



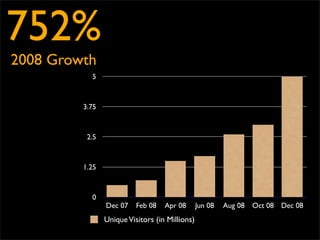
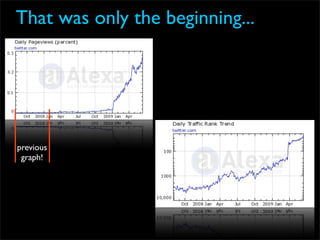
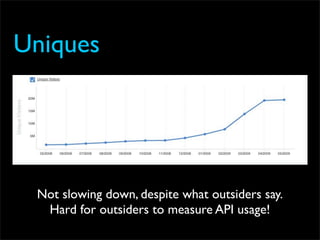


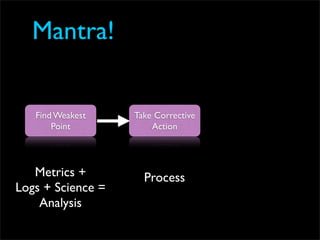
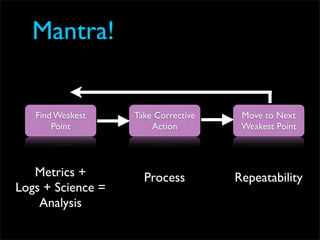





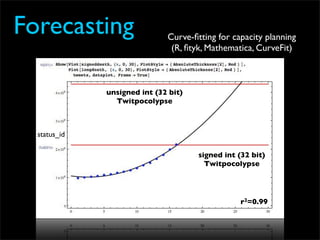






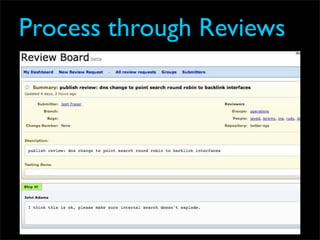

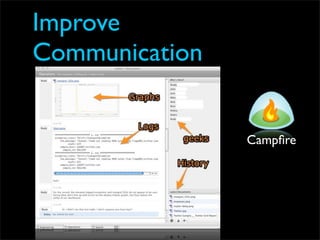

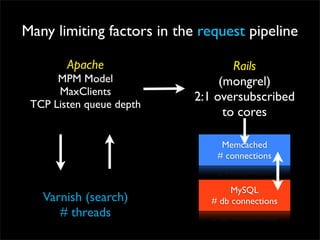
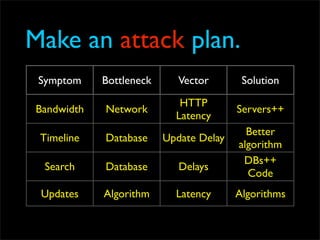




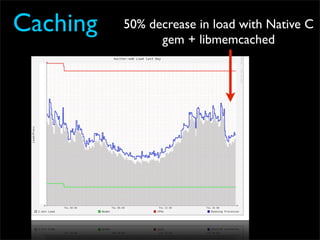

















Fixing Twitter and Finding your own Fail Whale document discusses Twitter operations. The Twitter operations team focuses on software performance, availability, capacity planning, and configuration management using metrics, logs, and science. They use a dedicated managed services team and run their own servers instead of cloud services. The document outlines Twitter's rapid growth and challenges in maintaining performance. It discusses strategies for monitoring, analyzing metrics to find weak points, deploying changes, and improving processes through configuration management and peer reviews.





















































































