Download as PDF, PPTX































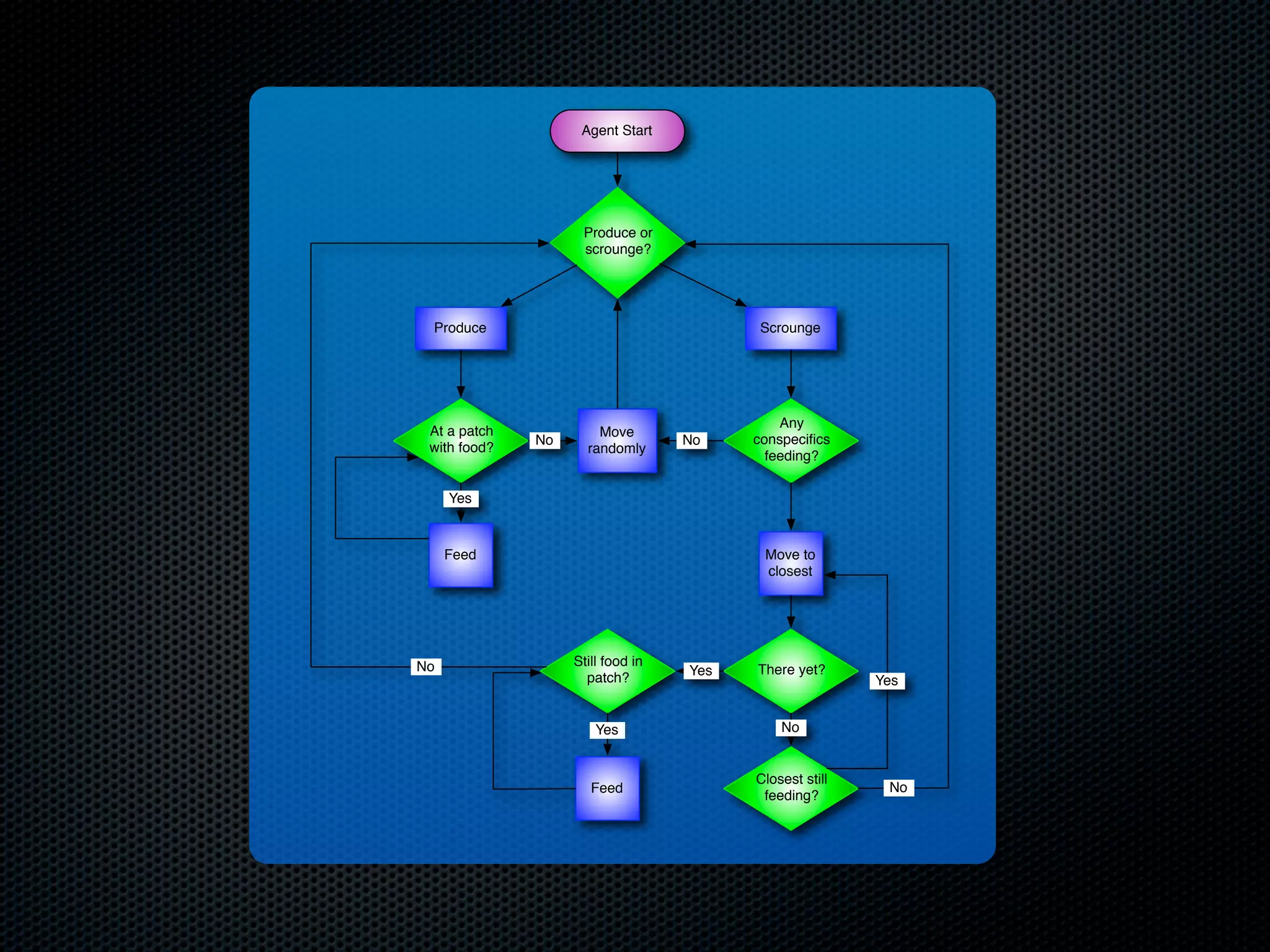
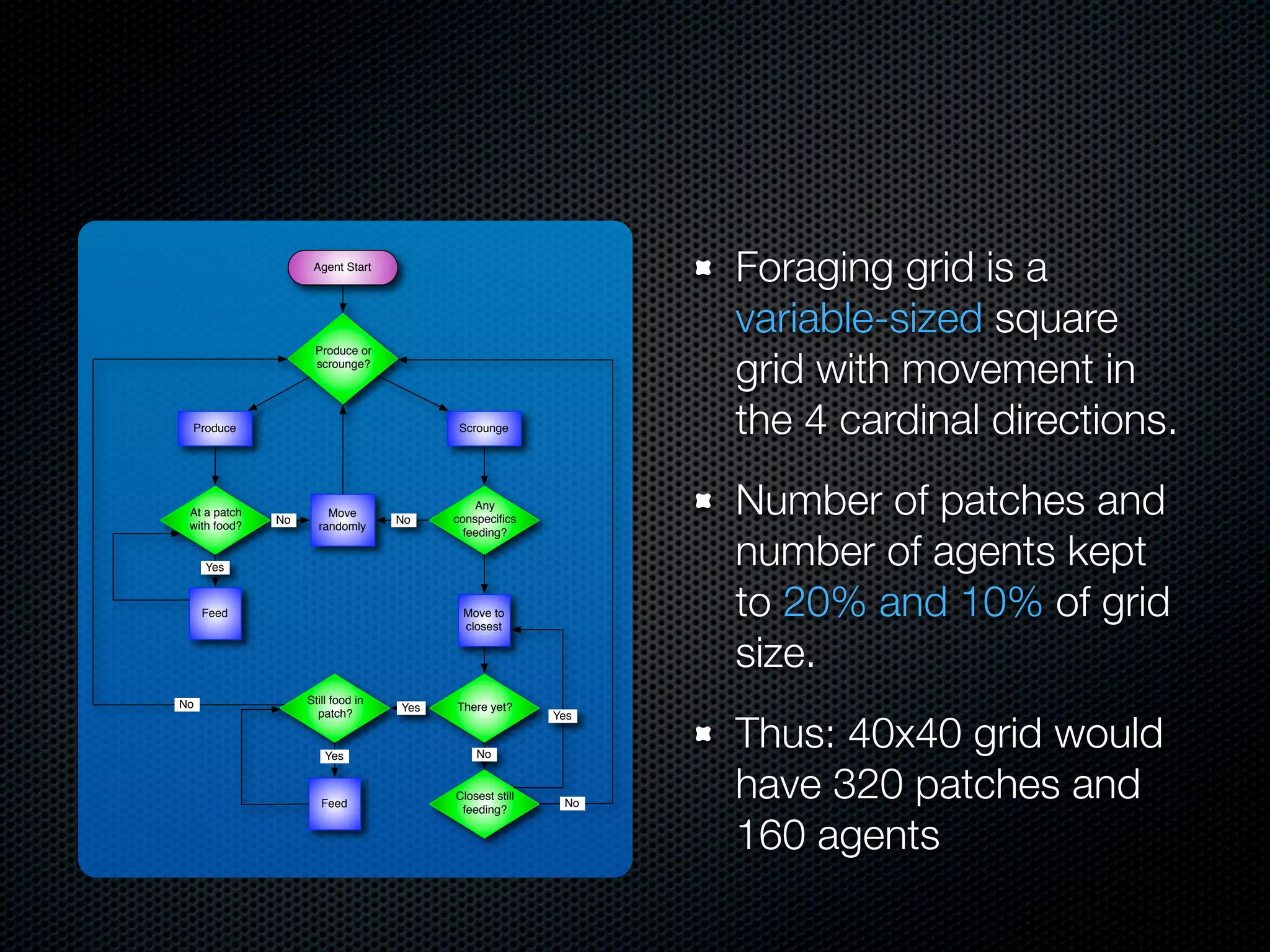

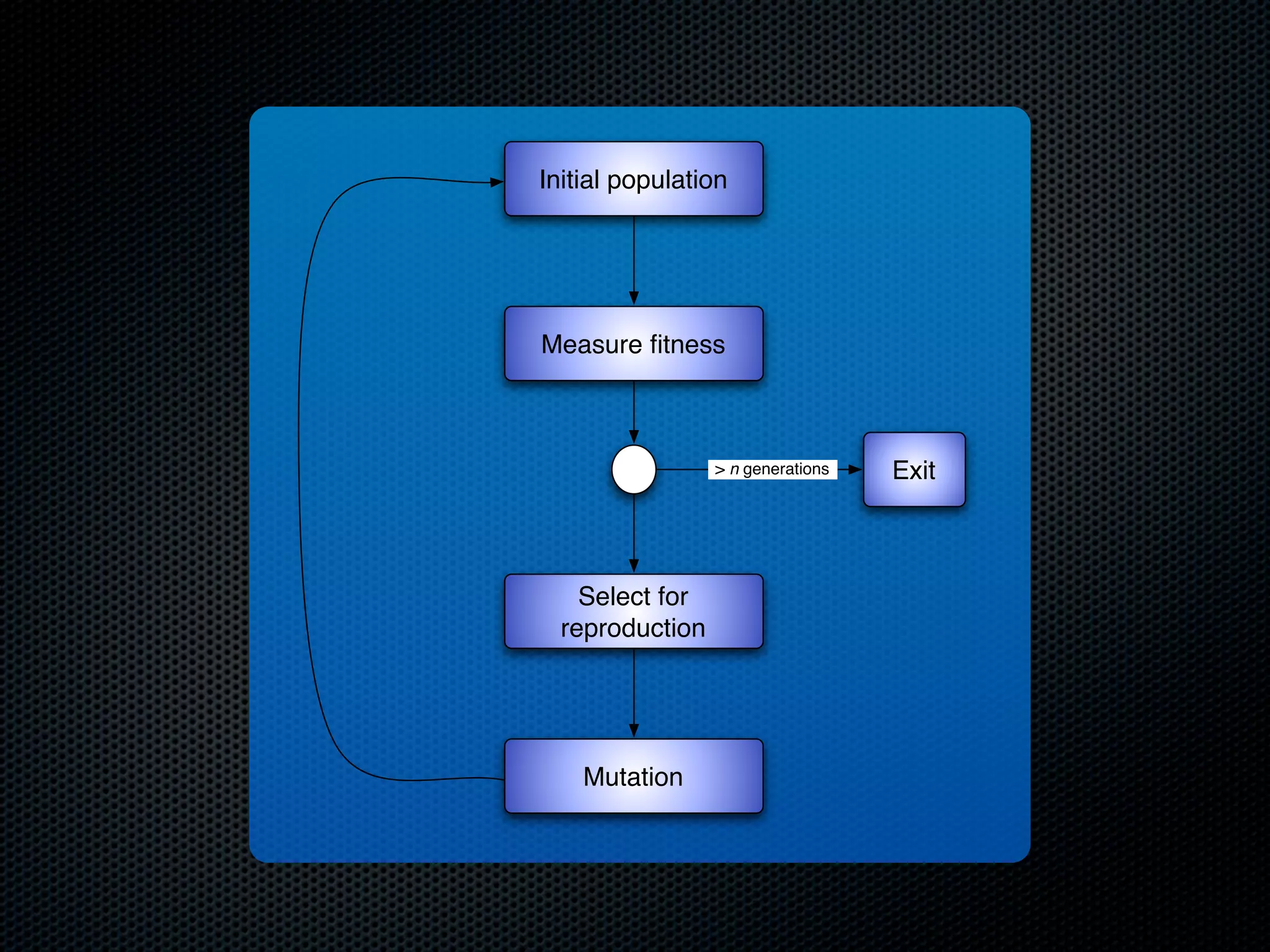
