1. Represents text documents as graph-of-words and extracts subgraph features through frequent subgraph mining to classify texts as a graph classification problem.
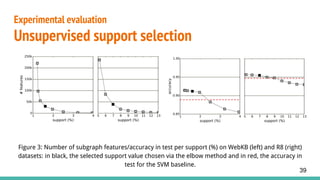
2. Uses gSpan algorithm to efficiently mine frequent subgraphs from the graph-of-words and selects the optimal minimum support threshold using the elbow method.
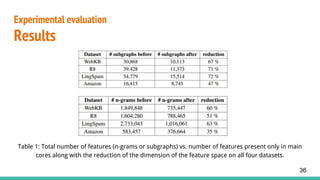
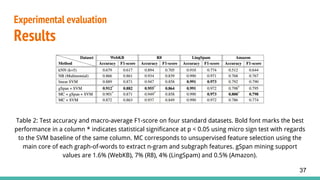
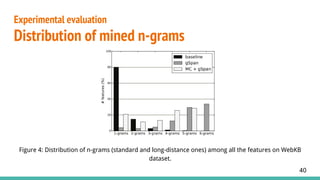
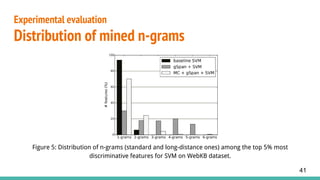
3. Evaluates the approach on four datasets, achieving improved accuracy over bag-of-words models by extracting long-distance n-gram features through subgraph mining.





![Introduction
Bag-of-words and its issues
Example
“He likes watching action movies, she likes watching romantic movies”
⇒ [ “He”, “likes”, “watching”, “action”, “movies”, “she”, “likes”, “watching”,
“romantic”, “movies” ].
The sentence has 10 distinct words, by using indexes of the list, it can be
represented by a 10-entry vector: [ 1, 2, 2, 1, 2, 1, 2, 2, 1, 2 ]
6](https://image.slidesharecdn.com/xrrcbmotwe95zgabgzqw-signature-15f02179727776564e4b757d9d178679a476841c3ef701289bc70548e48e4b91-poli-160425172918/85/Text-categorization-as-a-graph-6-320.jpg)