
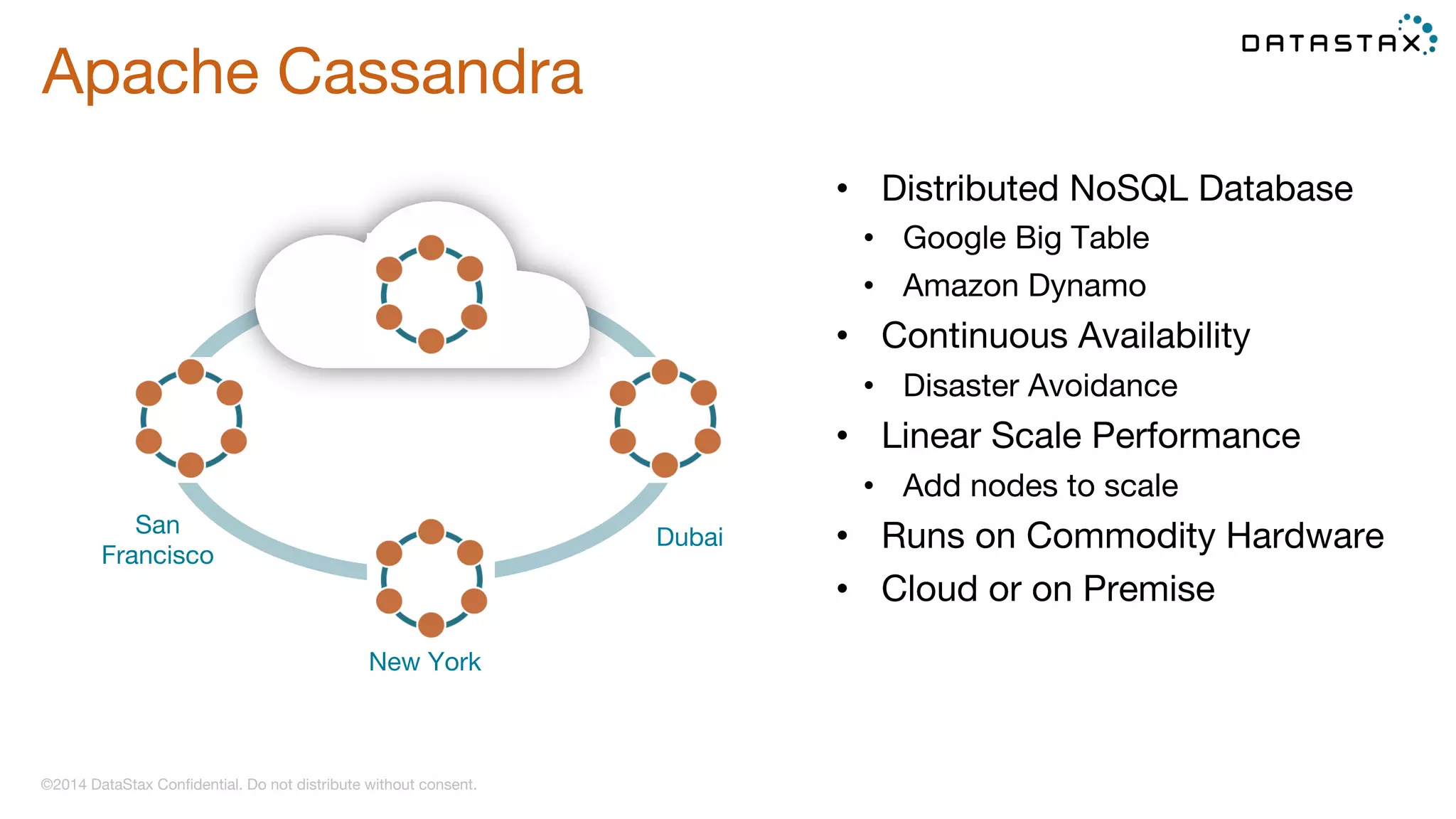
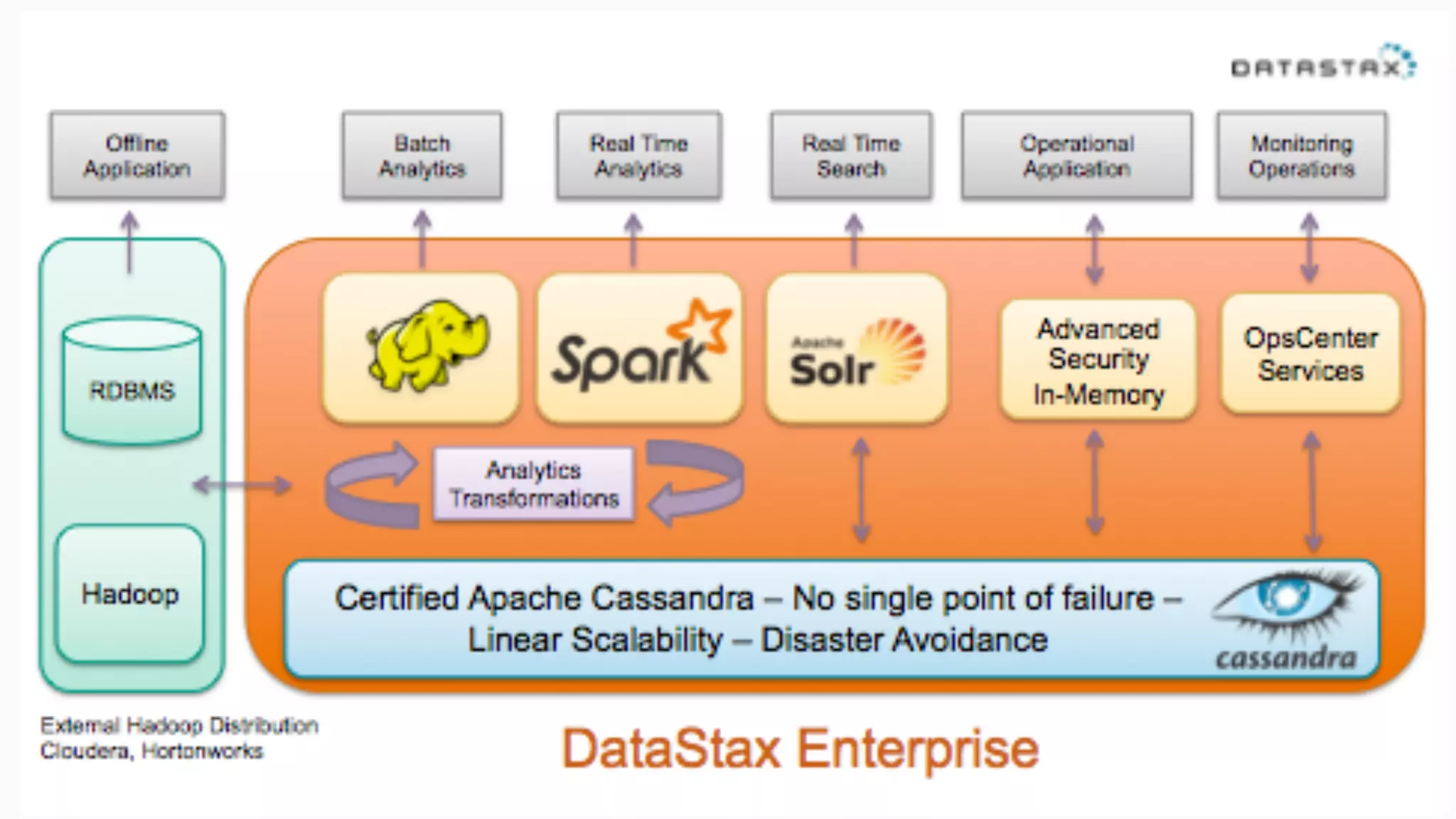


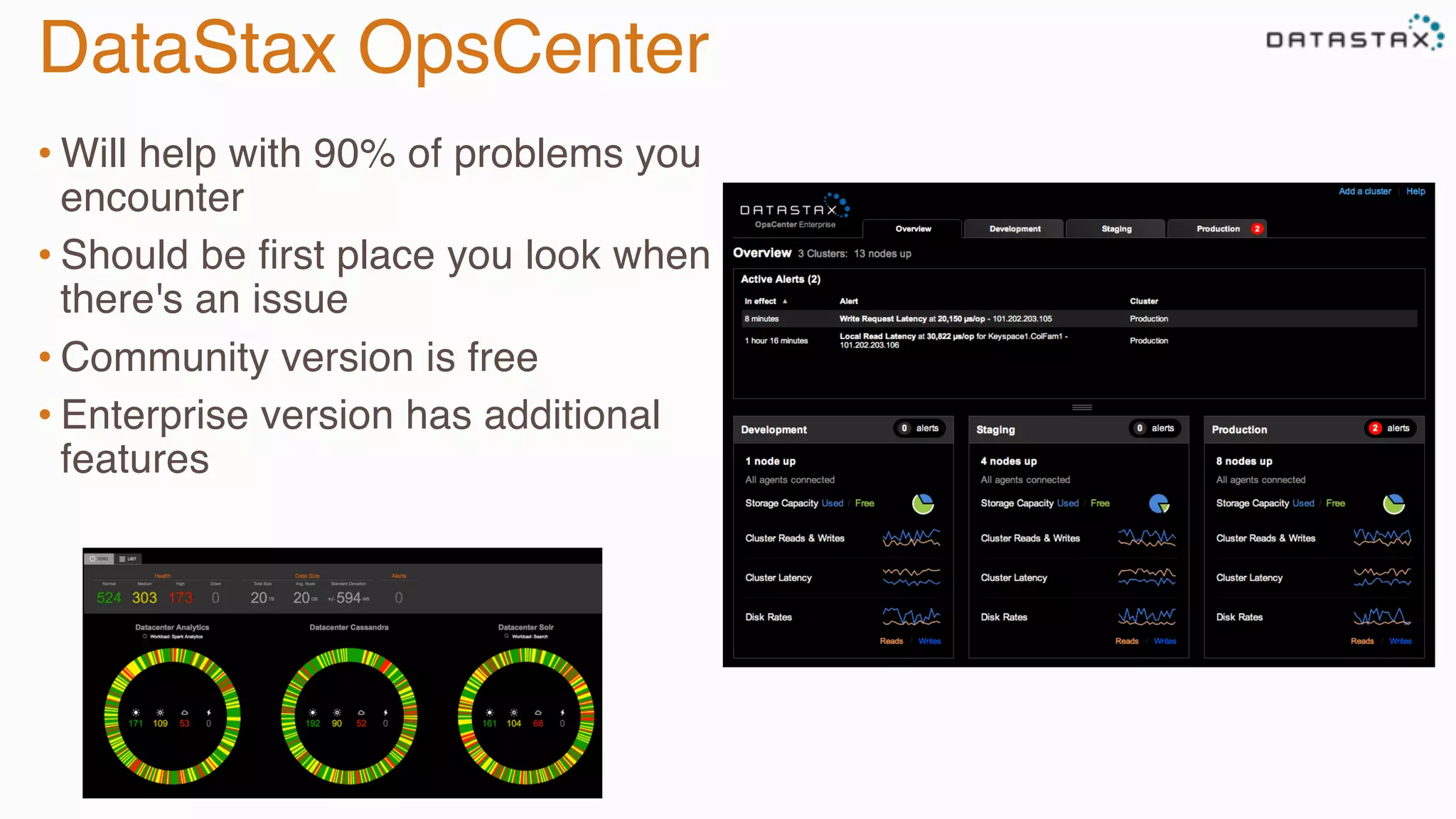

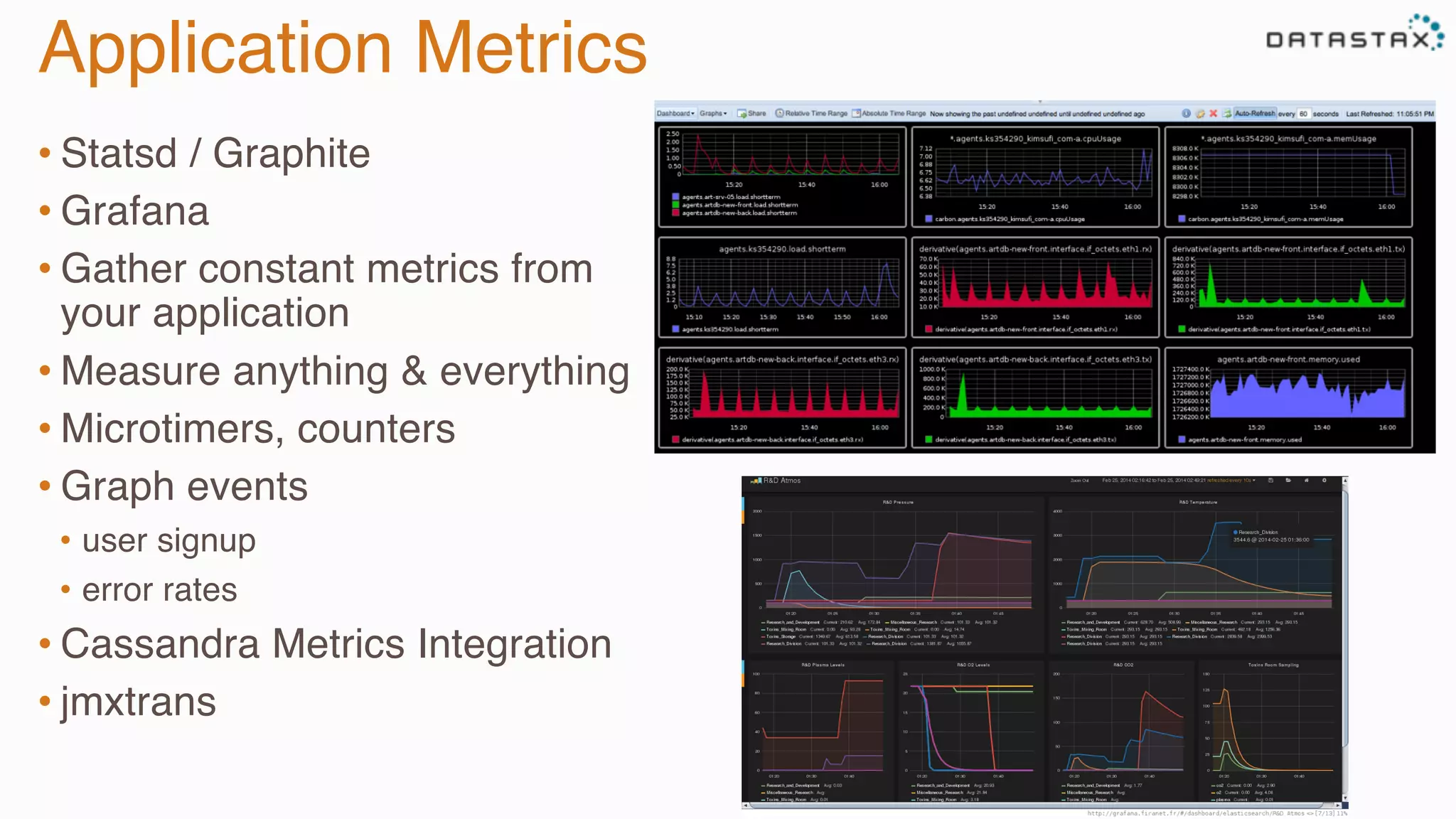
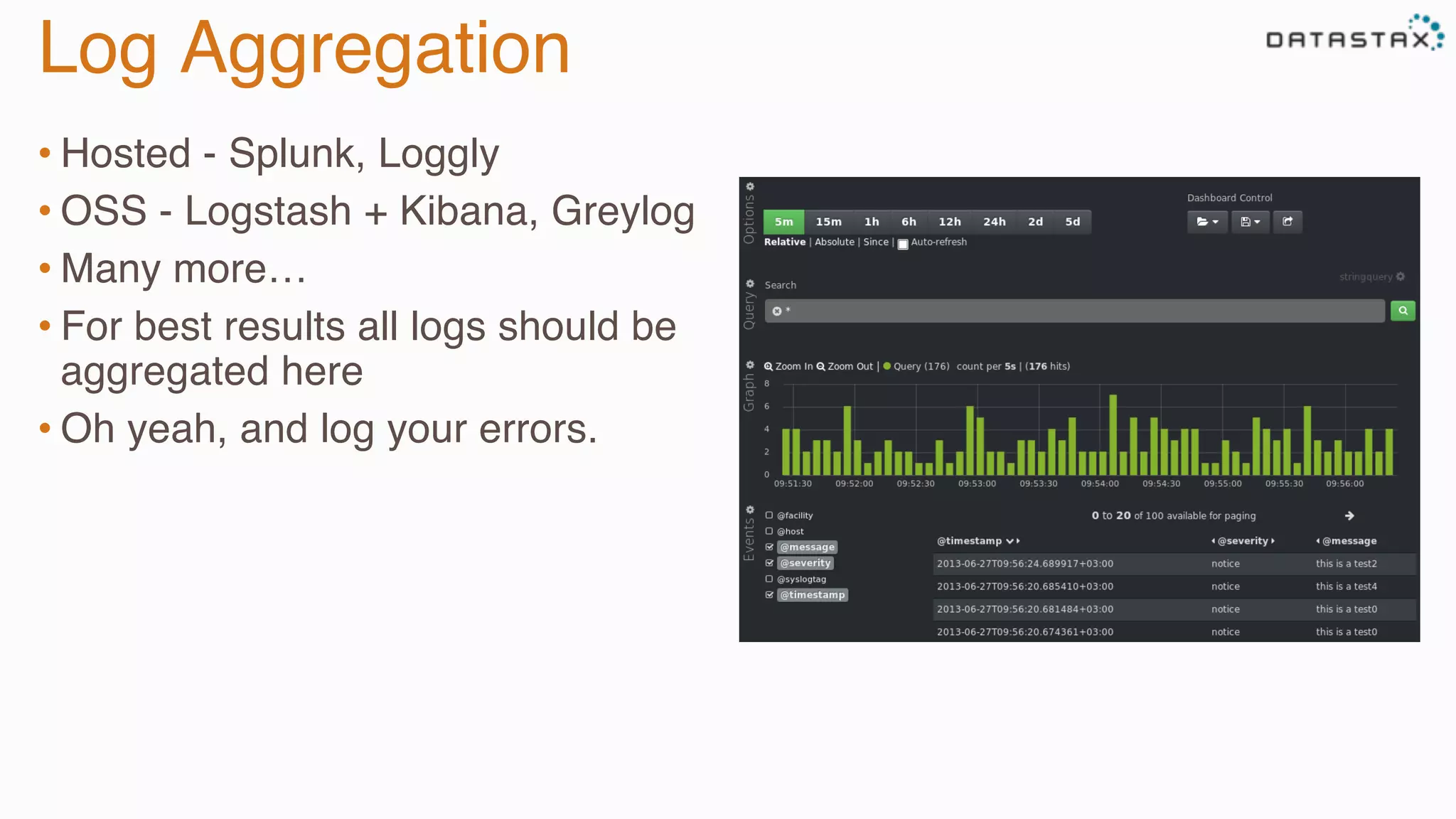

