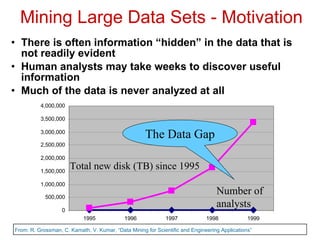
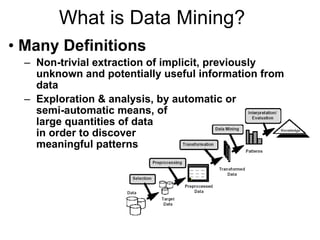
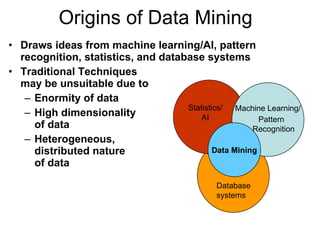
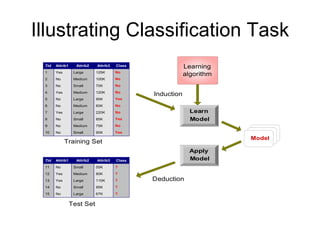
This document discusses data mining and its applications. It notes that large amounts of data are being collected from various sources and stored. Data mining can help analyze this data by discovering patterns and relationships that would be difficult for humans to find manually. The document provides an overview of data mining techniques like classification and discusses software used for data mining like SAS Enterprise Miner, R, and Weka.
![Data Mining at UVA New Horizons in Teaching and Learning Conference May 21-24, 2007 Kathy Gerber, ITC Research Computing [email_address]](https://image.slidesharecdn.com/datamining-110203063856-phpapp02/85/Datamining-1-320.jpg)
![Data Mining at UVA New Horizons in Teaching and Learning Conference May 21-24, 2007 Kathy Gerber, ITC Research Computing [email_address]](https://image.slidesharecdn.com/datamining-110203063856-phpapp02/75/Datamining-1-2048.jpg)