Download as PDF, PPTX










![Review: UCB1
Assume ri,t ∼ Pi with support [0, 1] and mean µi
Idea: select more seldom-selected arms and less often-selected arms.
In other words, give a confidence bonus1!
UCB12: define score as
si,t = ˆµi,t +
2 log t
ni,t
where ˆµi,t is empirical mean, and ni,t is number of arm i selected
UCB1 policy garantees the optimal regret O(log T)
Also, there are other choices for UCB (ex. KL-UCB3, Bayes-UCB4)
1
We call this bonus UCB(upper confidence bound). Thus, score = estimated mean + UCB.
2
Auer et al. Finite-time Analysis of the Multiarmed Bandit Problem. Machine Learning, 2002.
3
Garivier & Capp´e. The KL-UCB Algorithm for Bounded Stochastic Bandits and Beyond. COLT, 2011.
4
Kaufmann et al. On Bayesian Upper Confidence Bounds for Bandit Problems. AISTATS, 2012.
Sangwoo Mo (KAIST) Contextual Bandit Survey August 4, 2016 11 / 32](https://image.slidesharecdn.com/contextualbanditsurvey-160805144524/75/Contextual-Bandit-Survey-11-2048.jpg)
![LinUCB
Assume ri,t ∼ P(ri,t | ci,t, θ) where E[ri,t] = cT
i,tθ∗ (ci,t, θ ∈ Rd )
Like UCB1, want to define score as
si,t = cT
i,t
ˆθt + UCBi,t
Question: how to choose proper UCBi,t?
Sangwoo Mo (KAIST) Contextual Bandit Survey August 4, 2016 12 / 32](https://image.slidesharecdn.com/contextualbanditsurvey-160805144524/75/Contextual-Bandit-Survey-12-2048.jpg)


![Review: Thompson Sampling
Another popular strategy for MAB is Thompson Sampling1
It can be applied to both contextual and non-contextual bandit
Assume ri,t ∼ P(ri,t | ci,t, θ∗) with prior θ∗ ∼ P(θ)
Idea: sample estimator ˆθt from the posterior distribution
step 1. draw θt from posterior P(θ | D = {ct, at, rt})
step 2. select arm ai = arg maxi E[ri,t | ci,t, θt]
The idea is simple, but it works well both in theory2 and in practice3
1
Thompson. On the Likelihood that One Unknown Probability Exceeds Another in View of the Evidence of Two Samples.
Biometrica, 1933.
2
Agrawal et al. Analysis of Thompson Sampling for the Multi-armed Bandit Problem. COLT, 2012.
3
Scott. A modern Bayesian look at the multi-armed bandit. Applied Stochastic Models in Business and Industry, 2010.
Sangwoo Mo (KAIST) Contextual Bandit Survey August 4, 2016 15 / 32](https://image.slidesharecdn.com/contextualbanditsurvey-160805144524/75/Contextual-Bandit-Survey-15-2048.jpg)
![LinTS
Assume ri,t ∼ N(cT
i,tθ∗, v2) and θ∗ ∼ N(θt, v2B−1
t ) where
Bt =
t−1
τ=1
ci,τ cT
i,τ + Id , ˆθt = B−1
t
t−1
τ=1
ci,τ ri,τ
ri,t ∈ [¯ri,t − R, ¯ri,t + R], v = R
24
d log
t
δ
Then, the posterior of θ∗ is N(θt+1, v2B−1
t+1)
LinTS1: run Thompson Sampling in this assumption
Regret bound (with probability 1 − δ) is
O(
d2 √
T1+ log(Td) log
1
δ
)
1
Agrawal et al. Thompson Sampling for Contextual Bandits with Linear Payoffs. ICML, 2013.
Sangwoo Mo (KAIST) Contextual Bandit Survey August 4, 2016 16 / 32](https://image.slidesharecdn.com/contextualbanditsurvey-160805144524/75/Contextual-Bandit-Survey-16-2048.jpg)
![UCB & TS: Nonlinear Case
Assume E[ri,t] = f (ci,t) is general nonlinear function
If we assume f is a member of exponential family, we can use
GLM-UCB1
If we assume f is sampled from a Guassian Process, we can use
GP-UCB2/CGP-UCB3
If we assume f is an element of Reproducing Kernel Hilbert Space,
we can use KernelUCB4
Also, we can use Thompson Sampling if we know the form of
probability distribution
1
Filippi et al. Parametric Bandits: The Generalized Linear Case. NIPS, 2010.
2
Srinivas et al. Gaussian Process Optimization in the Bandit Setting: No Regret and Experimental Design. ICML, 2010.
3
Krause & Ong. Contextual Gaussian Process Bandit Optimization. NIPS, 2011.
4
Valko et al. Finite-Time Analysis of Kernelised Contextual Bandits. UAI, 2013.
Sangwoo Mo (KAIST) Contextual Bandit Survey August 4, 2016 17 / 32](https://image.slidesharecdn.com/contextualbanditsurvey-160805144524/75/Contextual-Bandit-Survey-17-2048.jpg)






