Downloaded 35 times


































![METADATA
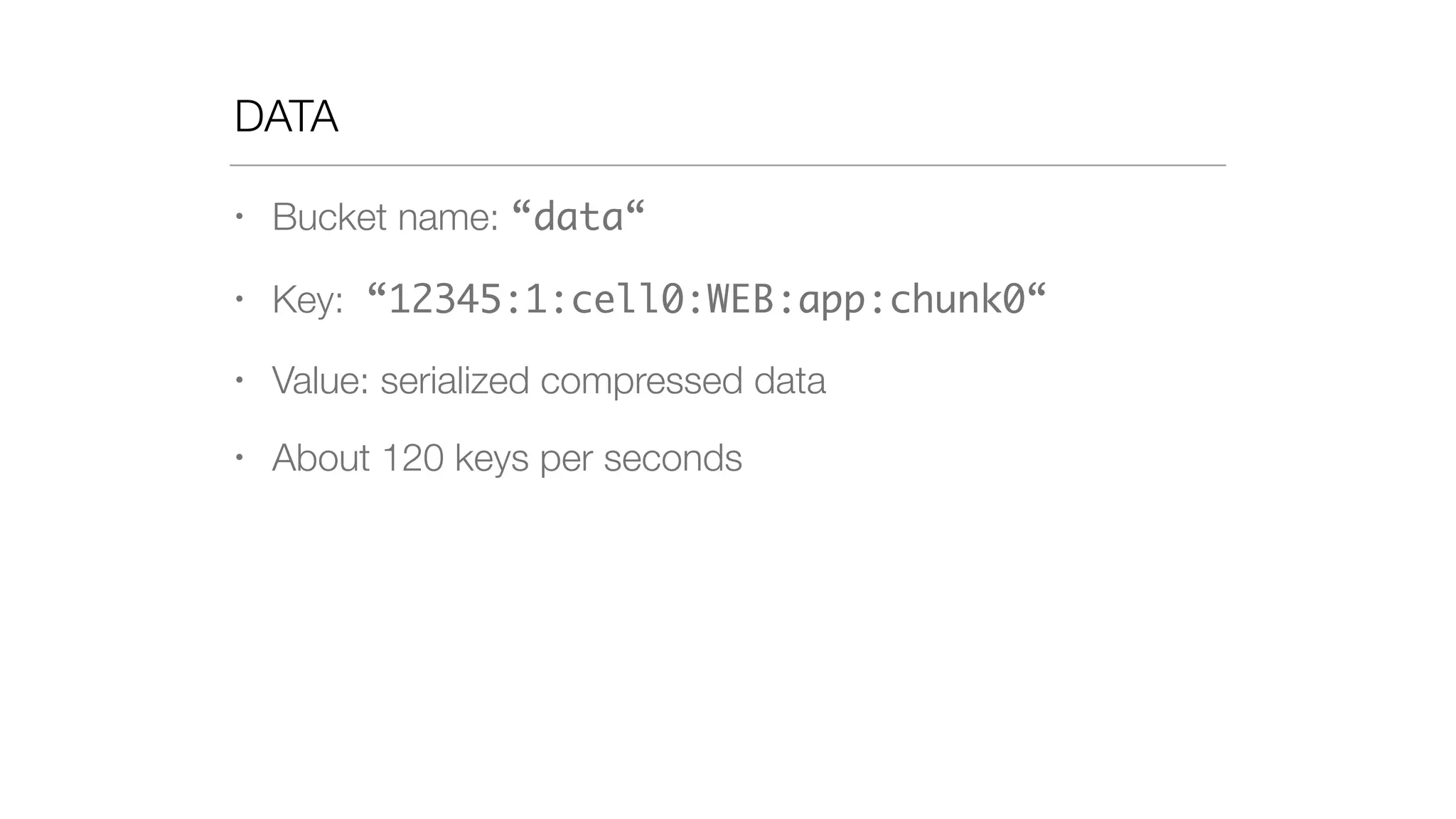
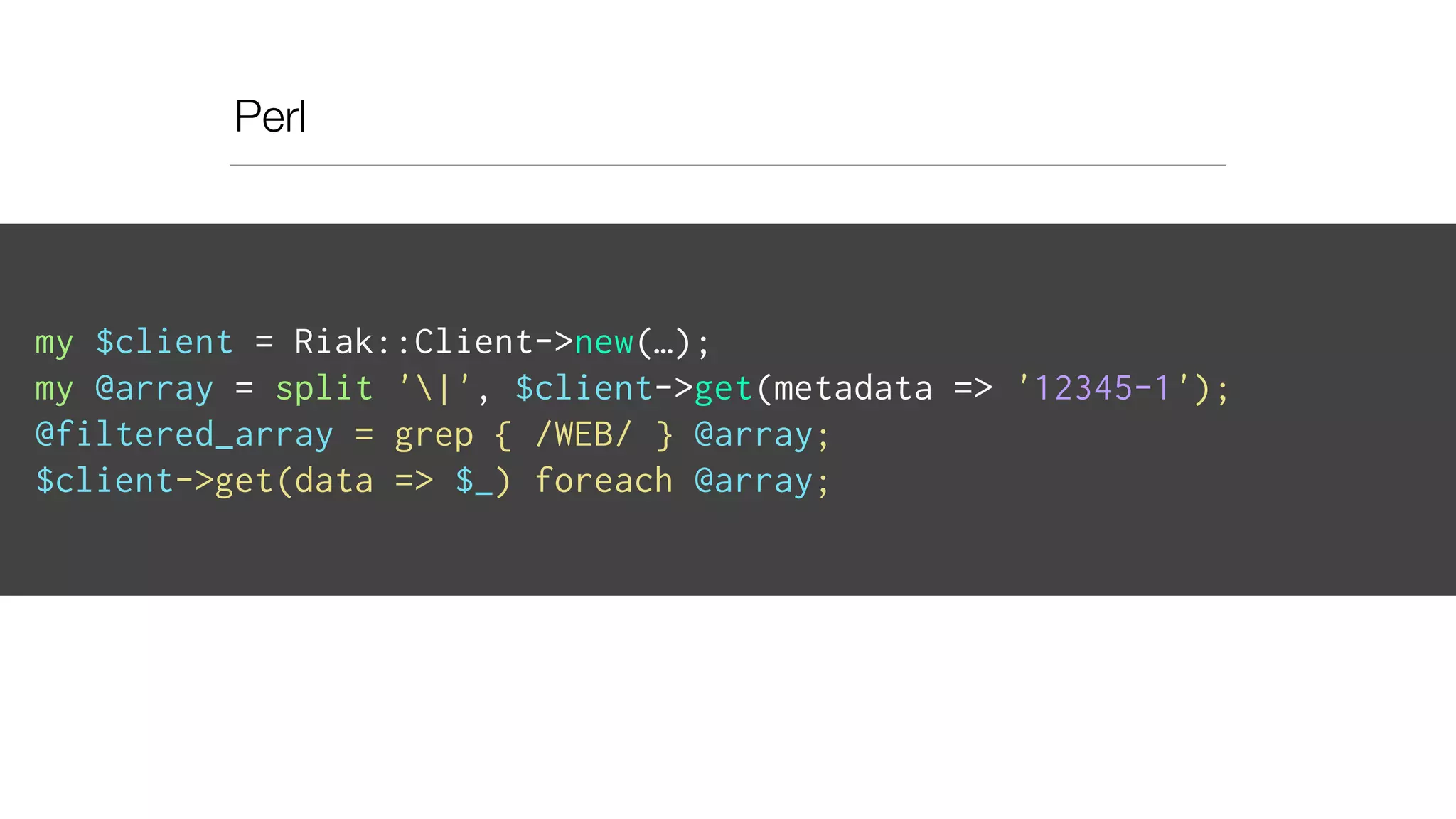
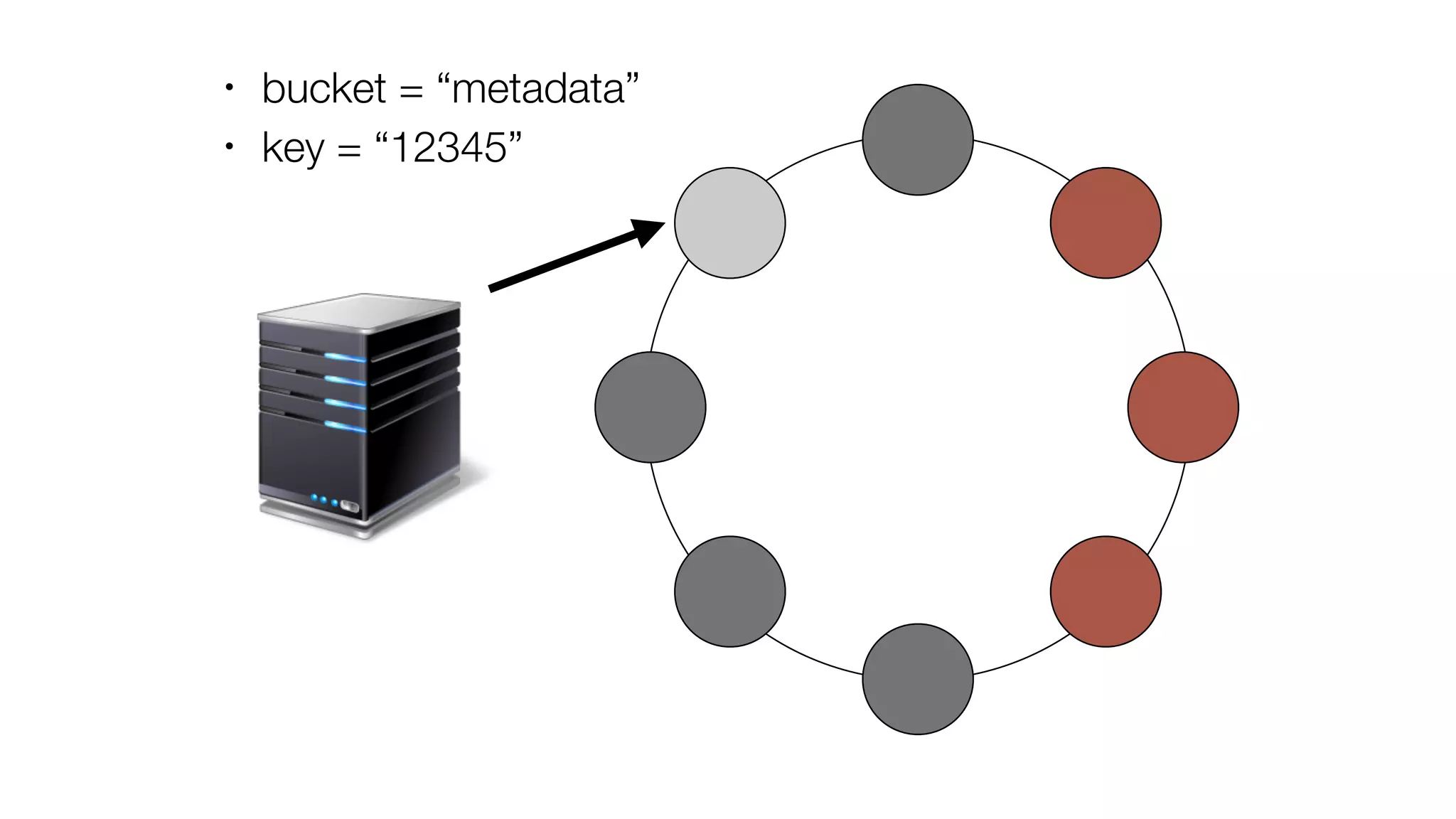
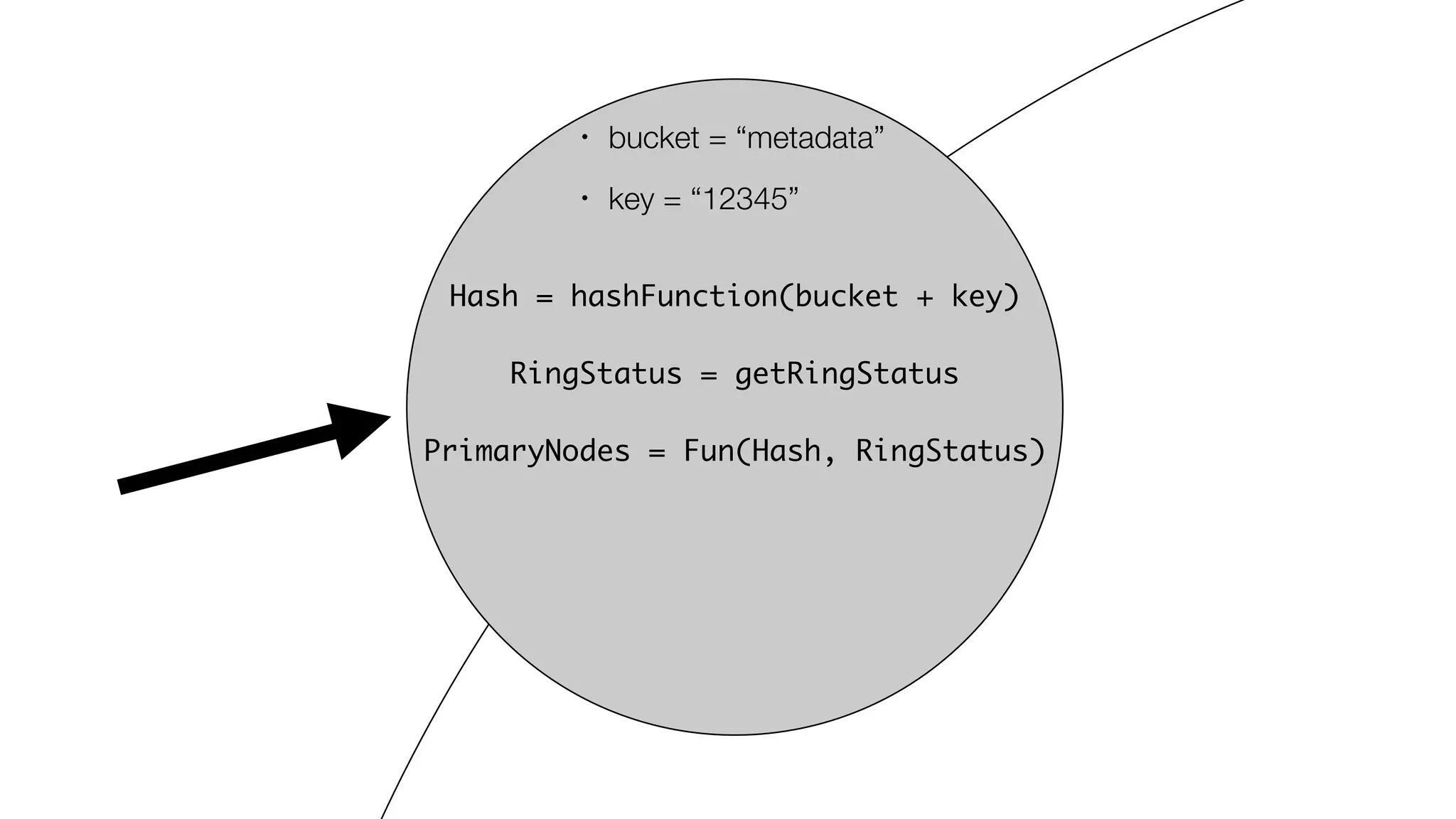
• Bucket name: “metadata“
• Key: epoch-dc “12345-2“
• Value: list of data keys:
[ “12345:1:cell0:WEB:app:chunk0“,
