言語処理学会第20回年次大会(2014/3)のチュートリアル講義資料です。
- 要旨 -
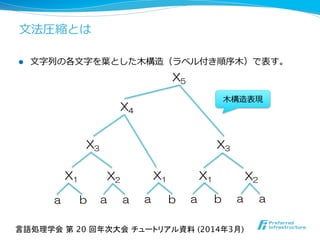
文法圧縮とは,入力テキストをよりコンパクトな文脈自由文法(CFG)に変換する圧縮法の総称である. 文法圧縮の強みは圧縮テキストを展開すること無く,検索等のテキスト処理を効率よく行える点にある. 驚くべきことにその処理速度は,元テキスト上での同じ処理を理論的に,時には実際にも凌駕する. また近年,ウェブアーカイブやログ,ゲノム配列等の大規模実データを高効率に圧縮できることで注目を集めている. しかしながら,文法圧縮についての初学者向けの解説資料はまだまだ少ない. そこで本チュートリアルでは,文法圧縮の歴史的背景から最新動向までを幅広く紹介する. 具体的には文法変換アルゴリズム,圧縮テキスト上での文字列パターン検索,文法圧縮に基づく省メモリデータ構造等の解説を行う.





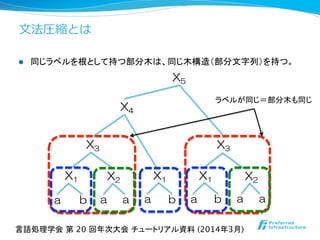
![⽂文法圧縮の枠組み
l ⽂文法圧縮の枠組みを提唱した⼈人達
l Kieffer, J. C.; Yang, E.-H. (2000),
“Grammar-based codes: A new class of universal lossless
source codes”, IEEE Trans. Inform. Theory 46 (3): 737–754
l Kiefferらの前に⽂文法圧縮に基づく圧縮法(表現)を提案した研究
l Sequitur [Nevill-Manning+ ’94],
l SLP [Karpinski+ ’97],
l Greedy [Apostlico+ ’98],
l Re-Pair [Larsson+ ’99].
言語処理学会 第 20 回年次大会 チュートリアル資料 (2014年3月)](https://image.slidesharecdn.com/nlp2014maruyamagrammar-140318191120-phpapp01/85/NLP2014-6-320.jpg)

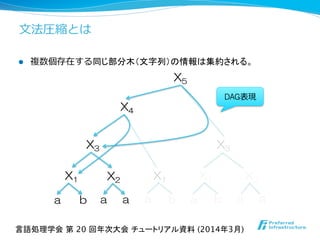
![⽂文法圧縮の強み
l 冗⻑⾧長度度の⾼高いデータに強力
l Navarro, G. (2012): “Indexing Highly Repetitive Collection”, IWOCA.
l 繰り返しを多く含むようなデータの例例
l ゲノム集合、⽂文書レポジトリ、ウェブ履履歴など
gzip bzip2 ppmdi
Re-Pair
(⽂文法圧縮)
LZMA
(LZ77)
圧縮率率率[%] 27.70% 26.34% 24.88% 2.80% 1.46%
0.00%
5.00%
10.00%
15.00%
20.00%
25.00%
30.00%
圧縮率率率[%]
出芽酵母菌36個体に対する圧縮率
言語処理学会 第 20 回年次大会 チュートリアル資料 (2014年3月)
※ 引用元 http://pizzachili.dcc.uchile.cl/repcorpus/statistics.pdf](https://image.slidesharecdn.com/nlp2014maruyamagrammar-140318191120-phpapp01/85/NLP2014-8-320.jpg)
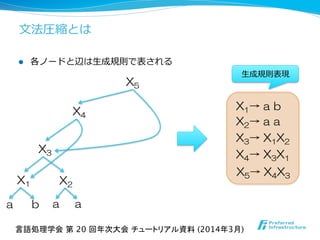
![l ⽂文法圧縮に適⽤用可能な圧縮⽂文字列列処理理アルゴリズム
l パターン照合とその変種
l [Karpinski+ ’97]; [Miyazaki+ ’97]; [Kida+ ’03]; [Cégielski+ ’06];
[Lifshits ’07]; [Tiskin ’11]; [Yamamoto+ ’11]; etc.
l 特徴的パターン発⾒見見
l [Inenaga+ ’12]; [Matsubara+ ’09];
l 最⻑⾧長⼀一致部分列列 / 編集距離離計算
l [Tiskin ’08]; [Hermelin+ ’09, ’13]
l 等価判定
l [Lifshits ’07]
などなど
⽂文法圧縮の強み
言語処理学会 第 20 回年次大会 チュートリアル資料 (2014年3月)](https://image.slidesharecdn.com/nlp2014maruyamagrammar-140318191120-phpapp01/85/NLP2014-10-320.jpg)
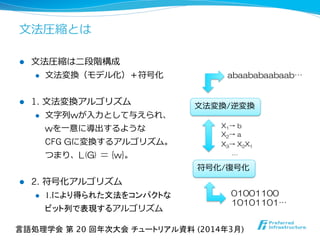
![⽂文法圧縮の強み
l ⽂文法圧縮を利利⽤用した圧縮データ構造
l ランダムアクセス可能な圧縮⽂文字列列
l [Bille+ ’11]; [Maruyama+ ’13b]
l 完備索索引付辞書
l [Navarro+ ’11]
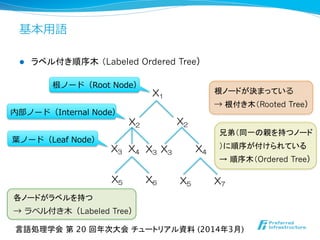
l ラベル付き順序木
l [Lohrey+ ’11]
l グラフ (ウェブデータ)
l [Claude+ ’10a, ’10b]
l キーワード辞書
l [Brisaboa+ ’11]
l 圧縮接尾辞配列列
l [González+ ’07] などなど
言語処理学会 第 20 回年次大会 チュートリアル資料 (2014年3月)](https://image.slidesharecdn.com/nlp2014maruyamagrammar-140318191120-phpapp01/85/NLP2014-12-320.jpg)








