pandas UDFs, and Pandas Function APIs 354
Redesigned Pandas UDFs with Python Type Hints 354
x | Table of Contents
Foreword
Apache Spark hasevolved significantly since I first started the project at UC Berkeley
in 2009. After moving to the Apache Software Foundation, the open source project
has had over 1,400 contributors from hundreds of companies, and the global Spark
meetup group has grown to over half a million members. Spark’s user base has also
become highly diverse, encompassing Python, R, SQL, and JVM developers, with use
cases ranging from data science to business intelligence to data engineering. I have
been working closely with the Apache Spark community to help continue its develop‐
ment, and I am thrilled to see the progress thus far.
The release of Spark 3.0 marks an important milestone for the project and has
sparked the need for updated learning material. The idea of a second edition of
Learning Spark has come up many times—and it was overdue. Even though I coau‐
thored both Learning Spark and Spark: The Definitive Guide (both O’Reilly), it was
time for me to let the next generation of Spark contributors pick up the narrative. I’m
delighted that four experienced practitioners and developers, who have been working
closely with Apache Spark from its early days, have teamed up to write this second
edition of the book, incorporating the most recent APIs and best practices for Spark
developers in a clear and informative guide.
The authors’ approach to this edition is highly conducive to hands-on learning. The
key concepts in Spark and distributed big data processing have been distilled into
easy-to-follow chapters. Through the book’s illustrative code examples, developers
can build confidence using Spark and gain a greater understanding of its Structured
APIs and how to leverage them. I hope that this second edition of Learning Spark will
guide you on your large-scale data processing journey, whatever problems you wish
to tackle using Spark.
— Matei Zaharia, Chief Technologist,
Cofounder of Databricks, Asst. Professor at Stanford,
and original creator of Apache Spark
xiii
21.
Preface
We welcome youto the second edition of Learning Spark. It’s been five years since the
first edition was published in 2015, originally authored by Holden Karau, Andy Kon‐
winski, Patrick Wendell, and Matei Zaharia. This new edition has been updated to
reflect Apache Spark’s evolution through Spark 2.x and Spark 3.0, including its
expanded ecosystem of built-in and external data sources, machine learning, and
streaming technologies with which Spark is tightly integrated.
Over the years since its first 1.x release, Spark has become the de facto big data uni‐
fied processing engine. Along the way, it has extended its scope to include support for
various analytic workloads. Our intent is to capture and curate this evolution for
readers, showing not only how you can use Spark but how it fits into the new era of
big data and machine learning. Hence, we have designed each chapter to build pro‐
gressively on the foundations laid by the previous chapters, ensuring that the content
is suited for our intended audience.
Who This Book Is For
Most developers who grapple with big data are data engineers, data scientists, or
machine learning engineers. This book is aimed at those professionals who are look‐
ing to use Spark to scale their applications to handle massive amounts of data.
In particular, data engineers will learn how to use Spark’s Structured APIs to perform
complex data exploration and analysis on both batch and streaming data; use Spark
SQL for interactive queries; use Spark’s built-in and external data sources to read,
refine, and write data in different file formats as part of their extract, transform, and
load (ETL) tasks; and build reliable data lakes with Spark and the open source Delta
Lake table format.
For data scientists and machine learning engineers, Spark’s MLlib library offers many
common algorithms to build distributed machine learning models. We will cover
how to build pipelines with MLlib, best practices for distributed machine learning,
xv
22.
how to useSpark to scale single-node models, and how to manage and deploy these
models using the open source library MLflow.
While the book is focused on learning Spark as an analytical engine for diverse work‐
loads, we will not cover all of the languages that Spark supports. Most of the examples
in the chapters are written in Scala, Python, and SQL. Where necessary, we have
infused a bit of Java. For those interested in learning Spark with R, we recommend
Javier Luraschi, Kevin Kuo, and Edgar Ruiz’s Mastering Spark with R (O’Reilly).
Finally, because Spark is a distributed engine, building an understanding of Spark
application concepts is critical. We will guide you through how your Spark applica‐
tion interacts with Spark’s distributed components and how execution is decomposed
into parallel tasks on a cluster. We will also cover which deployment modes are sup‐
ported and in what environments.
While there are many topics we have chosen to cover, there are a few that we have
opted to not focus on. These include the older low-level Resilient Distributed Dataset
(RDD) APIs and GraphX, Spark’s API for graphs and graph-parallel computation.
Nor have we covered advanced topics such as how to extend Spark’s Catalyst opti‐
mizer to implement your own operations, how to implement your own catalog, or
how to write your own DataSource V2 data sinks and sources. Though part of Spark,
these are beyond the scope of your first book on learning Spark.
Instead, we have focused and organized the book around Spark’s Structured APIs,
across all its components, and how you can use Spark to process structured data at
scale to perform your data engineering or data science tasks.
How the Book Is Organized
We organized the book in a way that leads you from chapter to chapter by introduc‐
ing concepts, demonstrating these concepts via example code snippets, and providing
full code examples or notebooks in the book’s GitHub repo.
Chapter 1, Introduction to Apache Spark: A Unified Analytics Engine
Introduces you to the evolution of big data and provides a high-level overview of
Apache Spark and its application to big data.
Chapter 2, Downloading Apache Spark and Getting Started
Walks you through downloading and setting up Apache Spark on your local
machine.
Chapter 3, Apache Spark’s Structured APIs through Chapter 6, Spark SQL and Datasets
These chapters focus on using the DataFrame and Dataset Structured APIs to
ingest data from built-in and external data sources, apply built-in and custom
functions, and utilize Spark SQL. These chapters comprise the foundation for
later chapters, incorporating all the latest Spark 3.0 changes where appropriate.
xvi | Preface
23.
Chapter 7, Optimizingand Tuning Spark Applications
Provides you with best practices for tuning, optimizing, debugging, and inspect‐
ing your Spark applications through the Spark UI, as well as details on the con‐
figurations you can tune to increase performance.
Chapter 8, Structured Streaming
Guides you through the evolution of the Spark Streaming engine and the Struc‐
tured Streaming programming model. It examines the anatomy of a typical
streaming query and discusses the different ways to transform streaming data—
stateful aggregations, stream joins, and arbitrary stateful aggregation—while pro‐
viding guidance on how to design performant streaming queries.
Chapter 9, Building Reliable Data Lakes with Apache Spark
Surveys three open source table format storage solutions, as part of the Spark
ecosystem, that employ Apache Spark to build reliable data lakes with transac‐
tional guarantees. Due to Delta Lake’s tight integration with Spark for both batch
and streaming workloads, we focus on that solution and explore how it facilitates
a new paradigm in data management, the lakehouse.
Chapter 10, Machine Learning with MLlib
Introduces MLlib, the distributed machine learning library for Spark, and walks
you through an end-to-end example of how to build a machine learning pipeline,
including topics such as feature engineering, hyperparameter tuning, evaluation
metrics, and saving and loading models.
Chapter 11, Managing, Deploying, and Scaling Machine Learning Pipelines with Apache
Spark
Covers how to track and manage your MLlib models with MLflow, compares and
contrasts different model deployment options, and explores how to leverage
Spark for non-MLlib models for distributed model inference, feature engineer‐
ing, and/or hyperparameter tuning.
Chapter 12, Epilogue: Apache Spark 3.0
The epilogue highlights notable features and changes in Spark 3.0. While the full
range of enhancements and features is too extensive to fit in a single chapter, we
highlight the major changes you should be aware of and recommend you check
the release notes when Spark 3.0 is officially released.
Throughout these chapters, we have incorporated or noted Spark 3.0 features where
needed and tested all the code examples and notebooks against Spark 3.0.0-preview2.
Preface | xvii
24.
How to Usethe Code Examples
The code examples in the book range from brief snippets to complete Spark applica‐
tions and end-to-end notebooks, in Scala, Python, SQL, and, where necessary, Java.
While some short code snippets in a chapter are self-contained and can be copied and
pasted to run in a Spark shell (pyspark or spark-shell), others are fragments from
standalone Spark applications or end-to-end notebooks. To run standalone Spark
applications in Scala, Python, or Java, read the instructions in the respective chapter’s
README files in this book’s GitHub repo.
As for the notebooks, to run these you will need to register for a free Databricks
Community Edition account. We detail how to import the notebooks and create a
cluster using Spark 3.0 in the README.
Software and Configuration Used
Most of the code in this book and the accompanying notebooks were written in and
tested against Apache Spark 3.0.0-preview2, which was available to us at the time we
were writing the final chapters.
By the time this book is published, Apache Spark 3.0 will have been released and be
available to the community for general use. We recommend that you download and
use the official release with the following configurations for your operating system:
• Apache Spark 3.0 (prebuilt for Apache Hadoop 2.7)
• Java Development Kit (JDK) 1.8.0
If you intend to use only Python, then you can simply run pip install pyspark.
Conventions Used in This Book
The following typographical conventions are used in this book:
Italic
Indicates new terms, URLs, email addresses, filenames, and file extensions.
Constant width
Used for program listings, as well as within paragraphs to refer to program ele‐
ments such as variable or function names, databases, data types, environment
variables, statements, and keywords.
Constant width bold
Shows commands or other text that should be typed literally by the user.
xviii | Preface
25.
Constant width italic
Showstext that should be replaced with user-supplied values or by values deter‐
mined by context.
This element signifies a general note.
Using Code Examples
If you have a technical question or a problem using the code examples, please send an
email to bookquestions@oreilly.com.
This book is here to help you get your job done. In general, if example code is offered
with this book, you may use it in your programs and documentation. You do not
need to contact us for permission unless you’re reproducing a significant portion of
the code. For example, writing a program that uses several chunks of code from this
book does not require permission. Selling or distributing examples from O’Reilly
books does require permission. Answering a question by citing this book and quoting
example code does not require permission. Incorporating a significant amount of
example code from this book into your product’s documentation does require
permission.
We appreciate, but generally do not require, attribution. An attribution usually
includes the title, author, publisher, and ISBN. For example: “Learning Spark, 2nd
Edition, by Jules S. Damji, Brooke Wenig, Tathagata Das, and Denny Lee. Copyright
2020 Databricks, Inc., 978-1-492-05004-9.”
If you feel your use of code examples falls outside fair use or the permission given
above, feel free to contact us at permissions@oreilly.com.
O’Reilly Online Learning
For more than 40 years, O’Reilly Media has provided technol‐
ogy and business training, knowledge, and insight to help
companies succeed.
Our unique network of experts and innovators share their knowledge and expertise
through books, articles, and our online learning platform. O’Reilly’s online learning
platform gives you on-demand access to live training courses, in-depth learning
paths, interactive coding environments, and a vast collection of text and video from
O’Reilly and 200+ other publishers. For more information, visit http://oreilly.com.
Preface | xix
26.
How to ContactUs
Please address comments and questions concerning this book to the publisher:
O’Reilly Media, Inc.
1005 Gravenstein Highway North
Sebastopol, CA 95472
800-998-9938 (in the United States or Canada)
707-829-0515 (international or local)
707-829-0104 (fax)
Visit our web page for this book, where we list errata, examples, and any additional
information, at https://oreil.ly/LearningSpark2.
Email bookquestions@oreilly.com to comment or ask technical questions about this
book.
For news and information about our books and courses, visit http://oreilly.com.
Find us on Facebook: http://facebook.com/oreilly
Follow us on Twitter: http://twitter.com/oreillymedia
Watch us on YouTube: http://www.youtube.com/oreillymedia
Acknowledgments
This project was truly a team effort involving many people, and without their support
and feedback we would not have been able to finish this book, especially in today’s
unprecedented COVID-19 times.
First and foremost, we want to thank our employer, Databricks, for supporting us and
allocating us dedicated time as part of our jobs to finish this book. In particular, we
want to thank Matei Zaharia, Reynold Xin, Ali Ghodsi, Ryan Boyd, and Rick Schultz
for encouraging us to write the second edition.
Second, we would like to thank our technical reviewers: Adam Breindel, Amir Issaei,
Jacek Laskowski, Sean Owen, and Vishwanath Subramanian. Their diligent and con‐
structive feedback, informed by their technical expertise in the community and
industry point of view, made this book what it is: a valuable resource to learn Spark.