“12345:1:cell0:WEB:app:chunk1“
…
“12345:4:cell0:EMK::chunk3“ ]
• As pipe separated value](https://image.slidesharecdn.com/slideswide-150329114034-conversion-gate01/75/Using-Riak-for-Events-storage-and-analysis-at-Booking-com-64-2048.jpg)


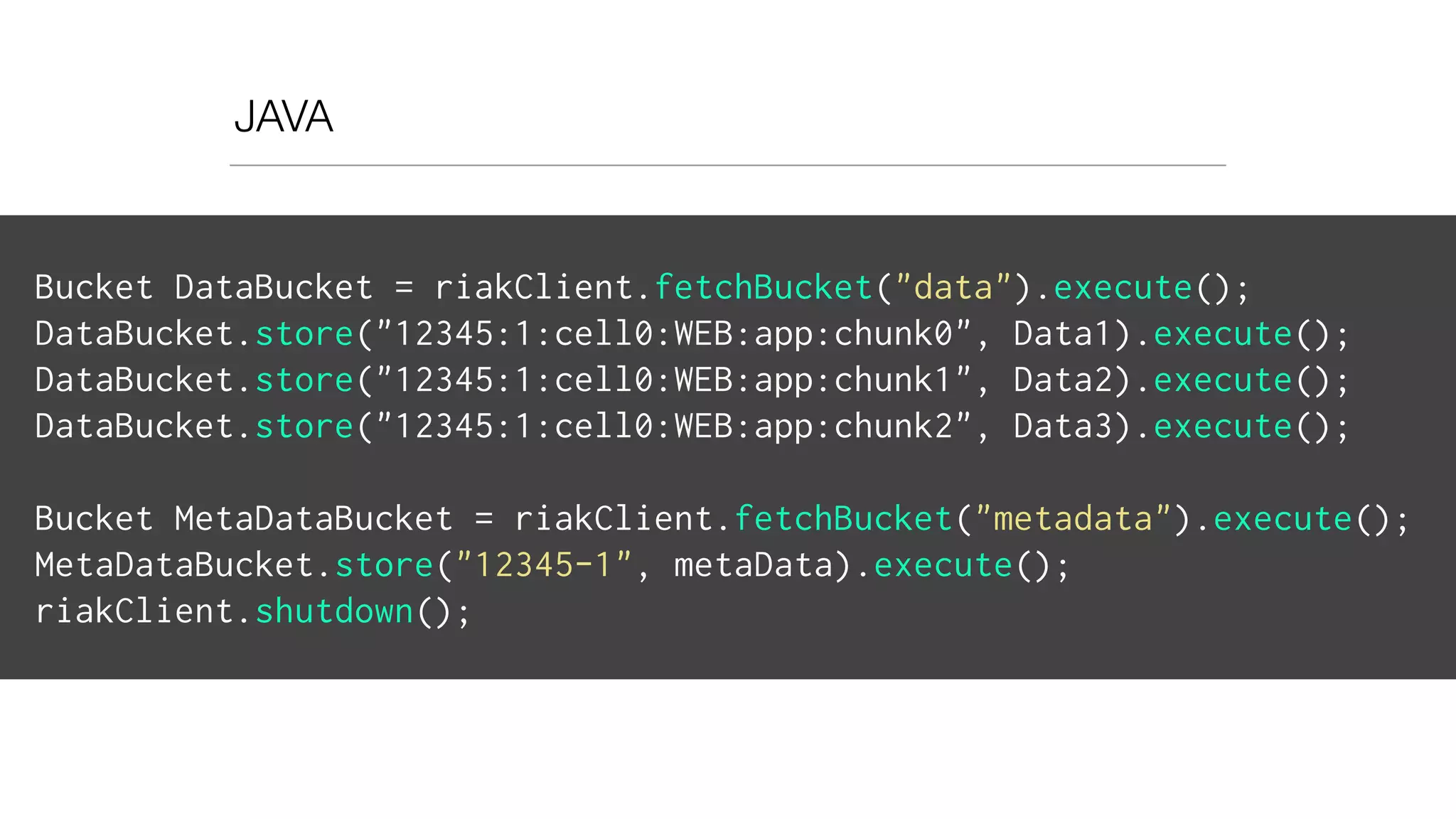










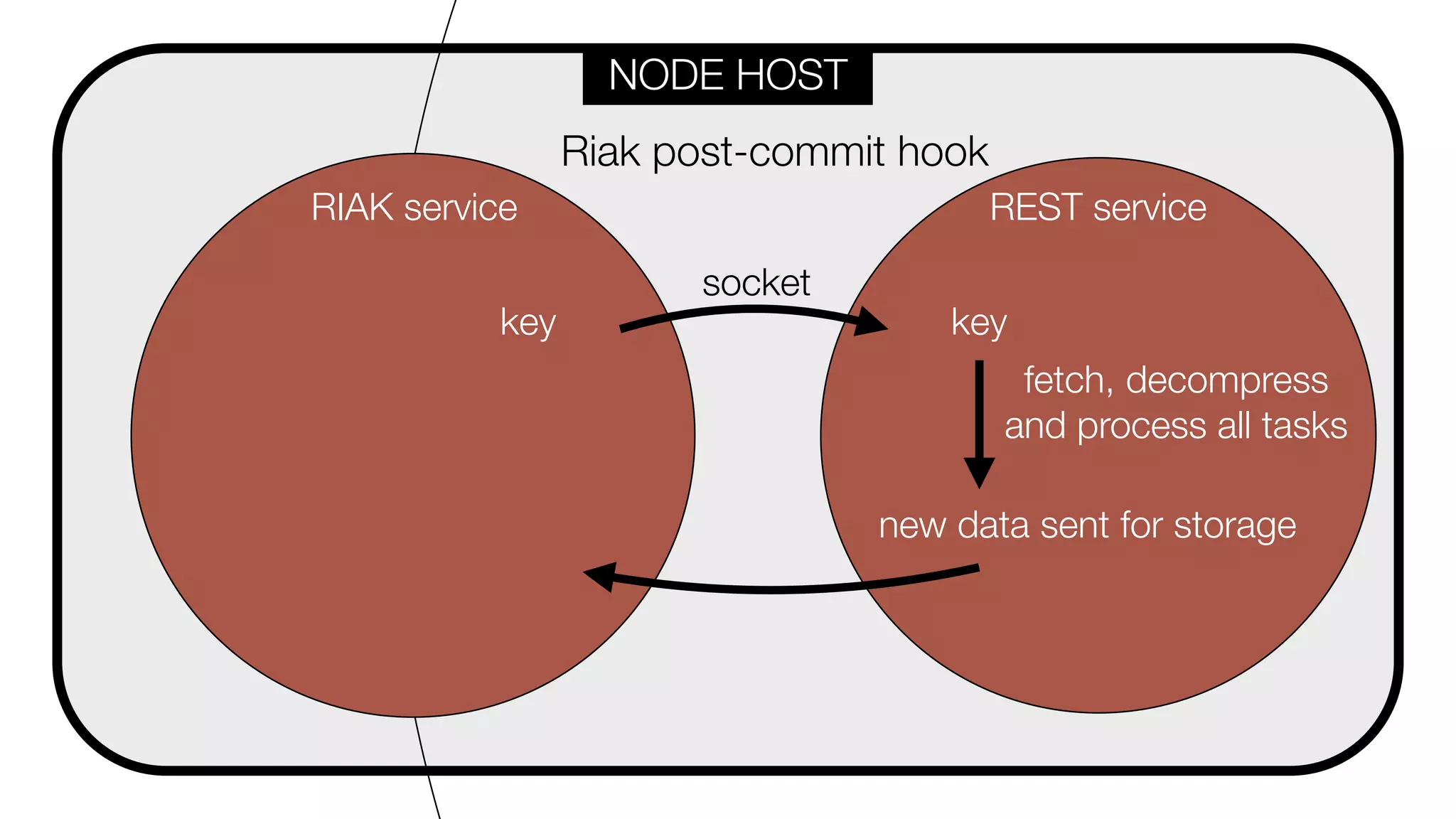
![HOOK CODE
metadata_stored_hook(RiakObject) ->
