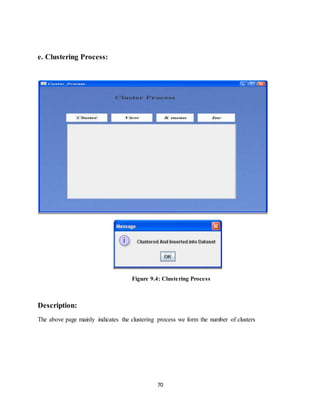
This document discusses techniques for analyzing unstructured text data from computer data inspection. It discusses using clustering algorithms like K-means and hierarchical clustering to automatically group related documents without supervision. The goal is to help computer examiners analyze large amounts of text data more efficiently. Prior work on clustering ensembles, evolving gene expression clusters, self-organizing maps, and thematically clustering search results is reviewed as relevant to this problem. The problem is how to identify and cluster documents stored across multiple remote locations during computer inspections when existing algorithms make this difficult.







































![44
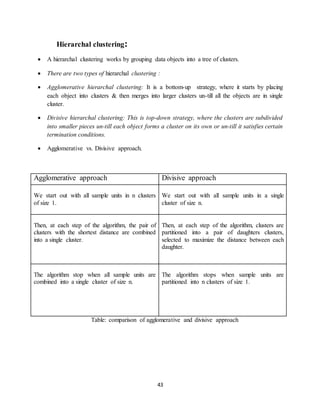
Hierarchical Algorithm:
• The maximum distance between elements of each cluster (also called complete-linkage
clustering): maxf d(x; y) : x 2 A; y 2 B g:
• The minimum distance between elements of each cluster (also called single-linkage
clustering): minf d(x; y) : x 2 A; y 2 B g:
• The mean distance between elements of each cluster (also called average linkage
clustering, used e.g. in UPGMA):
• The sum of all intra-cluster variance.
• The increase in variance for the cluster being merged (Ward’s method<ref
name="[6])The probability that candidate clusters spawn from the same distribution function
(V-linkage). Each agglomeration occurs at a greater distance between clusters than the
previous agglomeration, and one can decide to stop clustering either when the clusters are too
far apart to be merged (distance criterion) or when there is a sufficiently small number of
clusters (number criterion).
Hierarchical vs. partitioning algorithms:
Hierarchical techniques produce a nested sequence of partitions, with a single, all inclusive
cluster at the top and singleton clusters of individual points at the bottom. Each intermediate
level can be viewed as combining (splitting) two cluster from the next lower (next higher)
level. Partitional techniques create a one level (unnested) partitioning the data points. If k is
the desired number of clusters, then partitions approaches typically find all k clusters at
once. Contrast this with traditional hierarchical schemes, which bisect a cluster to get two
clusters or merge two clusters to get one.
Distance Measure
An important step in any clustering is to select a distance measure. We will determine how
the similarity of two elements is calculated. This influence the shape of the clusters, as some
elements may be close to another according to one distance and further away according to
another. The various distance measures are:](https://image.slidesharecdn.com/finalproj21-150911154651-lva1-app6891/85/Final-proj-2-1-44-320.jpg)























![78
B-Source Code
Preprocess.java :
package ncluster;
import com.mysql.jdbc.Connection;
import java.io.*;
import java.sql.*;
import java.util.*;
import javax.swing.JFileChooser;
import ptstemmer.implementations.PorterStemmer;
public class preprocess extends javax.swing.JFrame {
String cont="", line="", path="", filename="", word="", str="", count="", nooffile="";
public static int numofdoc,count1,coun,i, noofterm;
File folder, files[];
PorterStemmer stemmer = new PorterStemmer();
float[] tf=new float[1500];
double[] idf=new double[1500];
double[] result=new double[1500];
int i1=0,j1=0,k1=0;
public preprocess() {
initComponents();
}
@SuppressWarnings("unchecked")
// <editor-fold defaultstate="collapsed" desc="Generated Code">
private void initComponents() {](https://image.slidesharecdn.com/finalproj21-150911154651-lva1-app6891/85/Final-proj-2-1-78-320.jpg)