![Review: EXP3
Assume ri,t ∈ [0, 1] is selected by the enviroment
In adversarial setting, the agent must select arm randomly
Idea: weight more probability to higher-reward ovserved arms
EXP31 (EXPonential-weight algorithm for EXPloration and
EXPloitation):
Regret bound is O(
√
TK log K)
1
Auer et al. The nonstochastic multiarmed bandit problem. SIAM, 2002.
Sangwoo Mo (KAIST) Contextual Bandit Survey August 4, 2016 24 / 32](https://image.slidesharecdn.com/contextualbanditsurvey-160805144524/75/Contextual-Bandit-Survey-24-2048.jpg)



![Supervised Learning to Contextual Bandit
Idea: note that contextual bandit can be thought as a supervised
learing problem with partially-observed restriction
Trick: use randomized algorithm (ex. epsilon-greedy) and unbiased
(true) reward estimator ˆrat ,t =
rat ,t
pat
instead of observed reward rat ,t.
Then,
E[ˆri,t] = pi ·
ri,t
pi
+ (1 − pi ) · 0 = ri,t
Using this trick, any supervised learning algorithm can be converted
to a contextual bandit algorithm
Banditron and NeuralBandit are examples using neural network
Sangwoo Mo (KAIST) Contextual Bandit Survey August 4, 2016 28 / 32](https://image.slidesharecdn.com/contextualbanditsurvey-160805144524/75/Contextual-Bandit-Survey-28-2048.jpg)


![Reference
[Zhou 2015] A Survey on Contextual Multi-armed Bandits. arXiv,
2015.
[Burtini’ 2015] A Survey of Online Experiment Design with the
Stochastic Multi-Armed Bandit. arXiv, 2015.
[Bubeck’ 2012] Regret Analysis of Stochastic and Nonstochastic
Multi-armed Bandit Problems. arXiv, 2012.
Sangwoo Mo (KAIST) Contextual Bandit Survey August 4, 2016 32 / 32](https://image.slidesharecdn.com/contextualbanditsurvey-160805144524/75/Contextual-Bandit-Survey-32-2048.jpg)