Key = riak_object:key(RiakObject),
Bucket = riak_object:bucket(RiakObject),
[ Epoch, DC ] = binary:split(Key, <<"-">>),
Data = riak_object:get_value(RiakObject),
DataKeys = binary:split(Data, <<"|">>, [ global ]),
send_to_REST(Epoch, Hostname, DataKeys),
ok.](https://image.slidesharecdn.com/slideswide-150329114034-conversion-gate01/75/Using-Riak-for-Events-storage-and-analysis-at-Booking-com-84-2048.jpg)
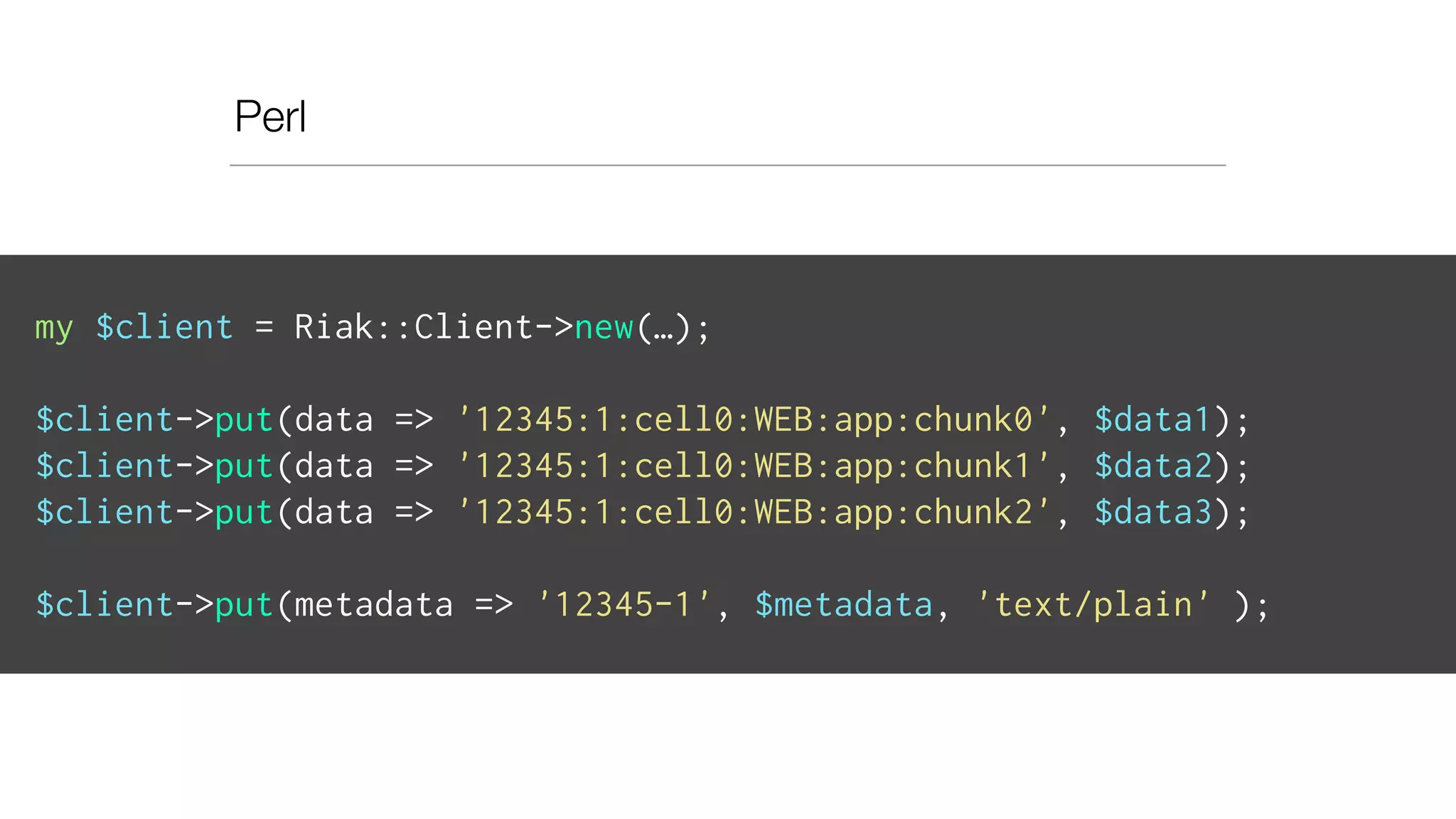
![send_to_REST(Epoch, Hostname, DataKeys) ->
Method = post,
URL = "http://" ++ binary_to_list(Hostname)
++ ":5000?epoch=" ++ binary_to_list(Epoch),
HTTPOptions = [ { timeout, 4000 } ],
Options = [ { body_format, string },
{ sync, false },
{ receiver, fun(ReplyInfo) -> ok end }