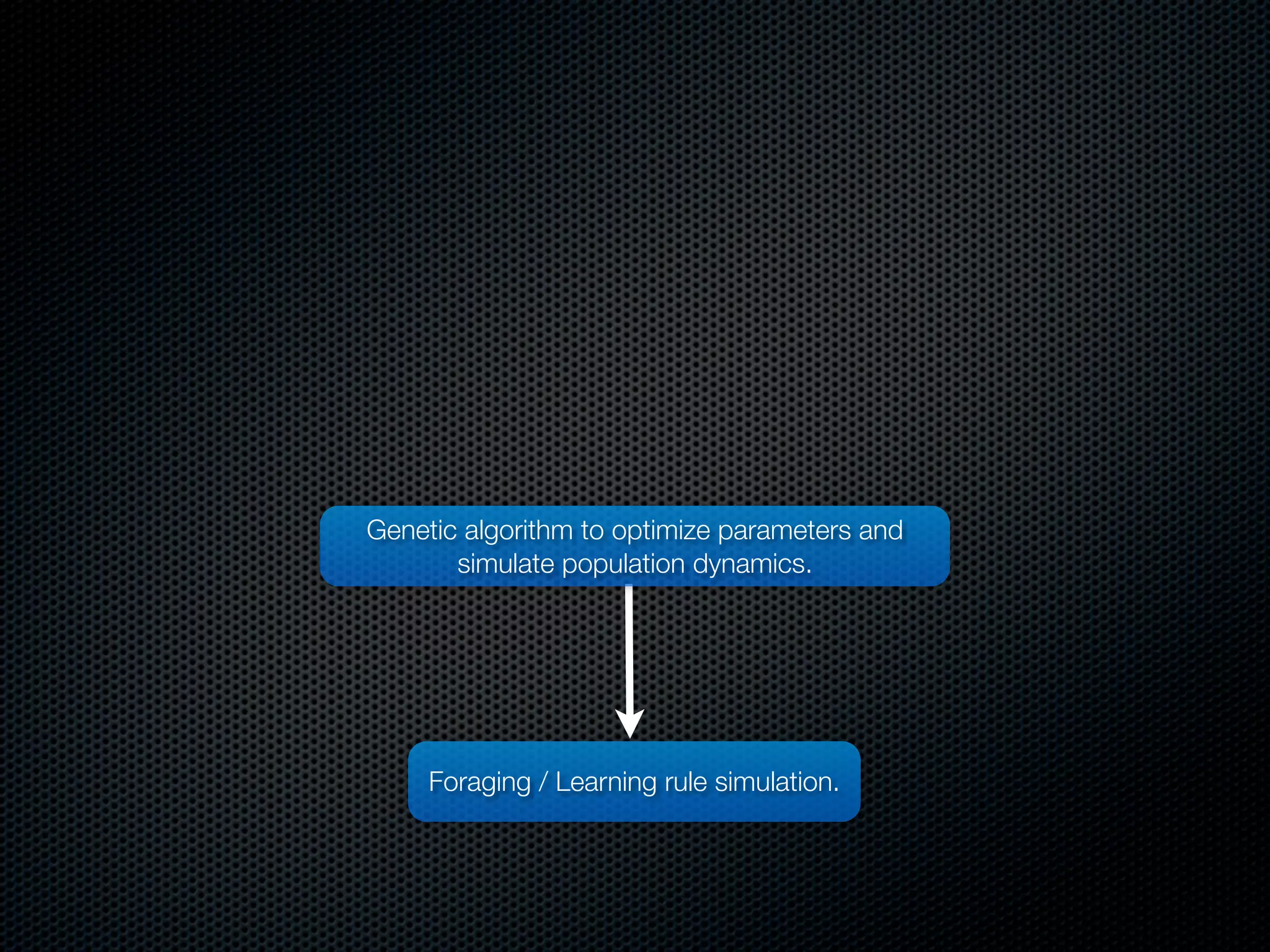





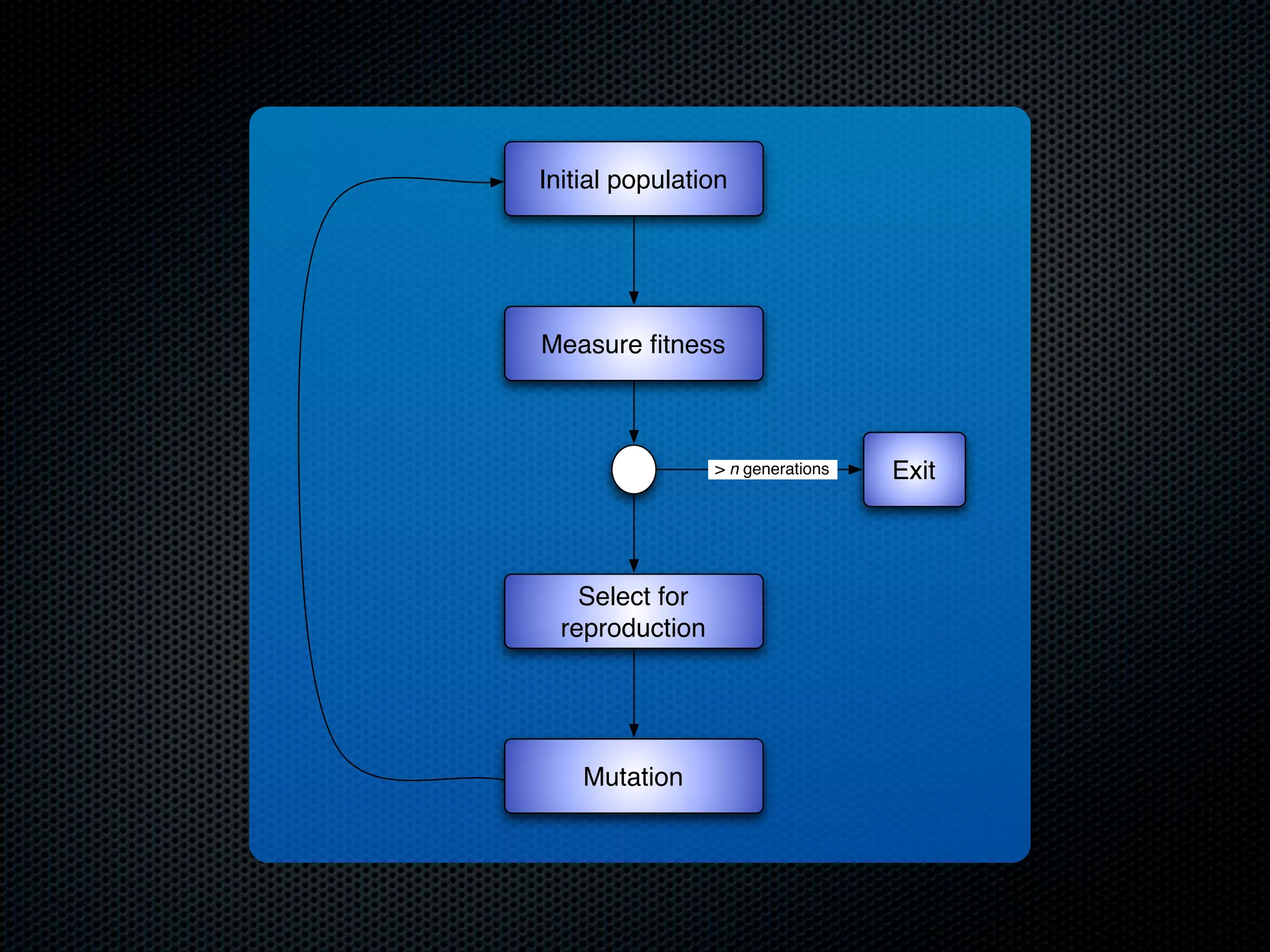
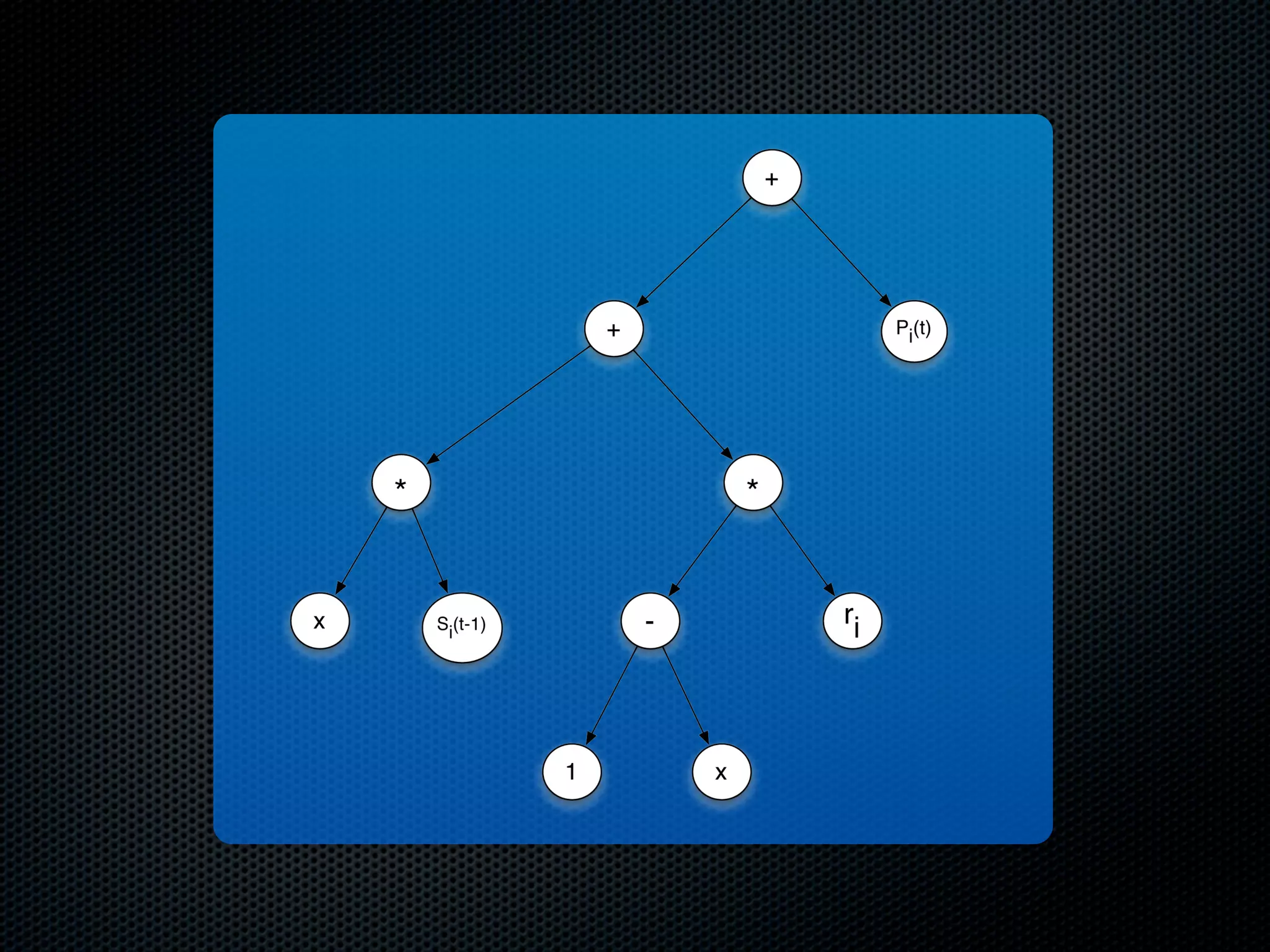