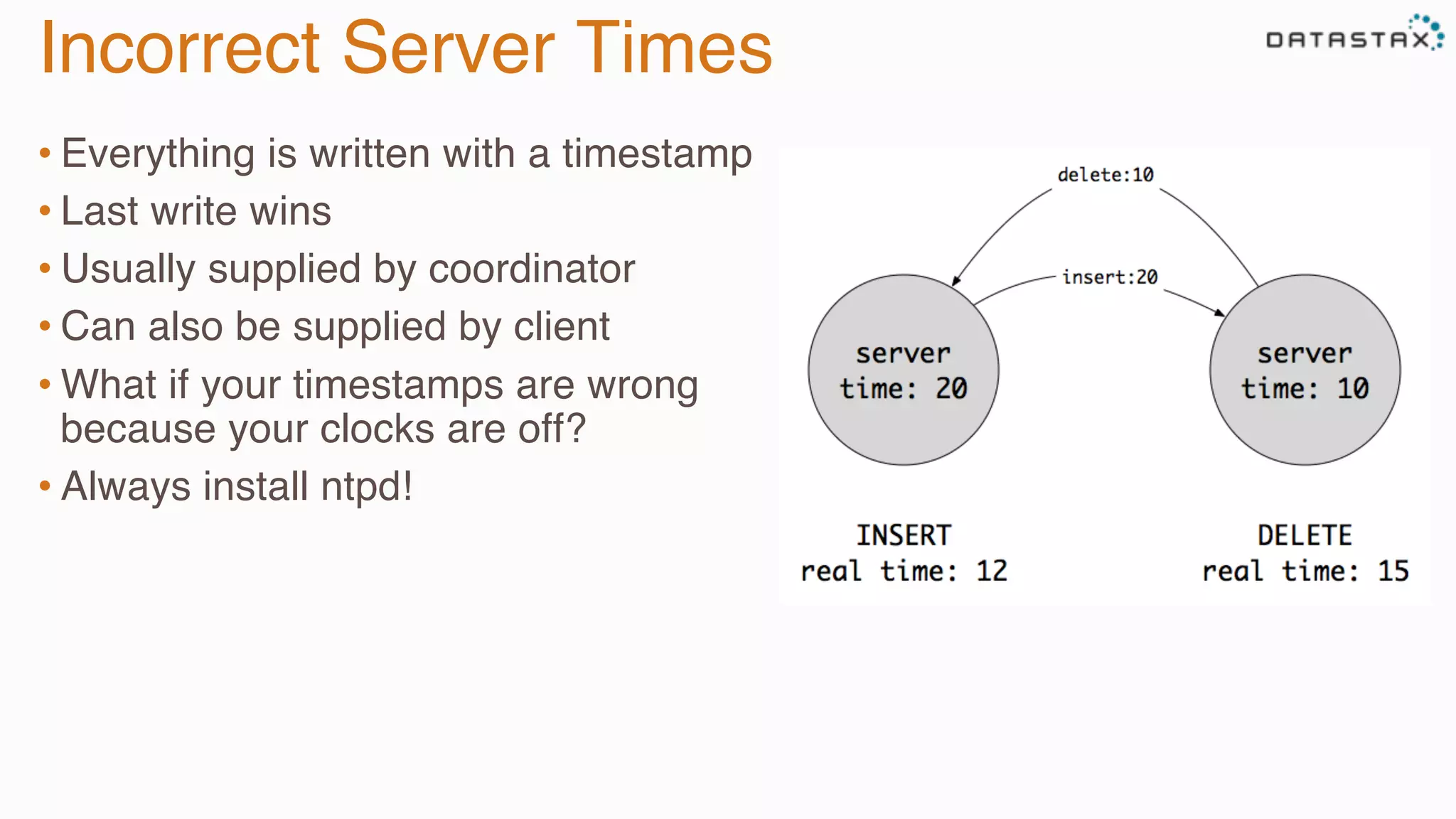

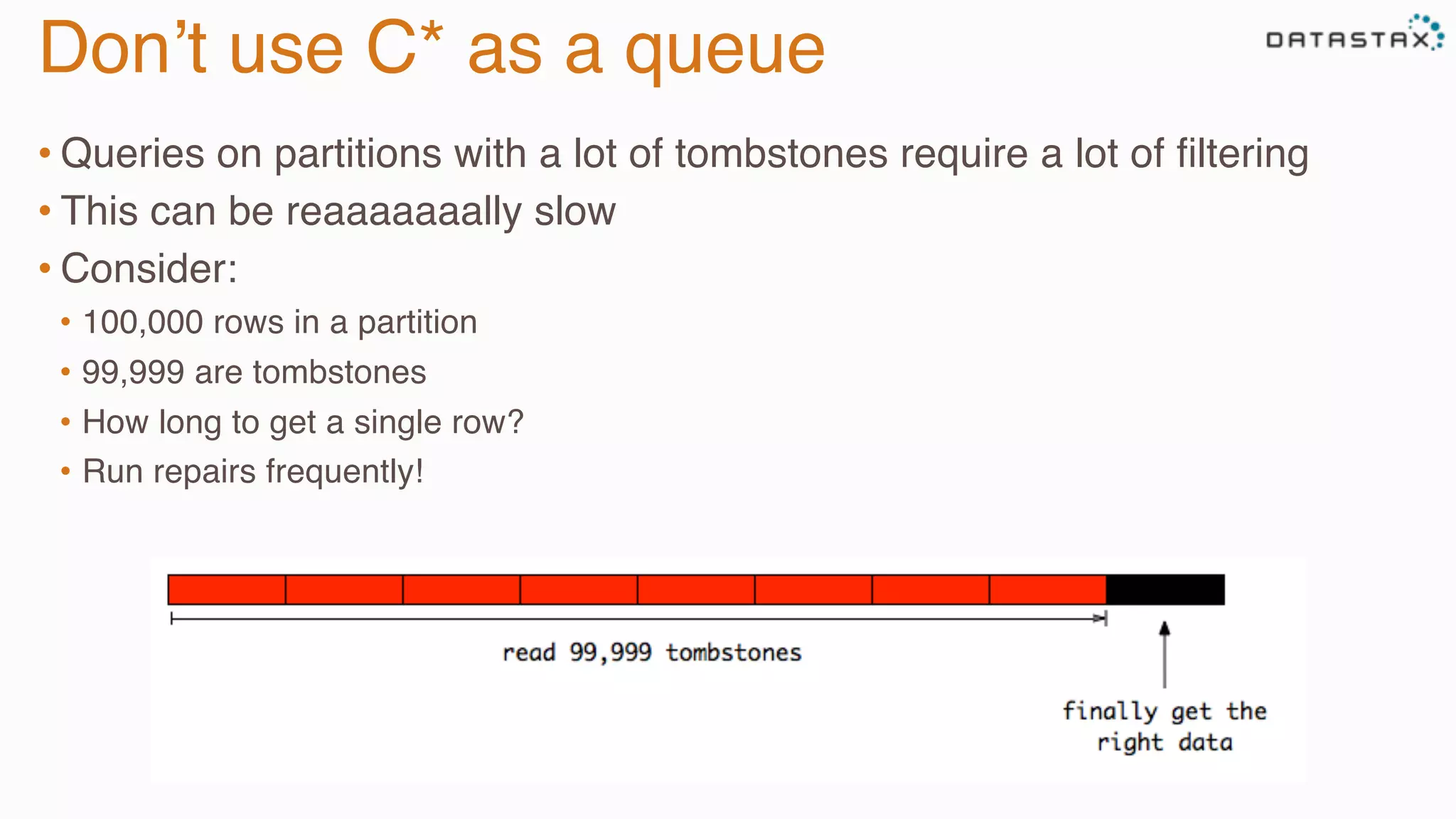






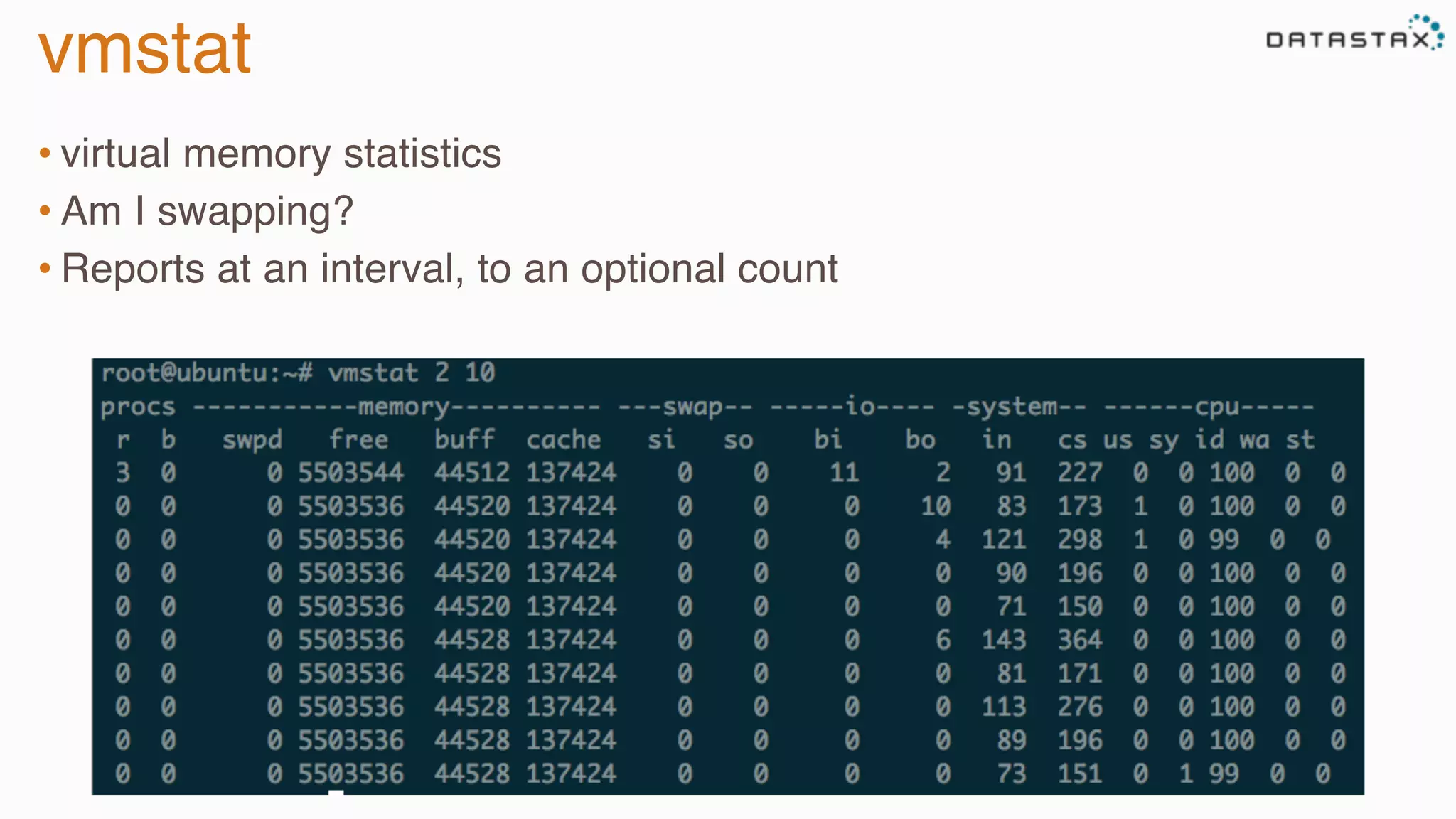
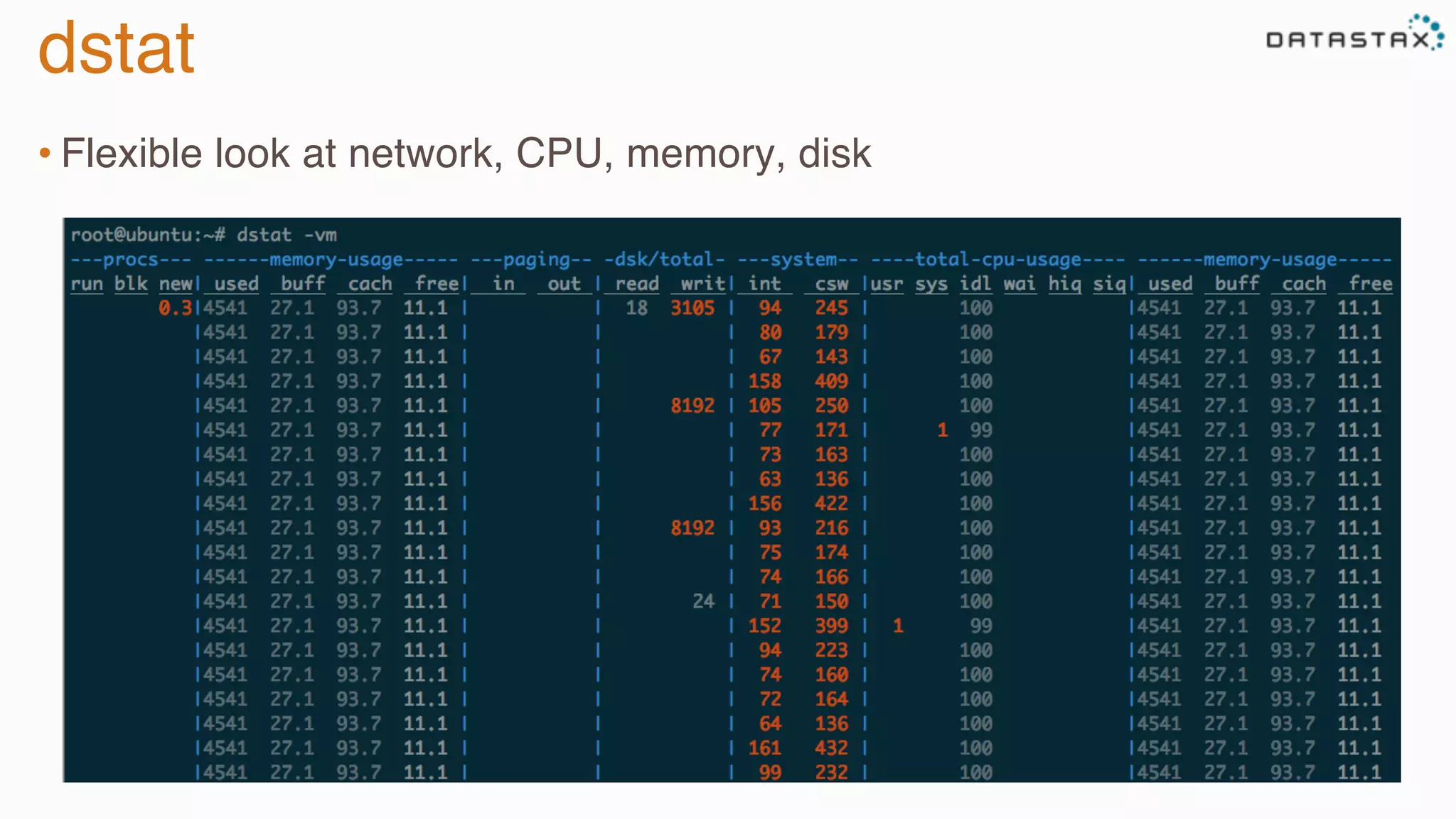