],
Body = iolist_to_binary(mochijson2:encode( DataKeys )),
httpc:request(Method, {URL, [], "application/json", Body},
HTTPOptions, Options),
ok.](https://image.slidesharecdn.com/slideswide-150329114034-conversion-gate01/75/Using-Riak-for-Events-storage-and-analysis-at-Booking-com-85-2048.jpg)





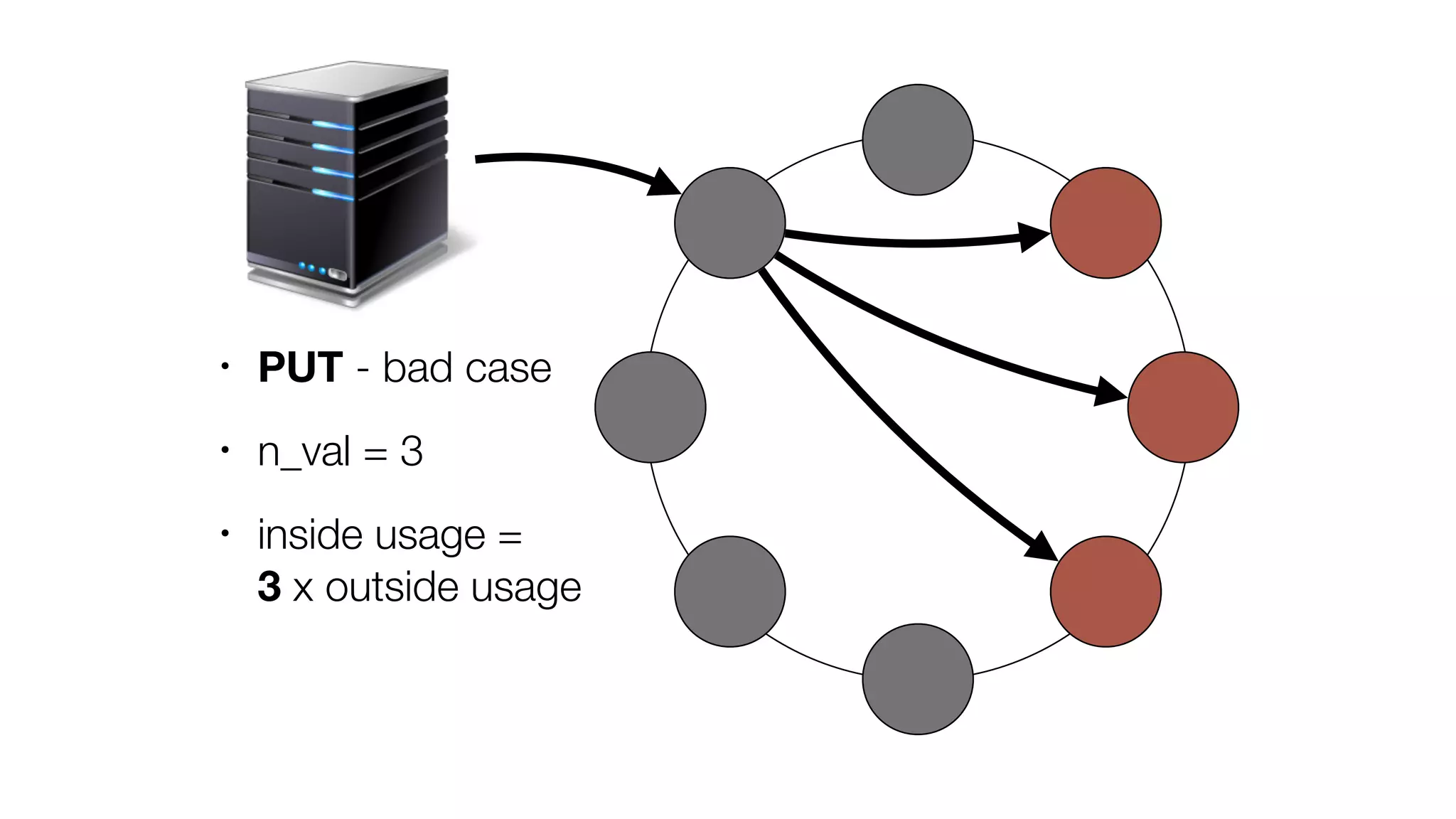
