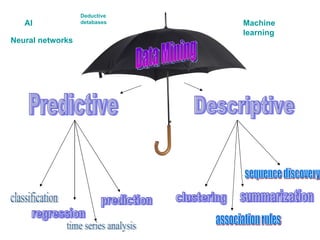
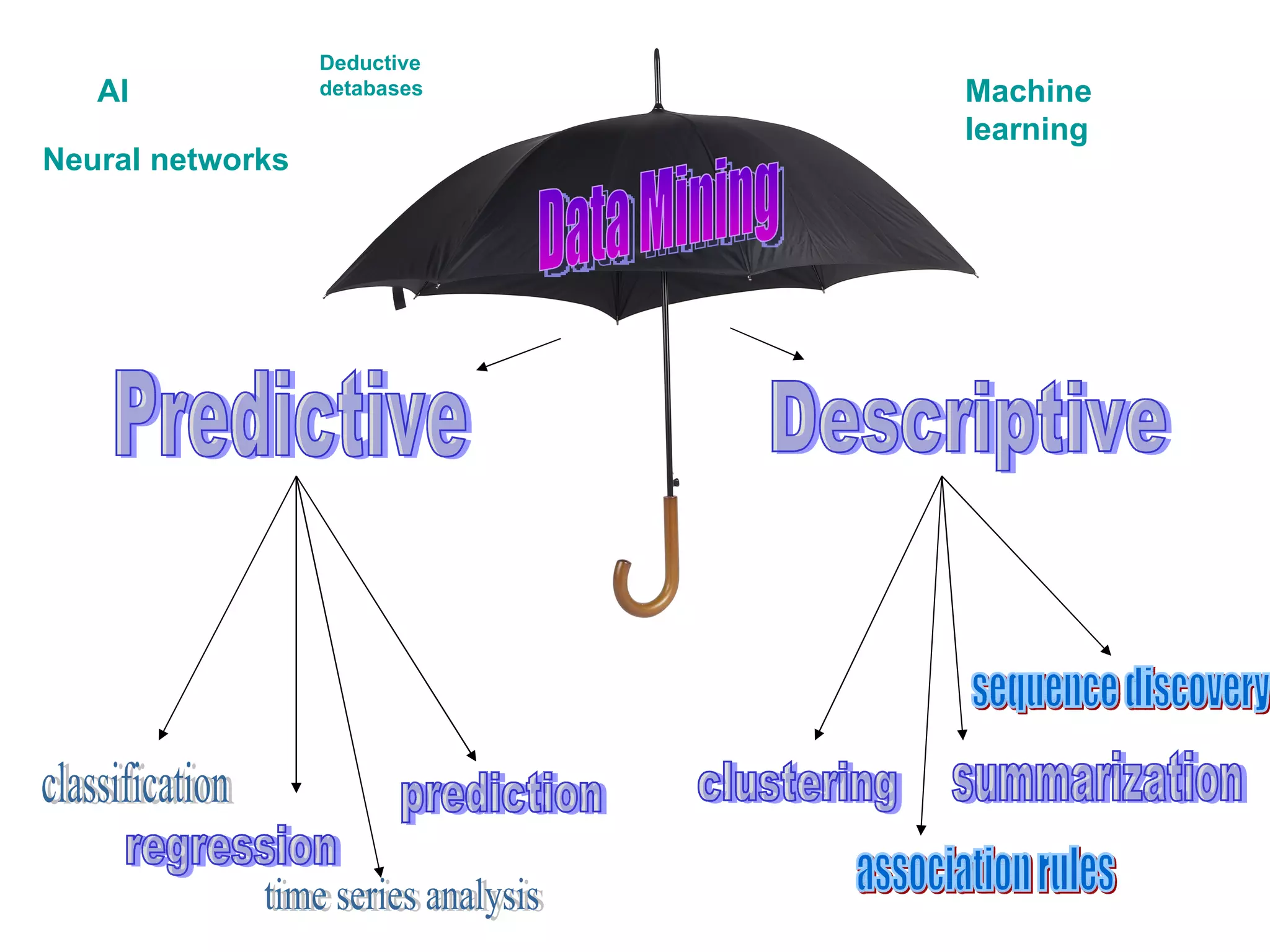
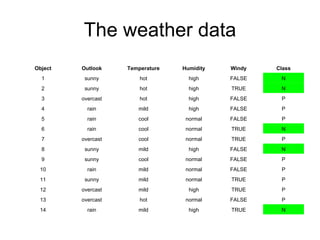
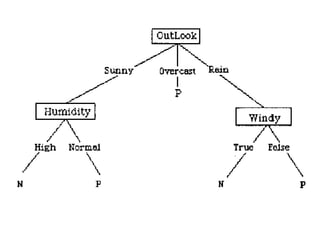
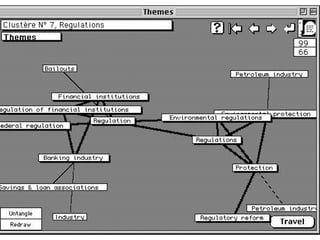
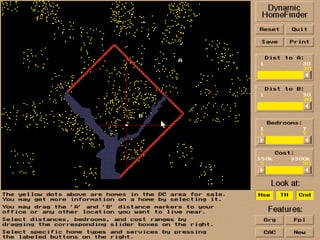
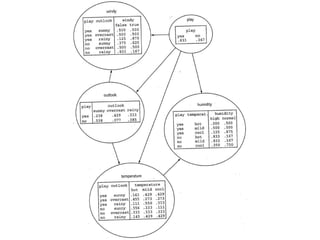
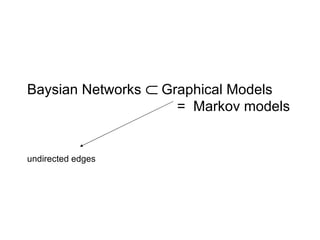
The document discusses various techniques in data mining including predictive, descriptive and classification methods. It provides examples of opportunities in data mining through vast amounts of data being collected in fields like astronomy, biology, physics and business. Challenges discussed include dealing with incomplete records and interpreting results from models to avoid overfitting. Both supervised and unsupervised learning techniques are covered.