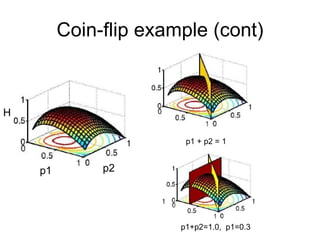
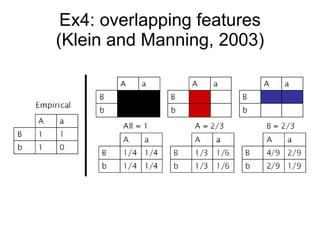
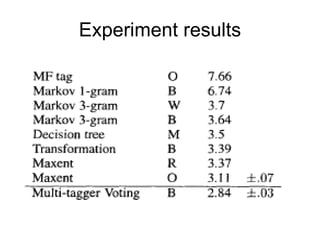
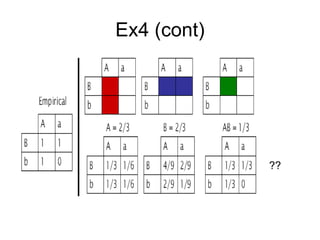
This document discusses maximum entropy models and their application to natural language processing tasks. It introduces maximum entropy modeling, describing how the approach works by choosing a probability distribution with maximum entropy subject to constraints from observed data. Training involves using algorithms like generalized iterative scaling to find optimal feature weights that satisfy the constraints. Maximum entropy models have been applied successfully to tasks like part-of-speech tagging, machine translation, and language modeling.

























































































































![[ppt]](https://cdn.slidesharecdn.com/ss_thumbnails/ppt2931-thumbnail.jpg?width=640&height=640&fit=bounds)



















