
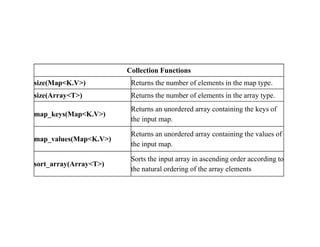
![String Functions
ascii(string str) Returns the numeric value of the first character of str.
character_length(string str) Returns the number of UTF-8 characters contained in str
concat(string|binary A, string|binary
B...)
Returns the string or bytes resulting from concatenating the
strings or bytes passed in as parameters in order.
find_in_set(string str, string strList)
Returns the first occurance of str in strList where strList is a
comma-delimited string.
length(string A) Returns the length of the string.
length(string A) Returns the length of the string.
locate(string substr, string str[, int pos])
Returns the position of the first occurrence of substr in str
after position pos.
lower(string A)
Returns the string resulting from converting all characters
to lower case.
ltrim(string A)
Returns the string resulting from trimming spaces from the
beginning(left hand side) of A.](https://image.slidesharecdn.com/bigdataanalyticshive-221128105444-dcdfb254/85/Big-Data-Analytics-Part2-13-320.jpg)



![Hive Builtin function examples
select reverse("ABCDEF"); // Returns FEDCBA
select rpad("UNITED",10,'0'); // Returns UNITED0000
select rpad("UNITED",10,' '); // Returns 'UNITED '
select rpad("UNITEDSTATES",10,'0'); // Returns UNITEDSTAT
select rpad("UNITEDSTATES",10,'0'); // Returns UNITEDSTAT
select rpad("UNITEDSTATES",10,null); // Returns NULL
select space(10); // Returns ' '
select split("USA IS A PLACE"," "); // Returns: ["USA","IS","A","PLACE"]
select substr("USA IS A PLACE",5,2); // Returns IS
select substr("USA IS A PLACE",5,100); // Returns IS A PLACE
select upper("unitedstates"); // Returns UNITEDSTATES](https://image.slidesharecdn.com/bigdataanalyticshive-221128105444-dcdfb254/85/Big-Data-Analytics-Part2-17-320.jpg)

![Hive Builtin function examples
select reverse('Hadoop'); // OK poodaH
select split('hadoop~supports~split~function','~');
// ["hadoop","supports","split","function"]
// ["hadoop","supports","split","function"]
select max(Salary) from employee_data;
select min(Salary) from employee_data;
select Id, upper(Name) from employee_data;
select Id, lower(Name) from employee_data;](https://image.slidesharecdn.com/bigdataanalyticshive-221128105444-dcdfb254/85/Big-Data-Analytics-Part2-19-320.jpg)



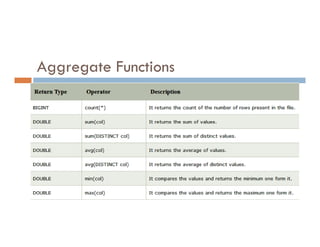


![select reverse("ABCDEF"); // Returns FEDCBA
select rpad("UNITED",10,'0'); // Returns UNITED0000
select rpad("UNITED",10,' '); // Returns 'UNITED
select rpad("UNITEDSTATES",10,'0'); // Returns UNITEDSTAT
select rpad("UNITEDSTATES",10,'0'); // Returns UNITEDSTAT
select rpad("UNITEDSTATES",10,null); // Returns NULL
select space(10); ==> Returns ' '
select split("USA IS A PLACE"," "); // Returns: ["USA","IS","A","PLACE"]
select substr("USA IS A PLACE",5,2); // Returns IS
select substr("USA IS A PLACE",5,100); // Returns IS A PLACE
select upper("unitedstates"); // Returns UNITEDSTATES](https://image.slidesharecdn.com/bigdataanalyticshive-221128105444-dcdfb254/85/Big-Data-Analytics-Part2-27-320.jpg)

![select reverse('Hadoop'); // OK poodaH
select split('hadoop~supports~split~function','~');
// ["hadoop","supports","split","function"]
// ["hadoop","supports","split","function"]
select max(Salary) from employee_data;
select min(Salary) from employee_data;
select Id, upper(Name) from employee_data;
select Id, lower(Name) from employee_data;](https://image.slidesharecdn.com/bigdataanalyticshive-221128105444-dcdfb254/85/Big-Data-Analytics-Part2-29-320.jpg)

