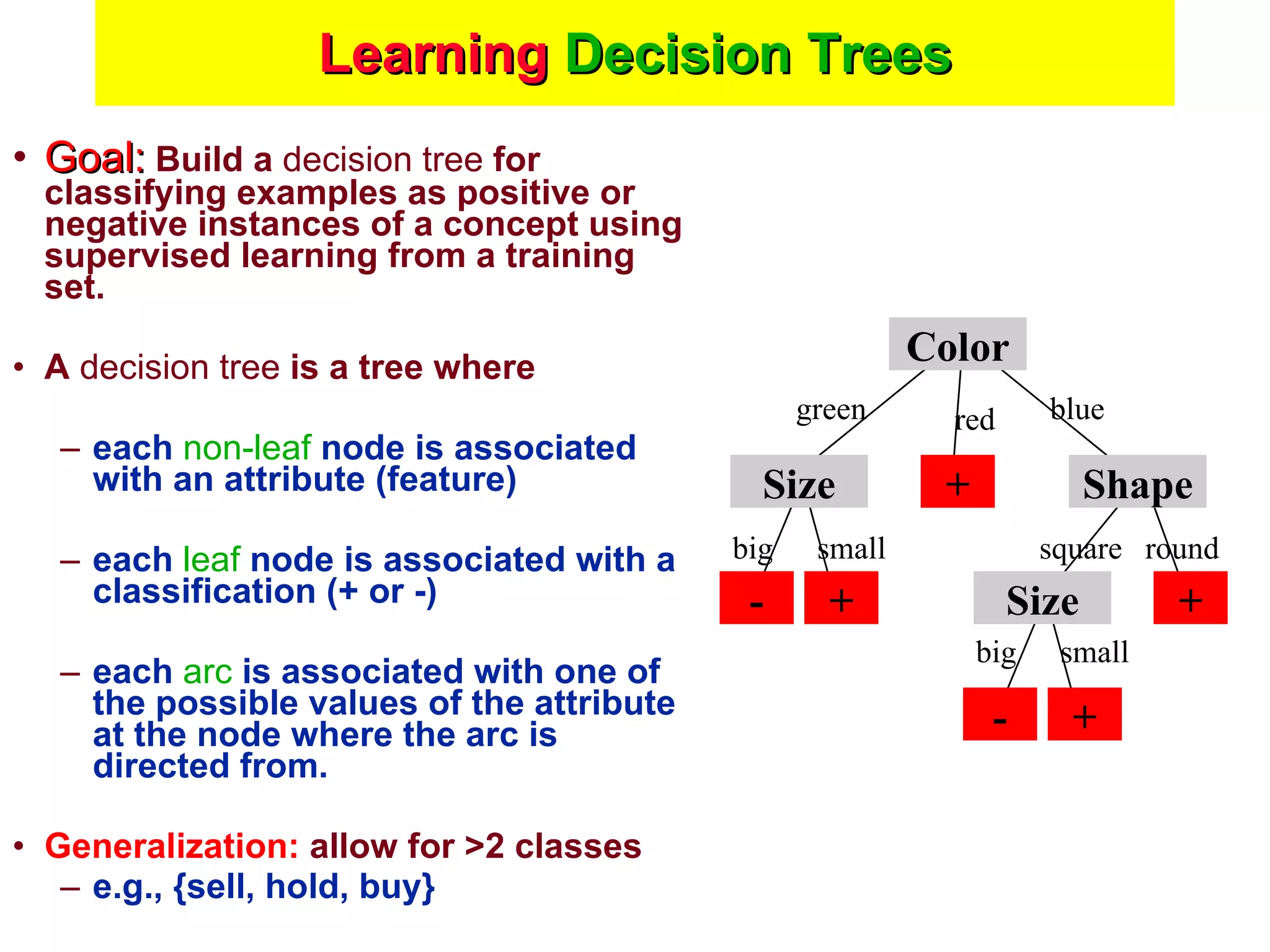
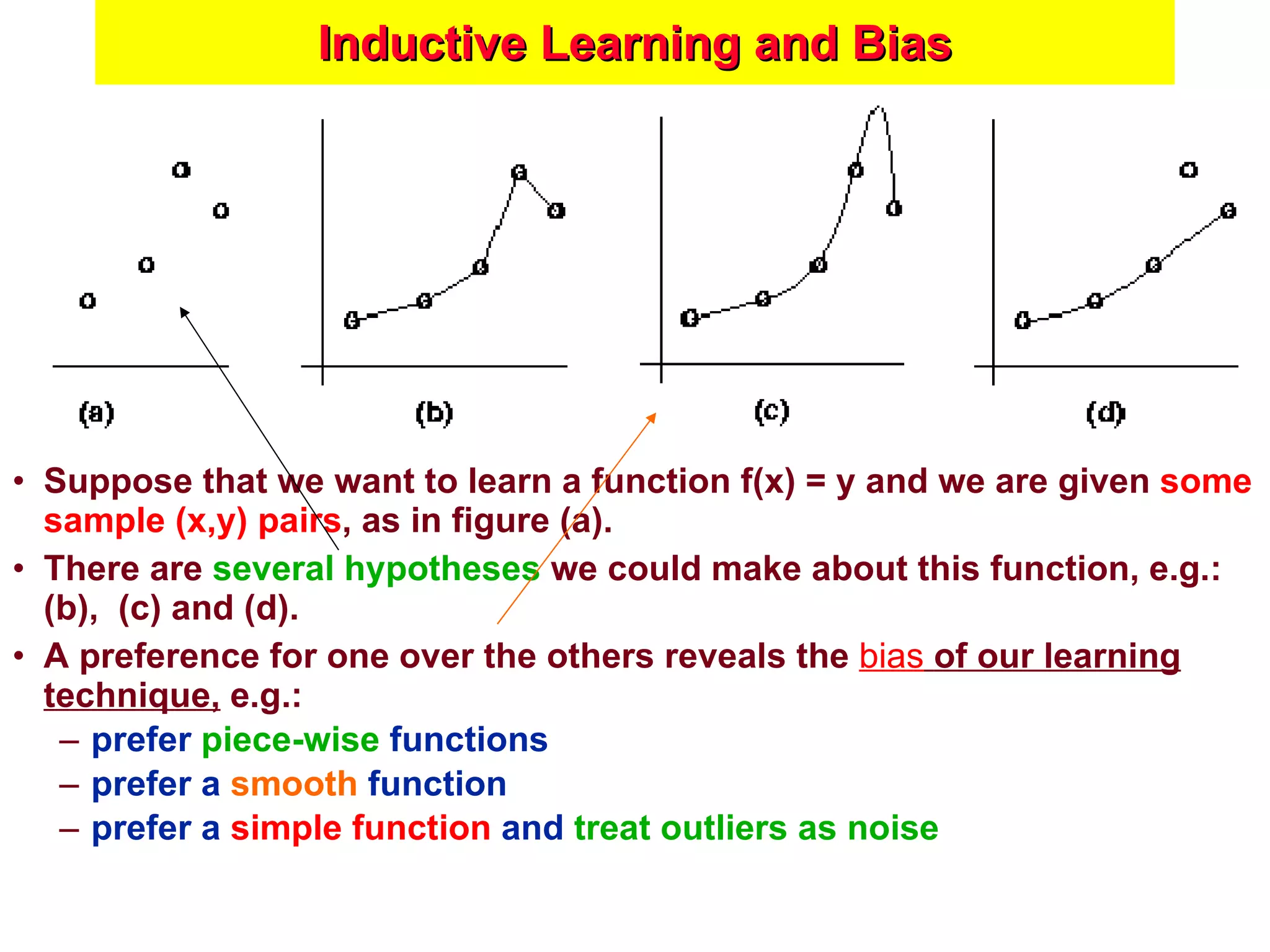
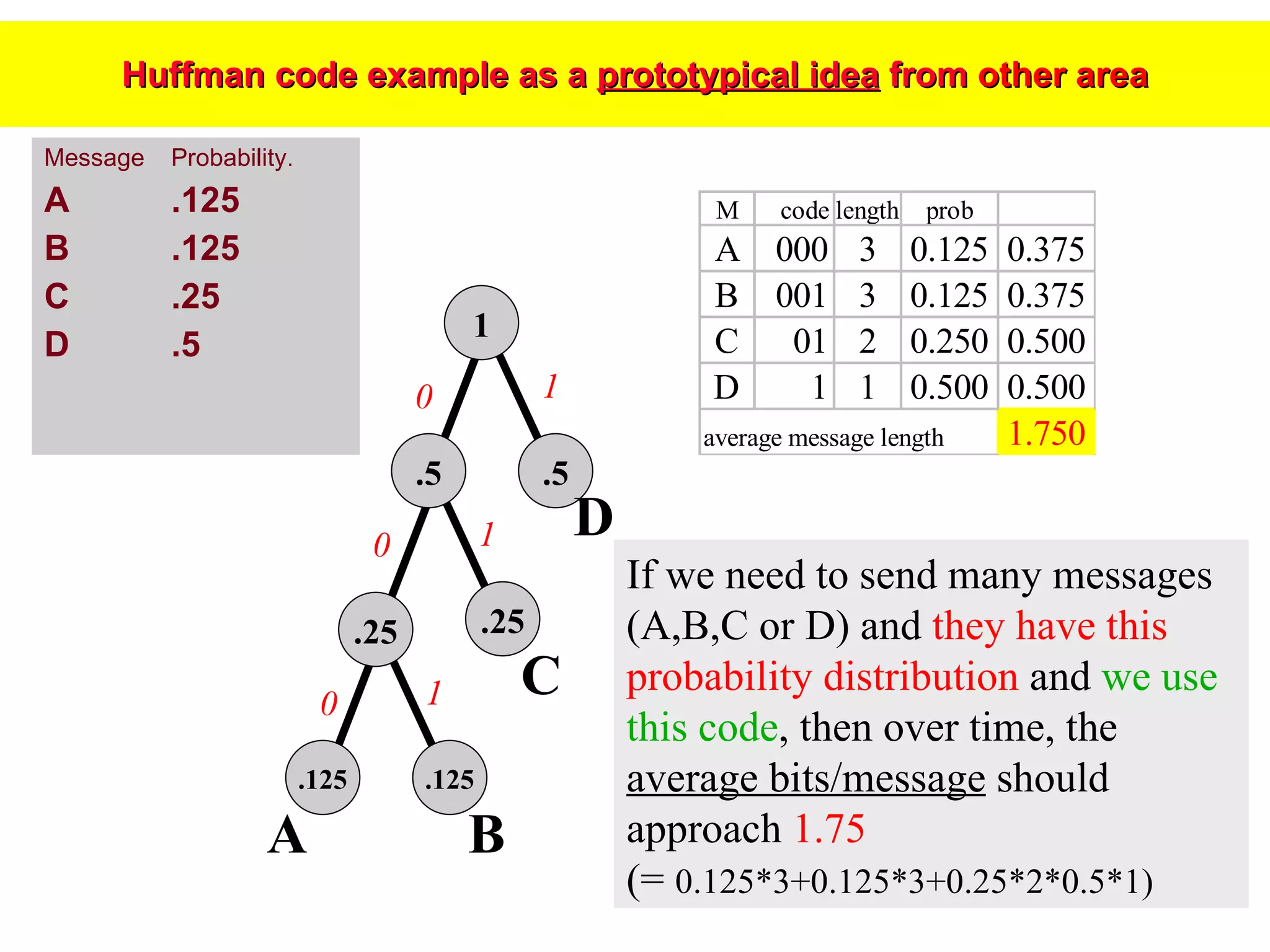
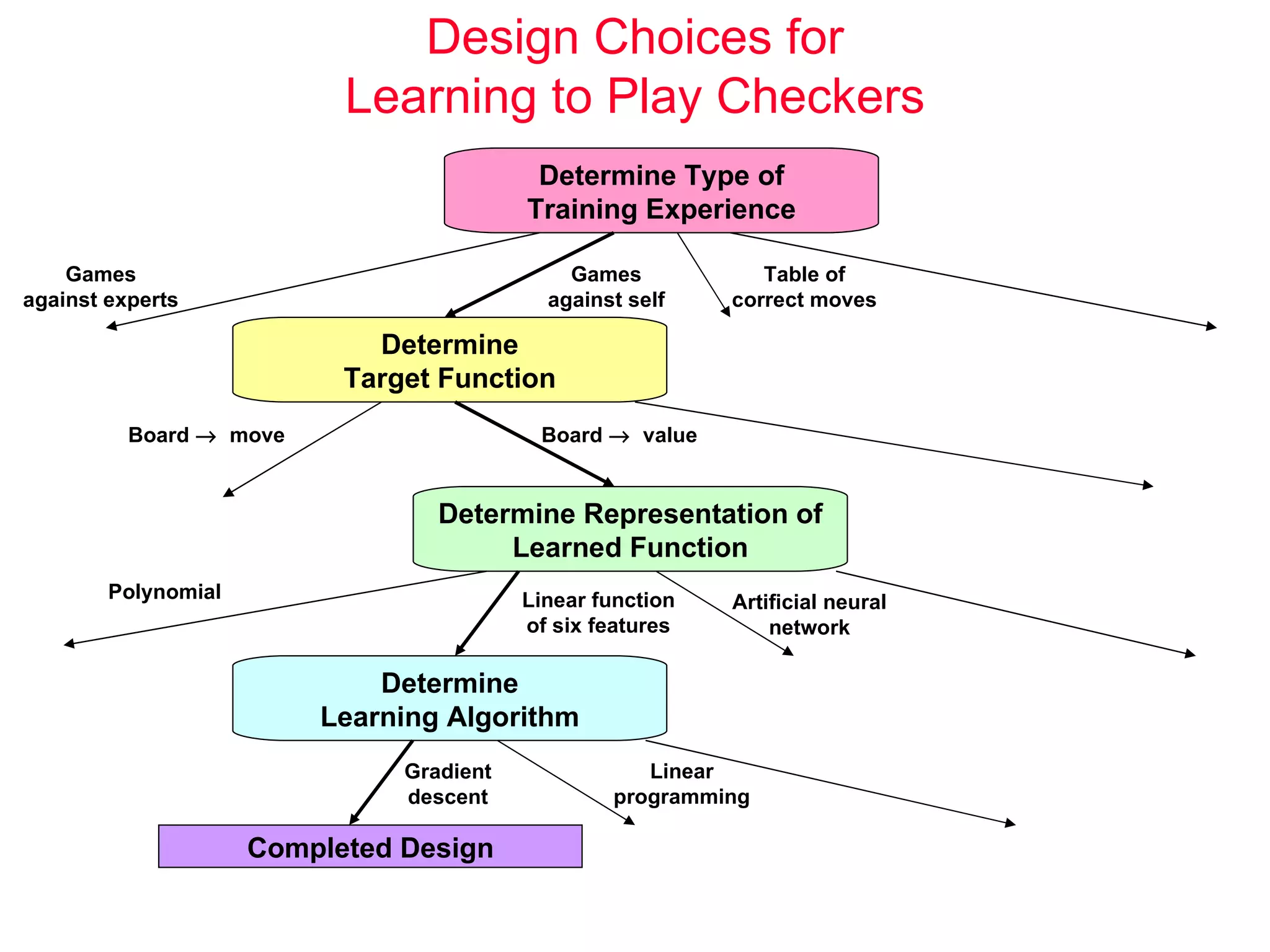
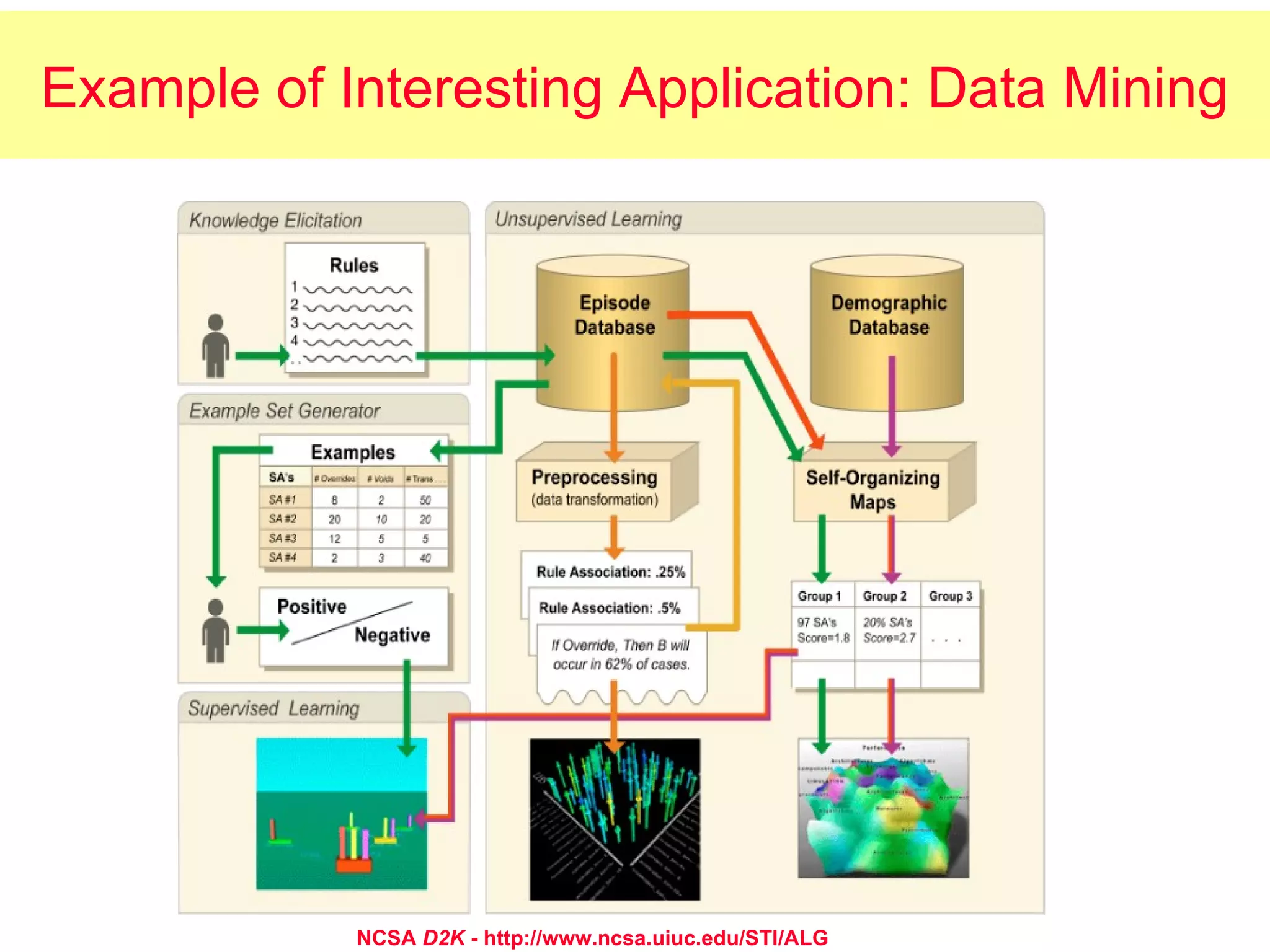