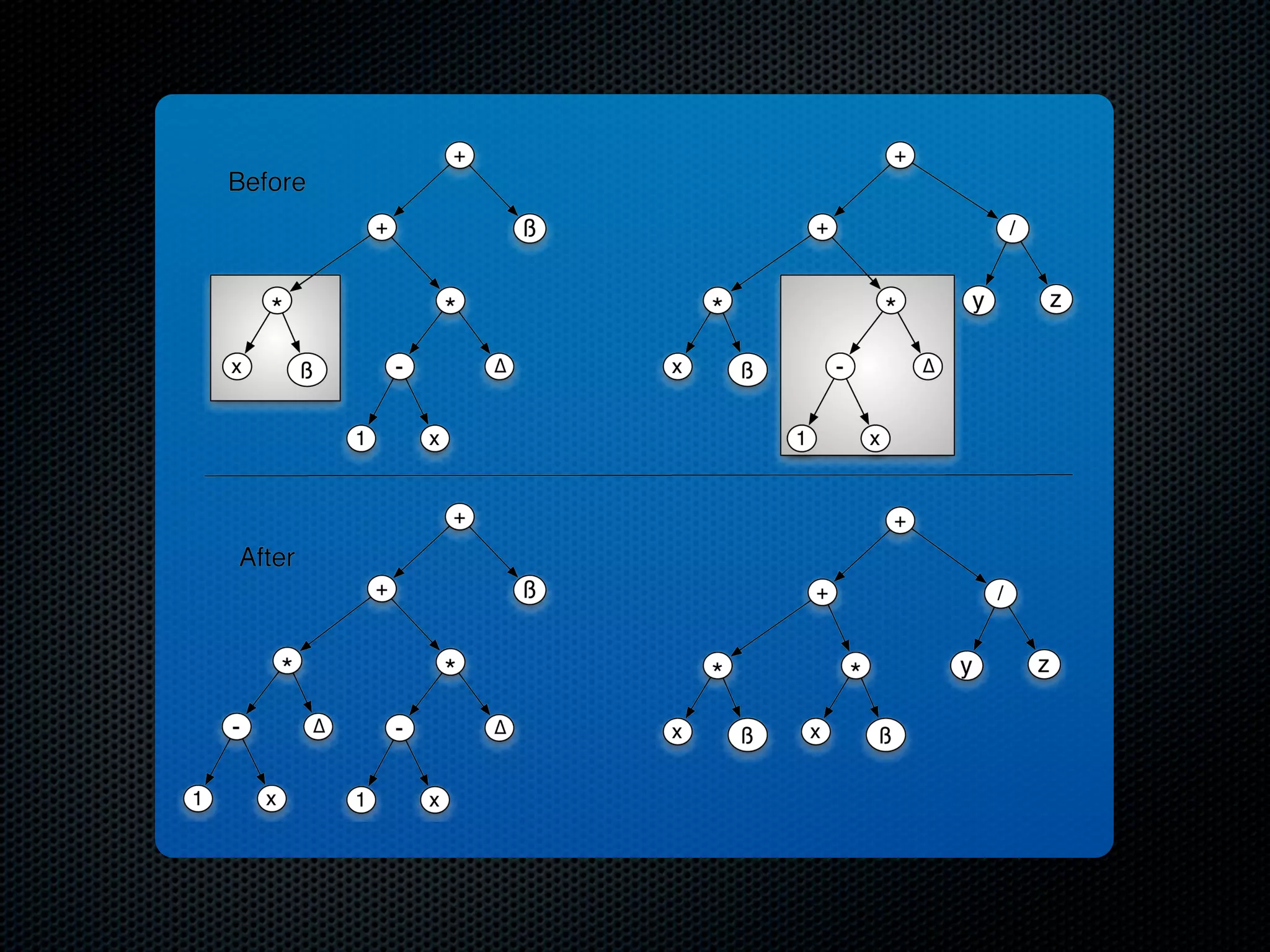
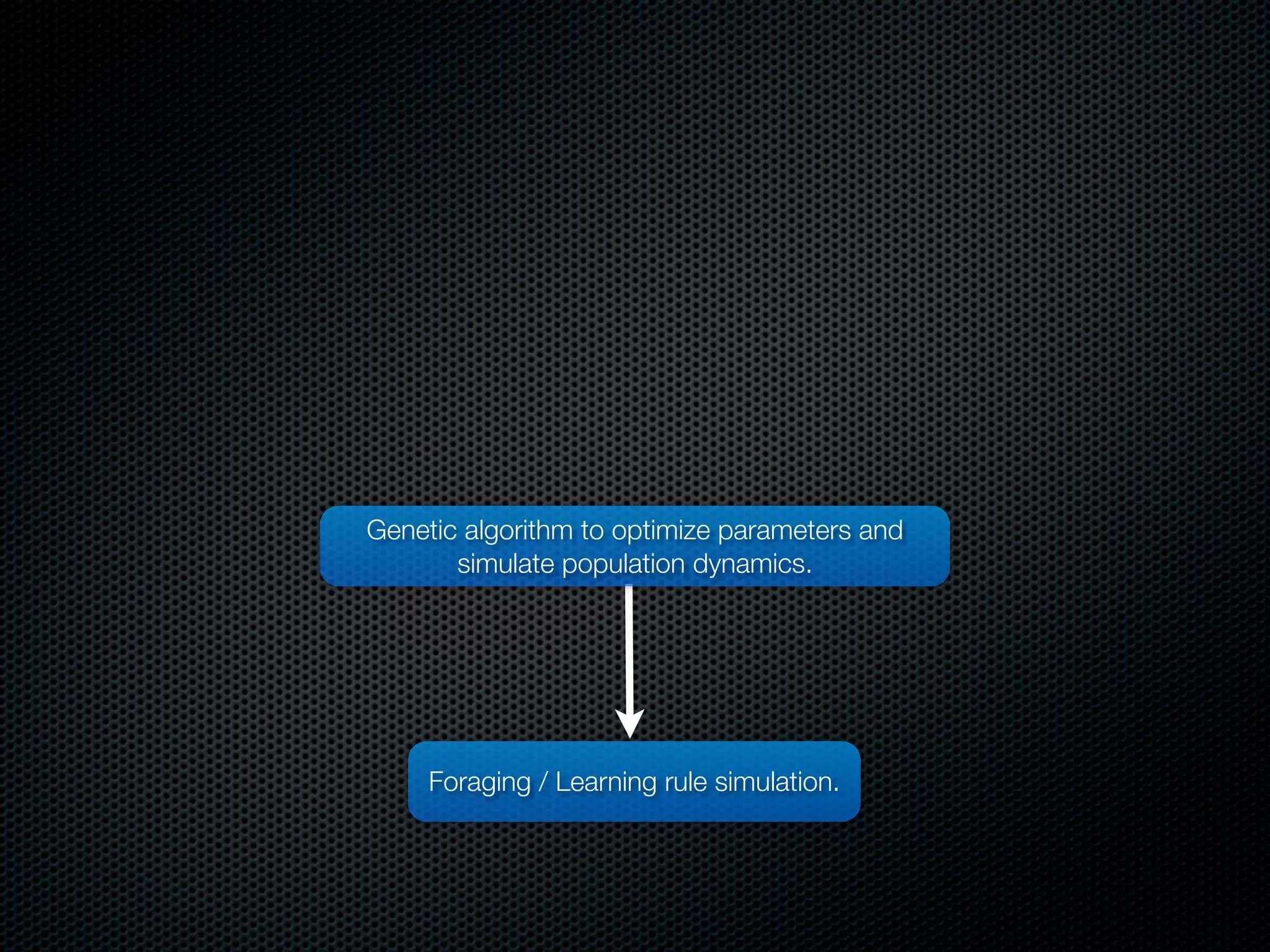
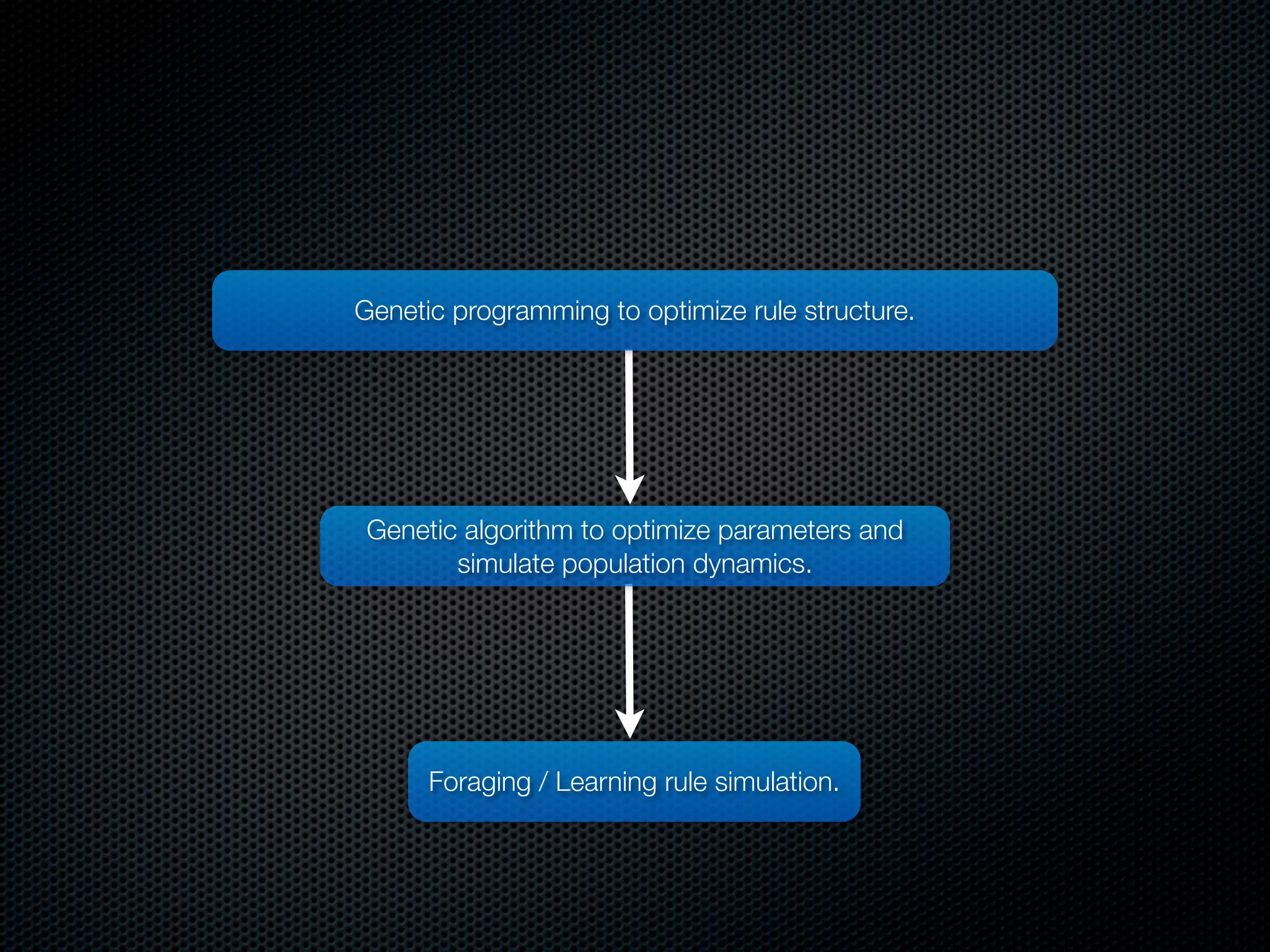





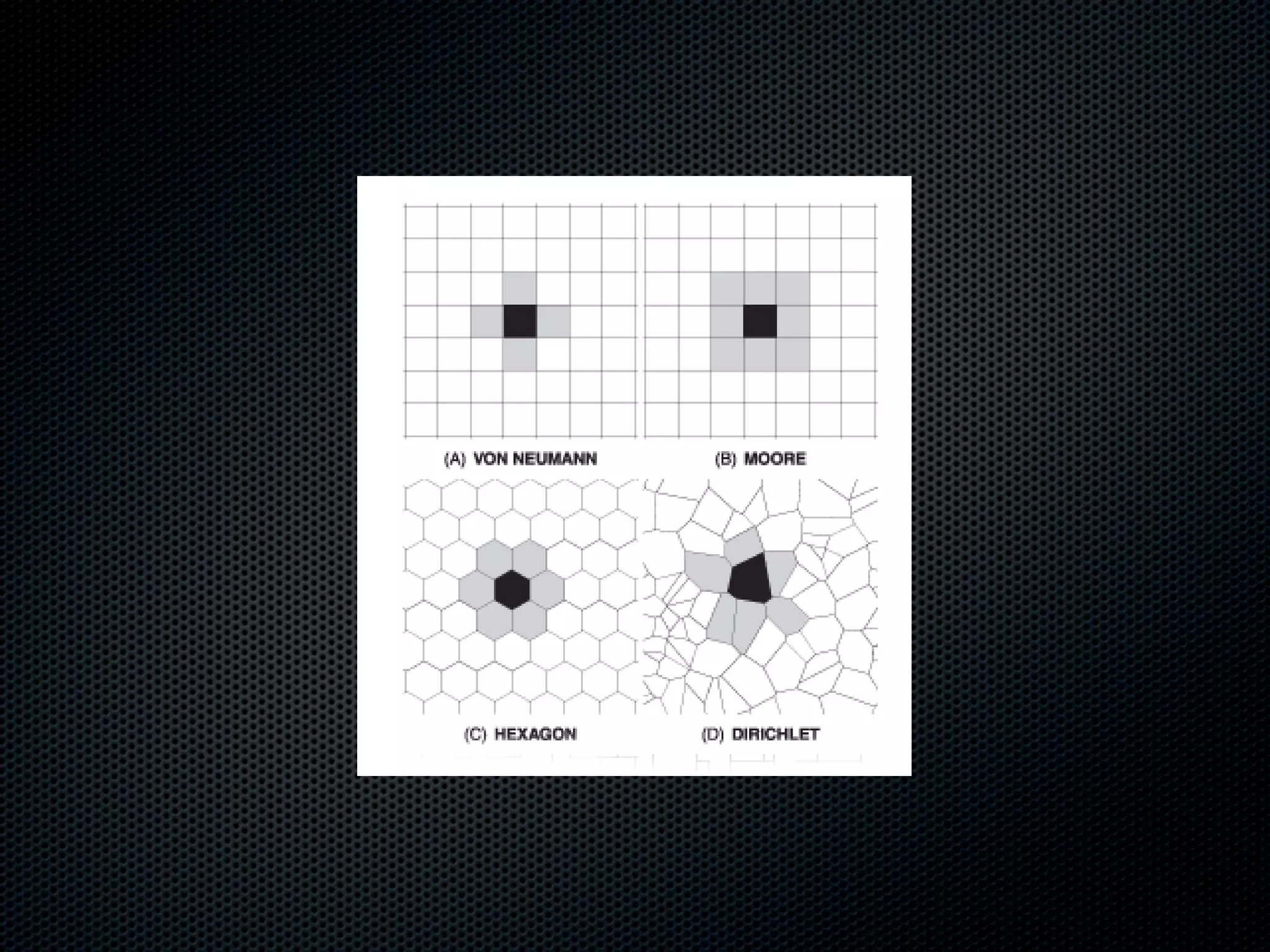