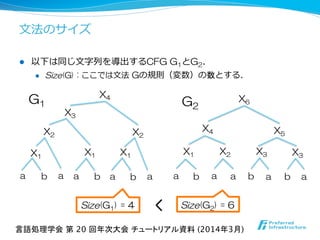
![l 最⼩小CFG問題 [Charikar+ ʼ’05]
l 近似率
l ⽂文法圧縮アルゴリズムの理理論論性能
アルゴリズムの⽣生成した⽂文法サイズ
最⼩小CFGのサイズ
近似率率率 =
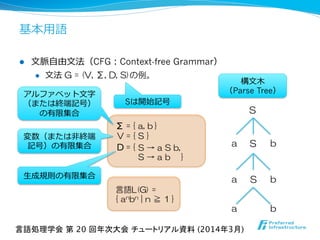
入力:文字列w.
出力:wを一意に導出する最小サイズのCFG.
NP困難問題
言語処理学会 第 20 回年次大会 チュートリアル資料 (2014年3月)
⽂文法変換アルゴリズム](https://image.slidesharecdn.com/nlp2014maruyamagrammar-140318191120-phpapp01/85/NLP2014-31-320.jpg)

![⽂文法変換アルゴリズム
l 貪欲アルゴリズム
l Bisection / Multilevel Pattern Matching [Kieffer+ ʼ’00]
l Sequitur [Nevill-‐‑‒Manning+ ʻ‘97]
l Re-‐‑‒Pair [Larsson+ ʼ’99]
l LFS2 [Nakamura+ ʼ’09]
l GREEDY [Apostlico+ ʻ‘98]
l 近似アルゴリズム
l O(log (n/g*))近似アルゴリズム
l [Charikar+, ʼ’05]; [Rytter, ʼ’03]; [Jez, ʻ‘13]
l その他の近似アルゴリズム
l [Sakamoto+, ʼ’04, ʼ’09]; [Gagie+, ʼ’10];
OLCA [Maruyama+, ʼ’12, ʼ’13, ʼ’14]
言語処理学会 第 20 回年次大会 チュートリアル資料 (2014年3月)](https://image.slidesharecdn.com/nlp2014maruyamagrammar-140318191120-phpapp01/85/NLP2014-33-320.jpg)


![Re-Pair
l 利利点
l 単純な戦略略だが⾼高い圧縮率率率
l 短い部分⽂文字列列の繰り返しをうまく捕らえることができる
l 規則の右辺が⼆二⽂文字に制限されているため扱い易易い
l ⽋欠点
l ⾼高速に(線形時間で)動作させるためには複雑な実装が必要
l 使⽤用メモリ量量が多い
l ⼊入⼒力力テキスト⻑⾧長の20倍ほど(1バイト⽂文字、4バイト整数のとき)
l Re-Pairの亜種
l Re-Merge [Wan+ ’07],
l Approximate Re-Pair [Claude+ ’10a],
l Re-Pair VF [Yoshida+ ’13] など
言語処理学会 第 20 回年次大会 チュートリアル資料 (2014年3月)](https://image.slidesharecdn.com/nlp2014maruyamagrammar-140318191120-phpapp01/85/NLP2014-36-320.jpg)

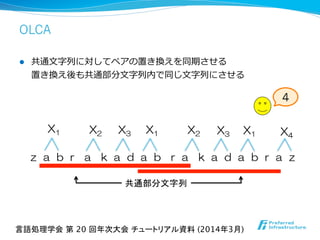
![l テクニック
l 記号の順序関係を利利⽤用する.
l ⽂文字列列中の極値や連続⽂文字を⽬目印とする.
例) 極小⽂文字 (w[i-1] > w[i] < w[i+1]) の⽬目印
X1 X2 X3 X1 X2 X3 X1 X4
z a b r a k a d a b r a k a d a b r a z
w[i, i+1]を置換え.
順序: … < a < b < c < … < z …
共通部分文字列
言語処理学会 第 20 回年次大会 チュートリアル資料 (2014年3月)
OLCA](https://image.slidesharecdn.com/nlp2014maruyamagrammar-140318191120-phpapp01/85/NLP2014-40-320.jpg)
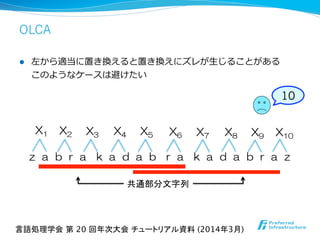
![OLCA
l アルゴリズムの動き
l 置き換えを1⽂文字になるまで再帰的に繰り返す。
l ⼀一回のループで3⽂文字中の2⽂文字は必ず置き換える。
ab b aba
a
X4
X1
X2
X1 X1
X3 X2
a
X2
w1
w2
w3
w4
w5
オフライン型
[Sakamoto+,‘04]
OLCA [Maruyama+, ‘12]
aa
X1
構⽂文⽊木の⾼高さは
O(log n).
言語処理学会 第 20 回年次大会 チュートリアル資料 (2014年3月)](https://image.slidesharecdn.com/nlp2014maruyamagrammar-140318191120-phpapp01/85/NLP2014-41-320.jpg)
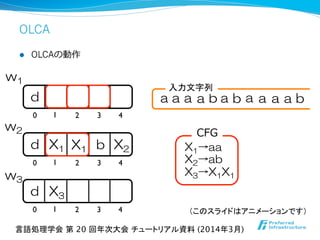
![OLCA
l 利利点
l 実装が容易易(隣隣り合う記号の⼤大⼩小⽐比較、置き換えのためのキュー)
l メモリ領領域が出⼒力力⽂文法のサイズで抑えられる
l ⽋欠点
l 実験的にはRe-Pairの⽅方が良良い圧縮率率率を達成できる
l 圧縮しにくいデータについてはメモリ効率率率が悪い
l OLCAの改良良版
l FOLCA (Fully-Online LCA)[Maruyama+ ’13]
l Lossy-FOLCA [Maruyama+ ’14]
言語処理学会 第 20 回年次大会 チュートリアル資料 (2014年3月)](https://image.slidesharecdn.com/nlp2014maruyamagrammar-140318191120-phpapp01/85/NLP2014-43-320.jpg)