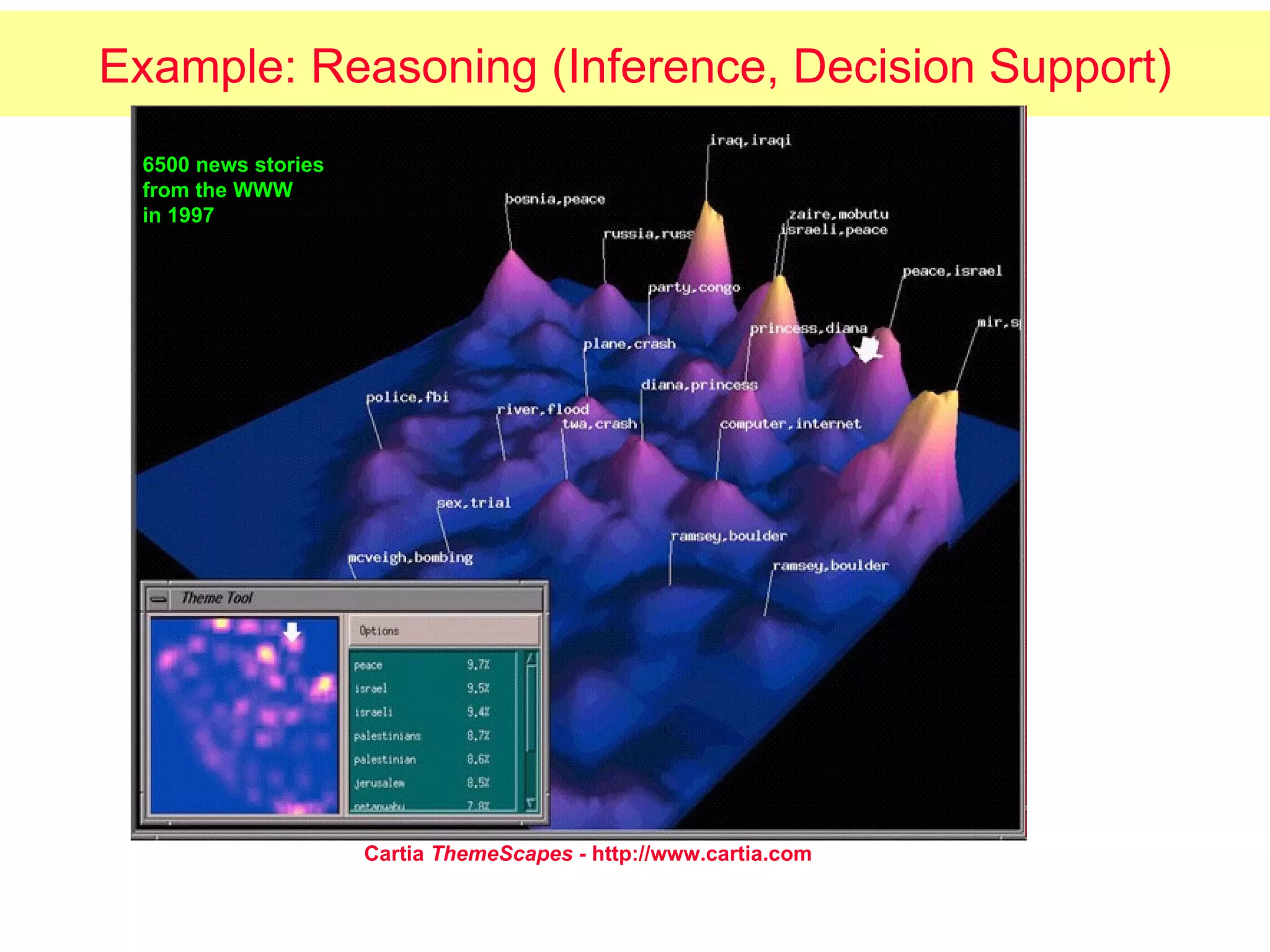
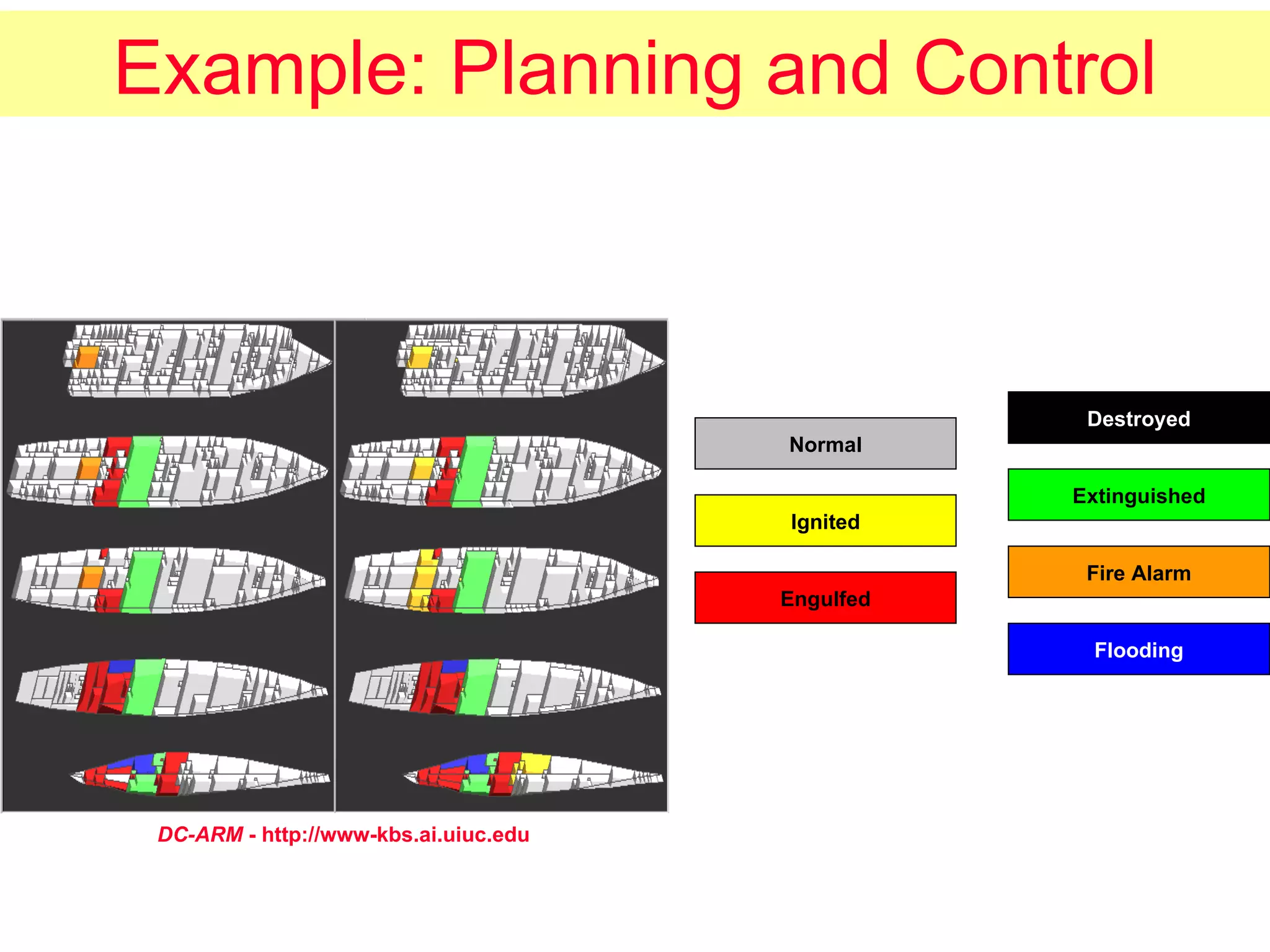
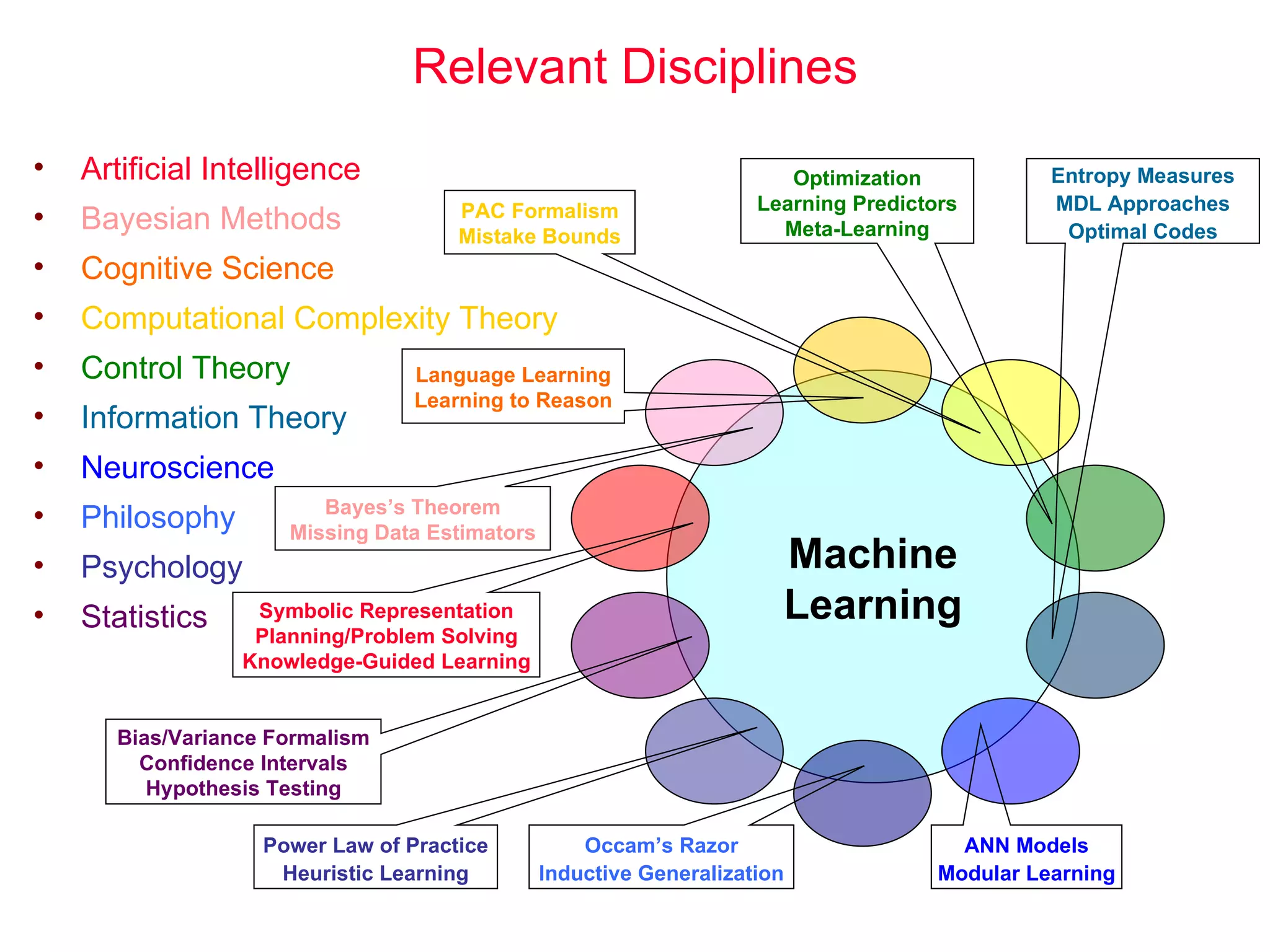
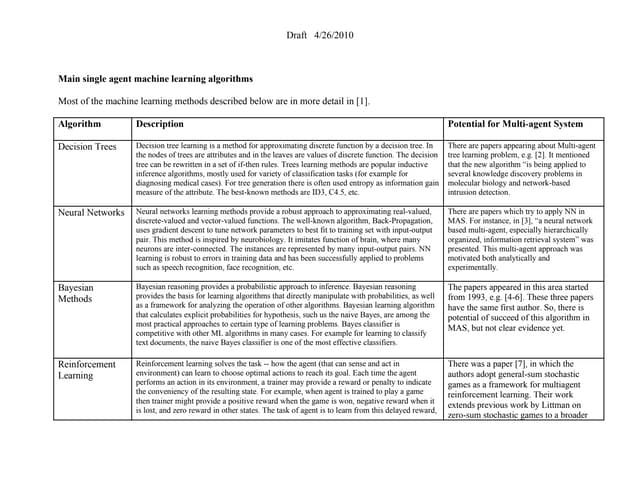