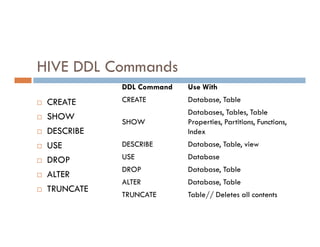


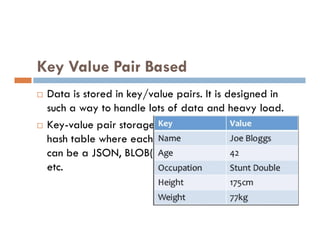
![HiveQL Data Manipulation
Load
Student_data.txt
LOAD statement in Hive is used to move
data files into the locations corresponding
to Hive tables
to Hive tables
LOAD DATA [LOCAL] INPATH 'hdfsfilepath/localfilepath'
[OVERWRITE] INTO TABLE existing_table_name](https://image.slidesharecdn.com/bigdataanalyticshive-221128105444-dcdfb254/85/Big-Data-Analytics-Part2-34-320.jpg)
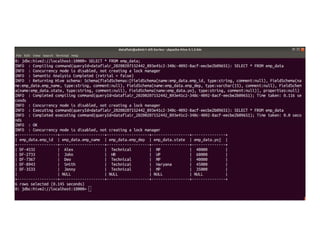
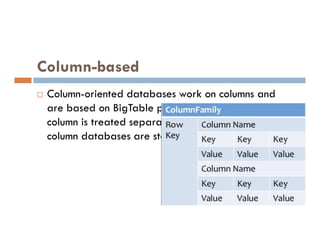
![INSERT Command
INSERT command in Hive loads the data into a Hive
table.
INSERT INTO TABLE tablename1 [PARTITION
INSERT INTO TABLE tablename1 [PARTITION
(partcol1=val1, partcol2=val2 ...)] select_statement1
FROM from_statement;](https://image.slidesharecdn.com/bigdataanalyticshive-221128105444-dcdfb254/85/Big-Data-Analytics-Part2-36-320.jpg)
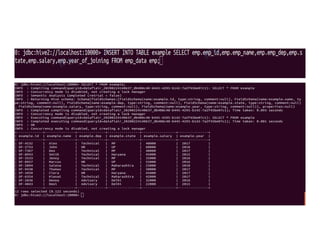
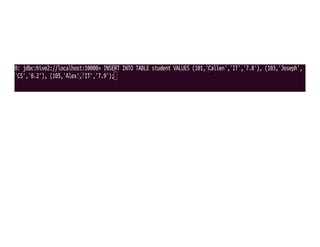
![DELETE command
DELETE statement in Hive deletes the table data. If
the WHERE clause is specified, then it deletes the
rows that satisfy the condition in where clause.
rows that satisfy the condition in where clause.
DELETE FROM tablename [WHERE expression];
DELETE FROM student WHERE roll_no=104;](https://image.slidesharecdn.com/bigdataanalyticshive-221128105444-dcdfb254/85/Big-Data-Analytics-Part2-39-320.jpg)













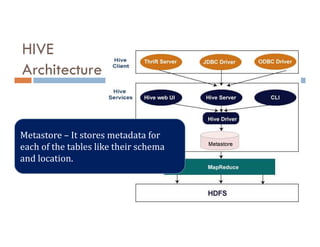
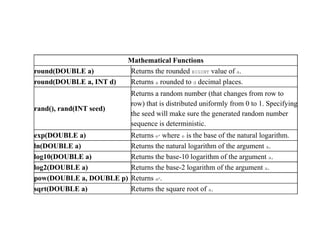
This document provides an overview of Apache Hive, including its architecture and features. It states that Hive is an open source data warehouse system built on Hadoop that allows users to query large datasets using SQL-like queries. It is used for analyzing structured data and is best suited for batch jobs. The document then discusses Hive's architecture, including its drivers, metastore, and Thrift interface. It also provides examples of built-in functions in Hive for mathematical operations, string manipulation, and more. Finally, it covers Hive commands for DDL, DML, and querying data.