![84
try{
JFileChooser chooser=new JFileChooser();
int returnVal = chooser.showOpenDialog(this);
if(returnVal == JFileChooser.APPROVE_OPTION) {
folder = chooser.getCurrentDirectory();
path = folder.getPath();
textbox1.setText(path);
files = folder.listFiles();
}
title.setText("Content of the File");
if(files.length>1){
for(i = 0;i<files.length; i++){
if (files[i].isFile())
{
int index = files[i].getName().lastIndexOf('.');
if (index>0&& index <= files[i].getName().length() - 2 ) {
filename = files[i].getName().substring(0, index);
String fname = filename.toUpperCase();
text.append("n"+fname+"nn");
}
}
FileReader fr = new FileReader(files[i]);
BufferedReader br = new BufferedReader(fr);
while((line = br.readLine())!=null){
text.append(line+" ");](https://image.slidesharecdn.com/finalproj21-150911154651-lva1-app6891/85/Final-proj-2-1-84-320.jpg)
![85
}
text.append("n");
}
}
}
catch (Exception ex) {
System.out.println(ex.getMessage());
}
}
private void removestopwordActionPerformed(java.awt.event.ActionEvent evt) {
while(true){
ch = Character.toLowerCase((char) ch);
w[j] = (char) ch;
if (j < 500) j++;
ch = in.read();
if (!Character.isLetter((char) ch)){
for (int c = 0; c < j; c++) s.add(w[c]);
s.stem();
{
String u;
u = s.toString();
f.createNewFile();
FileWriter writer = new FileWriter(newfname,true);
writer.write(u+" ");
writer.close();](https://image.slidesharecdn.com/finalproj21-150911154651-lva1-app6891/85/Final-proj-2-1-85-320.jpg)

![87
private void calcActionPerformed(java.awt.event.ActionEvent evt) {
frame1 form =new frame1();
form.setVisible(true);
}
public static void main(String args[]) {
java.awt.EventQueue.invokeLater(new Runnable() {
public void run() {
new preprocess().setVisible(true);
}});}
// Variables declaration - do not modify
private javax.swing.JLabel DocClust;
private javax.swing.JButton calc;
private javax.swing.JLabel jLabel1;
private javax.swing.JLabel jLabel2;
private javax.swing.JPanel jPanel1;
private javax.swing.JScrollPane jScrollPane1;
private javax.swing.JLabel pathoffile;
private javax.swing.JButton removestopword;
private javax.swing.JButton select;
private javax.swing.JLabel selfiles;
private javax.swing.JButton stemming;
private javax.swing.JTextArea text;
private javax.swing.JTextField textbox1;
private javax.swing.JLabel title;
// End of variables declaration }](https://image.slidesharecdn.com/finalproj21-150911154651-lva1-app6891/85/Final-proj-2-1-87-320.jpg)
![88
Graph.java :
package ncluster;
import java.awt.*;
import org.jfree.chart.*;
import org.jfree.chart.axis.*;
import org.jfree.chart.plot.*;
import org.jfree.chart.renderer.category.BarRenderer;
import org.jfree.data.category.DefaultCategoryDataset;
public class Graph {
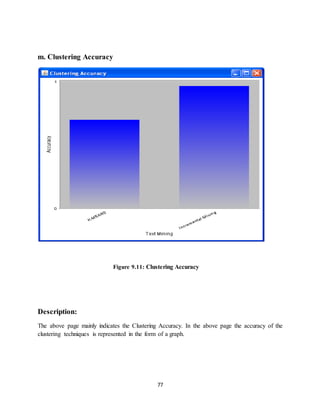
public static double kmeans = Purity.res1;
public static double hsk = Purity.res;
public static void main(String arg[]) {
DefaultCategoryDataset dataset = new DefaultCategoryDataset();
dataset.setValue(kmeans, "Accuracy", "K-MEANS");
dataset.setValue(hsk, "Accuracy", "Incremental Mining");
JFreeChart chart = ChartFactory.createBarChart("", "Text Mining",
"Accuracy", dataset, PlotOrientation.VERTICAL, false, true, false);
chart.setBackgroundPaint(Color.white);
final CategoryPlot plot = chart.getCategoryPlot();
plot.setBackgroundPaint(Color.lightGray);
plot.setDomainGridlinePaint(Color.white);
plot.setRangeGridlinePaint(Color.white);
final NumberAxis rangeAxis = (NumberAxis) plot.getRangeAxis();
rangeAxis.setStandardTickUnits(NumberAxis.createIntegerTickUnits());
final BarRenderer renderer = (BarRenderer) plot.getRenderer();](https://image.slidesharecdn.com/finalproj21-150911154651-lva1-app6891/85/Final-proj-2-1-88-320.jpg)























































