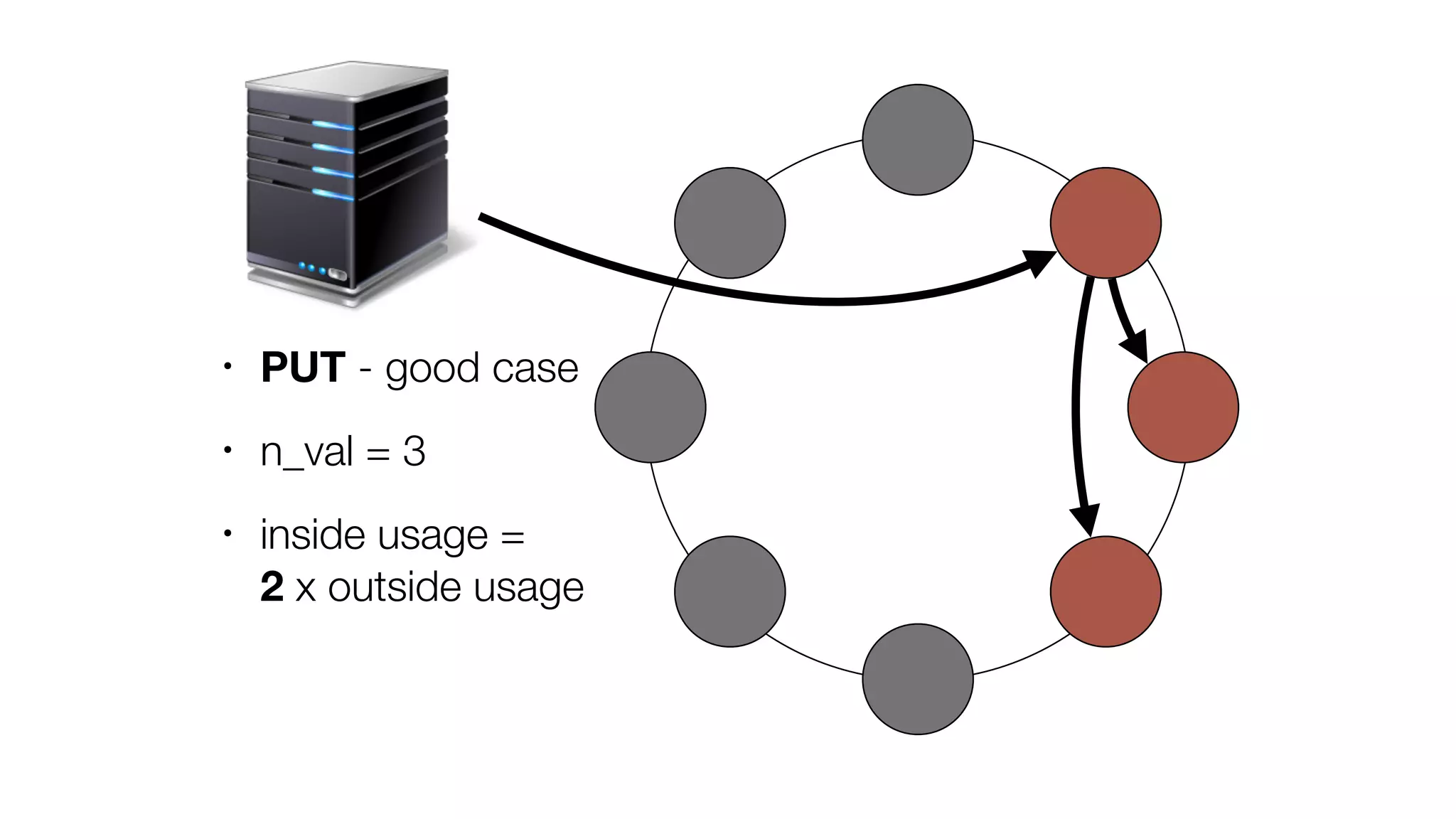
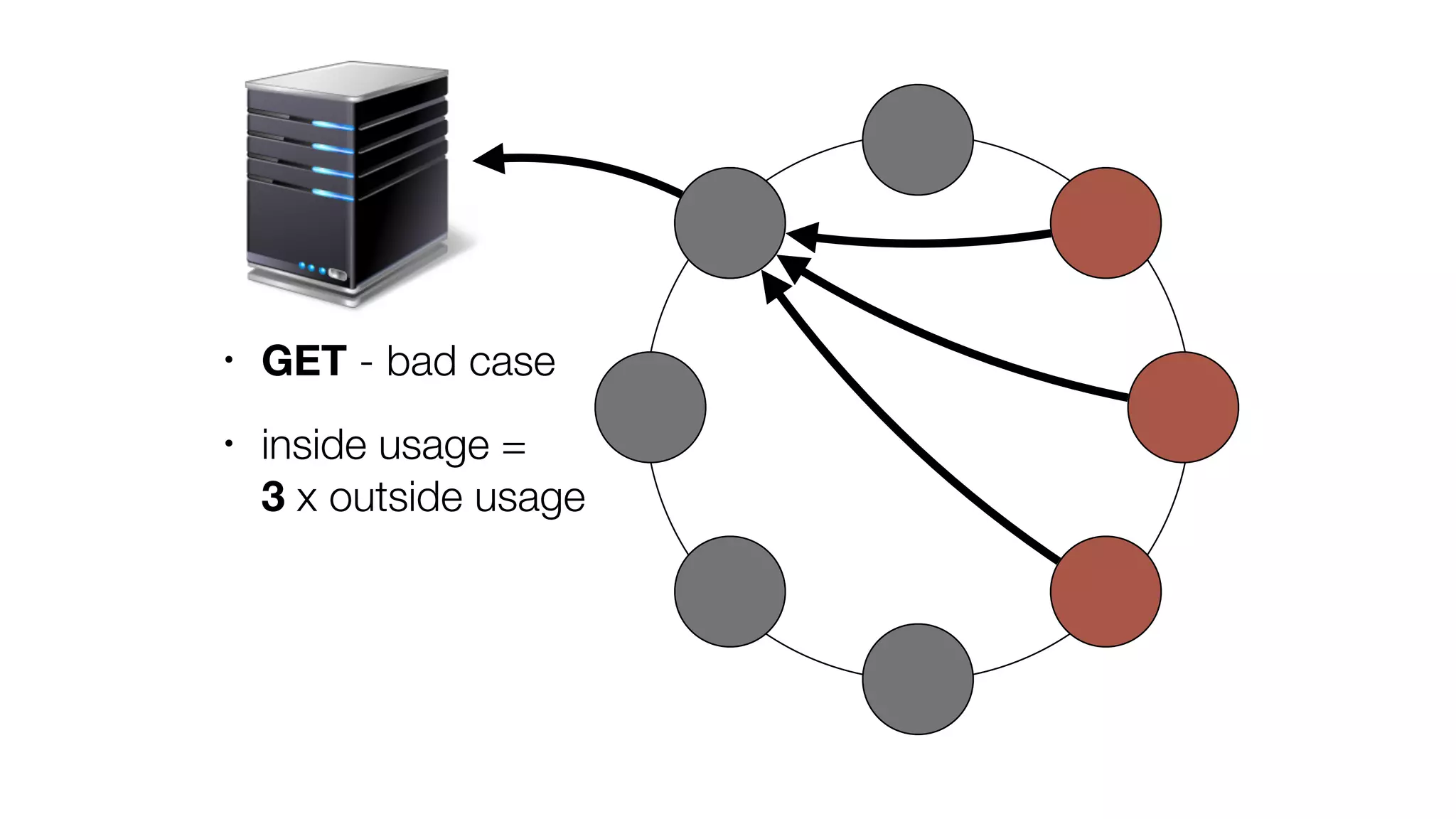
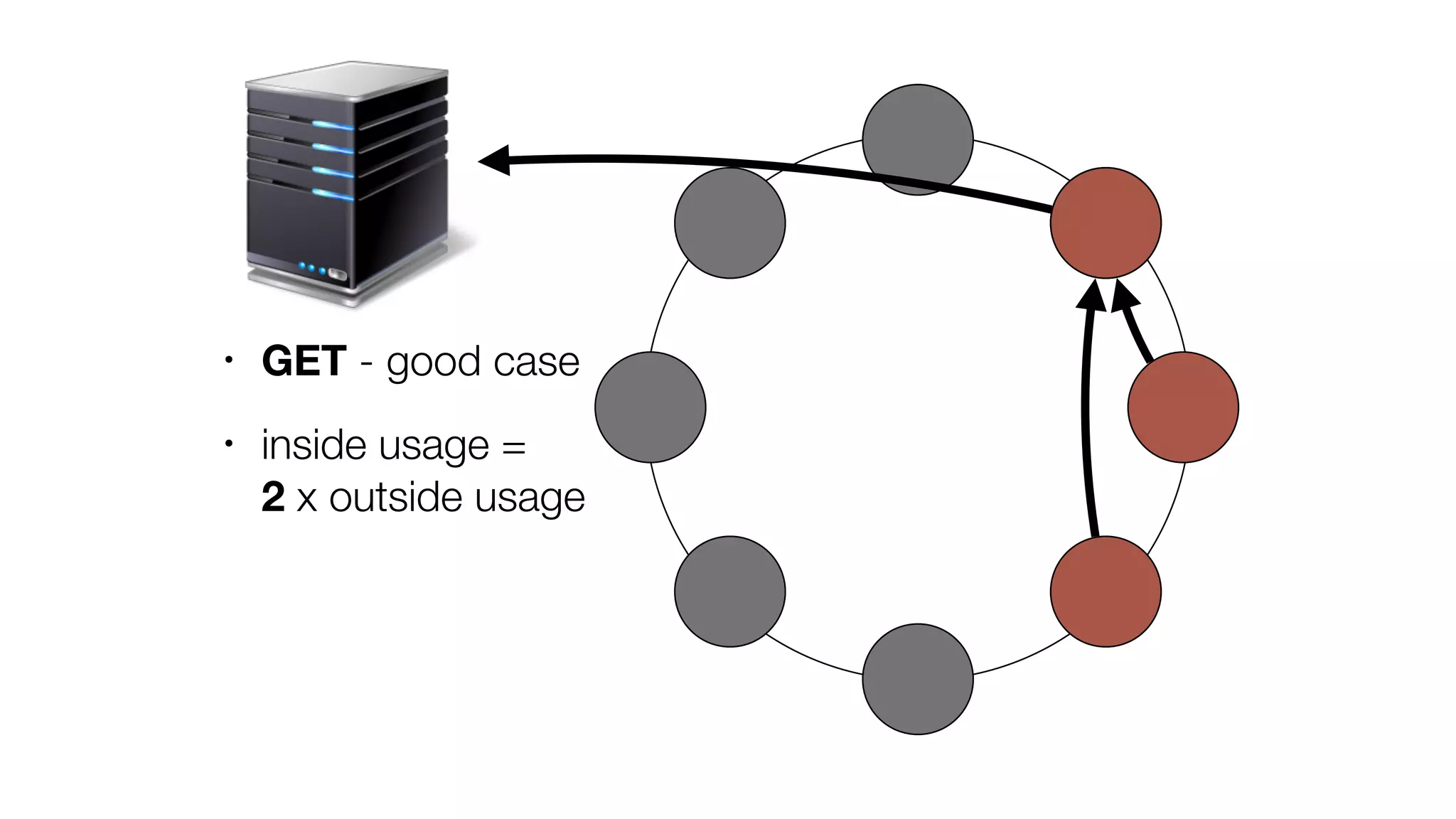













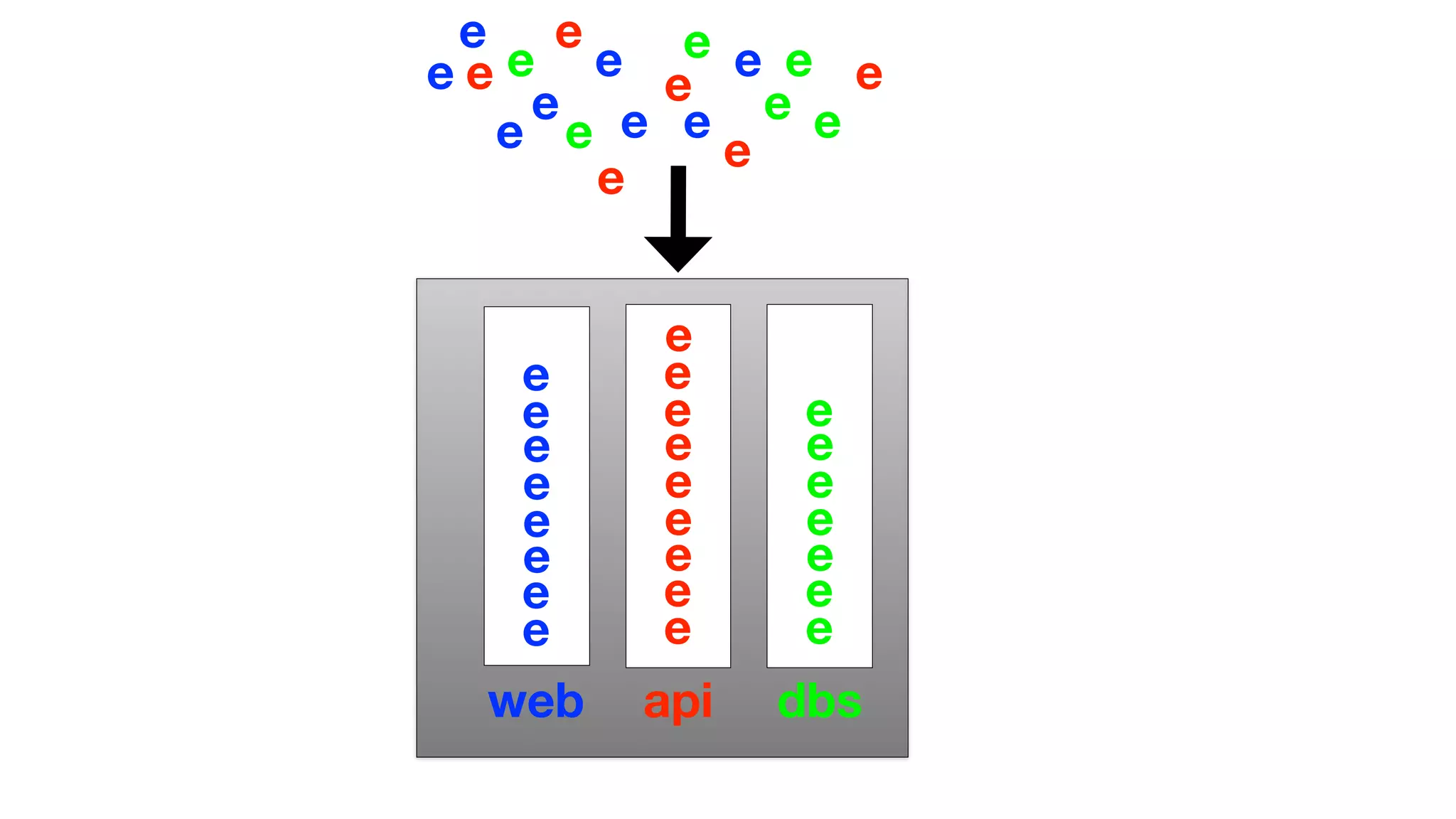
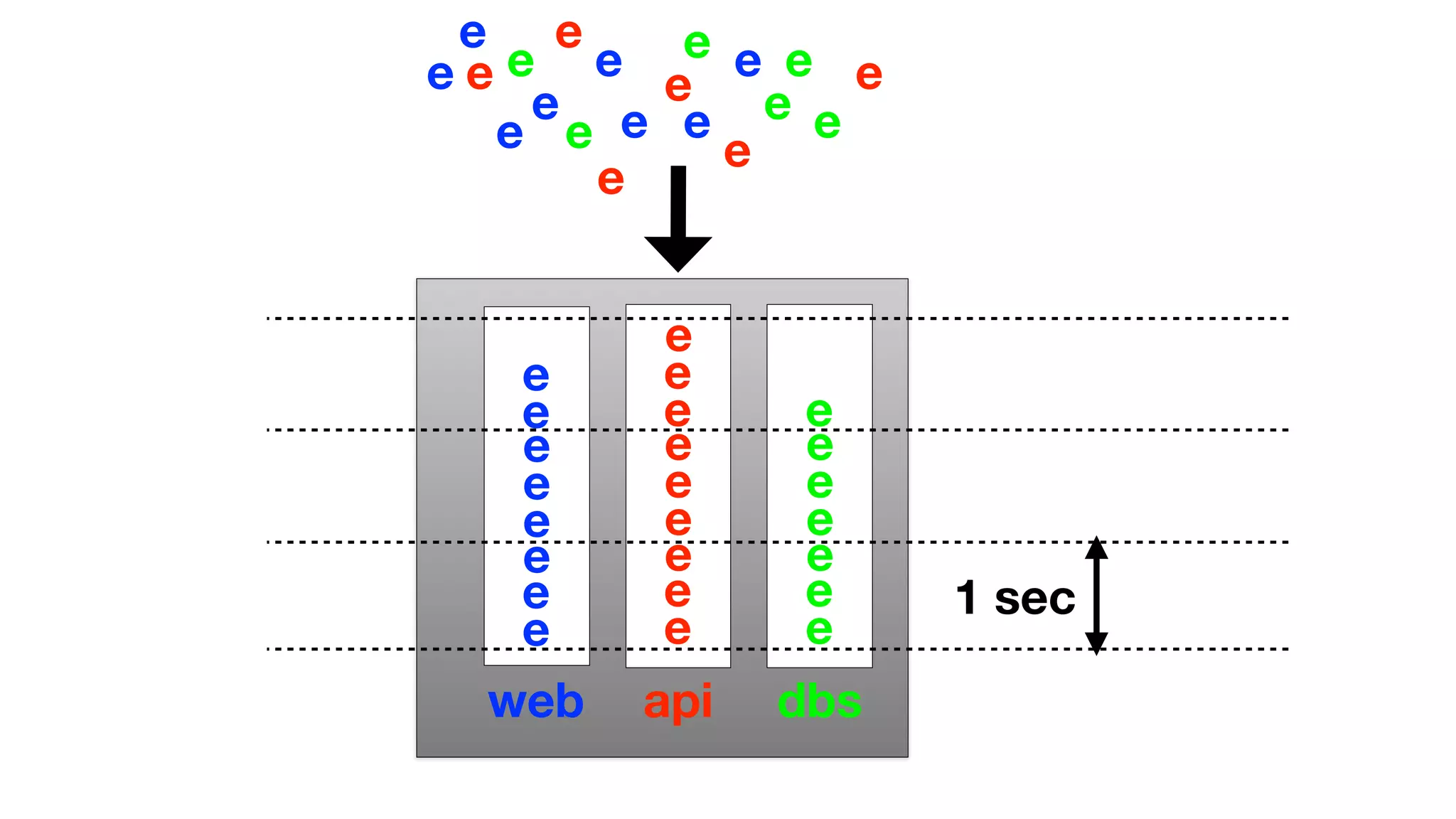
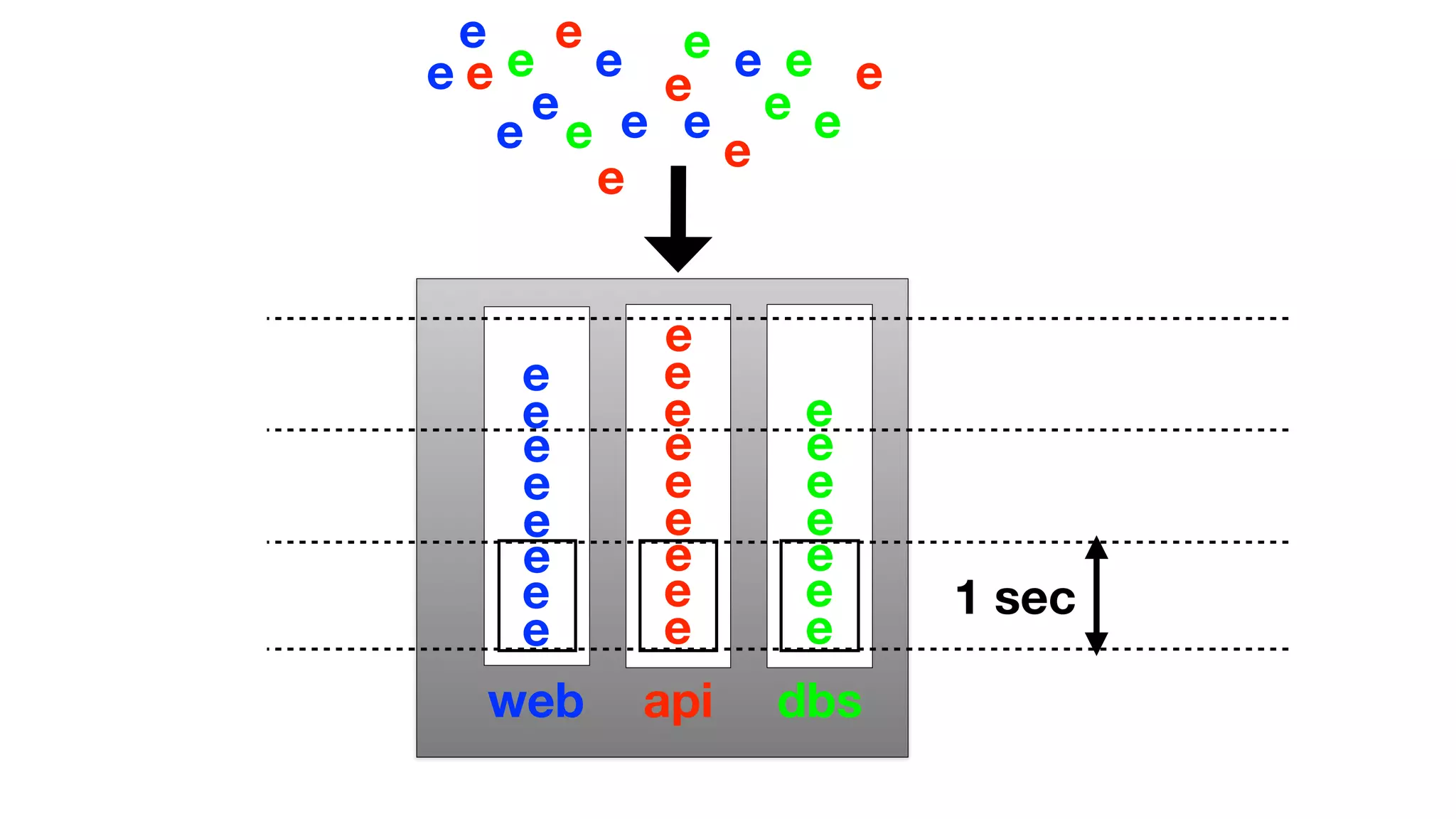
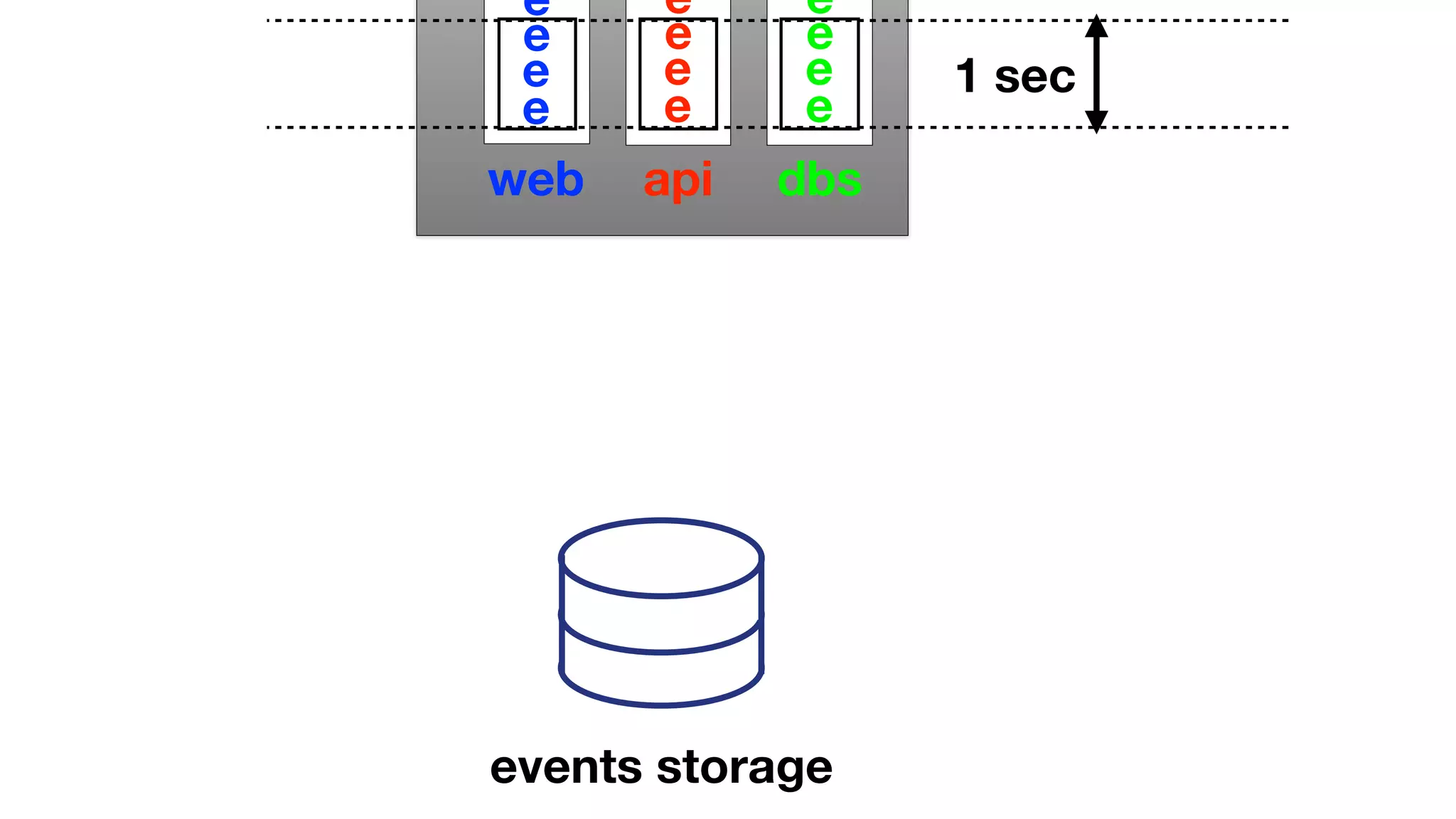
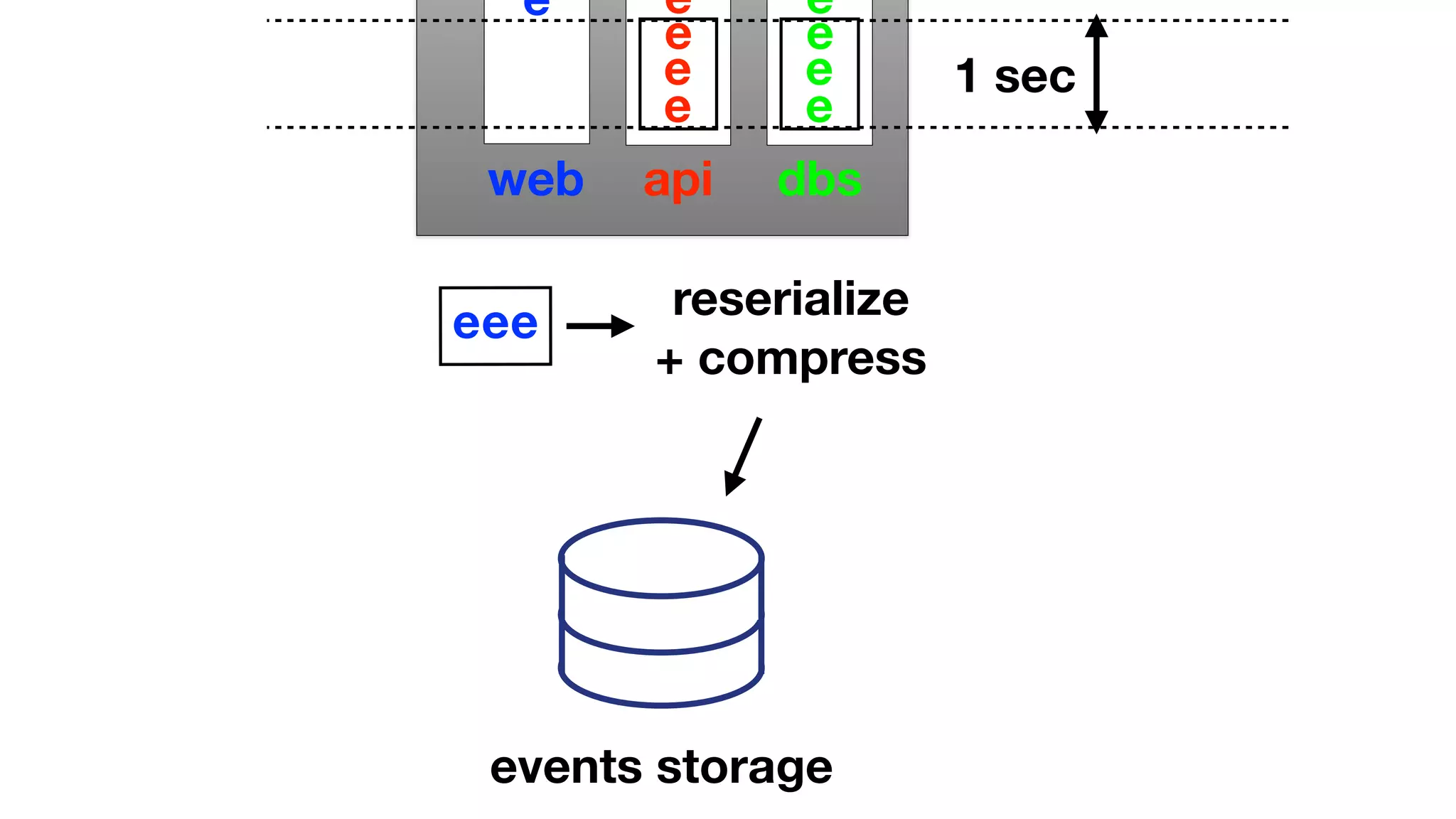