Besides the formal book reviewers, we received invaluable feedback from others
knowledgeable about specific topics and sections of the chapters, and we want to
acknowledge their contributions. Many thanks to: Conor Murphy, Hyukjin Kwon,
Maryann Xue, Niall Turbitt, Wenchen Fan, Xiao Li, and Yuanjian Li.
xx | Preface
27.
Finally, we wouldlike to thank our colleagues at Databricks (for their tolerance of us
missing or neglecting project deadlines), our families and loved ones (for their
patience and empathy as we wrote in the early light of day or late into the night on
weekdays and weekends), and the entire open source Spark community. Without
their continued contributions, Spark would not be where it is today—and we authors
would not have had much to write about.
Thank you all!
Preface | xxi
29.
CHAPTER 1
Introduction toApache Spark:
A Unified Analytics Engine
This chapter lays out the origins of Apache Spark and its underlying philosophy. It
also surveys the main components of the project and its distributed architecture. If
you are familiar with Spark’s history and the high-level concepts, you can skip this
chapter.
The Genesis of Spark
In this section, we’ll chart the course of Apache Spark’s short evolution: its genesis,
inspiration, and adoption in the community as a de facto big data unified processing
engine.
Big Data and Distributed Computing at Google
When we think of scale, we can’t help but think of the ability of Google’s search
engine to index and search the world’s data on the internet at lightning speed. The
name Google is synonymous with scale. In fact, Google is a deliberate misspelling of
the mathematical term googol: that’s 1 plus 100 zeros!
Neither traditional storage systems such as relational database management systems
(RDBMSs) nor imperative ways of programming were able to handle the scale at
which Google wanted to build and search the internet’s indexed documents. The
resulting need for new approaches led to the creation of the Google File System (GFS),
MapReduce (MR), and Bigtable.
While GFS provided a fault-tolerant and distributed filesystem across many com‐
modity hardware servers in a cluster farm, Bigtable offered scalable storage of
structured data across GFS. MR introduced a new parallel programming paradigm,
1
30.
based on functionalprogramming, for large-scale processing of data distributed over
GFS and Bigtable.
In essence, your MR applications interact with the MapReduce system that sends
computation code (map and reduce functions) to where the data resides, favoring
data locality and cluster rack affinity rather than bringing data to your application.
The workers in the cluster aggregate and reduce the intermediate computations and
produce a final appended output from the reduce function, which is then written to a
distributed storage where it is accessible to your application. This approach signifi‐
cantly reduces network traffic and keeps most of the input/output (I/O) local to disk
rather than distributing it over the network.
Most of the work Google did was proprietary, but the ideas expressed in the afore‐
mentioned three papers spurred innovative ideas elsewhere in the open source com‐
munity—especially at Yahoo!, which was dealing with similar big data challenges of
scale for its search engine.
Hadoop at Yahoo!
The computational challenges and solutions expressed in Google’s GFS paper pro‐
vided a blueprint for the Hadoop File System (HDFS), including the MapReduce
implementation as a framework for distributed computing. Donated to the Apache
Software Foundation (ASF), a vendor-neutral non-profit organization, in April 2006,
it became part of the Apache Hadoop framework of related modules: Hadoop Com‐
mon, MapReduce, HDFS, and Apache Hadoop YARN.
Although Apache Hadoop had garnered widespread adoption outside Yahoo!, inspir‐
ing a large open source community of contributors and two open source–based com‐
mercial companies (Cloudera and Hortonworks, now merged), the MapReduce
framework on HDFS had a few shortcomings.
First, it was hard to manage and administer, with cumbersome operational complex‐
ity. Second, its general batch-processing MapReduce API was verbose and required a
lot of boilerplate setup code, with brittle fault tolerance. Third, with large batches of
data jobs with many pairs of MR tasks, each pair’s intermediate computed result is
written to the local disk for the subsequent stage of its operation (see Figure 1-1).
This repeated performance of disk I/O took its toll: large MR jobs could run for hours
on end, or even days.
2 | Chapter 1: Introduction to Apache Spark: A Unified Analytics Engine
31.
Figure 1-1. Intermittentiteration of reads and writes between map and reduce
computations
And finally, even though Hadoop MR was conducive to large-scale jobs for general
batch processing, it fell short for combining other workloads such as machine learn‐
ing, streaming, or interactive SQL-like queries.
To handle these new workloads, engineers developed bespoke systems (Apache Hive,
Apache Storm, Apache Impala, Apache Giraph, Apache Drill, Apache Mahout, etc.),
each with their own APIs and cluster configurations, further adding to the opera‐
tional complexity of Hadoop and the steep learning curve for developers.
The question then became (bearing in mind Alan Kay’s adage, “Simple things should
be simple, complex things should be possible”), was there a way to make Hadoop and
MR simpler and faster?
Spark’s Early Years at AMPLab
Researchers at UC Berkeley who had previously worked on Hadoop MapReduce took
on this challenge with a project they called Spark. They acknowledged that MR was
inefficient (or intractable) for interactive or iterative computing jobs and a complex
framework to learn, so from the onset they embraced the idea of making Spark sim‐
pler, faster, and easier. This endeavor started in 2009 at the RAD Lab, which later
became the AMPLab (and now is known as the RISELab).
Early papers published on Spark demonstrated that it was 10 to 20 times faster than
Hadoop MapReduce for certain jobs. Today, it’s many orders of magnitude faster. The
central thrust of the Spark project was to bring in ideas borrowed from Hadoop Map‐
Reduce, but to enhance the system: make it highly fault tolerant and embarrassingly
parallel, support in-memory storage for intermediate results between iterative and
interactive map and reduce computations, offer easy and composable APIs in multi‐
ple languages as a programming model, and support other workloads in a unified
manner. We’ll come back to this idea of unification shortly, as it’s an important theme
in Spark.
By 2013 Spark had gained widespread use, and some of its original creators and
researchers—Matei Zaharia, Ali Ghodsi, Reynold Xin, Patrick Wendell, Ion Stoica,
and Andy Konwinski—donated the Spark project to the ASF and formed a company
called Databricks.
The Genesis of Spark | 3
32.
Databricks and thecommunity of open source developers worked to release Apache
Spark 1.0 in May 2014, under the governance of the ASF. This first major release
established the momentum for frequent future releases and contributions of notable
features to Apache Spark from Databricks and over 100 commercial vendors.
What Is Apache Spark?
Apache Spark is a unified engine designed for large-scale distributed data processing,
on premises in data centers or in the cloud.
Spark provides in-memory storage for intermediate computations, making it much
faster than Hadoop MapReduce. It incorporates libraries with composable APIs for
machine learning (MLlib), SQL for interactive queries (Spark SQL), stream process‐
ing (Structured Streaming) for interacting with real-time data, and graph processing
(GraphX).
Spark’s design philosophy centers around four key characteristics:
• Speed
• Ease of use
• Modularity
• Extensibility
Let’s take a look at what this means for the framework.
Speed
Spark has pursued the goal of speed in several ways. First, its internal implementation
benefits immensely from the hardware industry’s recent huge strides in improving
the price and performance of CPUs and memory. Today’s commodity servers come
cheap, with hundreds of gigabytes of memory, multiple cores, and the underlying
Unix-based operating system taking advantage of efficient multithreading and paral‐
lel processing. The framework is optimized to take advantage of all of these factors.
Second, Spark builds its query computations as a directed acyclic graph (DAG); its
DAG scheduler and query optimizer construct an efficient computational graph that
can usually be decomposed into tasks that are executed in parallel across workers on
the cluster. And third, its physical execution engine, Tungsten, uses whole-stage code
generation to generate compact code for execution (we will cover SQL optimization
and whole-stage code generation in Chapter 3).
With all the intermediate results retained in memory and its limited disk I/O, this
gives it a huge performance boost.
4 | Chapter 1: Introduction to Apache Spark: A Unified Analytics Engine
33.
Ease of Use
Sparkachieves simplicity by providing a fundamental abstraction of a simple logical
data structure called a Resilient Distributed Dataset (RDD) upon which all other
higher-level structured data abstractions, such as DataFrames and Datasets, are con‐
structed. By providing a set of transformations and actions as operations, Spark offers
a simple programming model that you can use to build big data applications in famil‐
iar languages.
Modularity
Spark operations can be applied across many types of workloads and expressed in any
of the supported programming languages: Scala, Java, Python, SQL, and R. Spark
offers unified libraries with well-documented APIs that include the following mod‐
ules as core components: Spark SQL, Spark Structured Streaming, Spark MLlib, and
GraphX, combining all the workloads running under one engine. We’ll take a closer
look at all of these in the next section.
You can write a single Spark application that can do it all—no need for distinct
engines for disparate workloads, no need to learn separate APIs. With Spark, you get
a unified processing engine for your workloads.
Extensibility
Spark focuses on its fast, parallel computation engine rather than on storage. Unlike
Apache Hadoop, which included both storage and compute, Spark decouples the two.
That means you can use Spark to read data stored in myriad sources—Apache
Hadoop, Apache Cassandra, Apache HBase, MongoDB, Apache Hive, RDBMSs, and
more—and process it all in memory. Spark’s DataFrameReaders and DataFrame
Writers can also be extended to read data from other sources, such as Apache Kafka,
Kinesis, Azure Storage, and Amazon S3, into its logical data abstraction, on which it
can operate.
The community of Spark developers maintains a list of third-party Spark packages as
part of the growing ecosystem (see Figure 1-2). This rich ecosystem of packages
includes Spark connectors for a variety of external data sources, performance moni‐
tors, and more.
What Is Apache Spark? | 5
34.
Figure 1-2. ApacheSpark’s ecosystem of connectors
Unified Analytics
While the notion of unification is not unique to Spark, it is a core component of its
design philosophy and evolution. In November 2016, the Association for Computing
Machinery (ACM) recognized Apache Spark and conferred upon its original creators
the prestigious ACM Award for their paper describing Apache Spark as a “Unified
Engine for Big Data Processing.” The award-winning paper notes that Spark replaces
all the separate batch processing, graph, stream, and query engines like Storm,
Impala, Dremel, Pregel, etc. with a unified stack of components that addresses diverse
workloads under a single distributed fast engine.
Apache Spark Components as a Unified Stack
As shown in Figure 1-3, Spark offers four distinct components as libraries for diverse
workloads: Spark SQL, Spark MLlib, Spark Structured Streaming, and GraphX. Each
of these components is separate from Spark’s core fault-tolerant engine, in that you
use APIs to write your Spark application and Spark converts this into a DAG that is
executed by the core engine. So whether you write your Spark code using the pro‐
vided Structured APIs (which we will cover in Chapter 3) in Java, R, Scala, SQL, or
6 | Chapter 1: Introduction to Apache Spark: A Unified Analytics Engine
35.
Python, the underlyingcode is decomposed into highly compact bytecode that is exe‐
cuted in the workers’ JVMs across the cluster.
Figure 1-3. Apache Spark components and API stack
Let’s look at each of these components in more detail.
Spark SQL
This module works well with structured data. You can read data stored in an RDBMS
table or from file formats with structured data (CSV, text, JSON, Avro, ORC, Parquet,
etc.) and then construct permanent or temporary tables in Spark. Also, when using
Spark’s Structured APIs in Java, Python, Scala, or R, you can combine SQL-like quer‐
ies to query the data just read into a Spark DataFrame. To date, Spark SQL is ANSI
SQL:2003-compliant and it also functions as a pure SQL engine.
For example, in this Scala code snippet, you can read from a JSON file stored on
Amazon S3, create a temporary table, and issue a SQL-like query on the results read
into memory as a Spark DataFrame:
// In Scala
// Read data off Amazon S3 bucket into a Spark DataFrame
spark.read.json("s3://apache_spark/data/committers.json")
.createOrReplaceTempView("committers")
// Issue a SQL query and return the result as a Spark DataFrame
val results = spark.sql("""SELECT name, org, module, release, num_commits
FROM committers WHERE module = 'mllib' AND num_commits > 10
ORDER BY num_commits DESC""")
You can write similar code snippets in Python, R, or Java, and the generated bytecode
will be identical, resulting in the same performance.
Spark MLlib
Spark comes with a library containing common machine learning (ML) algorithms
called MLlib. Since Spark’s first release, the performance of this library component
has improved significantly because of Spark 2.x’s underlying engine enhancements.
Unified Analytics | 7
36.
MLlib provides manypopular machine learning algorithms built atop high-level
DataFrame-based APIs to build models.