![⽂文法の符号化
l POSLP(Post-order Partial Parse Tree)表現 [Maruyama+, ’12]
l 規則を⽊木構造で表し、⼆二分⽊木の括弧列列表現で符号化
X1→a b
X2→X1a
X3→X1 X2
X4→X3 X2
④
Y1
a
③
②
b
Y2
a
①
( a ( b ) ( a ) ( Y1 ) ( Y2 )
CFG
( (
(
(
(
)
)
)
)
POSLP表現
b
X2
a
X1
a
X2
X1
X4
X3
言語処理学会 第 20 回年次大会 チュートリアル資料 (2014年3月)
約 glog g + 2gビット](https://image.slidesharecdn.com/nlp2014maruyamagrammar-140318191120-phpapp01/85/NLP2014-45-320.jpg)
![⽂文法の符号化
l g 変数のSLPを表現するための理理論論的に最⼩小のビット数
(情報理理論論的下限値)[Tabei+ ’13]
l glog g + g + o(g)ビット
l POSLPの利利点
l 符号化したまま各⽣生成規則にO(1)時間でアクセス可能。
l 符号化列列をオンラインで元⽂文字列列へ復復元可能。
l 類似した符号化アイデア
l [González+ ’07]; [Claude+ ’10b, ’12] など
言語処理学会 第 20 回年次大会 チュートリアル資料 (2014年3月)](https://image.slidesharecdn.com/nlp2014maruyamagrammar-140318191120-phpapp01/85/NLP2014-46-320.jpg)

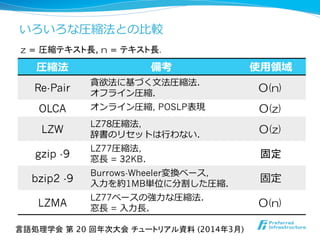
![実験:圧縮率率率 [%] (圧縮サイズ/⼊入⼒力力サイズ)
0.00
5.00
10.00
15.00
20.00
25.00
30.00
35.00
40.00
45.00
LCA-online
LZW
gzip -9
bzip2 -9
Re-Pair
LZMA
言語処理学会 第 20 回年次大会 チュートリアル資料 (2014年3月)
OLCA](https://image.slidesharecdn.com/nlp2014maruyamagrammar-140318191120-phpapp01/85/NLP2014-49-320.jpg)
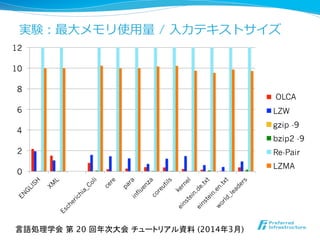
![実験:⼊入⼒力力1MBあたりの平均圧縮時間 [sec]
0
0.5
1
1.5
2
2.5
3
3.5
lca_online
LZW
gzip -9
bzip -9
Re-Pair
LZMA
言語処理学会 第 20 回年次大会 チュートリアル資料 (2014年3月)
OLCA](https://image.slidesharecdn.com/nlp2014maruyamagrammar-140318191120-phpapp01/85/NLP2014-51-320.jpg)