This document is a comprehensive survey on contextual bandits, detailing key concepts, problem settings, and algorithms like UCB and Thompson sampling. It covers both stochastic and adversarial cases, exploring various approaches and their regret bounds. The document also discusses how supervised learning techniques can be adapted for contextual bandit problems.
An overview of the seminar on Contextual Bandits, introducing main topics including problem setting and approaches.
Defines the multi-armed bandit problem and contextual bandit types, explaining the roles of the agent and environment.
Details the optimal regret bounds for stochastic, adversarial, and contextual bandits, emphasizing their complexities.
Two naïve reduction approaches to multi-armed bandits (MAB) are discussed, with associated regret bounds.
Introduces UCB and Thompson Sampling, along with their greedy and linear implementations for a contextual bandit.
Examines the LinUCB and LinTS methods, including score definitions and regret bounds under various assumptions.
Presents methods for nonlinear cases in contextual bandits, addressing advanced approaches like GLM-UCB and GP-UCB.
Describes the Epoch-Greedy algorithm for policy exploration and exploitation, including issues and regret bounds.
Presents Randomized UCB and an improvement to time complexity with ILOVECONBANDITS, noting their regret bounds.
Explains the adversarial contextual bandit setting, detailing EXP3 and its extensions with their respective regret bounds.
Discusses the conversion of supervised learning algorithms into contextual bandit settings using new reward estimators.
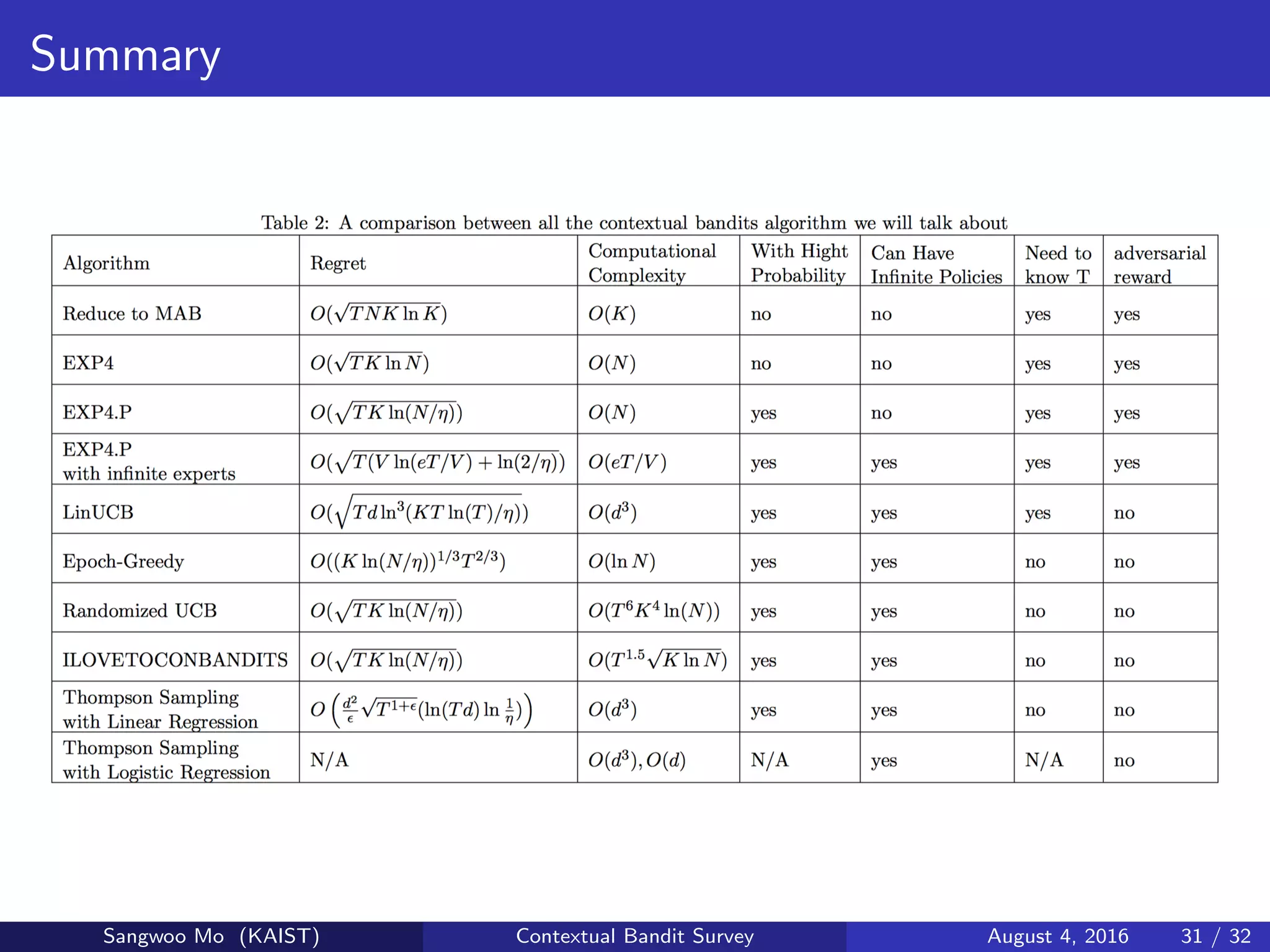
Presents a summary of the contextual bandit survey findings, along with references for further reading.












