Downloaded 181 times




























![Create a retention policy
CREATE RETENTION POLICY <rp-name> ON <db-name>
DURATION <duration> REPLICATION <n> [DEFAULT]](https://image.slidesharecdn.com/89qtwk1qg6fszvm0ylfg-signature-208f05d9bddab202564a85bd534c6dce9d0347af1b41147dab22e1baf53fe31d-poli-150725000729-lva1-app6891/85/Time-Series-Data-with-InfluxDB-34-320.jpg)
![Create a retention policy
CREATE RETENTION POLICY <rp-name> ON <db-name>
DURATION <duration> REPLICATION <n> [DEFAULT]
CREATE RETENTION POLICY high_precision ON mydb
DURATION 7d REPLICATION 3 DEFAULT](https://image.slidesharecdn.com/89qtwk1qg6fszvm0ylfg-signature-208f05d9bddab202564a85bd534c6dce9d0347af1b41147dab22e1baf53fe31d-poli-150725000729-lva1-app6891/85/Time-Series-Data-with-InfluxDB-35-320.jpg)
![Create a retention policy
CREATE RETENTION POLICY <rp-name> ON <db-name>
DURATION <duration> REPLICATION <n> [DEFAULT]
CREATE RETENTION POLICY high_precision ON mydb
DURATION 7d REPLICATION 3 DEFAULT
Writes will go into this RP unless
otherwise specified](https://image.slidesharecdn.com/89qtwk1qg6fszvm0ylfg-signature-208f05d9bddab202564a85bd534c6dce9d0347af1b41147dab22e1baf53fe31d-poli-150725000729-lva1-app6891/85/Time-Series-Data-with-InfluxDB-36-320.jpg)






















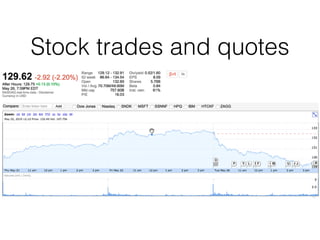
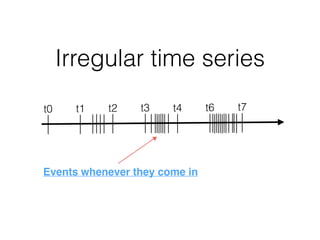
This document discusses working with time series data using InfluxDB. It provides an overview of time series data and why InfluxDB is useful for storing and querying it. Key features of InfluxDB covered include its SQL-like query language, retention policies for managing data storage, continuous queries for aggregation, and tools for data collection, visualization and monitoring.





















































![Paul Dix [InfluxData] The Journey of InfluxDB | InfluxDays 2022](https://cdn.slidesharecdn.com/ss_thumbnails/2022-11-02influxdays-journeyofinfluxdb-221020214252-ff7c76c5-thumbnail.jpg?width=640&height=640&fit=bounds)








![Paul Dix [InfluxData] | InfluxDays Opening Keynote | InfluxDays Virtual Exper...](https://cdn.slidesharecdn.com/ss_thumbnails/2020-11-10influxdays-introducinginfluxdbiox-201110182839-thumbnail.jpg?width=640&height=640&fit=bounds)






































![5G Explained! A High Level Overview [Introduction]](https://cdn.slidesharecdn.com/ss_thumbnails/5gexplainedahighleveloverview-260119165306-cc137a3e-thumbnail.jpg?width=640&height=640&fit=bounds)