![l 様々な圧縮法に対する圧縮パターン照合の研究
l 連⻑⾧長符号
l [Eilam-Tzoreff+ ’88]; [Amir+ ’92, ’97];
l ハフマン符号
l [Fukamachi+ ’92]; [Miyazaki+ ’98]; [Klein+ ’01];
l LZ77系
l [Farach+ ’95]; [Gasieniec+ ‘96]; [Klein+ ’00];
[Gawrychowski ’11a]; etc.
l LZ78系
l [Amir+ ’96]; [Kida+ ‘98, ’99]; [Navarro+ ’00];
[Kärkkäinen+ ’00]; [Gawrychowski ’11b]; etc.
l LZ系
l [Navarro+ ’99, ’04];
圧縮パターン照合
言語処理学会 第 20 回年次大会 チュートリアル資料 (2014年3月)](https://image.slidesharecdn.com/nlp2014maruyamagrammar-140318191120-phpapp01/85/NLP2014-59-320.jpg)
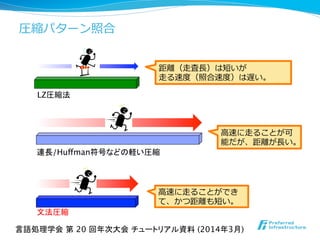
![テキスト:
状態遷移:
0
3
3
4
5
1
2
4
1
a b a b a b b a
5
l ⽂文法圧縮に対する圧縮パターン照合アルゴリズム [Kida+, ‘03]
a
0 1 2 4 5
b
3任意の
文字
-1
a b
パターン P=a b a b bを受理するKMPオートマトン
b
: goto
: failure
圧縮パターン照合
*図は状態遷移を計算するJump関数の例.パターンの出現を報告するOutput関数は省略.
a b X1 X3
S S : 開始規則の右辺
D : 開始規則以外の生成規則
言語処理学会 第 20 回年次大会 チュートリアル資料 (2014年3月)
X1 → ab,X2 → ba,
X3 → X1X2
D](https://image.slidesharecdn.com/nlp2014maruyamagrammar-140318191120-phpapp01/85/NLP2014-61-320.jpg)
![テキスト:
状態遷移:
0
3
3
4
5
1
2
4
1
S : a b X1 X3
a b a b a b b a
5
l ⽂文法圧縮に対する圧縮パターン照合アルゴリズム [Kida+, ‘03]
a
0 1 2 4 5
b
3任意の
文字
-1
a b
パターン P=a b a b bを受理するKMPオートマトン
b
: goto
: failure
X1
圧縮パターン照合
*図は状態遷移を計算するJump関数の例.パターンの出現を報告するOutput関数は省略.
言語処理学会 第 20 回年次大会 チュートリアル資料 (2014年3月)
a b X1 X3
S S : 開始規則の右辺
D : 開始規則以外の生成規則
X1 → ab,X2 → ba,
X3 → X1X2
D](https://image.slidesharecdn.com/nlp2014maruyamagrammar-140318191120-phpapp01/85/NLP2014-62-320.jpg)
![テキスト:
状態遷移:
0
3
3
4
5
1
2
4
1
S : a b X1 X3
a b a b a b b a
5
l ⽂文法圧縮に対する圧縮パターン照合アルゴリズム [Kida+, ‘03]
a
0 1 2 4 5
b
3任意の
文字
-1
a b
パターン P=a b a b bを受理するKMPオートマトン
b
: goto
: failure
O(|D|+|P|2)の前処理時間・領域
X1
走査時間:O(|S|+Pの出現回数)
*図は状態遷移を計算するJump関数の例.パターンの出現を報告するOutput関数は省略.
圧縮パターン照合
言語処理学会 第 20 回年次大会 チュートリアル資料 (2014年3月)
a b X1 X3
X1 → ab,X2 → ba,
X3 → X1X2
S
D
S : 開始規則の右辺
D : 開始規則以外の生成規則](https://image.slidesharecdn.com/nlp2014maruyamagrammar-140318191120-phpapp01/85/NLP2014-63-320.jpg)
![圧縮パターン照合
l 実際に⾼高速な圧縮パターン照合を実現するための問題
l 前処理理コスト(オートマトンの構築時間)
l ビット処理理のオーバーヘッド
l キャッシュヒット率率率 などなど
l 圧縮パターン照合アルゴリズムに特化した⽂文法圧縮の開発
l BPE (Byte-Pair-Encoding) [Shibata+ ’00].
l BPE using Byte-Huffman [Matsumoto+ ’09].
l BPEX [Maruyama+ ’10].
言語処理学会 第 20 回年次大会 チュートリアル資料 (2014年3月)](https://image.slidesharecdn.com/nlp2014maruyamagrammar-140318191120-phpapp01/85/NLP2014-64-320.jpg)
![圧縮パターン照合
KMP
KMP on BPE
KMP on BPEX
BMH
BMH on SE
SE
BPE
BPEX
言語処理学会 第 20 回年次大会 チュートリアル資料 (2014年3月)
l 実験結果
l 検索索時間はCPU時間。I/O時間を含めるとBPEXはさらに有利利。
l SE(Stopper Encoding)[Rautio+ ’02] : BM型検索索のための符号化](https://image.slidesharecdn.com/nlp2014maruyamagrammar-140318191120-phpapp01/85/NLP2014-65-320.jpg)
![圧縮索索引
l 代表的な全⽂文検索索索索引
l n-グラム索索引(n-gram index)、接尾辞配列列(Suffix Array) など
l 圧縮⾃自⼰己索索引(Compressed Self-Indexes) [Navarro+, ‘07]
l 元の⽂文書データを陽に持たずに次の操作をサポートするデータ構造
l パターンの出現回数報告
l パターンの出現位置報告
l 部分⽂文字列列復復元
l よく知られている圧縮⾃自⼰己索索引
l 圧縮接尾辞配列列(CSA : Compressed Suffix Array)、
FM-index、LZ78-indexなど
言語処理学会 第 20 回年次大会 チュートリアル資料 (2014年3月)](https://image.slidesharecdn.com/nlp2014maruyamagrammar-140318191120-phpapp01/85/NLP2014-66-320.jpg)
![圧縮索索引
l SLPに基づく⾃自⼰己索索引 [Claude+, ’11]
l Claude, F. ; Navarro, G. (2011) : Self-Indexed Grammar-Based
Compression. Fundam. Inform. 111(3): 313-337.
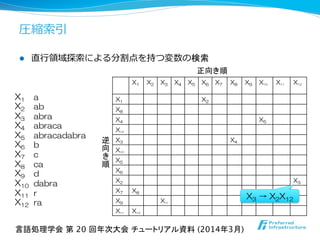
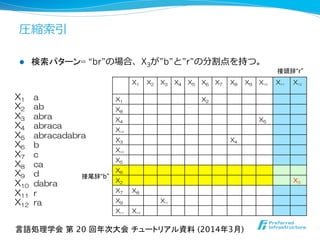
l パターンP[1 .. m]が与えられた時に
l Xi → XjXkと整数s (1 ≦ s ≦ m-‐‑‒1)に対して
Xjが表す文字列の接尾辞にP[1 .. s]、
Xkが表す⽂文字列列の接頭辞にP[s+1 .. m]
を持つ時に、XiはPの分割点を持つ変数。
l 出現回数の計算のために分割点を持つ全ての
変数を列列挙する。
言語処理学会 第 20 回年次大会 チュートリアル資料 (2014年3月)
Xj Xk
Xi
P[1 .. s]
P[s+1 .. m]
分割点](https://image.slidesharecdn.com/nlp2014maruyamagrammar-140318191120-phpapp01/85/NLP2014-67-320.jpg)

