Download to read offline



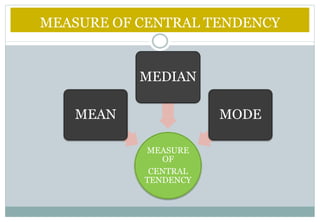
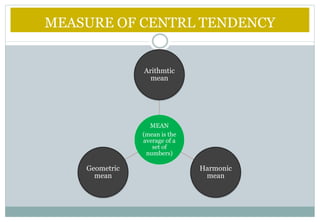
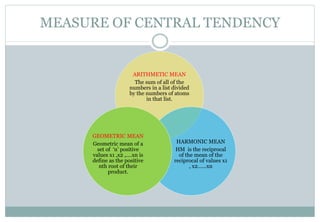
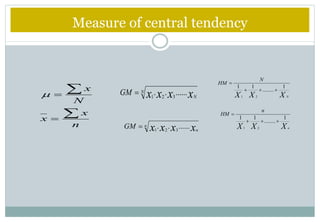
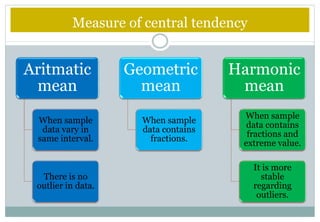
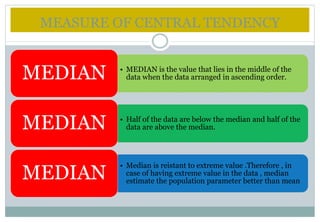


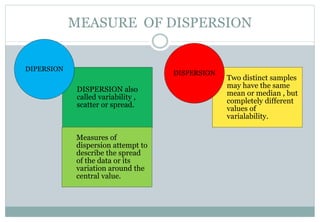
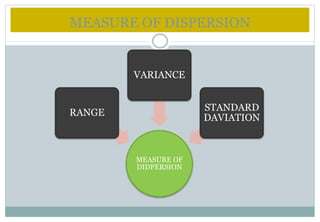









This document defines and explains various measures of central tendency and dispersion. It discusses the mean, median, mode, range, variance, and standard deviation as measures of central tendency and dispersion. It also provides the formulas to calculate the arithmetic mean, harmonic mean, geometric mean, variance, and standard deviation. Additionally, it demonstrates how to identify outliers in a data set using the lower and upper fences.












































































