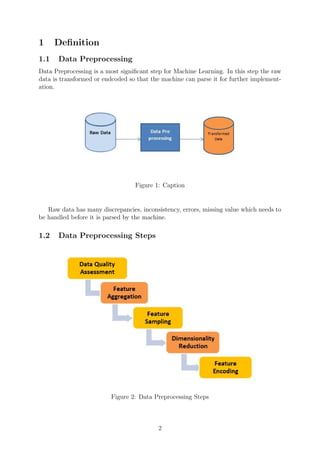
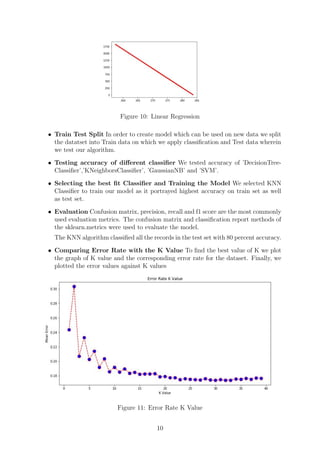
This document is a machine learning class assignment submitted by Trushita Redij to their supervisor Abhishek Kaushik at Dublin Business School. The assignment discusses data preprocessing techniques, decision trees, the Chinese Restaurant algorithm, and building supervised learning models. Specifically, linear regression and KNN classification models are implemented on population data from Ireland to predict total population and classify countries.










![References
[Wik19a] Wikipedia contributors, “Decision tree learning — Wikipedia, the free
encyclopedia,” 2019, [Online; accessed 17-December-2019]. [Online]. Avail-
able: https://en.wikipedia.org/w/index.php?title=Decision tree learning&
oldid=926138607
[Wik19b] ——, “Information gain in decision trees — Wikipedia, the free
encyclopedia,” 2019, [Online; accessed 18-December-2019]. [Online].
Available: https://en.wikipedia.org/w/index.php?title=Information gain in
decision trees&oldid=930926162
[Wik19c] ——, “Introduction to entropy — Wikipedia, the free encyclopedia,”
2019, [Online; accessed 18-December-2019]. [Online]. Available: https://en.
wikipedia.org/w/index.php?title=Introduction to entropy&oldid=926007171
11](https://image.slidesharecdn.com/10504099mlredijtrushita1-200713142138/85/Machine_Learning_Trushita-13-320.jpg)

































































