



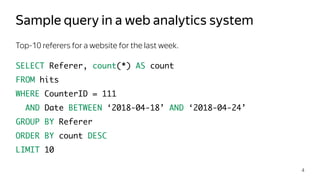





![How to keep the table sorted
13
Insertion number
Primary key
Part
[M, N]
Part
[N+1]
Merge in the background
M N N+1](https://image.slidesharecdn.com/milovidovpl18internals-180502184851/85/ClickHouse-Deep-Dive-by-Aleksei-Milovidov-13-320.jpg)
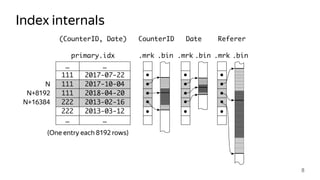
![How to keep the table sorted
14
Part
[M, N+1]
Insertion number
Primary key
M N+1](https://image.slidesharecdn.com/milovidovpl18internals-180502184851/85/ClickHouse-Deep-Dive-by-Aleksei-Milovidov-14-320.jpg)





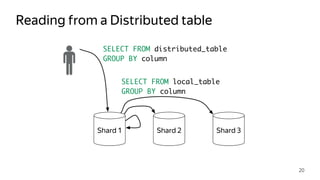
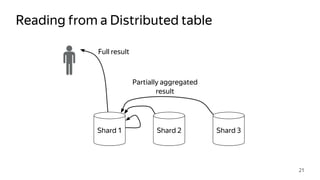

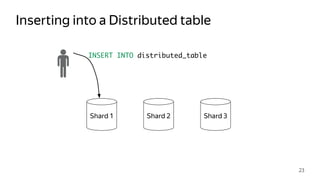
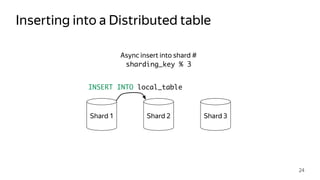
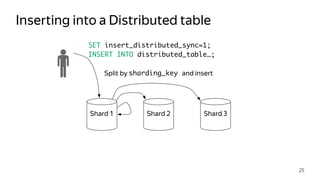



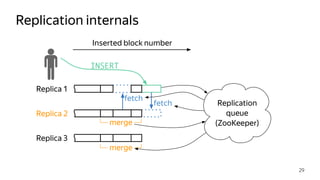

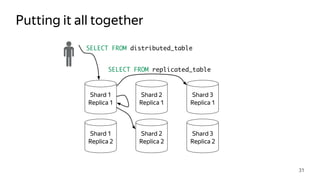




This document provides an overview of ClickHouse, an open source column-oriented database management system. It discusses ClickHouse's ability to handle high volumes of event data in real-time, its use of the MergeTree storage engine to sort and merge data efficiently, and how it scales through sharding and distributed tables. The document also covers replication using the ReplicatedMergeTree engine to provide high availability and fault tolerance.



































![[Meetup] a successful migration from elastic search to clickhouse](https://cdn.slidesharecdn.com/ss_thumbnails/meetupasuccessfulmigrationfromelasticsearchtoclickhouse-191004114403-thumbnail.jpg?width=640&height=640&fit=bounds)



















































