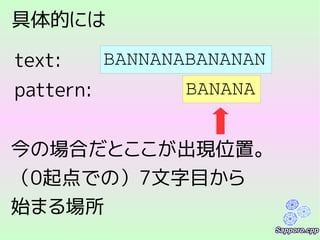
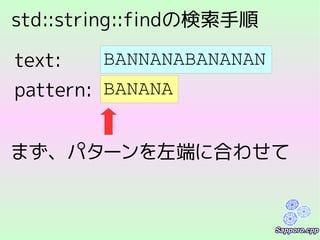
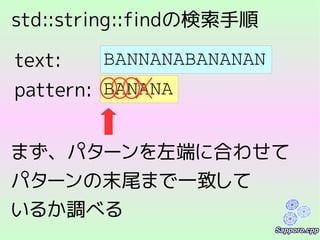
索引の方式2:
すべての部分文字列を保存する
1 2 34 5 6
P E O P L E
P
E
O
P
L
E
E
L
E
O
P
L
O
P
L
Suffix tree:
●
完全に木構造ですべての
部分文字列を格納
●
検索は超高速(木を順に
辿るだけ)
●
ただしメモリはものすごく
食う(ポインタを
文字数×5以上は使う)
E
E
60.
索引の方式2:
すべての部分文字列を保存する
1 2 34 5 6
P E O P L E Suffix array:
●
辞書順で並べて
左端の配列だけ保存
●
容量は小さめ(文字列長×
ポインタサイズ)
●
ただし、suffix treeに
比べると検索のオーバー
ヘッドが大きい
6 E
2 E O P L E
5 L E
3 O P L E
1 P E O P L E
4 P L E




































































































![アルゴリズムのお勉強 アルゴリズムとデータ構造 [素数・文字列探索・簡単なソート]](https://cdn.slidesharecdn.com/ss_thumbnails/random-160606142552-thumbnail.jpg?width=640&height=640&fit=bounds)
























