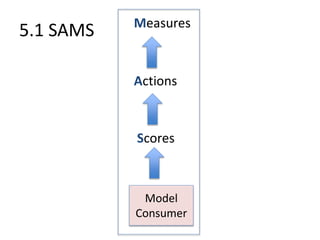
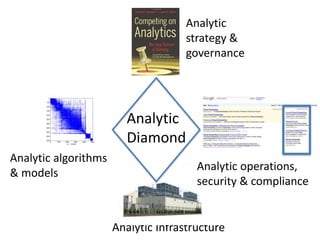
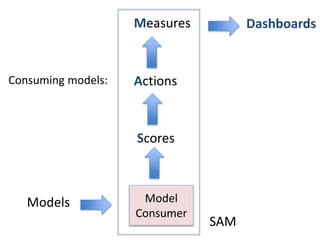
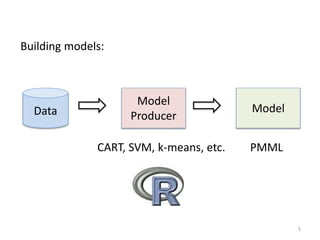
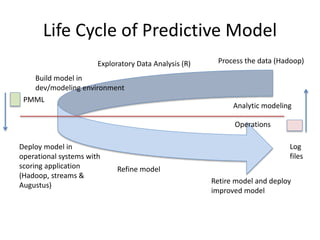
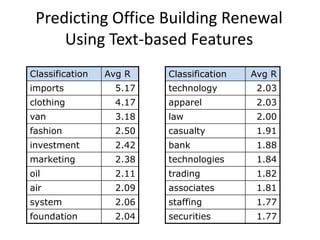
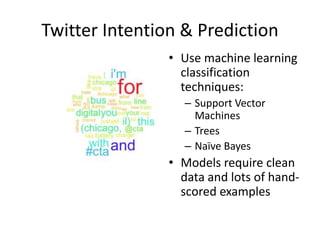
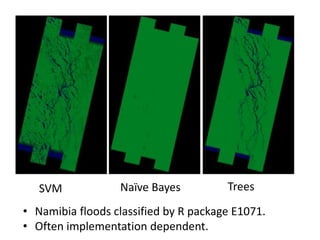
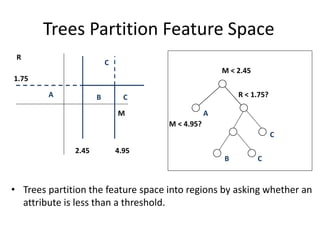
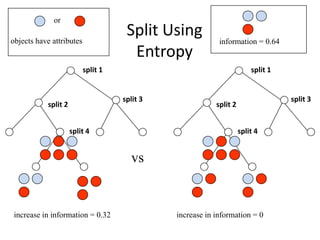
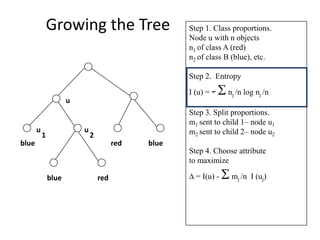
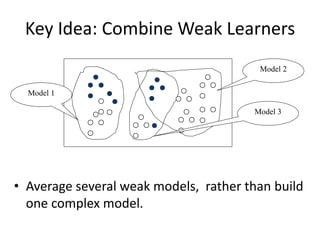
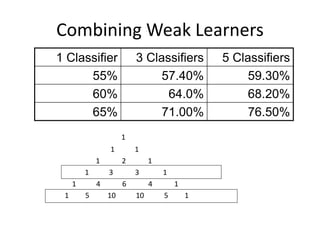
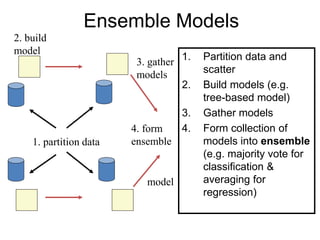
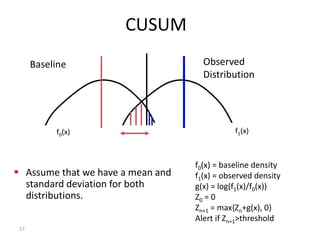
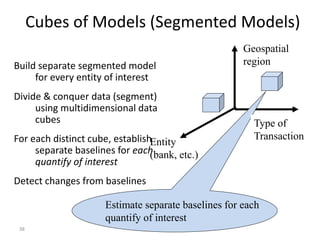
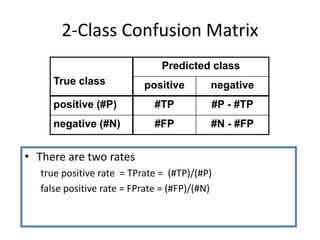
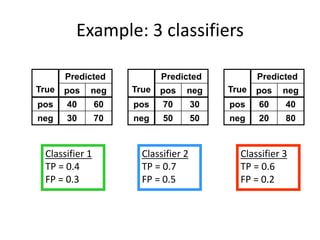
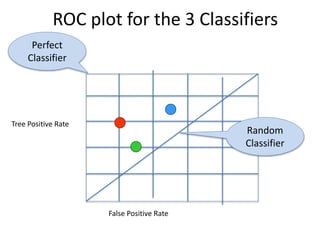
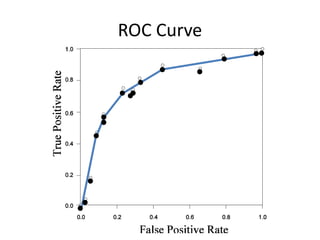
Robert Grossman and Collin Bennett of the Open Data Group discuss building and deploying big data analytic models. They describe the life cycle of a predictive model from exploratory data analysis to deployment and refinement. Key aspects include generating meaningful features from data, building and evaluating multiple models, and comparing models through techniques like confusion matrices and ROC curves to select the best performing model.









![Computing Count Distributions
def valueDistrib(b, field, select=None):
# given a dataframe b and an attribute field,
# returns the class distribution of the field
ccdict = {}
if select:
for i in select:
count = ccdict.get(b[i][field], 0)
ccdict[b[i][field]] = count + 1
else:
for i in range(len(b)):
count = ccdict.get(b[i][field], 0)
ccdict[b[i][field]] = count + 1
return ccdict](https://image.slidesharecdn.com/05-building-deploying-analytics-v2-170905012852/85/Building-and-deploying-analytics-17-320.jpg)
![Features
• Normalize
– [0, 1] or [-1, 1]
• Aggregate
• Discretize or bin
• Transform continuous to continuous or
discrete to discrete
• Compute ratios
• Use percentiles
• Use indicator variables](https://image.slidesharecdn.com/05-building-deploying-analytics-v2-170905012852/85/Building-and-deploying-analytics-18-320.jpg)




















































![[ppt]](https://cdn.slidesharecdn.com/ss_thumbnails/ppt2931-thumbnail.jpg?width=640&height=640&fit=bounds)
![[ppt]](https://cdn.slidesharecdn.com/ss_thumbnails/ppt3441-thumbnail.jpg?width=640&height=640&fit=bounds)





