![[DL輪読会] “Asymmetric Tri-training for Unsupervised Domain Adaptation (ICML2017...](https://cdn.slidesharecdn.com/ss_thumbnails/dlhacks20170728-170728025901-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DL輪読会]Learning Robust Rewards with Adversarial Inverse Reinforcement Learning](https://cdn.slidesharecdn.com/ss_thumbnails/180201dllearningrobustrewardswithadversarial3-180205170610-thumbnail.jpg?width=640&height=640&fit=bounds)







![[DL輪読会]Clebsch–Gordan Nets: a Fully Fourier Space Spherical Convolutional Neu...](https://cdn.slidesharecdn.com/ss_thumbnails/20181214clebschgordanmizuta-181214051939-thumbnail.jpg?width=640&height=640&fit=bounds)












































![[DSC Europe 25] Katherine Forrest - AI NOW: Understanding the Velocity of Cha...](https://cdn.slidesharecdn.com/ss_thumbnails/wvvbruqfrci0sfq9xwgb-4-251212104007-e5ad1987-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DSC Europe 25] Andy Cotgreave - Nothing is new in analytics.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/mba4vzcurvoh5lfrd5zw-6-251205194645-341bbbbe-thumbnail.jpg?width=640&height=640&fit=bounds)



![[DSC Europe 25] Imai Jen-La Plante - The New Generation: AI and the Future of...](https://cdn.slidesharecdn.com/ss_thumbnails/kxi8t2l5rggivgcenyba-1-jenlaplante-dsc-251208152532-d1e076c2-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Dragana Ilic - AI for Big Data in Astronomy.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/8palya86qaatvjhva1ms-2-dragana-ilic-ai-ilic-251208151906-652b819c-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DSC Europe 25] Milan Zdravkovic - The road less traveled in District Heating...](https://cdn.slidesharecdn.com/ss_thumbnails/nfaboniqwsz4ucyctnmy-2-milan-zdravkovic-dsc2025-the-road-less-traveled-in-district-heating-operation-251208151905-f56388a5-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DSC Europe 25] Dusan Pavlov - There Is No Spoon: Inferring Vision from Neura...](https://cdn.slidesharecdn.com/ss_thumbnails/wg0v1umoqjm4nnbd3p0v-there-is-no-spoon-251205085715-6d81d6c5-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Dragan Vucic - Building the Learning Organization - How AI Tr...](https://cdn.slidesharecdn.com/ss_thumbnails/8brigo2sbu6qur6gxrra-7-251205085715-6ae07d24-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Milan Sekuloski - Data, Defence, and Development: Cybersecuri...](https://cdn.slidesharecdn.com/ss_thumbnails/dfrkwwx4qly6atqpbl4z-4-251209104645-c3d4b0ca-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DSC Europe 25] Sara Polak - The Ancient Operating System: What Archaeology T...](https://cdn.slidesharecdn.com/ss_thumbnails/3vch2p6tttdnwhsgazoz-3-sara-polak-smart-cities-251208152532-64404202-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Dusan Jovicic - AI Story: From on-prem to cloud and back agai...](https://cdn.slidesharecdn.com/ss_thumbnails/8kp49m6uq22ifnbwhfnk-2-251205085715-964d11a6-thumbnail.jpg?width=640&height=640&fit=bounds)