Download as PDF, PPTX








![GETTING STARTED
curl -X POST
-d '[
{
"name" : "hd_used",
"columns" : ["value", "host", "mount"],
"points" : [
[23.2, "serverA", "/mnt"]
]
}
]'
'http://localhost:8086/db/mydb/series?u=root&p=root'](https://image.slidesharecdn.com/influxdb-timeseriesdatabase5-141008043855-conversion-gate02/85/Time-series-database-InfluxDB-PHP-11-320.jpg)
![MORE POINTS FOR INSERT
[
{
"name": "log_lines",
"columns": ["time", "sequence_number", "line"],
"points": [
[1400425947368, 1, "this line is first"],
[1400425947368, 2, "and this is second"]
]
}
]](https://image.slidesharecdn.com/influxdb-timeseriesdatabase5-141008043855-conversion-gate02/85/Time-series-database-InfluxDB-PHP-12-320.jpg)
![IMPLEMENT UDP
PROTOCOL
[input_plugins.udp]
enabled = true
port = 4444
database = "search"
InfluxDB is down? Your APP works!](https://image.slidesharecdn.com/influxdb-timeseriesdatabase5-141008043855-conversion-gate02/85/Time-series-database-InfluxDB-PHP-13-320.jpg)
![BENCHMARK UDP VS TCP
CorleyBenchmarksInfluxDBAdapterEvent
Method Name Iterations Average Time Ops/second
------------------------ ------------ -------------- -------------
sendDataUsingHttpAdapter: [1,000 ] [0.0026700308323] [374.52751]
sendDataUsingUdpAdapter : [1,000 ] [0.0000436344147] [22,917.69026]](https://image.slidesharecdn.com/influxdb-timeseriesdatabase5-141008043855-conversion-gate02/85/Time-series-database-InfluxDB-PHP-14-320.jpg)
![QUERY
curl 'http://localhost:8086?u=root&p=root&q=select * from log_lines limit 1'
[
{
"name": "log_lines",
"columns": ["time", "sequence_number", "line"],
"points": [
[1400425947368, 287780001, "here's some useful log info"]
]
}
]](https://image.slidesharecdn.com/influxdb-timeseriesdatabase5-141008043855-conversion-gate02/85/Time-series-database-InfluxDB-PHP-15-320.jpg)






![FACTORY PATTERN
$options = [
"adapter" => [
"name" => "InfluxDBAdapterGuzzleAdapter",
"options" => [
// guzzle options
],
],
"options" => [
"host" => "my.influx.domain.tld",
],
"filters" => [
"query" => [
"name" => "InfluxDBFilterColumnsPointsFilter"
],
],
];
$client = InfluxDBClientFactory::create($options);](https://image.slidesharecdn.com/influxdb-timeseriesdatabase5-141008043855-conversion-gate02/85/Time-series-database-InfluxDB-PHP-24-320.jpg)
![MARK YOUR EVENT
$client->mark("error.404", ["page" => "/a-missing-page"]);
$client->mark("app.search", $points, "s");](https://image.slidesharecdn.com/influxdb-timeseriesdatabase5-141008043855-conversion-gate02/85/Time-series-database-InfluxDB-PHP-25-320.jpg)




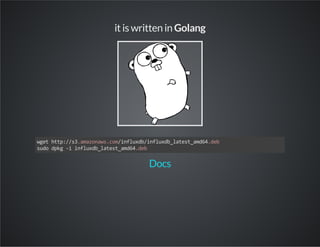
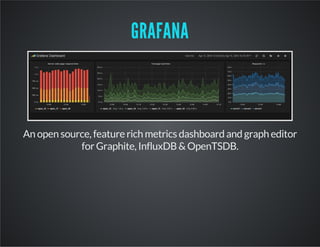
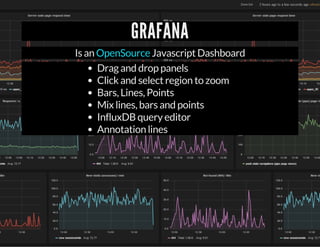
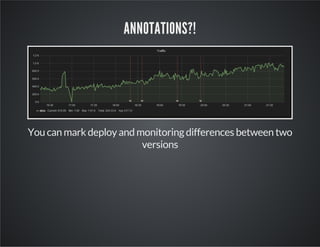
This document discusses InfluxDB, an open-source time series database. It stores time stamped numeric data in structures called time series. The document provides an overview of time series data, describes how to install and use InfluxDB, and discusses features like its HTTP API, client libraries, Grafana integration for visualization, and benchmark results showing it has better performance for time series data than other databases.




















































![Paul Dix [InfluxData] The Journey of InfluxDB | InfluxDays 2022](https://cdn.slidesharecdn.com/ss_thumbnails/2022-11-02influxdays-journeyofinfluxdb-221020214252-ff7c76c5-thumbnail.jpg?width=640&height=640&fit=bounds)




![Dean Sheehan [InfluxData] | InfluxDB Time Series Engine Overview | InfluxDays...](https://cdn.slidesharecdn.com/ss_thumbnails/dem10timeseriesengineoverviewdeansheehan-221020205424-fa16f7e9-thumbnail.jpg?width=640&height=640&fit=bounds)

















