Starting with Apache Spark 1.6, the MLlib project is split between
two packages: spark.mllib and spark.ml. The DataFrame-based
API is the latter while the former contains the RDD-based APIs,
which are now in maintenance mode. All new features go into
spark.ml. This book refers to “MLlib” as the umbrella library for
machine learning in Apache Spark.
These APIs allow you to extract or transform features, build pipelines (for training
and evaluating), and persist models (for saving and reloading them) during deploy‐
ment. Additional utilities include the use of common linear algebra operations and
statistics. MLlib includes other low-level ML primitives, including a generic gradient
descent optimization. The following Python code snippet encapsulates the basic oper‐
ations a data scientist may do when building a model (more extensive examples will
be discussed in Chapters 10 and 11):
# In Python
from pyspark.ml.classification import LogisticRegression
...
training = spark.read.csv("s3://...")
test = spark.read.csv("s3://...")
# Load training data
lr = LogisticRegression(maxIter=10, regParam=0.3, elasticNetParam=0.8)
# Fit the model
lrModel = lr.fit(training)
# Predict
lrModel.transform(test)
...
Spark Structured Streaming
Apache Spark 2.0 introduced an experimental Continuous Streaming model and
Structured Streaming APIs, built atop the Spark SQL engine and DataFrame-based
APIs. By Spark 2.2, Structured Streaming was generally available, meaning that devel‐
opers could use it in their production environments.
Necessary for big data developers to combine and react in real time to both static data
and streaming data from engines like Apache Kafka and other streaming sources, the
new model views a stream as a continually growing table, with new rows of data
appended at the end. Developers can merely treat this as a structured table and issue
queries against it as they would a static table.
8 | Chapter 1: Introduction to Apache Spark: A Unified Analytics Engine
37.
1 Contributed tothe community by Databricks as an open source project, GraphFrames is a general graph pro‐
cessing library that is similar to Apache Spark’s GraphX but uses DataFrame-based APIs.
Underneath the Structured Streaming model, the Spark SQL core engine handles all
aspects of fault tolerance and late-data semantics, allowing developers to focus on
writing streaming applications with relative ease. This new model obviated the old
DStreams model in Spark’s 1.x series, which we will discuss in more detail in Chap‐
ter 8. Furthermore, Spark 2.x and Spark 3.0 extended the range of streaming data
sources to include Apache Kafka, Kinesis, and HDFS-based or cloud storage.
The following code snippet shows the typical anatomy of a Structured Streaming
application. It reads from a localhost socket and writes the word count results to an
Apache Kafka topic:
# In Python
# Read a stream from a local host
from pyspark.sql.functions import explode, split
lines = (spark
.readStream
.format("socket")
.option("host", "localhost")
.option("port", 9999)
.load())
# Perform transformation
# Split the lines into words
words = lines.select(explode(split(lines.value, " ")).alias("word"))
# Generate running word count
word_counts = words.groupBy("word").count()
# Write out to the stream to Kafka
query = (word_counts
.writeStream
.format("kafka")
.option("topic", "output"))
GraphX
As the name suggests, GraphX is a library for manipulating graphs (e.g., social net‐
work graphs, routes and connection points, or network topology graphs) and per‐
forming graph-parallel computations. It offers the standard graph algorithms for
analysis, connections, and traversals, contributed by users in the community: the
available algorithms include PageRank, Connected Components, and Triangle
Counting.1
This code snippet shows a simple example of how to join two graphs using the
GraphX APIs:
Unified Analytics | 9
38.
// In Scala
valgraph = Graph(vertices, edges)
messages = spark.textFile("hdfs://...")
val graph2 = graph.joinVertices(messages) {
(id, vertex, msg) => ...
}
Apache Spark’s Distributed Execution
If you have read this far, you already know that Spark is a distributed data processing
engine with its components working collaboratively on a cluster of machines. Before
we explore programming with Spark in the following chapters of this book, you need
to understand how all the components of Spark’s distributed architecture work
together and communicate, and what deployment modes are available.
Let’s start by looking at each of the individual components shown in Figure 1-4 and
how they fit into the architecture. At a high level in the Spark architecture, a Spark
application consists of a driver program that is responsible for orchestrating parallel
operations on the Spark cluster. The driver accesses the distributed components in
the cluster—the Spark executors and cluster manager—through a SparkSession.
Figure 1-4. Apache Spark components and architecture
Spark driver
As the part of the Spark application responsible for instantiating a SparkSession, the
Spark driver has multiple roles: it communicates with the cluster manager; it requests
resources (CPU, memory, etc.) from the cluster manager for Spark’s executors
(JVMs); and it transforms all the Spark operations into DAG computations, schedules
10 | Chapter 1: Introduction to Apache Spark: A Unified Analytics Engine
39.
them, and distributestheir execution as tasks across the Spark executors. Once the
resources are allocated, it communicates directly with the executors.
SparkSession
In Spark 2.0, the SparkSession became a unified conduit to all Spark operations and
data. Not only did it subsume previous entry points to Spark like the SparkContext,
SQLContext, HiveContext, SparkConf, and StreamingContext, but it also made
working with Spark simpler and easier.
Although in Spark 2.x the SparkSession subsumes all other con‐
texts, you can still access the individual contexts and their respec‐
tive methods. In this way, the community maintained backward
compatibility. That is, your old 1.x code with SparkContext or
SQLContext will still work.
Through this one conduit, you can create JVM runtime parameters, define Data‐
Frames and Datasets, read from data sources, access catalog metadata, and issue
Spark SQL queries. SparkSession provides a single unified entry point to all of
Spark’s functionality.
In a standalone Spark application, you can create a SparkSession using one of the
high-level APIs in the programming language of your choice. In the Spark shell
(more on this in the next chapter) the SparkSession is created for you, and you can
access it via a global variable called spark or sc.
Whereas in Spark 1.x you would have had to create individual contexts (for stream‐
ing, SQL, etc.), introducing extra boilerplate code, in a Spark 2.x application you can
create a SparkSession per JVM and use it to perform a number of Spark operations.
Let’s take a look at an example:
// In Scala
import org.apache.spark.sql.SparkSession
// Build SparkSession
val spark = SparkSession
.builder
.appName("LearnSpark")
.config("spark.sql.shuffle.partitions", 6)
.getOrCreate()
...
// Use the session to read JSON
val people = spark.read.json("...")
...
// Use the session to issue a SQL query
val resultsDF = spark.sql("SELECT city, pop, state, zip FROM table_name")
Unified Analytics | 11
40.
Cluster manager
The clustermanager is responsible for managing and allocating resources for the
cluster of nodes on which your Spark application runs. Currently, Spark supports
four cluster managers: the built-in standalone cluster manager, Apache Hadoop
YARN, Apache Mesos, and Kubernetes.
Spark executor
A Spark executor runs on each worker node in the cluster. The executors communi‐
cate with the driver program and are responsible for executing tasks on the workers.
In most deployments modes, only a single executor runs per node.
Deployment modes
An attractive feature of Spark is its support for myriad deployment modes, enabling
Spark to run in different configurations and environments. Because the cluster man‐
ager is agnostic to where it runs (as long as it can manage Spark’s executors and
fulfill resource requests), Spark can be deployed in some of the most popular envi‐
ronments—such as Apache Hadoop YARN and Kubernetes—and can operate in dif‐
ferent modes. Table 1-1 summarizes the available deployment modes.
Table 1-1. Cheat sheet for Spark deployment modes
Mode Spark driver Spark executor Cluster manager
Local Runs on a single JVM, like a
laptop or single node
Runs on the same JVM as the
driver
Runs on the same host
Standalone Can run on any node in the
cluster
Each node in the cluster will
launch its own executor JVM
Can be allocated arbitrarily to any
host in the cluster
YARN (client) Runs on a client, not part of the
cluster
YARN’s NodeManager’s container YARN’s Resource Manager works
with YARN’s Application Master to
allocate the containers on
NodeManagers for executors
YARN
(cluster)
Runs with the YARN Application
Master
Same as YARN client mode Same as YARN client mode
Kubernetes Runs in a Kubernetes pod Each worker runs within its own
pod
Kubernetes Master
Distributed data and partitions
Actual physical data is distributed across storage as partitions residing in either HDFS
or cloud storage (see Figure 1-5). While the data is distributed as partitions across the
physical cluster, Spark treats each partition as a high-level logical data abstraction—as
a DataFrame in memory. Though this is not always possible, each Spark executor is
preferably allocated a task that requires it to read the partition closest to it in the net‐
work, observing data locality.
12 | Chapter 1: Introduction to Apache Spark: A Unified Analytics Engine
41.
Figure 1-5. Datais distributed across physical machines
Partitioning allows for efficient parallelism. A distributed scheme of breaking up data
into chunks or partitions allows Spark executors to process only data that is close to
them, minimizing network bandwidth. That is, each executor’s core is assigned its
own data partition to work on (see Figure 1-6).
Figure 1-6. Each executor’s core gets a partition of data to work on
For example, this code snippet will break up the physical data stored across clusters
into eight partitions, and each executor will get one or more partitions to read into its
memory:
# In Python
log_df = spark.read.text("path_to_large_text_file").repartition(8)
print(log_df.rdd.getNumPartitions())
And this code will create a DataFrame of 10,000 integers distributed over eight parti‐
tions in memory:
Unified Analytics | 13
42.
# In Python
df= spark.range(0, 10000, 1, 8)
print(df.rdd.getNumPartitions())
Both code snippets will print out 8.
In Chapters 3 and 7, we will discuss how to tune and change partitioning configura‐
tion for maximum parallelism based on how many cores you have on your executors.
The Developer’s Experience
Of all the developers’ delights, none is more attractive than a set of composable APIs
that increase productivity and are easy to use, intuitive, and expressive. One of
Apache Spark’s principal appeals to developers has been its easy-to-use APIs for oper‐
ating on small to large data sets, across languages: Scala, Java, Python, SQL, and R.
One primary motivation behind Spark 2.x was to unify and simplify the framework
by limiting the number of concepts that developers have to grapple with. Spark 2.x
introduced higher-level abstraction APIs as domain-specific language constructs,
which made programming Spark highly expressive and a pleasant developer experi‐
ence. You express what you want the task or operation to compute, not how to com‐
pute it, and let Spark ascertain how best to do it for you. We will cover these
Structured APIs in Chapter 3, but first let’s take a look at who the Spark developers
are.
Who Uses Spark, and for What?
Not surprisingly, most developers who grapple with big data are data engineers, data
scientists, or machine learning engineers. They are drawn to Spark because it allows
them to build a range of applications using a single engine, with familiar program‐
ming languages.
Of course, developers may wear many hats and sometimes do both data science and
data engineering tasks, especially in startup companies or smaller engineering groups.
Among all these tasks, however, data—massive amounts of data—is the foundation.
Data science tasks
As a discipline that has come to prominence in the era of big data, data science is
about using data to tell stories. But before they can narrate the stories, data scientists
have to cleanse the data, explore it to discover patterns, and build models to predict
or suggest outcomes. Some of these tasks require knowledge of statistics, mathemat‐
ics, computer science, and programming.
Most data scientists are proficient in using analytical tools like SQL, comfortable with
libraries like NumPy and pandas, and conversant in programming languages like R
14 | Chapter 1: Introduction to Apache Spark: A Unified Analytics Engine
43.
and Python. Butthey must also know how to wrangle or transform data, and how to
use established classification, regression, or clustering algorithms for building mod‐
els. Often their tasks are iterative, interactive or ad hoc, or experimental to assert their
hypotheses.
Fortunately, Spark supports these different tools. Spark’s MLlib offers a common set
of machine learning algorithms to build model pipelines, using high-level estimators,
transformers, and data featurizers. Spark SQL and the Spark shell facilitate interactive
and ad hoc exploration of data.
Additionally, Spark enables data scientists to tackle large data sets and scale their
model training and evaluation. Apache Spark 2.4 introduced a new gang scheduler, as
part of Project Hydrogen, to accommodate the fault-tolerant needs of training and
scheduling deep learning models in a distributed manner, and Spark 3.0 has intro‐
duced the ability to support GPU resource collection in the standalone, YARN, and
Kubernetes deployment modes. This means developers whose tasks demand deep
learning techniques can use Spark.