![圧縮索索引
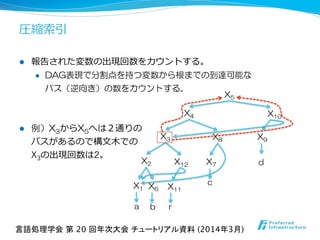
l パターンP[1 .. m]の出現回数の計算時間
l パターンPの可能な分割点(m-1通り)に対して以下を実⾏行行する。
l 接頭辞 / 接尾辞の範囲の計算は変数を辞書順に並べた配列列を⽤用意、
変数の接頭辞 / 接尾辞を部分的に展開しながら⼆二分探索索を⾏行行う。
‒ O(mlog g + h)時間, hは構⽂文⽊木の最⼤大の⾼高さ。
l 直⾏行行領領域探索索はウェーブレット⽊木を使って効率率率的に計算可能。
‒ O(log g + k)時間, k = 指定領領域に含まれる報告点数。
‒ 詳しくは「ウェーブレット⽊木の世界」をご参照ください。
‒ http://research.preferred.jp/2013/01/wavelettree_world/
l 分割点を持つ変数Xiの出現回数の計算
‒ O(Xiの出現回数 × h)時間
言語処理学会 第 20 回年次大会 チュートリアル資料 (2014年3月)](https://image.slidesharecdn.com/nlp2014maruyamagrammar-140318191120-phpapp01/85/NLP2014-72-320.jpg)
![圧縮索索引
l 特徴
l 出現回数の他にも位置報告/部分⽂文字列列復復元をサポート。
l 任意の⽂文法圧縮テキストを索索引構造に変換可能。
l 簡潔データ構造を利利⽤用することでコンパクトな領領域で実装可能。
l 改良良版 [Claude+ ’12] では検索索時間が構⽂文⽊木の⾼高さに依存しない。
l 応⽤用
l ゲノムデータ集合のn-‐‑‒gram索索引 [Claude+ ʼ’10c]
l バージョン管理された文書集合に対する⽂文書列列挙 [Claude+ ’13]
l その他の⽂文法圧縮に関係する索索引構造
l ESP-index [Maruyama+ ’11]
l Balanced SLP+LZ77-index [Gagie+ ’12]
言語処理学会 第 20 回年次大会 チュートリアル資料 (2014年3月)](https://image.slidesharecdn.com/nlp2014maruyamagrammar-140318191120-phpapp01/85/NLP2014-73-320.jpg)

![圧縮データ構造
l ⽂文法圧縮を利利⽤用した圧縮データ構造
l ランダムアクセス可能な圧縮⽂文字列列
l [Bille+ ’11]; [Maruyama+ ’13b]
l 完備索索引付辞書
l [Navarro+ ’11]
l ラベル付き順序木
l [Lohrey+ ’11]
l グラフ (ウェブデータ)
l [Claude+ ’10a, ’10b]
l キーワード辞書
l [Brisaboa+ ’11]
l 圧縮接尾辞配列列
l [González+ ’07] などなど
言語処理学会 第 20 回年次大会 チュートリアル資料 (2014年3月)](https://image.slidesharecdn.com/nlp2014maruyamagrammar-140318191120-phpapp01/85/NLP2014-76-320.jpg)
![ランダムアクセス可能な圧縮⽂文字列列
l ⽬目的
l 既に圧縮されているデータの任意の1⽂文字(または部分⽂文字列列)
のみを⾼高速に参照したい。
l これができるとテキスト等に限らず、
データ構造を圧縮したまま扱うことができる。
l 実⽤用的な研究成果
l [Brisaboa+ ’09]
l DAC: Directly Addressable Codes
l dag_vector (implemented by Okanohara, D.)
l [Kreft+ ’10]
l LZ-End, LZ-Begin
言語処理学会 第 20 回年次大会 チュートリアル資料 (2014年3月)](https://image.slidesharecdn.com/nlp2014maruyamagrammar-140318191120-phpapp01/85/NLP2014-77-320.jpg)