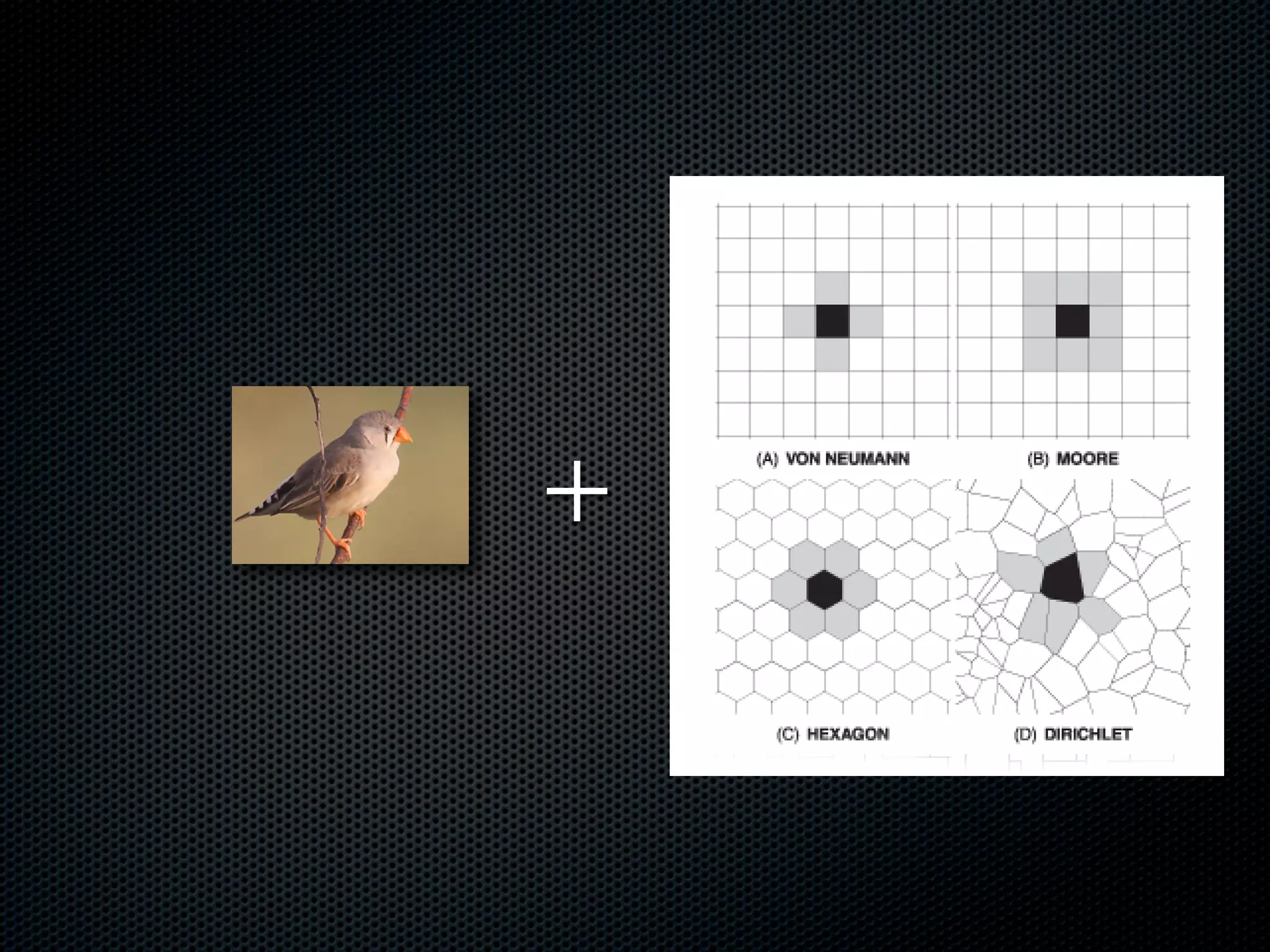
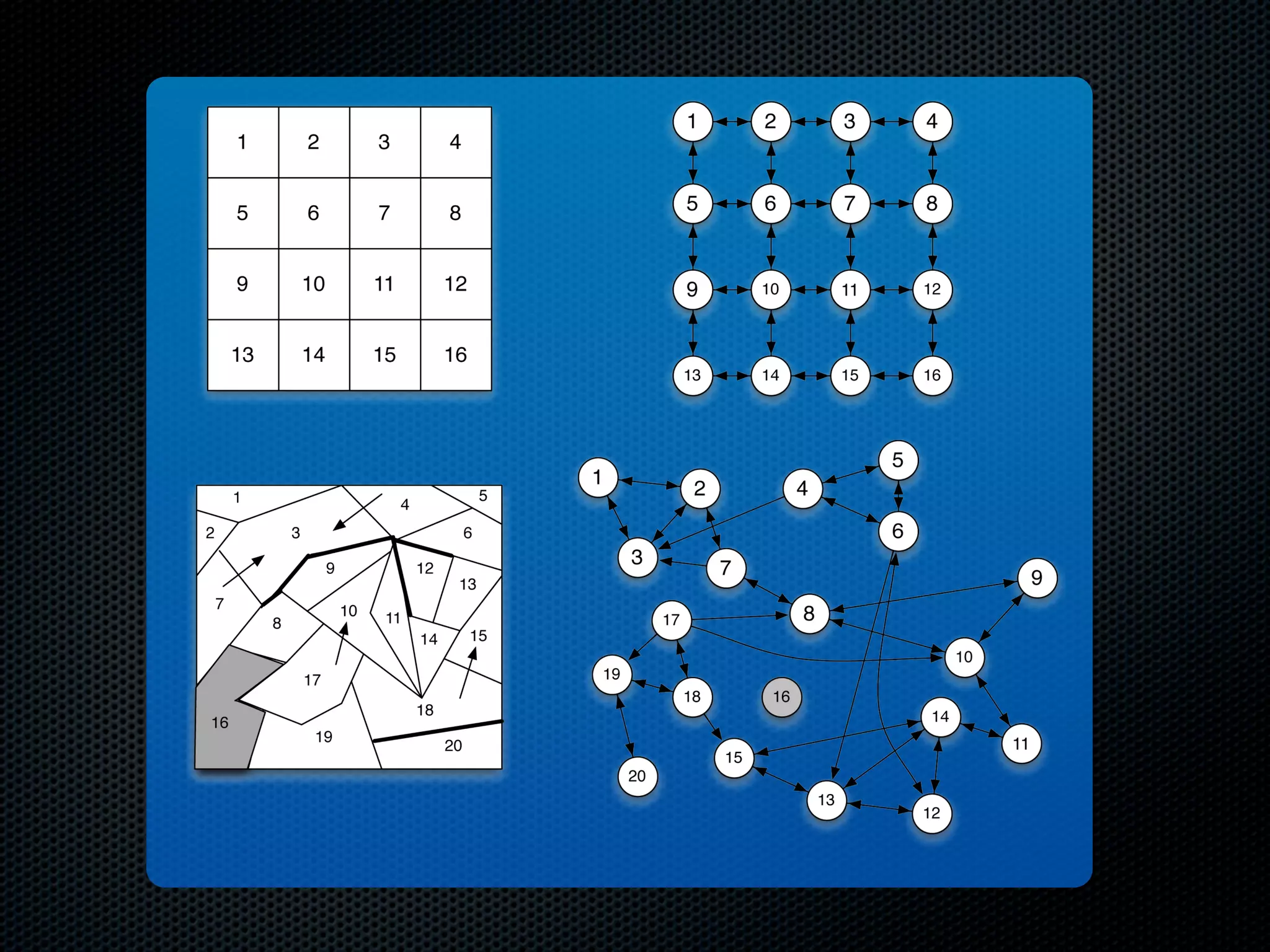





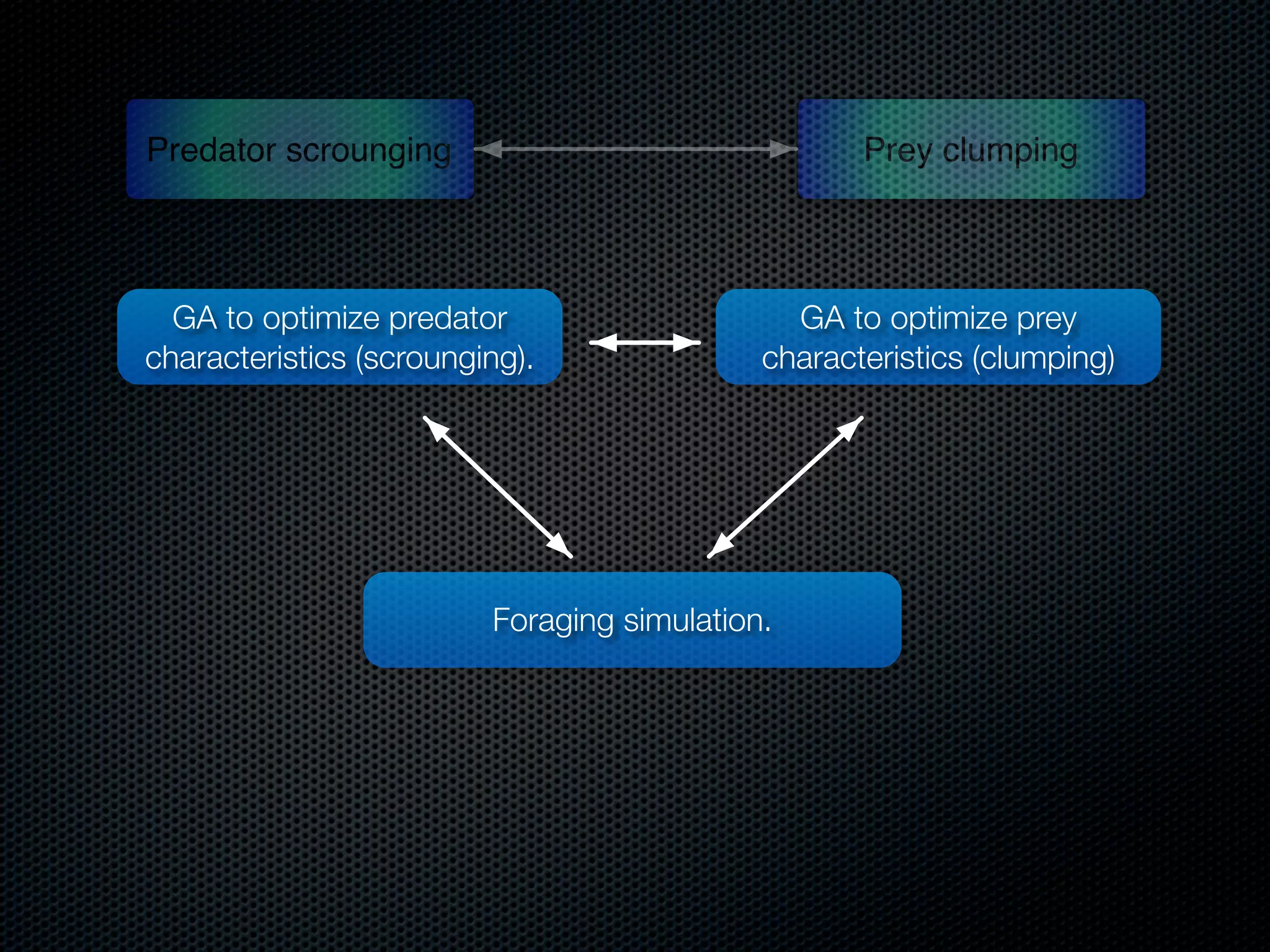

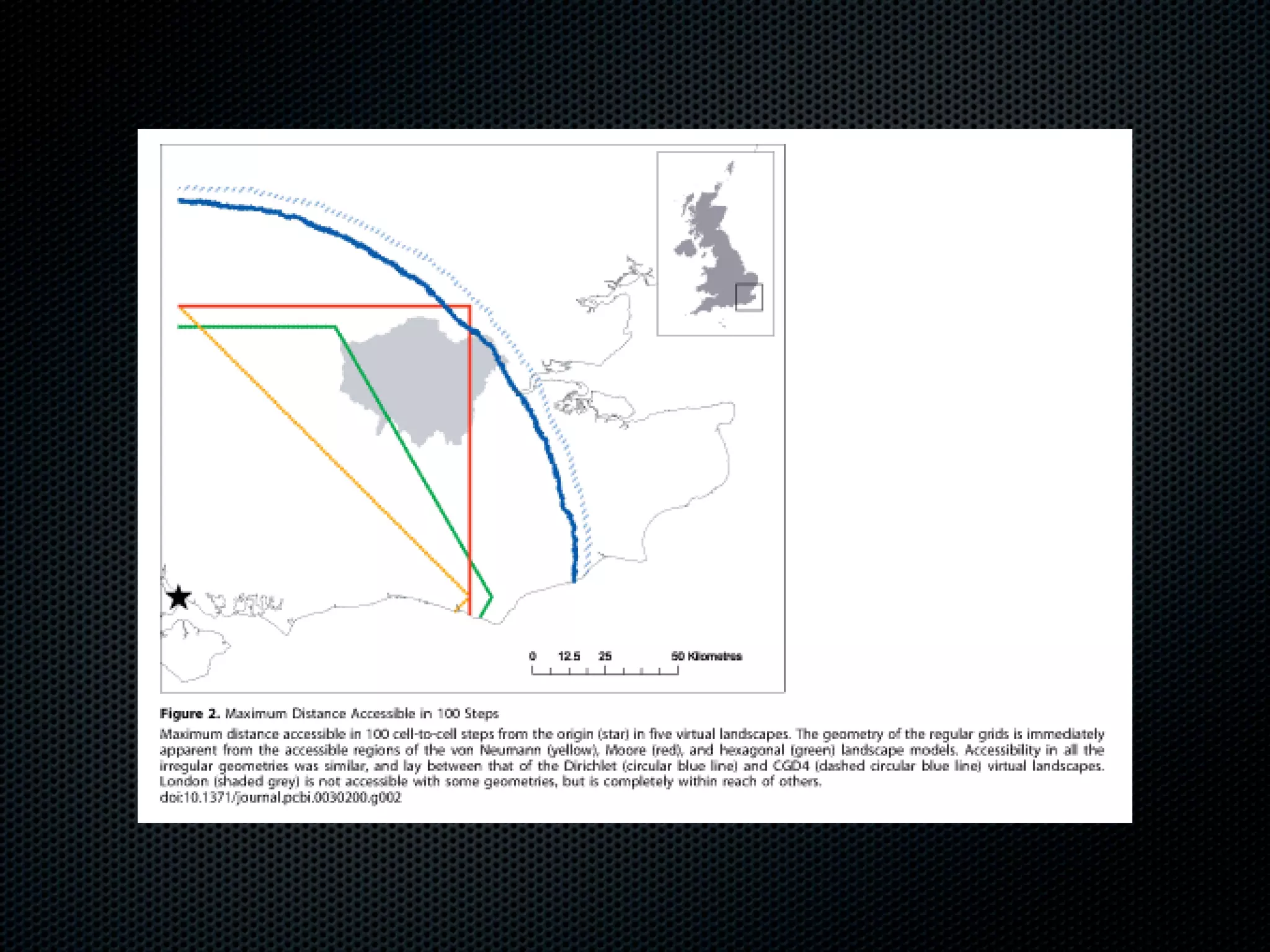














