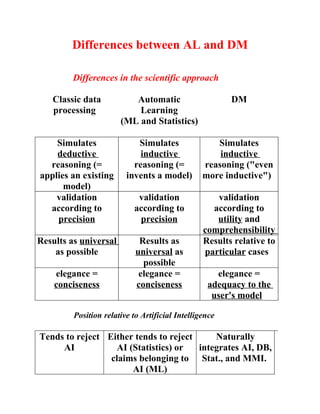
The document discusses the differences between automatic learning/machine learning and data mining. It provides definitions for supervised vs unsupervised learning, what automated induction is, and the base components of data mining. Additionally, it outlines differences in the scientific approach between automatic learning and data mining, as well as differences from an industry perspective, including common data mining techniques used and tips for successful data mining projects.



![A few definitions 1:
Supervised and Unsupervised Learning
Supervised Learning (“with teacher”)
Input: description in extension of the problem.
Most often:
Field 1 Field 2 … Field k Class
Record 1 Value 11 Value 12 … Value 1k Class
value
…
Record p Value p1 Value p2 … Value pk Class
value
Output : extract the ‘properties’ of this description
(also called : description in intention)
IF (Field m = Value ml) & Field n ∈ [Value ij, Value mn] & …
THEN Class value = a
Unsupervised Learning (“without teacher”)
Discover patterns in the data](https://image.slidesharecdn.com/presentation-on-machine-learning-and-data-mining2694/85/Presentation-on-Machine-Learning-and-Data-Mining-3-320.jpg)