Downloaded 19 times





![The Line Protocol
• Self describing data
– Points are written to InfluxDB using the Line Protocol, which follows the following format:
<measurement>[,<tag-key>=<tag-value>] [<field-key>=<field-value>] [unix-nano-timestamp]
– This provides extremely high flexibility as new metrics are identified for collection into
InfluxDB. New measure to capture? Just send it to InfluxDB. It’s that easy.
cpu_load,hostname=server02,az=us_west usage_user=24.5,usage_idle=15.3 1234567890000000
Measurement
Tag
Set
Field Set
Timestamp](https://image.slidesharecdn.com/influxdayslondonoptimizinginflux-180619163927/85/OPTIMIZING-THE-TICK-STACK-5-320.jpg)

![What if my plugin sends data like that to InfluxDB?
Write something that sits between your plugin and InfluxDB to sanitize the data OR
use one of our write plugins:
Example - Telegraf’s Graphite input plugin: Takes input like…
…and parses it with the following template…
…resulting in the following points in line protocol hitting the database:
sensu.metric.net.server0.eth0.rx_packets 461295119435 1444234982
sensu.metric.net.server0.eth0.tx_bytes 1093086493388480 1444234982
sensu.metric.net.server0.eth0.rx_bytes 1015633926034834 1444234982
["sensu.metric.* ..measurement.host.interface.field"]
net,host=server0,interface=eth0 rx_packets=461295119435 1444234982
net,host=server0,interface=eth0 tx_bytes=1093086493388480 1444234982
net,host=server0,interface=eth0 rx_bytes=1015633926034834 1444234982](https://image.slidesharecdn.com/influxdayslondonoptimizinginflux-180619163927/85/OPTIMIZING-THE-TICK-STACK-7-320.jpg)
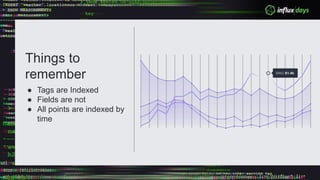
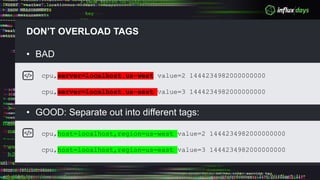
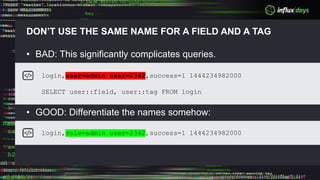
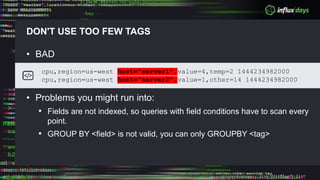




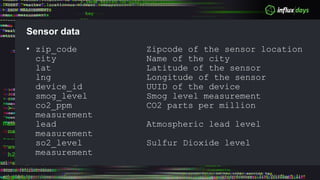
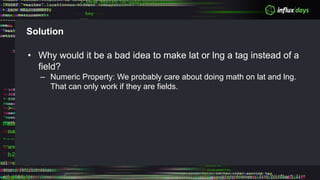
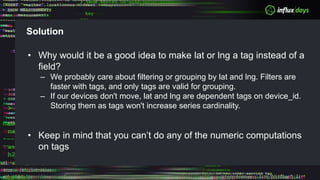
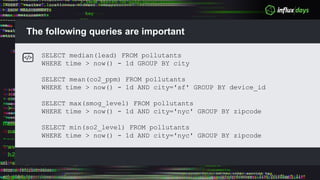
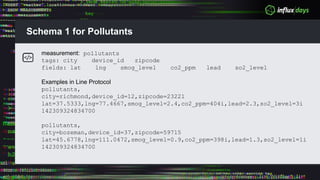
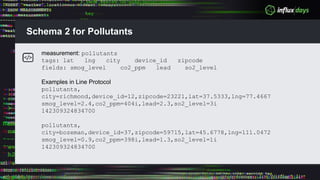
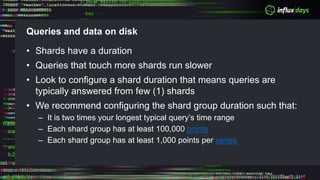
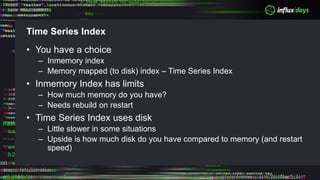
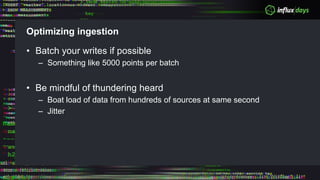




The document outlines a workshop agenda for new practitioners focusing on the Tick Stack, including sessions on installation, writing queries, architecting InfluxEnterprise, and optimizing data ingestion. It emphasizes best practices for data schema design within InfluxDB, particularly regarding the use of tags and fields, and provides examples related to IoT applications and air quality monitoring. Key considerations include the impact of schema on queries, the importance of optimizing data ingestion, and strategies for efficient query performance.




![Frossie Economou & Angelo Fausti [Vera C. Rubin Observatory] | How InfluxDB H...](https://cdn.slidesharecdn.com/ss_thumbnails/veracrubininfluxdays2020-201111202349-thumbnail.jpg?width=640&height=640&fit=bounds)


























![Paul Dix [InfluxData] The Journey of InfluxDB | InfluxDays 2022](https://cdn.slidesharecdn.com/ss_thumbnails/2022-11-02influxdays-journeyofinfluxdb-221020214252-ff7c76c5-thumbnail.jpg?width=640&height=640&fit=bounds)































![Ward Bowman [PTC] | ThingWorx Long-Term Data Storage with InfluxDB | InfluxDa...](https://cdn.slidesharecdn.com/ss_thumbnails/influxdays-221027185325-5d2f430b-thumbnail.jpg?width=640&height=640&fit=bounds)
![Scott Anderson [InfluxData] | New & Upcoming Flux Features | InfluxDays 2022](https://cdn.slidesharecdn.com/ss_thumbnails/influxdays2022-fluxupdates-scott-221021210238-9d323cba-thumbnail.jpg?width=640&height=640&fit=bounds)
![Steinkamp, Clifford [InfluxData] | Closing Thoughts | InfluxDays 2022](https://cdn.slidesharecdn.com/ss_thumbnails/influxdays2022closingthoughtsday2-221020220104-abde55ea-thumbnail.jpg?width=640&height=640&fit=bounds)
![Steinkamp, Clifford [InfluxData] | Welcome to InfluxDays 2022 - Day 2 | Influ...](https://cdn.slidesharecdn.com/ss_thumbnails/influxdays2022welcometoday2-221020215815-c8463942-thumbnail.jpg?width=640&height=640&fit=bounds)
![Steinkamp, Clifford [InfluxData] | Closing Thoughts Day 1 | InfluxDays 2022](https://cdn.slidesharecdn.com/ss_thumbnails/influxdays2022closingthoughtsday1-221020215301-f8040e1f-thumbnail.jpg?width=640&height=640&fit=bounds)