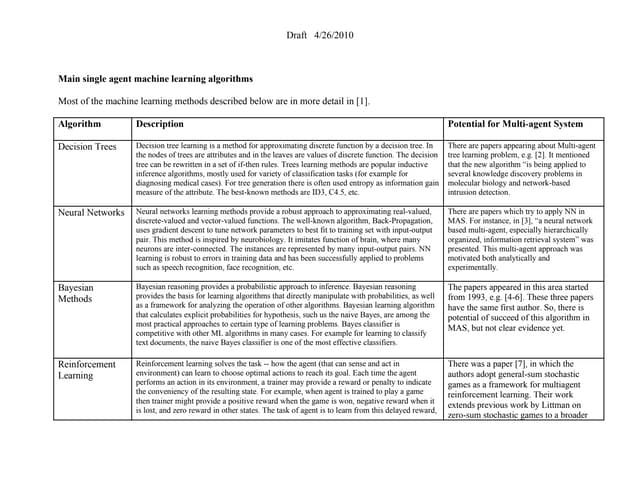
The document appears to be a Ph.D. proposal by Steven Hamblin that covers four chapters on foraging behavior and learning rules. Chapter 1 will discuss the evolution of learning rules for foraging. Chapter 2 will examine learning rules in more detail. Chapter 3 will consider the effects of landscape geometry on foraging. Chapter 4 will analyze predator-prey coevolution through changes in predator scrounging behavior and prey clumping habits. The proposal involves using genetic algorithms and foraging simulations to optimize learning rule parameters and population dynamics over time.