Data engineering tasks
After building their models, data scientists often need to work with other team mem‐
bers, who may be responsible for deploying the models. Or they may need to work
closely with others to build and transform raw, dirty data into clean data that is easily
consumable or usable by other data scientists. For example, a classification or cluster‐
ing model does not exist in isolation; it works in conjunction with other components
like a web application or a streaming engine such as Apache Kafka, or as part of a
larger data pipeline. This pipeline is often built by data engineers.
Data engineers have a strong understanding of software engineering principles and
methodologies, and possess skills for building scalable data pipelines for a stated busi‐
ness use case. Data pipelines enable end-to-end transformations of raw data coming
from myriad sources—data is cleansed so that it can be consumed downstream by
developers, stored in the cloud or in NoSQL or RDBMSs for report generation, or
made accessible to data analysts via business intelligence tools.
Spark 2.x introduced an evolutionary streaming model called continuous applications
with Structured Streaming (discussed in detail in Chapter 8). With Structured
Streaming APIs, data engineers can build complex data pipelines that enable them to
ETL data from both real-time and static data sources.
Data engineers use Spark because it provides a simple way to parallelize computations
and hides all the complexity of distribution and fault tolerance. This leaves them free
to focus on using high-level DataFrame-based APIs and domain-specific language
(DSL) queries to do ETL, reading and combining data from multiple sources.
The Developer’s Experience | 15
44.
The performance improvementsin Spark 2.x and Spark 3.0, due to the Catalyst opti‐
mizer for SQL and Tungsten for compact code generation, have made life for data
engineers much easier. They can choose to use any of the three Spark APIs—RDDs,
DataFrames, or Datasets—that suit the task at hand, and reap the benefits of Spark.
Popular Spark use cases
Whether you are a data engineer, data scientist, or machine learning engineer, you’ll
find Spark useful for the following use cases:
• Processing in parallel large data sets distributed across a cluster
• Performing ad hoc or interactive queries to explore and visualize data sets
• Building, training, and evaluating machine learning models using MLlib
• Implementing end-to-end data pipelines from myriad streams of data
• Analyzing graph data sets and social networks
Community Adoption and Expansion
Not surprisingly, Apache Spark struck a chord in the open source community, espe‐
cially among data engineers and data scientists. Its design philosophy and its inclu‐
sion as an Apache Software Foundation project have fostered immense interest
among the developer community.
Today, there are over 600 Apache Spark Meetup groups globally with close to half a
million members. Every week, someone in the world is giving a talk at a meetup or
conference or sharing a blog post on how to use Spark to build data pipelines. The
Spark + AI Summit is the largest conference dedicated to the use of Spark for
machine learning, data engineering, and data science across many verticals.
Since Spark’s first 1.0 release in 2014 there have been many minor and major releases,
with the most recent major release of Spark 3.0 coming in 2020. This book will cover
aspects of Spark 2.x and Spark 3.0. By the time of its publication the community will
have released Spark 3.0, and most of the code in this book has been tested with Spark
3.0-preview2.
Over the course of its releases, Spark has continued to attract contributors from
across the globe and from numerous organizations. Today, Spark has close to 1,500
contributors, well over 100 releases, 21,000 forks, and some 27,000 commits on Git‐
Hub, as Figure 1-7 shows. And we hope that when you finish this book, you will feel
compelled to contribute too.
16 | Chapter 1: Introduction to Apache Spark: A Unified Analytics Engine
45.
Figure 1-7. Thestate of Apache Spark on GitHub (source: https://github.com/apache/
spark)
Now we can turn our attention to the fun of learning—where and how to start using
Spark. In the next chapter, we’ll show you how to get up and running with Spark in
three simple steps.
The Developer’s Experience | 17
47.
CHAPTER 2
Downloading ApacheSpark
and Getting Started
In this chapter, we will get you set up with Spark and walk through three simple steps
you can take to get started writing your first standalone application.
We will use local mode, where all the processing is done on a single machine in a
Spark shell—this is an easy way to learn the framework, providing a quick feedback
loop for iteratively performing Spark operations. Using a Spark shell, you can proto‐
type Spark operations with small data sets before writing a complex Spark applica‐
tion, but for large data sets or real work where you want to reap the benefits of
distributed execution, local mode is not suitable—you’ll want to use the YARN or
Kubernetes deployment modes instead.
While the Spark shell only supports Scala, Python, and R, you can write a Spark
application in any of the supported languages (including Java) and issue queries in
Spark SQL. We do expect you to have some familiarity with the language of your
choice.
Step 1: Downloading Apache Spark
To get started, go to the Spark download page, select “Pre-built for Apache Hadoop
2.7” from the drop-down menu in step 2, and click the “Download Spark” link in step
3 (Figure 2-1).
19
48.
Figure 2-1. TheApache Spark download page
This will download the tarball spark-3.0.0-preview2-bin-hadoop2.7.tgz, which con‐
tains all the Hadoop-related binaries you will need to run Spark in local mode on
your laptop. Alternatively, if you’re going to install it on an existing HDFS or Hadoop
installation, you can select the matching Hadoop version from the drop-down menu.
How to build from source is beyond the scope of this book, but you can read more
about it in the documentation.
At the time this book went to press Apache Spark 3.0 was still in
preview mode, but you can download the latest Spark 3.0 using the
same download method and instructions.
Since the release of Apache Spark 2.2, developers who only care about learning Spark
in Python have the option of installing PySpark from the PyPI repository. If you only
program in Python, you don’t have to install all the other libraries necessary to run
Scala, Java, or R; this makes the binary smaller. To install PySpark from PyPI, just run
pip install pyspark.
There are some extra dependencies that can be installed for SQL, ML, and MLlib, via
pip install pyspark[sql,ml,mllib] (or pip install pyspark[sql] if you only
want the SQL dependencies).
You will need to install Java 8 or above on your machine and set the
JAVA_HOME environment variable. See the documentation for
instructions on how to download and install Java.
20 | Chapter 2: Downloading Apache Spark and Getting Started
49.
If you wantto run R in an interpretive shell mode, you must install R and then run
sparkR. To do distributed computing with R, you can also use the open source project
sparklyr, created by the R community.
Spark’s Directories and Files
We assume that you are running a version of the Linux or macOS operating system
on your laptop or cluster, and all the commands and instructions in this book will be
in that flavor. Once you have finished downloading the tarball, cd to the downloaded
directory, extract the tarball contents with tar -xf spark-3.0.0-preview2-bin-
hadoop2.7.tgz, and cd into that directory and take a look at the contents:
$ cd spark-3.0.0-preview2-bin-hadoop2.7
$ ls
LICENSE R RELEASE conf examples kubernetes python yarn
NOTICE README.md bin data jars licenses sbin
Let’s briefly summarize the intent and purpose of some of these files and directories.
New items were added in Spark 2.x and 3.0, and the contents of some of the existing
files and directories were changed too:
README.md
This file contains new detailed instructions on how to use Spark shells, build
Spark from source, run standalone Spark examples, peruse links to Spark docu‐
mentation and configuration guides, and contribute to Spark.
bin
This directory, as the name suggests, contains most of the scripts you’ll employ to
interact with Spark, including the Spark shells (spark-sql, pyspark, spark-
shell, and sparkR). We will use these shells and executables in this directory
later in this chapter to submit a standalone Spark application using spark-
submit, and write a script that builds and pushes Docker images when running
Spark with Kubernetes support.
sbin
Most of the scripts in this directory are administrative in purpose, for starting
and stopping Spark components in the cluster in its various deployment
modes. For details on the deployment modes, see the cheat sheet in Table 1-1 in
Chapter 1.
kubernetes
Since the release of Spark 2.4, this directory contains Dockerfiles for creating
Docker images for your Spark distribution on a Kubernetes cluster. It also con‐
tains a file providing instructions on how to build the Spark distribution before
building your Docker images.
Step 1: Downloading Apache Spark | 21
50.
data
This directory ispopulated with *.txt files that serve as input for Spark’s compo‐
nents: MLlib, Structured Streaming, and GraphX.
examples
For any developer, two imperatives that ease the journey to learning any new
platform are loads of “how-to” code examples and comprehensive documenta‐
tion. Spark provides examples for Java, Python, R, and Scala, and you’ll want to
employ them when learning the framework. We will allude to some of these
examples in this and subsequent chapters.
Step 2: Using the Scala or PySpark Shell
As mentioned earlier, Spark comes with four widely used interpreters that act like
interactive “shells” and enable ad hoc data analysis: pyspark, spark-shell, spark-
sql, and sparkR. In many ways, their interactivity imitates shells you’ll already be
familiar with if you have experience with Python, Scala, R, SQL, or Unix operating
system shells such as bash or the Bourne shell.
These shells have been augmented to support connecting to the cluster and to allow
you to load distributed data into Spark workers’ memory. Whether you are dealing
with gigabytes of data or small data sets, Spark shells are conducive to learning Spark
quickly.
To start PySpark, cd to the bin directory and launch a shell by typing pyspark. If you
have installed PySpark from PyPI, then just typing pyspark will suffice:
$ pyspark
Python 3.7.3 (default, Mar 27 2019, 09:23:15)
[Clang 10.0.1 (clang-1001.0.46.3)] on darwin
Type "help", "copyright", "credits" or "license" for more information.
20/02/16 19:28:48 WARN NativeCodeLoader: Unable to load native-hadoop library
for your platform... using builtin-java classes where applicable
Welcome to
____ __
/ __/__ ___ _____/ /__
_ / _ / _ `/ __/ '_/
/__ / .__/_,_/_/ /_/_ version 3.0.0-preview2
/_/
Using Python version 3.7.3 (default, Mar 27 2019 09:23:15)
SparkSession available as 'spark'.
>>> spark.version
'3.0.0-preview2'
>>>
22 | Chapter 2: Downloading Apache Spark and Getting Started
51.
To start asimilar Spark shell with Scala, cd to the bin directory and type
spark-shell:
$ spark-shell
20/05/07 19:30:26 WARN NativeCodeLoader: Unable to load native-hadoop library
for your platform... using builtin-java classes where applicable
Spark context Web UI available at http://10.0.1.7:4040
Spark context available as 'sc' (master = local[*], app id = local-1581910231902)
Spark session available as 'spark'.
Welcome to
____ __
/ __/__ ___ _____/ /__
_ / _ / _ `/ __/ '_/
/___/ .__/_,_/_/ /_/_ version 3.0.0-preview2
/_/
Using Scala version 2.12.10 (Java HotSpot(TM) 64-Bit Server VM, Java 1.8.0_241)
Type in expressions to have them evaluated.
Type :help for more information.
scala> spark.version
res0: String = 3.0.0-preview2
scala>
Using the Local Machine
Now that you’ve downloaded and installed Spark on your local machine, for the
remainder of this chapter you’ll be using Spark interpretive shells locally. That is,
Spark will be running in local mode.
Refer to Table 1-1 in Chapter 1 for a reminder of which compo‐
nents run where in local mode.
As noted in the previous chapter, Spark computations are expressed as operations.
These operations are then converted into low-level RDD-based bytecode as tasks,
which are distributed to Spark’s executors for execution.
Let’s look at a short example where we read in a text file as a DataFrame, show a sam‐
ple of the strings read, and count the total number of lines in the file. This simple
example illustrates the use of the high-level Structured APIs, which we will cover in
the next chapter. The show(10, false) operation on the DataFrame only displays the
first 10 lines without truncating; by default the truncate Boolean flag is true. Here’s
what this looks like in the Scala shell:
Step 2: Using the Scala or PySpark Shell | 23
52.
scala> val strings= spark.read.text("../README.md")
strings: org.apache.spark.sql.DataFrame = [value: string]
scala> strings.show(10, false)
+------------------------------------------------------------------------------+
|value |
+------------------------------------------------------------------------------+
|# Apache Spark |
| |
|Spark is a unified analytics engine for large-scale data processing. It |
|provides high-level APIs in Scala, Java, Python, and R, and an optimized |
|engine that supports general computation graphs for data analysis. It also |
|supports a rich set of higher-level tools including Spark SQL for SQL and |
|DataFrames, MLlib for machine learning, GraphX for graph processing, |
| and Structured Streaming for stream processing. |
| |
|<https://spark.apache.org/> |
+------------------------------------------------------------------------------+
only showing top 10 rows
scala> strings.count()
res2: Long = 109
scala>
Quite simple. Let’s look at a similar example using the Python interpretive shell,
pyspark:
$ pyspark
Python 3.7.3 (default, Mar 27 2019, 09:23:15)
[Clang 10.0.1 (clang-1001.0.46.3)] on darwin
Type "help", "copyright", "credits" or "license" for more information.