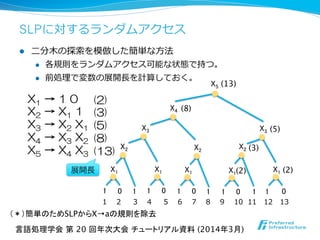
![SLPに対するランダムアクセス
l ⼆二分⽊木の探索索を模倣した簡単な⽅方法
l 開始規則から⽬目的の位置まで展開⻑⾧長を利利⽤用して
部分的な復復元を⾏行行う。
X1 → 1 0
X2 → X1 1
X3 → X2 X1
X4 → X3 X2
X5 → X4 X3
(2)
(3)
(5)
(8)
(13)
X1
1
0
X1
1
0
X1
1
0
X1
1
0
X1
1
0
1
1
1
X2
X2
X2
X3
X3
X4
X5
(13)
(5)
(3)
(2)
(2)
1 2 3 4 5 6 7 8 9 10 11 12 13
w[10…12]にアクセス
展開長
言語処理学会 第 20 回年次大会 チュートリアル資料 (2014年3月)
(8)
(*)簡単のためSLPからX→aの規則を除去](https://image.slidesharecdn.com/nlp2014maruyamagrammar-140318191120-phpapp01/85/NLP2014-80-320.jpg)
![ランダムアクセス可能な圧縮⽂文字列列
l ⽂文法圧縮の場合の問題点
l 計算時間がO(構⽂文⽊木の⾼高さ)に依存する
l Re-‐‑‒Pairの場合、最悪時の⾼高さが抑えられないので問題
l OCLA[Maruyama+, ʼ’12]が⽣生成する⽂文法は⾼高さO(log n)で抑えられる
l バランスした構⽂文⽊木への変換アルゴリズム[Rytter ʼ’03]
l [Bille+ ʼ’11]は、構⽂文⽊木がバランスしていなくてもO(log n)時間で
任意の⽂文字(部分⽂文字列列)を報告できるデータ構造を提案
l [Maruyama+ ʼ’13]では、POSLP上でランダムアクセスと
データの末尾追加をサポートするデータ構造を提案
言語処理学会 第 20 回年次大会 チュートリアル資料 (2014年3月)](https://image.slidesharecdn.com/nlp2014maruyamagrammar-140318191120-phpapp01/85/NLP2014-81-320.jpg)

![完備索索引付辞書
l ビット⽂文字列列 B[1 .. n], B[i] ∈{0, 1} に対して次の操作をサポート
l Lookupc(B, i) : B[i]を返す
l Rankc(B, i) : B[1 .. i]に含まれる c の数
l Selectc(B, i) : Bに現れる i 番⽬目の c の位置
l ここではSLPによる完備索索引付辞書の実現⽅方法を解説
B[1, 6]に含まれる1の数
3番目に現れる0の位置
B 011101100
i 123456789
Rank1 (B, 6)=4 Select0 (B, 3)=8
言語処理学会 第 20 回年次大会 チュートリアル資料 (2014年3月)](https://image.slidesharecdn.com/nlp2014maruyamagrammar-140318191120-phpapp01/85/NLP2014-83-320.jpg)
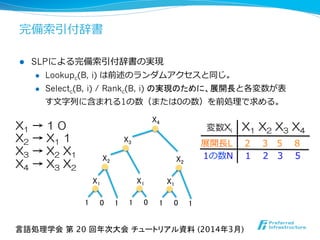
![完備索索引付辞書
l Select1(B, i)の計算
l 1の数Nを参照することで、根から i 番⽬目の1までのパスを辿る。
l 辿ってきたパスよりも左側に出現する変数の展開⻑⾧長Nを参照する
ことで対象となる1の位置を計算する。
言語処理学会 第 20 回年次大会 チュートリアル資料 (2014年3月)
X1 → 1 0
X2 → X1 1
X3 → X2 X1
X4 → X3 X2
展開⻑⾧長L 2 3 5 8
変数Xi X1 X2 X3 X4
X1
1
0
X1
1
0
X1
1
0
1
1
X2
X2
X3
X4
1の数N 1 2 3 5
(3)
(2)
(1)
(2)
(3)
Select1 (B, 3) = L[2] + 1 = 4](https://image.slidesharecdn.com/nlp2014maruyamagrammar-140318191120-phpapp01/85/NLP2014-85-320.jpg)
![完備索索引付辞書
l Rank1(B, i)の計算
l Lookupと同様に展開⻑⾧長Lを使って、根からB[i]までのパスを辿る。
l 辿ってきたパスよりも左側に現れる変数の1の数Nを合計し、
B[1 .. i]に含まれる1の数を計算する。
言語処理学会 第 20 回年次大会 チュートリアル資料 (2014年3月)
X1 → 1 0
X2 → X1 1
X3 → X2 X1
X4 → X3 X2
X1
1
0
X1
1
0
X1
1
0
1
1
X2
X2
X3
X4
(2)
(3)
(5)
(3)
(2)
Rank1 (B, 4) = N[2] + 1 = 3
展開⻑⾧長L 2 3 5 8
変数Xi X1 X2 X3 X4
1の数N 1 2 3 5](https://image.slidesharecdn.com/nlp2014maruyamagrammar-140318191120-phpapp01/85/NLP2014-86-320.jpg)
![完備索索引付辞書
l Select0(B, i)とRank0(B, i)の計算
l 変数Xiの0の数=L[i] – N[i]。
l c=1の場合と同様に計算できる。
l 計算時間
l ランダムアクセス同様に構文木の⾼高さに依存
l Re-Pairによる完備索索引付辞書の実⽤用的な実装 [Navarro+ ’11]
l ⼀一般のアルファベット⽂文字に対するRank/Select操作まで拡張
l ⽂文書配列列(⽂文書列列挙問題)を効率率率よく圧縮して扱えることを実験
的に⽰示した。
言語処理学会 第 20 回年次大会 チュートリアル資料 (2014年3月)](https://image.slidesharecdn.com/nlp2014maruyamagrammar-140318191120-phpapp01/85/NLP2014-87-320.jpg)



![公開ソフトウェア
l Re-Pair [Larsson+ ’99]
l http://ihome.cuhk.edu.hk/~b126594/ja/restore.html
l https://code.google.com/p/re-pair/
l http://www.dcc.uchile.cl/~gnavarro/software/
l Re-Pairに基づくラベル付き順序⽊木の圧縮データ構造 [Lohrey+ ’11]
l https://code.google.com/p/treerepair/
l Re-Pairに基づくウェブグラフの圧縮データ構造 [Claude+ ’10b]
l http://webgraphs.recoded.cl/index.php?section=rpgraph
l OLCA [Maruyama+ ’10]
l https://code.google.com/p/lcacomp/
l Sequitur [Nevill-Manning+ ’97]
l http://www.sequitur.info/
言語処理学会 第 20 回年次大会 チュートリアル資料 (2014年3月)](https://image.slidesharecdn.com/nlp2014maruyamagrammar-140318191120-phpapp01/85/NLP2014-91-320.jpg)