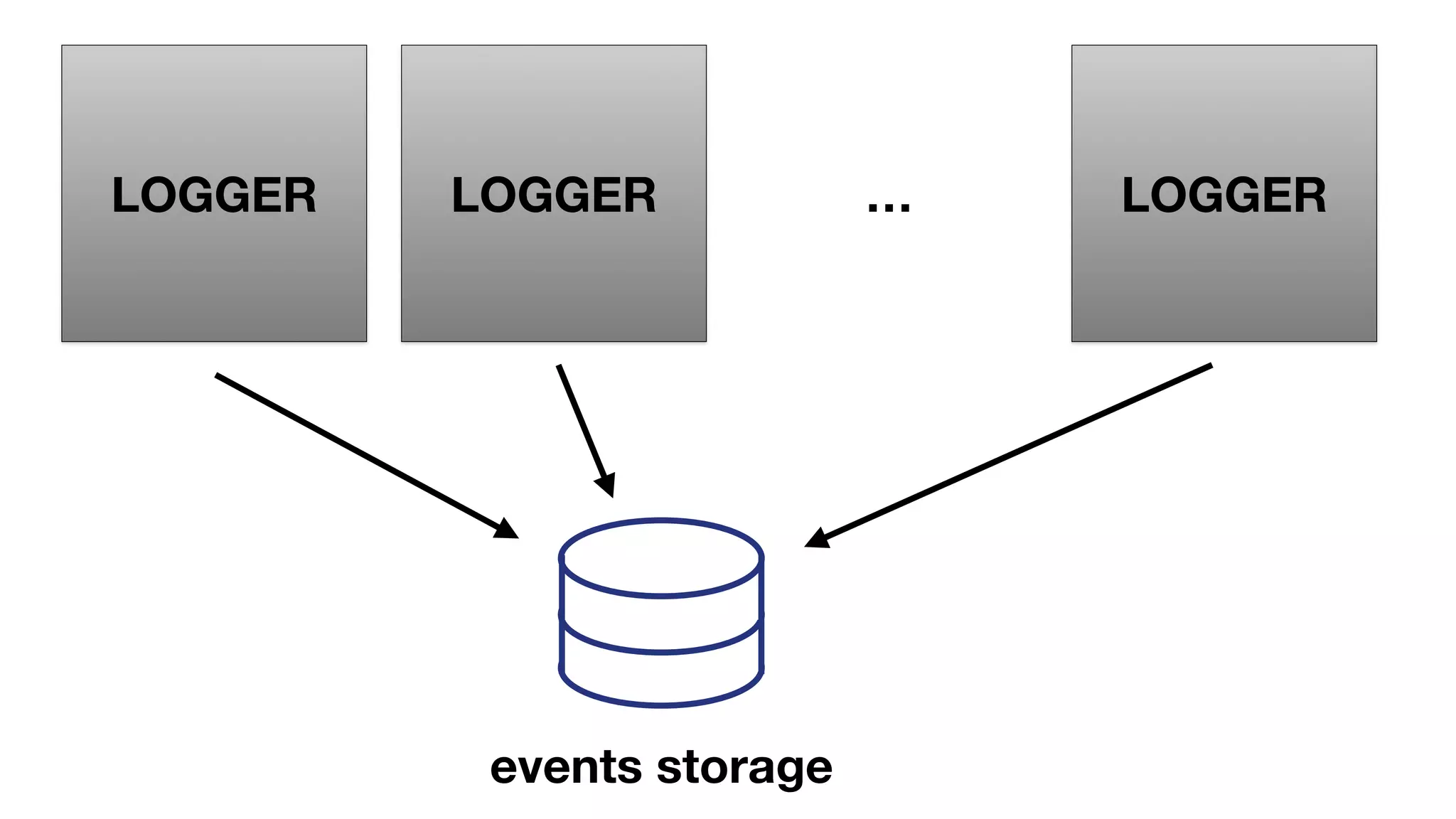
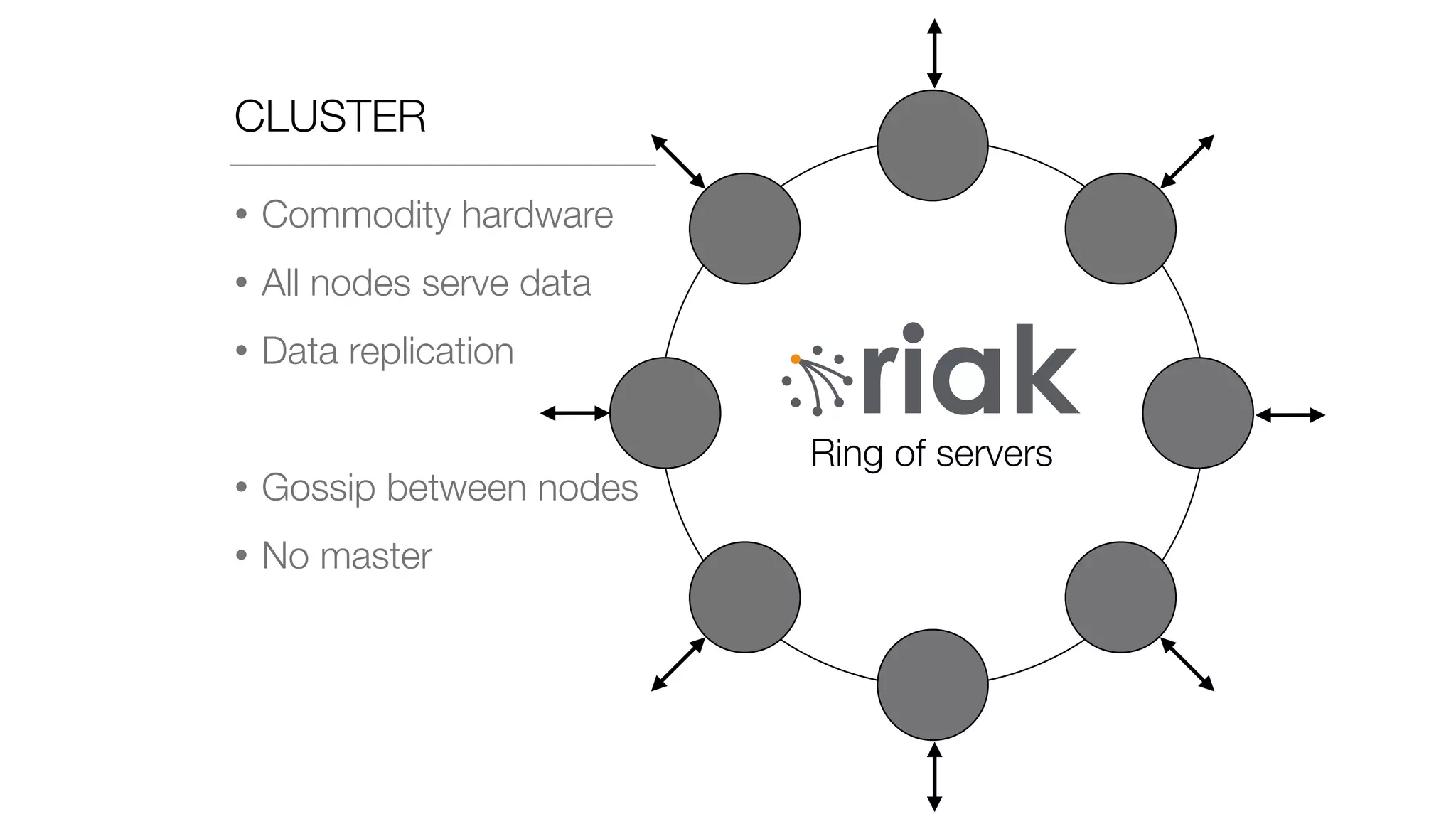
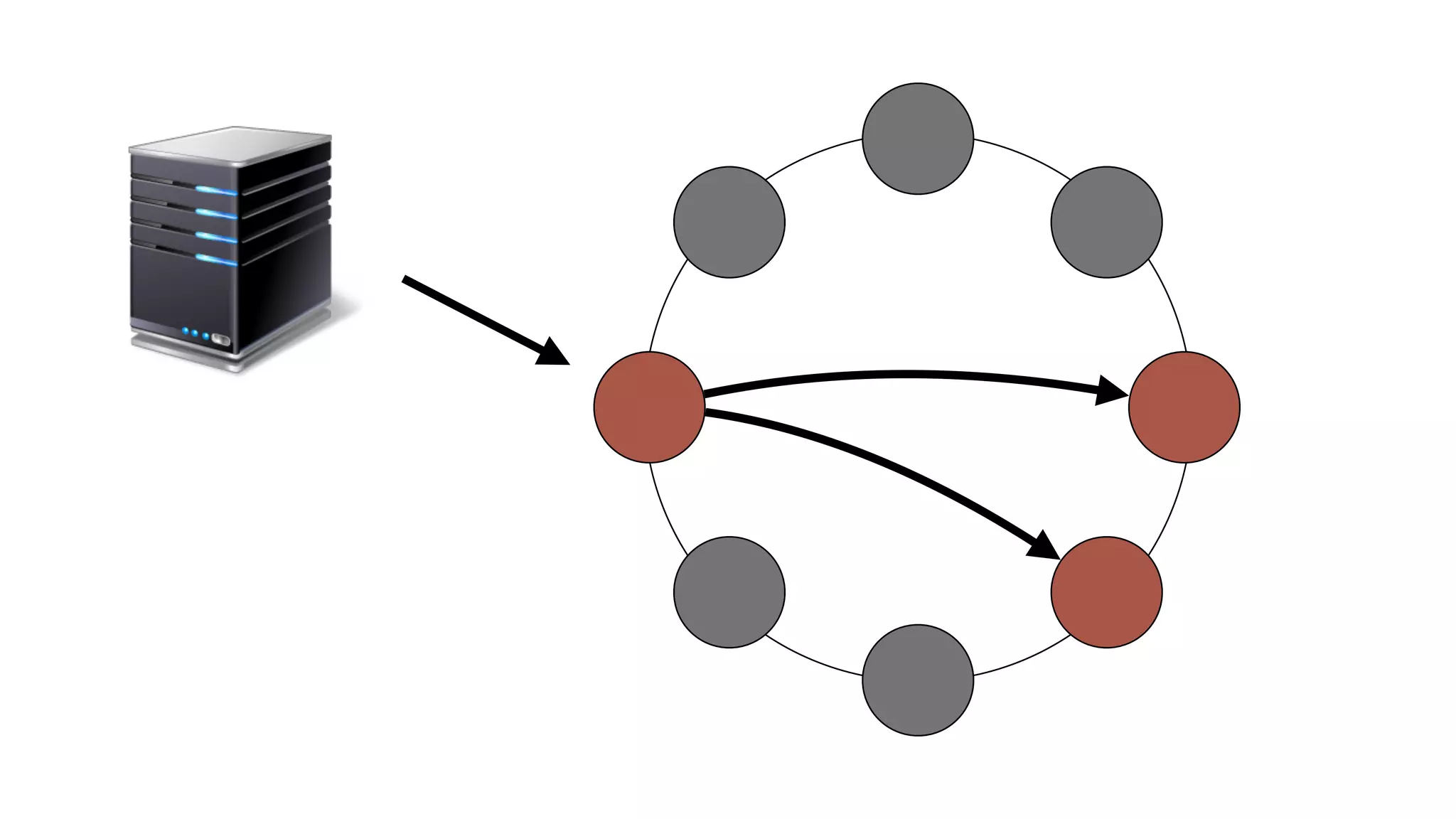
The document discusses the implementation of event storage and real-time analysis at Booking.com using Riak, detailing the structure and flow of events generated from different subsystems. It highlights the need for efficient data serialization and aggregation methods, as well as the architecture chosen for scalability, security, and performance. The presentation concludes with insights on real-time processing, network bandwidth challenges, and the efficacy of using Riak as a robust solution for handling large volumes of event data.






































