WARNING: An illegal reflective access operation has occurred
WARNING: Illegal reflective access by org.apache.spark.unsafe.Platform
WARNING: Use --illegal-access=warn to enable warnings of further illegal
reflective access operations
WARNING: All illegal access operations will be denied in a future release
20/01/10 11:28:29 WARN NativeCodeLoader: Unable to load native-hadoop library
for your platform... using builtin-java classes where applicable
Using Spark's default log4j profile: org/apache/spark/log4j-defaults.properties
Setting default log level to "WARN".
To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use
setLogLevel(newLevel).
Welcome to
____ __
/ __/__ ___ _____/ /__
_ / _ / _ `/ __/ '_/
/__ / .__/_,_/_/ /_/_ version 3.0.0-preview2
/_/
Using Python version 3.7.3 (default, Mar 27 2019 09:23:15)
SparkSession available as 'spark'.
>>> strings = spark.read.text("../README.md")
24 | Chapter 2: Downloading Apache Spark and Getting Started
53.
>>> strings.show(10, truncate=False)
+------------------------------------------------------------------------------+
|value|
+------------------------------------------------------------------------------+
|# Apache Spark |
| |
|Spark is a unified analytics engine for large-scale data processing. It |
|provides high-level APIs in Scala, Java, Python, and R, and an optimized |
|engine that supports general computation graphs for data analysis. It also |
|supports a rich set of higher-level tools including Spark SQL for SQL and |
|DataFrames, MLlib for machine learning, GraphX for graph processing, |
|and Structured Streaming for stream processing. |
| |
|<https://spark.apache.org/> |
+------------------------------------------------------------------------------+
only showing top 10 rows
>>> strings.count()
109
>>>
To exit any of the Spark shells, press Ctrl-D. As you can see, this rapid interactivity
with Spark shells is conducive not only to rapid learning but to rapid prototyping,
too.
In the preceding examples, notice the API syntax and signature parity across both
Scala and Python. Throughout Spark’s evolution from 1.x, that has been one (among
many) of the enduring improvements.
Also note that we used the high-level Structured APIs to read a text file into a Spark
DataFrame rather than an RDD. Throughout the book, we will focus more on these
Structured APIs; since Spark 2.x, RDDs are now consigned to low-level APIs.
Every computation expressed in high-level Structured APIs is
decomposed into low-level optimized and generated RDD opera‐
tions and then converted into Scala bytecode for the executors’
JVMs. This generated RDD operation code is not accessible to
users, nor is it the same as the user-facing RDD APIs.
Step 3: Understanding Spark Application Concepts
Now that you have downloaded Spark, installed it on your laptop in standalone
mode, launched a Spark shell, and executed some short code examples interactively,
you’re ready to take the final step.
To understand what’s happening under the hood with our sample code, you’ll need to
be familiar with some of the key concepts of a Spark application and how the code is
Step 3: Understanding Spark Application Concepts | 25
54.
transformed and executedas tasks across the Spark executors. We’ll begin by defining
some important terms:
Application
A user program built on Spark using its APIs. It consists of a driver program and
executors on the cluster.
SparkSession
An object that provides a point of entry to interact with underlying Spark func‐
tionality and allows programming Spark with its APIs. In an interactive Spark
shell, the Spark driver instantiates a SparkSession for you, while in a Spark
application, you create a SparkSession object yourself.
Job
A parallel computation consisting of multiple tasks that gets spawned in response
to a Spark action (e.g., save(), collect()).
Stage
Each job gets divided into smaller sets of tasks called stages that depend on each
other.
Task
A single unit of work or execution that will be sent to a Spark executor.
Let’s dig into these concepts in a little more detail.
Spark Application and SparkSession
At the core of every Spark application is the Spark driver program, which creates a
SparkSession object. When you’re working with a Spark shell, the driver is part of
the shell and the SparkSession object (accessible via the variable spark) is created for
you, as you saw in the earlier examples when you launched the shells.
In those examples, because you launched the Spark shell locally on your laptop, all the
operations ran locally, in a single JVM. But you can just as easily launch a Spark shell
to analyze data in parallel on a cluster as in local mode. The commands spark-shell
--help or pyspark --help will show you how to connect to the Spark cluster man‐
ager. Figure 2-2 shows how Spark executes on a cluster once you’ve done this.
26 | Chapter 2: Downloading Apache Spark and Getting Started
After this hegave back his slice of bread and butter. “Don’t want
’e now, I wants a piece of cake.”
“You must eat the bread and butter first,” he was told.
“No, shan’t,” he said, and passed it on to Ruthie, who could not
take it from him because Miss Margaret shook her head.
“Shan’t eat ’en,” Tommy stated, emphatically.
But this was a case in which Miss Margaret undoubtedly held
the upper hand. She made no reply to Tommy’s assertion, and when
he tried to extract a piece of cake from the basket it was placed
beyond his reach.
“Shan’t eat ’en,” he said again, but again no notice was taken of
his words. Defiantly he picked up the bucket and spade and began
to dig in the sand.
A tempting row of Cornish splits, halved and spread with jam
and cream, was prepared by Miss Dorothea.
Tommy soon returned. “Can I have a split, please?” he asked, in
quite a different voice.
“Yes,” he was promised, “as soon as ever the bread and butter’s
eaten.”
He shook his head, and almost at once asked again, “Please can
I have a split, ’n jam ’n cream?”
“Tommy,” said Miss Margaret, very definitely, “don’t be such a
foolish boy. Until you have eaten the bread and butter you can have
nothing else. Try to understand that I mean that.”
Tommy’s hands hung limply at his sides. He gazed in open-
mouthed amazement at Miss Margaret. She did really and truly
mean it, he supposed. It was very odd and very surprising, and he
picked up the rejected bread and butter and slowly began to eat.
“Oh, my cake,” exclaimed Ruthie, as half a slice of saffron-cake
broke in her hand and fell into the sand.
“You can’t eat that now, Ruthie,” laughed Miss Margaret, as she
was about to pick it up. “It will be much too gritty.”
57.
Then Miss Margaretrealized that she had made a grave tactical
error, for at once Tommy’s bread and butter fell at his feet.
“That must be eaten,” said Miss Margaret quickly, and Tommy
put his heel upon it and ground it deep down in the sand. Out of the
corners of his eyes he glanced at Miss Margaret, but apparently she
was quite unaware of his action, so he sidled up to her and once
more pleaded for a split.
At this point, with disconcerting suddenness, the rain began to
fall. Hastily the luncheon basket was repacked and Miss Margaret,
Miss Dorothea and Ruthie ran to the shelter of a coach-house near
by, where they were given permission to stay. Tommy remained
behind and resumed his digging in the sand. When no notice was
taken of his absence, he decided that making castles in the rain was
poor sport. Accordingly he rejoined his party and found them merrily
continuing the interrupted lunch.
Confidently he approached Miss Margaret, asking for “a split an’
cream, please.”
“But I can’t give you a split,” she said, “you were to have it
when you’d eaten the bread and butter, and not until then.”
“I did eat the bread and butter in my hand.”
“What about the piece in the sand?”
Then Miss Margaret had seen him tread on it: this was
unexpected.
“Couldn’t help droppin’ ’e,” he said, now almost tearfully.
“But why did you bury it deep down in the sand?”
“I thought somebody might come along an’ not know, an’ pick
’e up an’ eat ’e, an’ it wouldn’t be nice for they.”
“Very well,” said Miss Margaret, “I’ll give you another piece
exactly the same size, and when you’ve eaten that you can have
splits and cream and just whatever you like.”
But Tommy refused and kicked a ball savagely round and round
the coach-house to soothe his outraged feelings. Violent exercise,
however, did not allay his hunger.
58.
“Please can Ihave a split,” he asked once more.
Without speaking, Miss Margaret offered him a piece of bread
and butter exactly the size of that which he had hidden in the sand,
and Tommy ate it without remonstrance.
After lunch the picnic-party played ball-games in the roomy
coach-house, but when at the end of an hour the rain showed no
sign of abating, the ladies, in spite of Ruthie’s earnest pleading,
decided that it would be wiser to go home.
Somewhat dejectedly they walked to the inn for the gingle and
Jimmy. Tommy brought up the rear, trailing his long spade after him
and rattling his bucket against his knees each step he took. “Well,”
Miss Dorothea overheard him say, “Well, Ruthie; now this day do be
bravely spoiled.”
On the homeward drive Miss Dorothea told the children the
history of Little Black Sambo. Then Ruthie told a story in which full-
stops occurred in the middle of sentences whenever it was
absolutely necessary that she should pause for breath.
“There was wanst a little boy an’ he had a rabbit and it lived in
a house in the garden an’ he went up to feed it with green stuff one
night an’ he. Left the door open an’ he met a man an’ he said to the
man what have you got in your pocket an’ the man said a little
rabbit an’ the boy took this little baby rabbit an’ took it to his home
because he’d lost his own rabbit. Through leavin’ the door open an’
he met a man an’ he said to the man what’ve you got in your pocket
an’ he said a very little bird so he took it to his home and put it in a
house in his garden.”
At some length the story went on. Always the boy met a man,
and always the man had in his pocket some strange and unexpected
animal which the boy took to his home and put in a house in the
garden.
But finally, “An’ the boy went out again an’ he met a lady
wheelin’ a pram an’ there was a baby in the pram an’ the boy said
what’ve you got in your pocket an’ the lady said I haven’t got nothin’
59.
in my pocketan’ neither she hadn’t got nothin’ in her pocket for she
only had a little baby an’ the little baby was in the pram.”
Then Ruthie looked round the gingle, smiling, and the wet
audience of three, realizing that in this unfinished and unsatisfactory
way the story ended, thanked her politely, and wondered whether
the boy kept all his new pets safely or whether, like the original
rabbit, they too escaped.
Going up the hill from Esselton they again passed the big,
immovable car; it was still standing right in the middle of the road.
All the passengers sat very closely together under the hood,
evidently awaiting relief. Fired by Ruthie’s example, Tommy decided
that he, too, would tell a story.
“There was wanst a rabbit—. An’ it went down to the beach—.
An’ there was another rabbit, too—. An’ a great, big giant came
down—. An’ he took away one of the rabbits, did the giant—. An’ the
giant ate it all up.”
They were passing St Peter’s by this time. Draeth and home and
Mammy were very near and Tommy felt unhappy inside. “I do be
feelin’ brave an’ bad,” he said, lifting tearful eyes to Miss Margaret.
But Miss Margaret was busily occupied with the pony and the reins,
and had no sympathy to extend to a conscience-stricken boy.
In pelting rain the gingle drew up in front of Mr. Chard’s door.
“Been a-sailin’, Tommy Tregennis?” asked some of the West Drayers,
but Tommy felt too bad to reply.
“Been a good boy, my lovely?” asked Mammy, as she drew off
his boots.
“I dunno!”
“But you must know,” said Mammy, as she buttoned the strap
shoes. “Been a good boy?”
There was no answer.
“Well, have you been naughty?” Mammy persisted.
Tommy wriggled down from the chair. “I dunno, and don’t ee
bother I no more, Mammy, ask Miss Margaret what I been,” and he
60.
ran from thehouse, unmindful of the rain, to seek the soothing
presence of his never-failing admirer, Aunt Keziah Kate.
After tea Mammy had a long and serious talk with the ladies.
“’Underds of times,” she admitted, she threatened Tommy, and
nothing happened. “When there’s visitors here I feel I must go the
easiest way,” she explained.
“He’s too good to be spoiled,” urged Miss Margaret.
“We don’t want to spoil him, Miss, his daddy an’ me, and we
must try and be firmer with him, for he do indeed be gettin’ out of
hand.”
At six o’clock Miss Margaret heard Tommy go into the bedroom,
and soon afterwards there was Mrs. Tregennis’s heavier step on the
stairs. There was a rustle of bed clothes and a creaking of springs,
and by these signs Miss Margaret knew that Tommy was in bed.
“Tommy,” said Mrs. Tregennis, “do you know why your Mammy
do be feelin’ very sad?”
“No Mammy,” was the reply, “but shall us talk a bit about you,
when ee was just a very little girl.”
“No, my son,” said Mrs. Tregennis, with great firmness; “we’m
not goin’ to talk about me when I was small; we be goin’ to talk
about you, instead, my son.”