![参考⽂文献
[Amir+ ’92] "Efficient Two-Dimensional Compressed Matching", DCC.
[Amir+ ’96] "Let Sleeping Files Lie: Pattern Matching in Z-Compressed Files", J. Comput. Syst.
Sci.
[Amir+ ’97] "Optimal Two-Dimensional Compressed Matching", J. Algorithms.
[Apostlico+ ’98] “Some Theory and Practice of Greedy Off-Line Textual Substitution”, DCC.
[Bille+ ’11] “Random Access to Grammar-Compressed Strings”, SODA.
[Brisaboa+ ’09] "Directly Addressable Variable-Length Codes", SPIRE.
[Brisaboa+ ’11] “Compressed String Dictionaries”, SEA.
[Charikar+ ’05] "The Smallest Grammar Problem", IEEE Transactions on Information Theory.
[Cégielski+ ’06] “Window Subsequence Problems for Compressed Texts”, CSR.
[Claude+ ’10a] “Fast and Compact Web Graph Representations”, TWEB.
[Claude+ ’10b] “Extended Compact Web Graph Representations”, Algorithms and Applications.
言語処理学会 第 20 回年次大会 チュートリアル資料 (2014年3月)](https://image.slidesharecdn.com/nlp2014maruyamagrammar-140318191120-phpapp01/85/NLP2014-93-320.jpg)
![参考⽂文献
[Claude+ ’10c] "Compressed Q-gram Indexing for Highly Repetitive Biological Sequences",
BIBE.
[Claude+ ’11] "Self-Indexed Grammar-Based Compression", Fundam. Inform.
[Claude+ ’12] “Improved Grammar-Based Compressed Indexes”, SPIRE.
[Claude+ ’13] "Document Listing on Versioned Documents", SPIRE.
[Eilam-Tzoreff+ ’88] "Matching Patterns in Strings Subject to Multi-Linear Transformations",
Theor. Comput. Sci.
[Gagie+ ’10] "Grammar-Based Compression in a Streaming Model”, LATA.
[Gagie+ ’12] “A Faster Grammar-Based Self-index”, LATA.
[Gawrychowski ’11a] “Pattern Matching in Lempel-Ziv Compressed Strings: Fast, Simple, and
Deterministic”, ESA.
[Gawrychowski ’11b] “Optimal Pattern Matching in LZW Compressed Strings”, SODA.
言語処理学会 第 20 回年次大会 チュートリアル資料 (2014年3月)](https://image.slidesharecdn.com/nlp2014maruyamagrammar-140318191120-phpapp01/85/NLP2014-94-320.jpg)
![参考⽂文献
[González+ ’07] "Compressed Text Indexes with Fast Locate", CPM.
[Hermelin+ ’09] "A Unified Algorithm for Accelerating Edit-Distance Computation via Text-
Compression", STACS.
[Hermelin+ ’13] "Unified Compression-Based Acceleration of Edit-Distance Computation",
Algorithmica.
[Inenaga+ ’12] “Finding Characteristic Substrings from Compressed Texts”, Int. J. Found.
Comput. Sci.
[Jez ’13] “Approximation of Grammar-Based Compression via Recompression”, CPM.
[Kärkkäinen+ ’00] "Approximate String Matching over Ziv-Lempel Compressed Text", CPM.
[Karpinski+ ’97] “An Efficient Pattern-Matching Algorithm for Strings with Short Descriptions”,
Nord. J. Comput.
[Kida+ ’98] "Multiple Pattern Matching in LZW Compressed Text", DCC.
言語処理学会 第 20 回年次大会 チュートリアル資料 (2014年3月)](https://image.slidesharecdn.com/nlp2014maruyamagrammar-140318191120-phpapp01/85/NLP2014-95-320.jpg)
![参考⽂文献
[Kida+ ’99] “Shift-And Approach to Pattern Matching in LZW Compressed Text”, CPM.
[Kida+ ’03] “Collage System: a Unifying Framework for Compressed Pattern Matching”, Theor.
Comput. Sci.
[Kieffer+ ’00] “Grammar-Based Codes: A New Class of Universal Lossless Source Codes”, IEEE
Trans. Inform. Theory.
[Klein+ ’00] “A New Compression Method for Compressed Matching”, DCC.
[Klein+ ’01] “Pattern Matching in Huffman Encoded Texts”, DCC.
[Kreft+ ’10] “LZ77-like Compression with Fast Random Access”, DCC.
[Larsson+ ’99] “Offline Dictionary-Based Compression”, DCC.
[Lifshits ’07] “Processing Compressed Texts: A Tractability Border”, CPM
[Lohrey+ ’11] "Tree Structure Compression with RePair", DCC.
言語処理学会 第 20 回年次大会 チュートリアル資料 (2014年3月)](https://image.slidesharecdn.com/nlp2014maruyamagrammar-140318191120-phpapp01/85/NLP2014-96-320.jpg)
![参考⽂文献
[Maruyama+ ’10] "Context-Sensitive Grammar Transform: Compression and Pattern Matching",
IEICE Transactions.
[Maruyama+ ’12] "An Online Algorithm for Lightweight Grammar-Based Compression”,
Algorithms.
[Maruyama+ ’13a] "ESP-Index: A Compressed Index Structure Based on Edit-Sensitive
Parsing”, J. Discrete Algorithms.
[Maruyama+ ’13b] “Fully-Online Grammar Compression”, SPIRE.
[Maruyama+ ’14] “Fully-Online Grammar Compression in Constant Space”, DCC.
[Matsubara+ ’09] “Efficient algorithms to compute compressed longest common substrings
and compressed palindromes”, Theor. Comput. Sci.
[Matsumoto+ ’09] “A Run-Time Efficient Implementation of Compressed Pattern Matching
Automata”, Int. J. Found. Comput. Sci.
言語処理学会 第 20 回年次大会 チュートリアル資料 (2014年3月)](https://image.slidesharecdn.com/nlp2014maruyamagrammar-140318191120-phpapp01/85/NLP2014-97-320.jpg)
![参考⽂文献
[Miyazaki+ ’97] “An Improved Pattern Matching Algorithm for Strings in Terms of Straight-Line
Programs”, CPM.
[Nakamura+ ’09] “Linear-Time Text Compression by Longest-First Substitution”, Algorithms.
[Navarro+ ’99] “A General Practical Approach to Pattern Matching over Ziv-Lempel Compressed
Text”, CPM.
[Navarro+ ’04] "Practical and Flexible Pattern Matching over Ziv-Lempel Compressed Text",
Journal of Discrete Algorithms.
[Navarro+ ’07] "Compressed Full-Text Indexes", ACM Computing Surveys.
[Navarro+ ’11] “Practical Compressed Document Retrieval”, SEA.
[Navarro+ ’12] “Indexing Highly Repetitive Collection”, IWOCA.
[Nevill-Manning+ ‘94] "Compression by Induction of Hierarchical Grammars”, DCC.
言語処理学会 第 20 回年次大会 チュートリアル資料 (2014年3月)](https://image.slidesharecdn.com/nlp2014maruyamagrammar-140318191120-phpapp01/85/NLP2014-98-320.jpg)
![参考⽂文献
[Nevill-Manning+ ’97] "Identifying Hierarchical Structure in Sequences: A Linear-Time
Algorithm", J. Artif. Intell. Res.
[Rautio+ ’02] “String Matching with Stopper Encoding and Code Splitting”, CPM.
[Rytter ’03] “Application of Lempel-Ziv Factorization to the Approximation of Grammar-Based
Compression”, Theor. Comput. Sci.
[Sakamoto+ ’04] "A Space-Saving Linear-Time Algorithm for Grammar-Based Compression",
SPIRE.
[Sakamoto+ ’09] "A Space-Saving Approximation Algorithm for Grammar-Based Compression"
IEICE Transactions.
[Shibata+ ’00] “Speeding Up Pattern Matching by Text Compression”, CIAC.
[Tabei+ ’13] “A Succinct Grammar Compression”, CPM.
言語処理学会 第 20 回年次大会 チュートリアル資料 (2014年3月)](https://image.slidesharecdn.com/nlp2014maruyamagrammar-140318191120-phpapp01/85/NLP2014-99-320.jpg)
![参考⽂文献
[Tiskin ’08] “Semi-local String Comparison: Algorithmic Techniques and Applications",
Mathematics in Computer Science.
[Tiskin ’11] “Towards Approximate Matching in Compressed Strings: Local Subsequence
Recognition”, CSR.
[Wan+ ’07] "Block Merging for Off-line Compression", Journal of the American Society for
Information Science and Technology.
[Yamamoto+ ’11] “Faster Subsequence and Don't-Care Pattern Matching on Compressed
Texts”, CPM.
[Yoshida+ ’13] "A Variable-length-to-fixed-length Coding Method Using a Re-Pair Algorithm",
IPSJ Transactions on Databases.
言語処理学会 第 20 回年次大会 チュートリアル資料 (2014年3月)](https://image.slidesharecdn.com/nlp2014maruyamagrammar-140318191120-phpapp01/85/NLP2014-100-320.jpg)