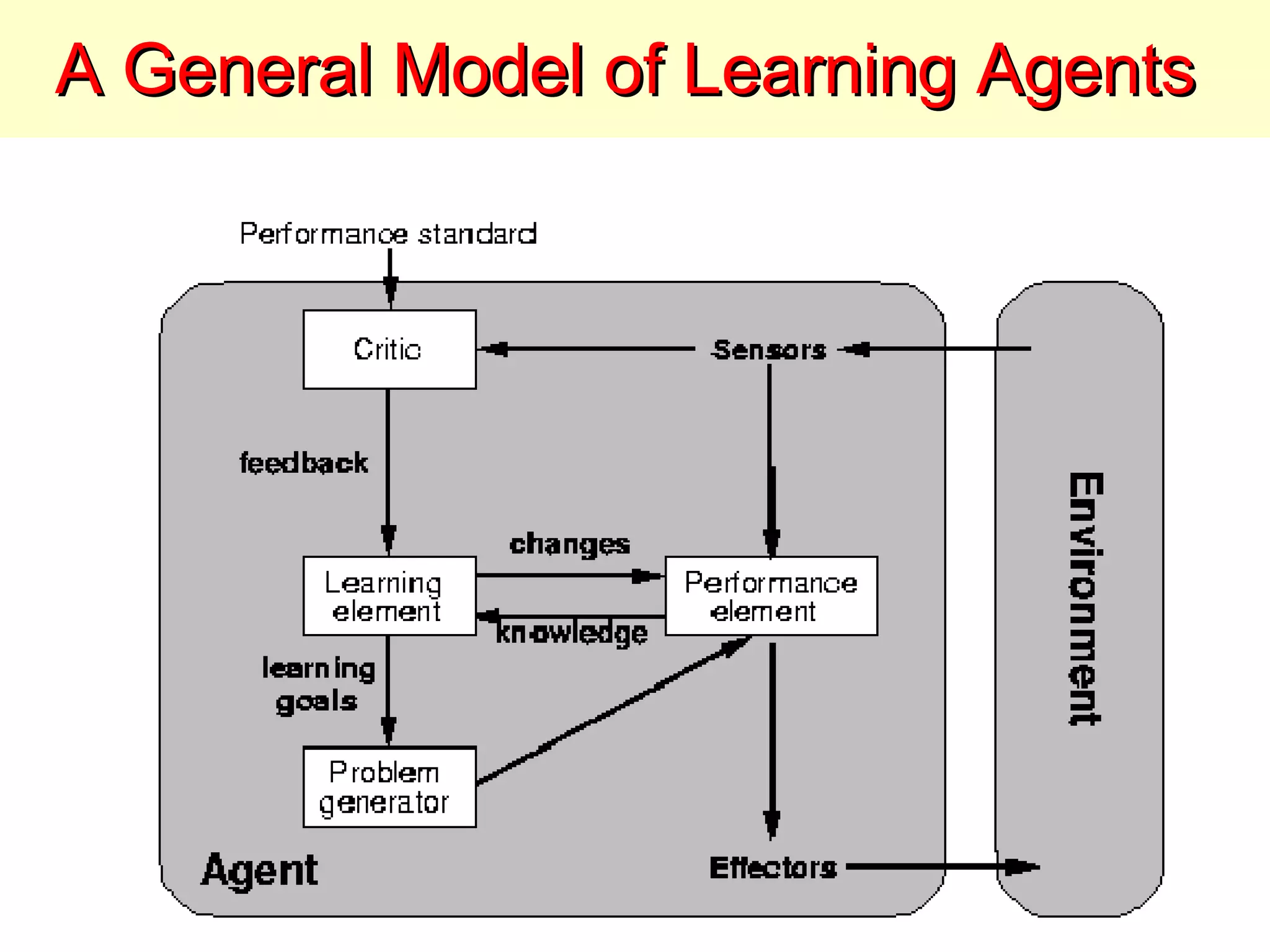
The document discusses machine learning and provides an overview of the field. It defines machine learning, explains why it is useful, and gives a brief tour of different machine learning techniques including decision trees, neural networks, Bayesian networks, and more. It also discusses some issues in machine learning like how learning problem characteristics and algorithms influence accuracy.














![Inductive Learning Framework Raw input data from sensors are preprocessed to obtain a feature vector , X, that adequately describes all of the relevant features for classifying examples. Each x is a list of (attribute, value) pairs. For example, X = [Person:Sue, EyeColor:Brown, Age:Young, Sex:Female] The number and names of attributes (aka features ) is fixed (positive, finite). Each attribute has a fixed, finite number of possible values. Each example can be interpreted as a point in an n-dimensional feature space , where n is the number of attributes.](https://image.slidesharecdn.com/introduction-to-machine-learning1998/75/Introduction-to-Machine-Learning-16-2048.jpg)