Then the door was closed and Miss Margaret heard no more.
61.
A
CHAPTER XXI
FTER thePolderry picnic the relations between Tommy and his
ladies were distinctly strained. In many little ways they worked
for his regeneration and tried to bring home to him the enormity of
his offences.
On the following day, which was Sunday, he himself showed tact
in avoiding the upstairs sitting-room. Mammy brought up the letters
and whenever the ladies approached the kitchen they found Tommy
fully and unobtrusively occupied with urgent affairs in the corner
farthest from the door.
On Monday morning when he was running along the quay from
school, his quick eye saw a halfpenny lying in the dust near some
drying tackle. This was unprecedented good fortune. It was the first
money that Tommy had ever found. After picking it up he looked
round for possible claimants, but as none appeared he put it in his
pocket and pursued his homeward way.
He found only Mammy indoors. She was very busy just then,
and although she was moderately enthusiastic over his find, he felt
the need of wider sympathy and ran out into the alley on the off-
chance of meeting with Jimmy Prynne.
Jimmy Prynne was not in sight, but coming up from the sea
were his ladies. They carried travelling-rugs and books, and were
laughing together as they walked. Tommy had always taken them
into his confidence at once no matter whether it was in joy or
sorrow. To-day he felt an unaccountable diffidence in approaching
them.
Somewhat hesitatingly he drew near and their laughter at once
ceased. “Found this!” and he held his dusty halfpenny up to view.
Miss Dorothea said nothing, Miss Margaret merely remarked
“Oh,” and passed on.
62.
Quite obviously theyhad not seen his treasure. “’Tis a ’a’penny,”
he insisted. “I found ’e on the quay all in a ’eap o’ dust.”
Miss Dorothea passed into the house. Miss Margaret smiled
politely, and “Oh,” she said once more.
Tommy was sick at heart. It was as though the very foundations
of his world were giving way.
In the matter of finds he seemed to have struck a run of luck,
for on Tuesday he came home with a knife picked up on the shingle
near the Frying Pan steps. It was an ivory-handled knife and had
four blades of different sizes; they were all rusty and all broken.
“I’ll give ee my knife, Daddy,” said Tommy, at tea-time, pushing
it across the table.
“Mustn’t do that, must never give nothin’ as cuts.”
“Why?” asked Tommy.
“’Twill cut love. If so be as I took that knife I shouldn’t love ee
any more. ’Tis all right if ’e do be bought, so here be a ’a’penny for
ee.”
Daddy thrust the knife into his deep, trouser pocket, and
Tommy put the halfpenny into his.
Tommy felt that his ladies would surely be interested in this
day’s event. There was not only the thrilling incident of the finding of
the knife, but there was the subsequent financial transaction with
Daddy, and a second halfpenny in his trouser pocket to-day. He
poured out his story to them as they were mounting the stairs. To
his amazement it left them cold.
When next they passed the kitchen door he entreated his Daddy
to show the knife to them, and Tregennis displayed the four broken
blades from which he had removed the rust with bits of cinder.
“You will find that most useful, Tregennis,” said Miss Margaret.
To Tommy she spoke not at all.
In the doorway she relaxed just a little. “You have really been
quite lucky, Tommy,” she remarked, and went with Miss Dorothea
down to the sea.
63.
Later the ladieshad occasion to buy stamps. Coming from the
post-office they saw Tommy sitting on the quay-wall, knocking off
bits of mortar with his heels.
“Our one-time friend!” laughed Miss Dorothea, but Miss
Margaret looked straight ahead.
When Tommy saw them he slipped from the wall and ran
behind them whistling and singing to attract attention. As this
proved a dull and ineffectual game he dodged in front kicking an old
salmon tin before him as he ran. By the Three Jolly Tars Teddy
Falconer was playing. When he saw Tommy he hastily picked up his
ball and shrank into the doorway of the inn. Now Tommy would have
been distinctly glad for this incident to pass unobserved, but it was
at this moment, unluckily, that Miss Margaret became aware of him.
“Why does Teddy look so frightened?” she asked.
“’Tother day I did kick his ball for ’e, and ...” with a dramatic
gesture towards the shrinking Teddy, “’e did run into his house to tell
his Mammy.”
The look that Miss Margaret gave Tommy showed him that his
position was in no wise strengthened. He fell behind and walked
home dejectedly to tea.
At half-past six that evening, when the water was high, there
was to be a launch, Tregennis said. Miss Dorothea was tired, so Miss
Margaret went alone to see the new lugger take the water. She
missed the launch because it was all over half-an-hour before she
got there, but she found instead, playing on the quay, Mary Sarah
and Katie, and the whole Stevenson family.
Of course the Stevensons were there, Mary Sarah explained, for
they were the O’Grady’s cousins. Mary Sarah was as much as five,
and in virtue of her age she took the lead. Mary Sarah enlightened
the others as to the identity of the Lady, and vouched for her
respectability, so to speak. The Lady had often spoken to her, she
told them with an air of superiority, and she had often spoken to the
Lady when the Lady was sittin’ writin’ up on the top o’ the cliffs.
64.
When the conversationdragged a reference was made to
sweets, and the whole party repaired to Mrs. Tregennis’s house.
“Mrs. Tregennis,” called out Miss Margaret, “here’s Mary Sarah
O’Grady, and Katie O’Grady, and their cousins the Stevensons and
me. We’ve all come here for sweets. Have you any to give away?”
There was a blank moment when Mrs. Tregennis announced
that she hadn’t got no not one.
Tommy, who was in the kitchen at the time, was delighted to
think that sweets were not forthcoming for Mary Sarah and Katie,
and the whole family of Stevensons.
Then Miss Margaret brightened up. “I remember!” she said, and
ran upstairs two steps at a time.
When she returned she had in her hand a good-sized paper bag
which she gave to Mary Sarah.
“Now Mary Sarah,” she admonished; “you share them out, turn
and turn about. Be quite fair. They’re such pretty children,” she
remarked to Mrs. Tregennis.
“They did oughter be,” was the reply, “for they be Irish to the
very finger-tips.”
Miss Margaret again turned to the group of children. “What
have you got, Katie?” and Katie withdrew from her mouth a big
bull’s-eye.
With bulging cheek, and somewhat inarticulately, Mary Sarah
spoke. “Her do have a shocking bad cold,” she said with the wisdom
of three times five; “they mints will be brave an’ good for she.”
This incident made a deep impression upon Tommy. So far the
ladies had been his own special property; he had shared them quite
occasionally with Ruthie, but with her alone. That Mary Sarah and
Katie and the Stevensons should adopt them was by no means in
accordance with his wishes. Something must be done, and that
something clearly must be the strengthening of his own moral
character.
Weeks before Miss Margaret had initiated Tommy into the
mysteries of an early morning rite. You first of all clasped hands
65.
(right hands ithad to be, Tommy’s left was always rejected), and
then you said “Good morning,” and smiled, and after that you shook
the hands up and down and jumped once to each shake. Both
shaking and jumping got quicker and quicker, and at last ended with
an abrupt stop, and your arms fell stiffly to your sides.
To Tommy this ceremony had become an integral part of the
morning. It was strange, too, how only Miss Margaret knew the
proper way. When Miss Dorothea tried to shake hands with him once
he found that she had absolutely no knowledge of the right method
of procedure and he had been obliged to tell her so.
For three mornings now the ceremony had been neglected. On
the Wednesday Tommy determined that it must no longer be
omitted, and when he saw Miss Margaret he held out his hand and
smiled. Miss Margaret smiled too, took his hand in hers, shook it just
once, said “Good morning,” then turned to Mrs. Tregennis and gave
orders for the day.
“Why wouldn’t Miss Margaret shake hands with me proper?” he
asked afterwards.
“Don’t ee know?” Mammy replied, “I guess I know. You think,
my son.”
So Tommy thought.
There was great excitement in Draeth the next day, for a big
Conservative tea-meeting had been arranged for the afternoon, and
The Member was to be present.
At one end of the tea-table Mrs. Tregennis presided. She was
accompanied by Tommy in the dandy-go-risset sailor suit, and by
Tregennis. Tregennis felt very stiff and uncomfortable, for as this
was such an important occasion Mrs. Tregennis had decided that he
must discard the fisherman’s jersey in favour of his wedding suit. In
all the eight years he had been married this suit had not been worn
above a dozen times, for, as he declared to Miss Margaret, “It has to
be some fine weather, Miss, when I puts on they.”
This afternoon the wedding suit was worn, and Tregennis, Mrs.
Tregennis and Tommy sat down to tea with their fellow-
66.
Conservatives and withall the quality of Draeth. An excellent tea
was provided at sixpence a head; The Member made a few remarks
on the political outlook which were well received, and the meeting
broke up amid general congratulations. As Mrs. Tregennis explained
afterwards to the ladies she herself was not a Conservative, in fact,
her father was a Liberal, so if it came to a question of family she was
a Liberal too. She knew naught of it, but always hoped that the best
man would get in, politics or no politics. Tommy, she supposed,
would be brought up as a Conservative and follow in his father’s
steps.
“But that is too dreadful to contemplate,” exclaimed Miss
Margaret. “Tommy, come here.”
This was a tone of voice Tommy had not heard for five days. He
came with alacrity.
Miss Margaret held out a bottle of boiled sweets that were just
the very best kind he liked; hard and scrunchy they were on the
outside, soft and sticky within.
“These,” said Miss Margaret, “are Liberal sweets. Each time you
eat one you must say, ‘I’m a good Liberal.’”
Tommy grinned.
“That do be bribery and corruption,” objected Tregennis.
“Never mind,” Miss Margaret replied. “Now, Tommy, what are
you to say?”
Tommy had taken two sweets at the same time and there was a
bulge in each cheek. In reply to Miss Margaret’s question he bit first
on the right side of his mouth, and “I be a brave good Liberal,” he
asserted. Then he bit on the left side and the formula was repeated.
Afterwards, “I don’t care which I be, ’servative or Liberal,” he
affirmed, “but I do like they sweets better’n either.”
The next morning Miss Margaret shook hands with him in quite
the proper manner. They jumped quite thirteen times and the ending
was exceptionally sudden and abrupt. While Miss Margaret stood
stiffly in front of him Tommy made a little dash forward and threw
67.
his arms aroundher. She stooped and kissed him and Tommy went
off happily to school.
So big was the bottle of Liberal sweets that even on Saturday
there were still some left. Just before tea Tommy asked many times
that Mammy would get these from the cupboard and let him eat
them then.
“Not before tea, ma handsome; not till ee do go to bed.”
“Wants they now to wanst, please Mammy,” Tommy stated.
“Not till ee do go to bed, I tell ee.”
“Gimme one of they Liberal sweets now.”
“Tommy,” it was Miss Margaret’s voice. “Tommy, I want to give
you a box of chocolates to-morrow, but if you ask once more to-day
for the bottle of sweets, I shall keep the chocolates for myself.”
“There, you hear,” said Mammy, “an’ you do know now, Tommy,
that what Miss Margaret says that she do mean.”
Tommy nodded a little shamefacedly. “Yes, I know,” he
assented; “I remember.”
When Tommy came in from play two hours later he walked up
to the kitchen cupboard.
“Mammy,” he demanded eagerly, holding up his hands to the
shelf out of reach, “Mammy, I tell ee, do give I one o’ they Lib....”
Then came recollection. “Oh,” he said, “I had a’most forgot.”
His outstretched hands dropped to his sides, he clutched the
stuff of his trousers to keep the restless fingers still, and with very
tightly closed lips turned his back on the cupboard and the kitchen,
and walked upstairs to bed.
Thus it was that Tommy took the first conscious and determined
step towards the improvement of his moral character.
69.
I
CHAPTER XXII
N theupper windows of the double-fronted house near the
church plain short blinds had replaced the long Madras muslin
curtains. Again the gay Brussels carpet in the best sitting-room was
covered with newspaper and the ornaments were put away. All
visitors had left Draeth, for the Summer was over, and with the
summer Tommy’s sixth birthday had come and gone.
Being six did not bring with it the rare delight that Tommy had
expected. For one thing he missed his ladies; for another he was
troubled by the growing sadness of his Mammy’s face. Twice when
he came in unexpectedly he had found her in tears, and yet she had
assured him that she had no headache anywhere.