![[DL輪読会]Learning Transferable Visual Models From Natural Language Supervision](https://cdn.slidesharecdn.com/ss_thumbnails/dlkobayashi0115-210115012308-thumbnail.jpg?width=640&height=640&fit=bounds)










![[DL輪読会]Deep Learning 第15章 表現学習](https://cdn.slidesharecdn.com/ss_thumbnails/deeplearning15-180601023904-thumbnail.jpg?width=640&height=640&fit=bounds)



![[DL輪読会]相互情報量最大化による表現学習](https://cdn.slidesharecdn.com/ss_thumbnails/20190913iwasawa-190913002312-thumbnail.jpg?width=640&height=640&fit=bounds)






![[DL輪読会]Flow-based Deep Generative Models](https://cdn.slidesharecdn.com/ss_thumbnails/20190307-190328024744-thumbnail.jpg?width=640&height=640&fit=bounds)
![[GTCJ2018]CuPy -NumPy互換GPUライブラリによるPythonでの高速計算- PFN奥田遼介](https://cdn.slidesharecdn.com/ss_thumbnails/gtcj2018cupypfnryosukeokuta-181009073034-thumbnail.jpg?width=640&height=640&fit=bounds)










![[Basic 11] 文脈自由文法 / 構文解析 / 言語解析プログラミング](https://cdn.slidesharecdn.com/ss_thumbnails/basic-11-180306134245-thumbnail.jpg?width=640&height=640&fit=bounds)


![アルゴリズムのお勉強 アルゴリズムとデータ構造 [素数・文字列探索・簡単なソート]](https://cdn.slidesharecdn.com/ss_thumbnails/random-160606142552-thumbnail.jpg?width=640&height=640&fit=bounds)















