Download as PDF, PPTX







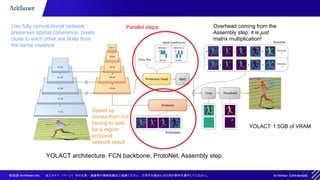



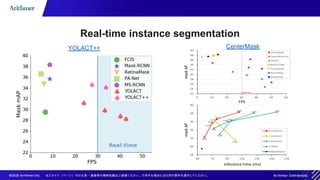
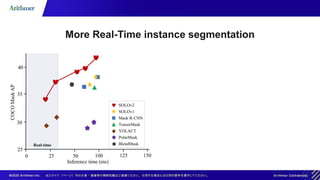

The document outlines methodologies for real-time instance segmentation, highlighting the use of Mask R-CNN and YOLACT models for detecting and delineating objects in images. It details the differences between the two-step approach of Mask R-CNN and the single-step approach of YOLACT, emphasizing the advantages of each technique in terms of speed and efficiency. Additionally, it references related works and resources for implementing instance segmentation using open-source toolkits.

![[DL輪読会]PointNet++: Deep Hierarchical Feature Learning on Point Sets in a Metr...](https://cdn.slidesharecdn.com/ss_thumbnails/181214dlpointnet-181214053349-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DL輪読会]Real-Time Semantic Stereo Matching](https://cdn.slidesharecdn.com/ss_thumbnails/real-timesemanticstereomatching-sugisakihiroaki-191213003224-thumbnail.jpg?width=640&height=640&fit=bounds)









![[DL輪読会]Deep High-Resolution Representation Learning for Human Pose Estimation](https://cdn.slidesharecdn.com/ss_thumbnails/20190517hrnet-190517005504-thumbnail.jpg?width=640&height=640&fit=bounds)




![SSII2021 [OS2-01] 転移学習の基礎:異なるタスクの知識を利用するための機械学習の方法](https://cdn.slidesharecdn.com/ss_thumbnails/os2-02final-210610091211-thumbnail.jpg?width=640&height=640&fit=bounds)



































