It was most unfortunate, too, that just when things were a little
dreary Granny Tregennis should be so very tired. Whenever Tommy
ran in to see her now, he found that she was still in bed, and
although she wanted him to play with her on Saturday mornings yet,
when he went upstairs, she seemed to have but little pleasure in the
play-toys that were kept in the fireplace cupboard.
“My Granny did ought to have a brave long sleep,” he asserted
with puckered brow.
“She do be goin’ to have a brave long sleep, ma handsome,”
Mammy’s eyes filled with tears as she spoke and this seemed to
Tommy inconsistent.
On the front, looking for occupation, he fell in with Old John.
Old John was a life-long friend, but of late there had been so many
other interests to attract him that Old John had been neglected.
Now Tommy hailed him. “Gotten a noo pair o’ trousers,” he
shouted, and almost overbalanced in his effort to stand on one leg
with the other stretched out at right angles in front of him.
“Hm!” said Old John.
70.
Taking his pipefrom his mouth he examined the trousers
critically. “Hm!” he said again.
“My Mammy’s blue skirt,” Tommy explained, proudly, while he
reversed his position. He now stood on the left leg and thrust
forward the right.
“Hallo!” he cried, for Mammy was approaching to bring him in to
bed.
“Tommy ’e do tell me ’e’ve gotten noo trousers.”
Mammy nodded.
“Made out o’ your blue skirt, Ellen Tregennis?”
Mammy nodded and smiled.
“You’m gotten as good a little woman as ever is in the world for
your Mammy, Tommy.” Old John looked at Mrs. Tregennis, who
laughed in acknowledgement of the compliment.
“We’m forced to do as careful as we can,” she said. “When Tom
can’t go neither boulter-fishin’ nor whiffin’ we be livin’ on our means
like the gintry; then I make clothes for Tommy, so’s he’ll be
respectable. ’Taint no mortal use, Old John, for we to look small and
be small both, so there’s where ’tis to.”
“Makes ’en out of hers!” This was a fact that Tommy was very
proud of.
Again Mammy laughed. “Well, ’tis so,” she admitted. “Tom an’
me we wears the clothes, then Tommy wears ’en, then they do be
made into mats an’ we treads on ’en. Blouses bain’t no good though,
for ’e,” she added ruefully; “very wastely things they be to tear up
for ’e, the sleeves do come s’awkward!”
“An’ Tom now, ’e do be a brave good husband?” queried Old
John.
“That he be. I wouldn’t stand no nonsense, I wouldn’t be
’umbugged about with ’e, me at my size.”
Mammy smiled and led Tommy off to bed.
At the top of the alley Tommy stopped. “I’ll be back in a
minute,” he said as he turned towards Main Street.
71.
“Where be a-goin’?”asked Mammy.
“Where be I a-goin’?” Tommy echoed in surprise. “Why I be a-
goin’ to say good-night to my Gran.”
“I shouldn’t go to-night, ma handsome; Granny’s tired.”
Tommy turned and looked at his mother in amazement. Every
night ever since he could remember he had run along to say “good-
night” to Granny.
“She’ll want me, an’ I must go,” he demurred.
“She do be too tired for ee to-night, my lamb.”
“Do ee mean, Mammy, that ’er do be too tired for me to say
good-night to she?” Tommy was frankly incredulous.
Mammy nodded and again the tears came. “She can’t do with
ee, not to-night,” she said very softly.
Much puzzled Tommy was led into the house and undressed;
still puzzled he went upstairs to bed. Half-an-hour later he fell
asleep, wondering.
The next day, Saturday, a reluctant Tommy was sent to spend
the morning on the beach, while Mammy went along to be with Aunt
Keziah Kate, for Granny’s tiredness was nearly over.
In the old-fashioned bedroom there was little to do but wait.
“She do be slippin’ away fast,” said Aunt Keziah Kate.
Gently she stroked the frail old hands that lay on the coarse
coverlet. There were no tears in her eyes. There would be plenty of
time for weeping afterwards, now they must just wait.
“It do be just like Gran.” Mammy hastily brushed away a tear.
“Never wasn’t no trouble to no-one, wasn’t Gran. All her life she’ve
spent in considerin’ others. As long as visitors was here she’ve
keppen up; now that the summer’s over she do be quietly slippin’
away.”
The old woman, lying so quietly on the bed, opened her eyes
and her lips moved slowly. Aunt Keziah Kate bent to catch the
whispered words.
“Saturday?”
72.
Aunt Keziah Katenodded.
“What be the time?”
Aunt Keziah Kate told her.
“Then where be Tommy?”
“You don’t want ’e mother this mornin’, do ee?”
An almost imperceptible movement of Granny’s head was the
reply, and Tommy was hastily found and brought up from the
sunshine of the beach to the dim light of Granny’s room.
“Go very quietly, my lamb,” warned Mrs. Tregennis.
“But I allus do,” answered Tommy, rather indignantly. “She don’t
never hear me come; it do be a surprise for she.”
Then he creaked across the room on tip-toe, stepped first of all
on to the hassock and from this to the chair. When he raised the
curtain the sight of the lined face lying so still, so very still, upon the
pillow stopped the “Bo” before it left his lips.
Instead, “Granny, Granny,” he whispered. “I do be come to play
with ee, my Granny.”
The tired old eyes opened very slowly, and for a moment it
almost seemed as though she smiled. “Ma lovely,” she whispered.
But there were no play-toys to-day, for in the same room where
a new life had begun so many years ago an old one was soon to
end. There was no storm now. Outside the sun shone brightly, and a
little breeze gently moved the old chintz window curtains made so
many years ago by Granny’s busy hands.
Granfäather Tregennis had come into the room and large tears
were rolling down his cheeks. Tommy thought that grown men never
cried. His wonder deepened when Granfäather, who was quite grown
up, knelt down on the other side of the bed and covered his face
with his hands.
Mammy and Aunt Keziah Kate were crying too.
Tommy’s heart tightened with despair. Granny had forgotten
him, for again her eyes were closed.
73.
Then he rememberedsomething that would surely arouse her
interest, and from his trouser pocket he pulled out yards of tangled,
woollen chain; the very chain that Granny had taught him to make in
the far-away Christmas holidays.
“I made this for ee, Granny,” he said, putting into her hands a
motley string of pink, and green, and blue and red. “I did make ’e
for ee all myself, no-one else did never do none of ’e at all.”
Once more Granny opened her eyes. “Thank ee ma lovely,” she
whispered, and a little sigh fluttered between her parted lips.
Then Tommy was led away.
When Aunt Keziah Kate would have removed the tangled chain
the feeble fingers closed and held it more firmly.
Afterwards, when Granny was at rest, Granfäather Tregennis
took it from the cold hands and put it away in a drawer with his few
treasures—a dry, withered rose given him by Granny many, many
years ago, and an artificial spray of orange-blossom worn by Granny
on their wedding-day.
74.
O
CHAPTER XXIII
N theday of Granny’s funeral Old John took care of Tommy.
Old John lived up towards the Barbican, in as neat a
cottage as you could find in Draeth. No woman ever did a hand’s
turn in his little, two-roomed crib; the old sailor washed and
mended, cleaned and scrubbed, and kept his home so well that, as
Mrs. Tregennis remarked, ’twould be possible to eat anything as ’e’d
made, an’ eat it off his floor at that, an’ she for one would gladly do
it.
It was not until Old John was getting on in years that he had
married and set up a cabin of his own. He had given up sailorin’ then
and turned fisherman, because he wouldn’t leave his bonny little
maid so much alone.
Only to himself, never to any other, did Old John confess that
the bonny little maid had proved a misfit. God, how he had loved
her! Nigh on eighty was Old John now, and still he dreamed of her
at night. Too much given to newsin’ she had been and that was all
the trouble.
“’Ousin’ and tea-drinkin’ don’t hold in our line o’ life,” Old John
had told her, but she had only laughed and followed her own bent.
Under her care, or lack of care, the trim cottage by the Barbican had
become a dirty hovel.
75.
ON THE DAYOF GRANNY’S FUNERAL, OLD
JOHN TOOK CARE OF TOMMY.
Before his love could wane she died. Thirty-five years had gone
by since the night that Old John held her for the last time in his
arms. In her place she left a son, and the son was more of a misfit
than the mother who bore him.
“One o’ they creeperses!” was the judgement of Draeth, and Old
John knew that the judgement was just. But not only was his John
sly, he was idle and lazy as well.
“If I could only have had a son like Tommy, an’ a wife like ...,”
then Old John checked himself sharply; there was disloyalty in the
76.
thought and hegave undivided attention to his guest.
“What be we a-goin’ to have for dinner?” Tommy was asking.
“Fish,” replied Old John.
“What did ee eat for breakfast?”
“Fish as I catched at sunrise.”
“An’ what’ll ee have for supper?”
“Fish again.”
“Seems a lot o’ fish in one day,” Tommy stated.
“Why, yes; of course. ’Twouldn’t be so cheap to live else,
Tommy. Don’t ee know thicky tiddley verse:
Fish for breakfast that we ’ad,
An’ for dinner ’ad a chad,
An’ for tea we ’ad some ray,
So we ’ad fish three times that day!”
The young voice and the old one said the lines over and over in
a monotonous sing-song until Tommy knew them off by heart.
Movements overhead showed that John was getting up.
Although it was nearly half-past nine he had not yet left the
bedroom. When he came downstairs he looked sulky and unwashed
and ate his breakfast in sullen silence.
“Fish to sell?” he muttered.
Old John pointed to his early morning catch.
As well as being sly and lazy John was also a bit soft, and never
acted on his own responsibility.
“How much be I to get for they?” he asked.
It was only a small catch and Old John lifted the fish from the
basket to estimate their value.
“Should fetch tenpence,” he decided, “but make what ee can. If
ee can’t get tenpence, take eightpence; an’ if ’ee can’t get
eightpence, take sixpence; but make what ee can. Should fetch
77.
tenpence, though,” hesaid again as he replaced the fish and passed
the basket to his son.
John always followed the line of least resistance. Half-way to the
quay he met a man who handled his fish with a view to buying.
“What do you want for they?” he was asked.
“My fäather said get tenpence if ee can, or eightpence if ee can;
or sixpence if ee can; just make what ee can. So what’ll ee give for
they?”
Long before his return was expected John slouched into the
cottage kitchen and threw four pennies on the table. “For they fish,”
he said, and walked away to join a knot of idlers on the front.
Old John sighed as he gathered up the coins. He felt very old
these days: he wasn’t by no means the man he used to be, and it
was very difficult to live.
“Goin’ a-whiffin’ again to-day?” Tommy asked him, and he
brought his mind to bear upon the needs of the moment.
“Not whiffin’, but afore tea I must see to my lobster pots,” he
replied. “Did ought to get a good catch, too. What be a-goin’ to do,
Tommy, when art a grown man? Fishin’?”
Tommy shook his head. “No,” he stated, emphatically. “My
Mammy says it do be starvation to put a lad to fishin’ now. I’ll be a
p’liceman an’ scare they children bravely, that I will.” Tommy drew
himself up in proud anticipation of his authority-to-be.
“Bit lonely, bain’t ee sometimes, Tommy?” was Old John’s next
essay.
Tommy did not understand, so Old John tried to make his
meaning clear.
“’Twould be nice for ee to have a baby sister to play with an’
look after,” he said. Then he knew that he had blundered.
Tommy clenched his fingers, set his teeth together and breathed
hard. “Ef a baby sister do come to my house,” he declared, “I shall
upstairs with she, an’ out through the toppest window ’er’ll go.”
78.
“Well, well, well!”Old John was at a loss. When you are close on
eighty it is not easy to sustain a conversation with a boy of six.
“Where be my granny?” Tommy asked, unexpectedly.
Old John was confused. It did not come easy to him to talk o’
things as ’ad to do wi’ religion.
“In heaven,” he answered, hesitatingly.
Tommy went to the door and looked earnestly upwards at the
clouds,
“.....white as flocks new shorn
And fresh from the clear brook.”
His eyes filled with tears, but he blinked them bravely back.
Mammy had said not to cry, and he tried hard to be a man.
“I wonder if God wanted she as much as us,” he said. Then a
feeling of unutterable loneliness came upon him. His bravery fell
from him, and he ran sobbing to Old John.
“I be frightened,” he sobbed. “I want Mammy; will Mammy have
gotten home?”
Clumsily Old John held him in his arms, and, six years old
though he was, Tommy fell asleep just like a little boy. Since
Saturday everything had been so sad and so unusual; he had not
been to school and the days had dragged. He had gone to bed late
and got up early, and now he was quite tired out. Old John carried
him upstairs and laid him gently upon the unmade bed. There
Tommy slept until he was awakened for the dinner of fish.
Before tea Tommy left Old John’s cottage, and Old John went to
see to his lobster pots.
In her unaccustomed black Mammy’s pale face looked still paler.
Daddy was wearing his wedding-suit and a broad black tie. It was all
so unusual that Tommy felt almost a stranger in his own house.
Auntie Martha came in early in the evening and brought with her a
coat of Mabel’s which she thought would do for Tommy to wear to
school in the coming winter months.
79.
Welcome to ourwebsite – the perfect destination for book lovers and
knowledge seekers. We believe that every book holds a new world,
offering opportunities for learning, discovery, and personal growth.
That’s why we are dedicated to bringing you a diverse collection of
books, ranging from classic literature and specialized publications to
self-development guides and children's books.
More than just a book-buying platform, we strive to be a bridge
connecting you with timeless cultural and intellectual values. With an
elegant, user-friendly interface and a smart search system, you can
quickly find the books that best suit your interests. Additionally,
our special promotions and home delivery services help you save time
and fully enjoy the joy of reading.
Join us on a journey of knowledge exploration, passion nurturing, and
personal growth every day!
ebookbell.com









![978-1-492-05004-9
[GP]
Learning Spark
by Jules S. Damji, Brooke Wenig, Tathagata Das, and Denny Lee
Copyright © 2020 Databricks, Inc. All rights reserved.
Printed in the United States of America.
Published by O’Reilly Media, Inc., 1005 Gravenstein Highway North, Sebastopol, CA 95472.
O’Reilly books may be purchased for educational, business, or sales promotional use. Online editions are
also available for most titles (http://oreilly.com). For more information, contact our corporate/institutional
sales department: 800-998-9938 or corporate@oreilly.com.
Acquisitions Editor: Jonathan Hassell
Development Editor: Michele Cronin
Production Editor: Deborah Baker
Copyeditor: Rachel Head
Proofreader: Penelope Perkins
Indexer: Potomac Indexing, LLC
Interior Designer: David Futato
Cover Designer: Karen Montgomery
Illustrator: Rebecca Demarest
January 2015: First Edition
July 2020: Second Edition
Revision History for the Second Edition
2020-06-24: First Release
See http://oreilly.com/catalog/errata.csp?isbn=9781492050049 for release details.
The O’Reilly logo is a registered trademark of O’Reilly Media, Inc. Learning Spark, the cover image, and
related trade dress are trademarks of O’Reilly Media, Inc.
The views expressed in this work are those of the authors, and do not represent the publisher’s views.
While the publisher and the authors have used good faith efforts to ensure that the information and
instructions contained in this work are accurate, the publisher and the authors disclaim all responsibility
for errors or omissions, including without limitation responsibility for damages resulting from the use of
or reliance on this work. Use of the information and instructions contained in this work is at your own
risk. If any code samples or other technology this work contains or describes is subject to open source
licenses or the intellectual property rights of others, it is your responsibility to ensure that your use
thereof complies with such licenses and/or rights.
This work is part of a collaboration between O’Reilly and Databricks. See our statement of editorial inde‐
pendence.](https://image.slidesharecdn.com/5592758-250520172834-b064bb3f/85/Learning-Spark-Lightningfast-Data-Analytics-2nd-Edition-Jules-S-Damji-10-320.jpg)





























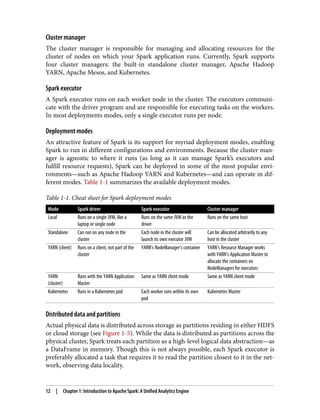




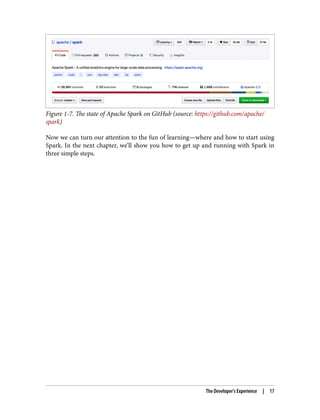


![Figure 2-1. The Apache Spark download page
This will download the tarball spark-3.0.0-preview2-bin-hadoop2.7.tgz, which con‐
tains all the Hadoop-related binaries you will need to run Spark in local mode on
your laptop. Alternatively, if you’re going to install it on an existing HDFS or Hadoop
installation, you can select the matching Hadoop version from the drop-down menu.
How to build from source is beyond the scope of this book, but you can read more
about it in the documentation.
At the time this book went to press Apache Spark 3.0 was still in
preview mode, but you can download the latest Spark 3.0 using the
same download method and instructions.
Since the release of Apache Spark 2.2, developers who only care about learning Spark
in Python have the option of installing PySpark from the PyPI repository. If you only
program in Python, you don’t have to install all the other libraries necessary to run
Scala, Java, or R; this makes the binary smaller. To install PySpark from PyPI, just run
pip install pyspark.
There are some extra dependencies that can be installed for SQL, ML, and MLlib, via
pip install pyspark[sql,ml,mllib] (or pip install pyspark[sql] if you only
want the SQL dependencies).
You will need to install Java 8 or above on your machine and set the
JAVA_HOME environment variable. See the documentation for
instructions on how to download and install Java.
20 | Chapter 2: Downloading Apache Spark and Getting Started](https://image.slidesharecdn.com/5592758-250520172834-b064bb3f/85/Learning-Spark-Lightningfast-Data-Analytics-2nd-Edition-Jules-S-Damji-48-320.jpg)

![data
This directory is populated with *.txt files that serve as input for Spark’s compo‐
nents: MLlib, Structured Streaming, and GraphX.
examples
For any developer, two imperatives that ease the journey to learning any new
platform are loads of “how-to” code examples and comprehensive documenta‐
tion. Spark provides examples for Java, Python, R, and Scala, and you’ll want to
employ them when learning the framework. We will allude to some of these
examples in this and subsequent chapters.
Step 2: Using the Scala or PySpark Shell
As mentioned earlier, Spark comes with four widely used interpreters that act like
interactive “shells” and enable ad hoc data analysis: pyspark, spark-shell, spark-
sql, and sparkR. In many ways, their interactivity imitates shells you’ll already be
familiar with if you have experience with Python, Scala, R, SQL, or Unix operating
system shells such as bash or the Bourne shell.
These shells have been augmented to support connecting to the cluster and to allow
you to load distributed data into Spark workers’ memory. Whether you are dealing
with gigabytes of data or small data sets, Spark shells are conducive to learning Spark
quickly.
To start PySpark, cd to the bin directory and launch a shell by typing pyspark. If you
have installed PySpark from PyPI, then just typing pyspark will suffice:
$ pyspark
Python 3.7.3 (default, Mar 27 2019, 09:23:15)
[Clang 10.0.1 (clang-1001.0.46.3)] on darwin
Type "help", "copyright", "credits" or "license" for more information.
20/02/16 19:28:48 WARN NativeCodeLoader: Unable to load native-hadoop library
for your platform... using builtin-java classes where applicable
Welcome to
____ __
/ __/__ ___ _____/ /__
_ / _ / _ `/ __/ '_/
/__ / .__/_,_/_/ /_/_ version 3.0.0-preview2
/_/
Using Python version 3.7.3 (default, Mar 27 2019 09:23:15)
SparkSession available as 'spark'.
>>> spark.version
'3.0.0-preview2'
>>>
22 | Chapter 2: Downloading Apache Spark and Getting Started](https://image.slidesharecdn.com/5592758-250520172834-b064bb3f/85/Learning-Spark-Lightningfast-Data-Analytics-2nd-Edition-Jules-S-Damji-50-320.jpg)
![To start a similar Spark shell with Scala, cd to the bin directory and type
spark-shell:
$ spark-shell
20/05/07 19:30:26 WARN NativeCodeLoader: Unable to load native-hadoop library
for your platform... using builtin-java classes where applicable
Spark context Web UI available at http://10.0.1.7:4040
Spark context available as 'sc' (master = local[*], app id = local-1581910231902)
Spark session available as 'spark'.
Welcome to
____ __
/ __/__ ___ _____/ /__
_ / _ / _ `/ __/ '_/
/___/ .__/_,_/_/ /_/_ version 3.0.0-preview2
/_/
Using Scala version 2.12.10 (Java HotSpot(TM) 64-Bit Server VM, Java 1.8.0_241)
Type in expressions to have them evaluated.
Type :help for more information.
scala> spark.version
res0: String = 3.0.0-preview2
scala>
Using the Local Machine
Now that you’ve downloaded and installed Spark on your local machine, for the
remainder of this chapter you’ll be using Spark interpretive shells locally. That is,
Spark will be running in local mode.
Refer to Table 1-1 in Chapter 1 for a reminder of which compo‐
nents run where in local mode.
As noted in the previous chapter, Spark computations are expressed as operations.
These operations are then converted into low-level RDD-based bytecode as tasks,
which are distributed to Spark’s executors for execution.
Let’s look at a short example where we read in a text file as a DataFrame, show a sam‐
ple of the strings read, and count the total number of lines in the file. This simple
example illustrates the use of the high-level Structured APIs, which we will cover in
the next chapter. The show(10, false) operation on the DataFrame only displays the
first 10 lines without truncating; by default the truncate Boolean flag is true. Here’s
what this looks like in the Scala shell:
Step 2: Using the Scala or PySpark Shell | 23](https://image.slidesharecdn.com/5592758-250520172834-b064bb3f/85/Learning-Spark-Lightningfast-Data-Analytics-2nd-Edition-Jules-S-Damji-51-320.jpg)
![scala> val strings = spark.read.text("../README.md")
strings: org.apache.spark.sql.DataFrame = [value: string]
scala> strings.show(10, false)
+------------------------------------------------------------------------------+
|value |
+------------------------------------------------------------------------------+
|# Apache Spark |
| |
|Spark is a unified analytics engine for large-scale data processing. It |
|provides high-level APIs in Scala, Java, Python, and R, and an optimized |
|engine that supports general computation graphs for data analysis. It also |
|supports a rich set of higher-level tools including Spark SQL for SQL and |
|DataFrames, MLlib for machine learning, GraphX for graph processing, |
| and Structured Streaming for stream processing. |
| |
|<https://spark.apache.org/> |
+------------------------------------------------------------------------------+
only showing top 10 rows
scala> strings.count()
res2: Long = 109
scala>
Quite simple. Let’s look at a similar example using the Python interpretive shell,
pyspark:
$ pyspark
Python 3.7.3 (default, Mar 27 2019, 09:23:15)
[Clang 10.0.1 (clang-1001.0.46.3)] on darwin
Type "help", "copyright", "credits" or "license" for more information.
WARNING: An illegal reflective access operation has occurred
WARNING: Illegal reflective access by org.apache.spark.unsafe.Platform
WARNING: Use --illegal-access=warn to enable warnings of further illegal
reflective access operations
WARNING: All illegal access operations will be denied in a future release
20/01/10 11:28:29 WARN NativeCodeLoader: Unable to load native-hadoop library
for your platform... using builtin-java classes where applicable
Using Spark's default log4j profile: org/apache/spark/log4j-defaults.properties
Setting default log level to "WARN".
To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use
setLogLevel(newLevel).
Welcome to
____ __
/ __/__ ___ _____/ /__
_ / _ / _ `/ __/ '_/
/__ / .__/_,_/_/ /_/_ version 3.0.0-preview2
/_/
Using Python version 3.7.3 (default, Mar 27 2019 09:23:15)
SparkSession available as 'spark'.
>>> strings = spark.read.text("../README.md")
24 | Chapter 2: Downloading Apache Spark and Getting Started](https://image.slidesharecdn.com/5592758-250520172834-b064bb3f/85/Learning-Spark-Lightningfast-Data-Analytics-2nd-Edition-Jules-S-Damji-52-320.jpg)