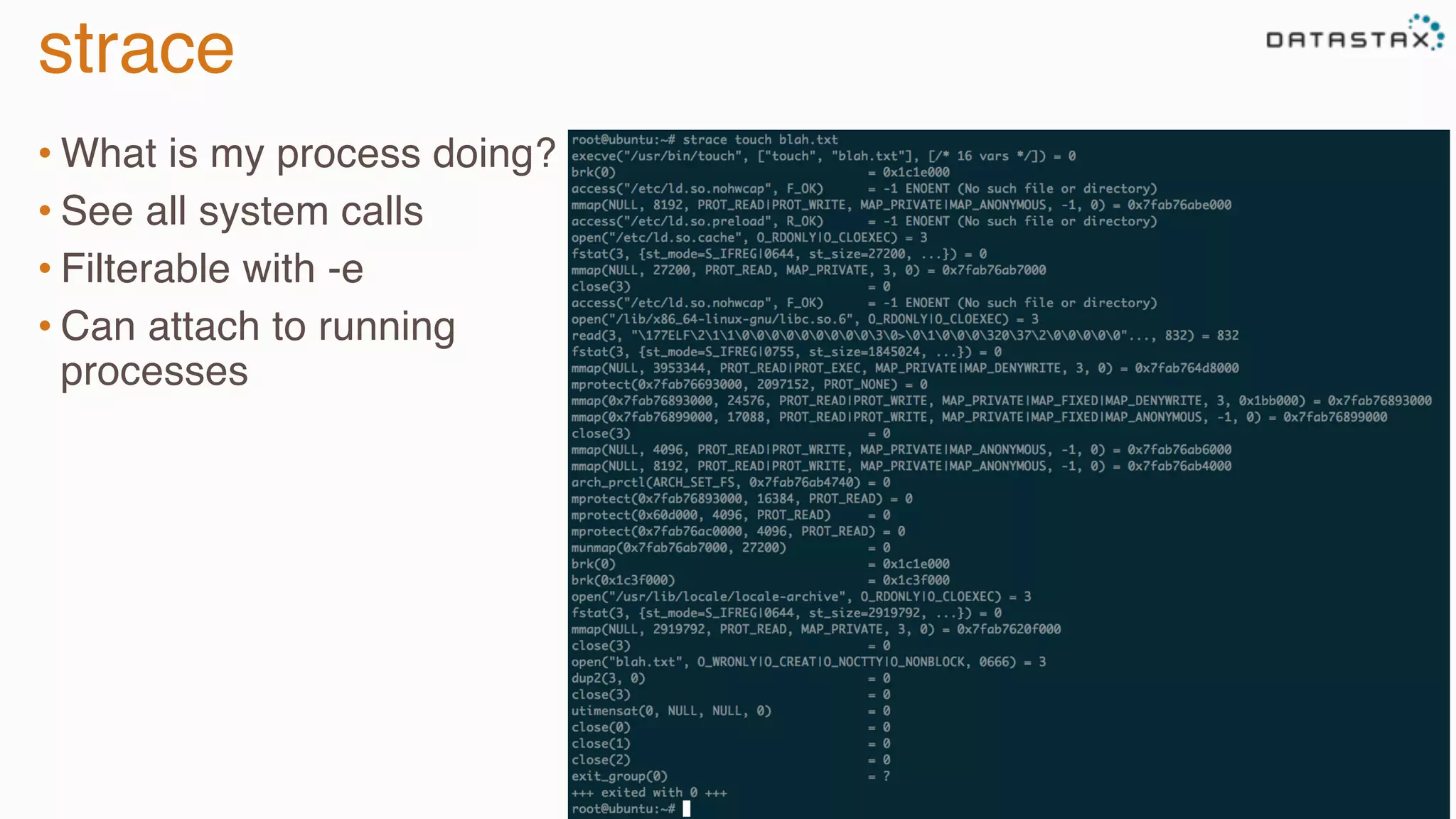
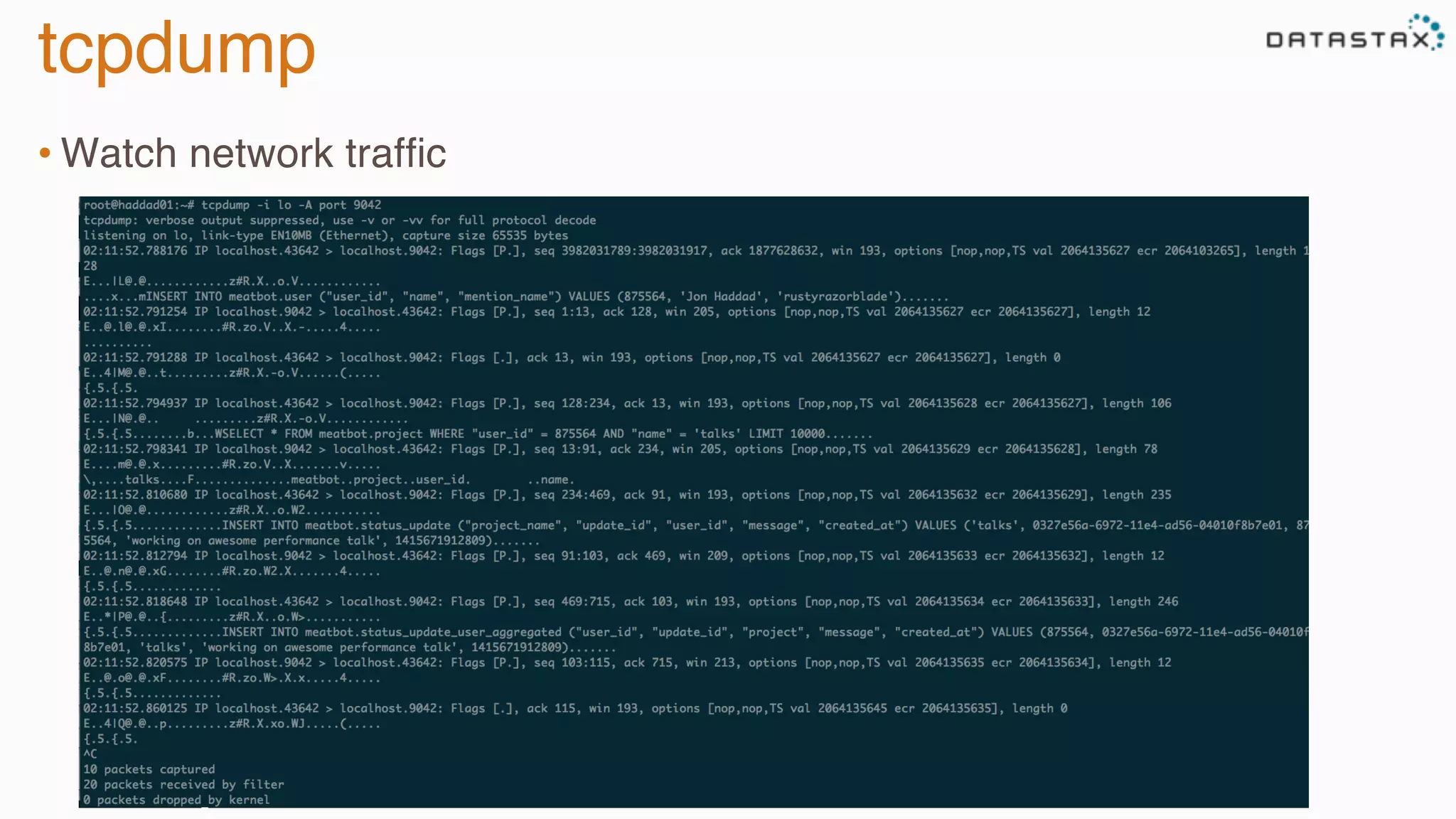
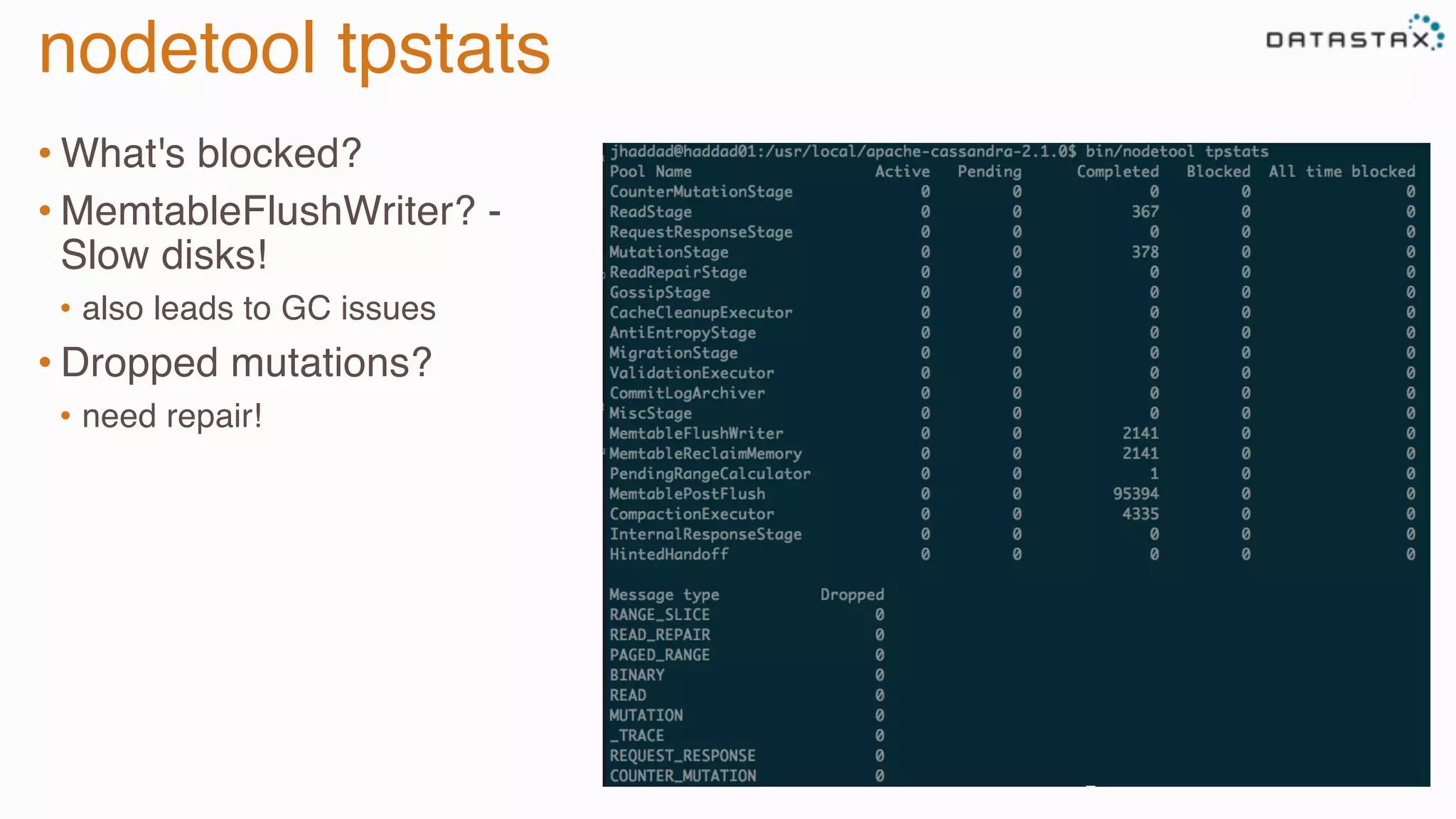

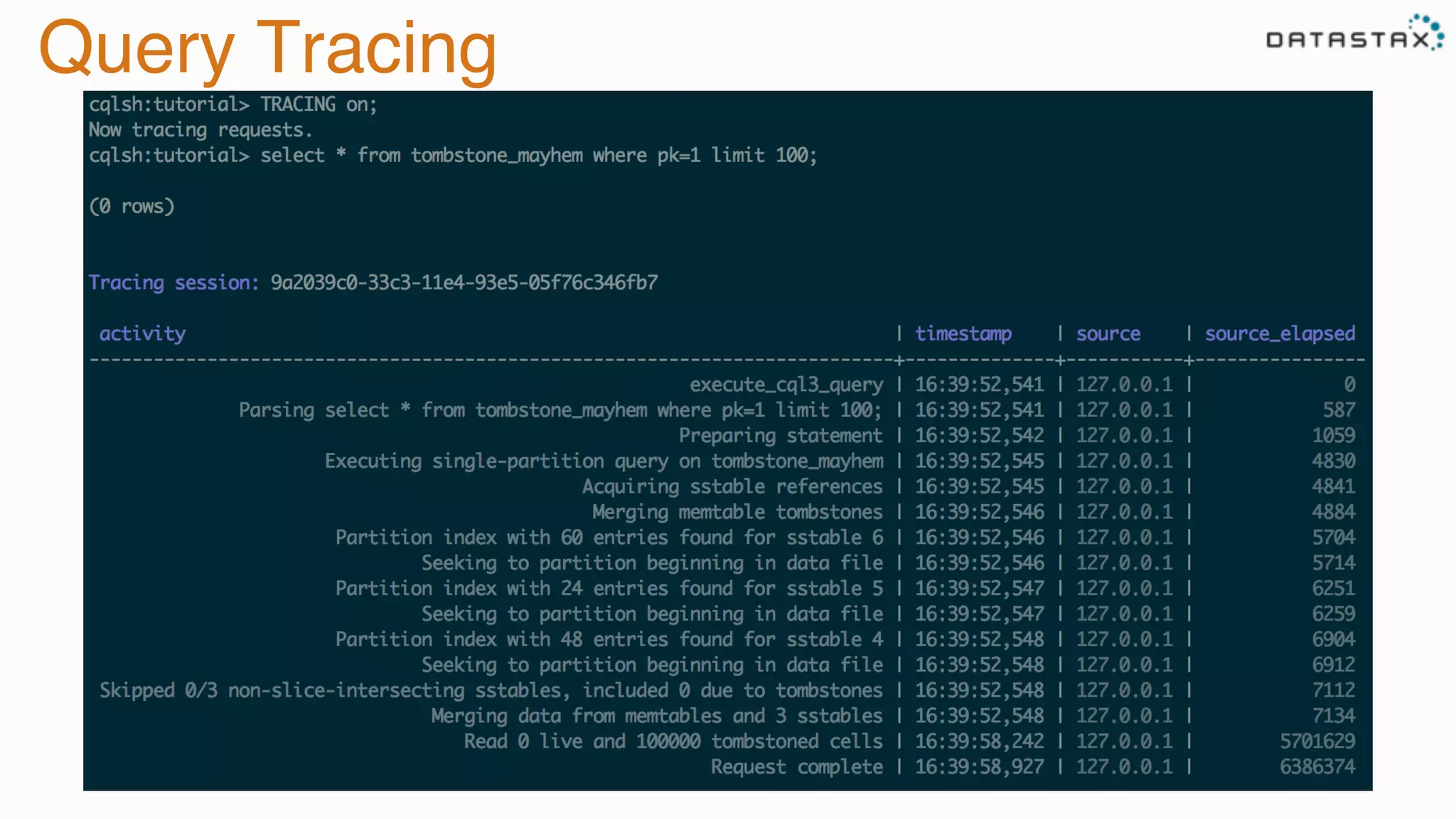

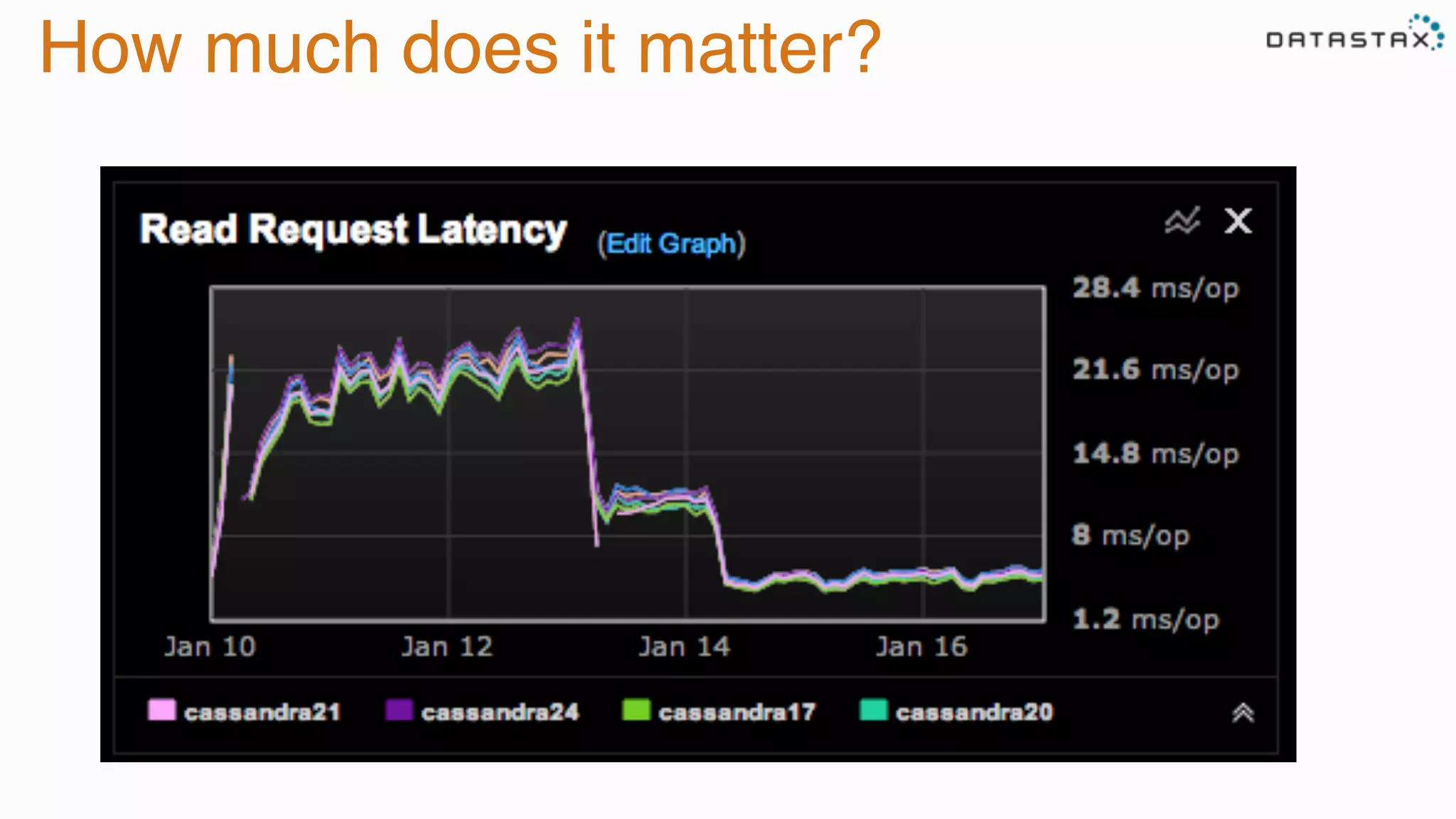



The document provides guidance on diagnosing and solving problems in production environments using Apache Cassandra, a distributed NoSQL database. It emphasizes the importance of preparation, monitoring, and debugging tools, as well as common pitfalls such as incorrect server timestamps and improper use of tombstones. Recommendations include utilizing DataStax OpsCenter, running regular maintenance like nodetool cleanup, and monitoring key metrics to identify performance issues.











































![[DE] Langzeitarchivierung von Daten und Datenbanken: Aufbewahrung zwischen Co...](https://cdn.slidesharecdn.com/ss_thumbnails/20110622vortragarchivierungdatendatenbankenibmulrichkampffmeyerhandout-161101093754-thumbnail.jpg?width=640&height=640&fit=bounds)













































![Vibe Coding vs. Spec-Driven Development [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/vibecodingvsspecdrivendevelopment-251209105622-43f455e7-thumbnail.jpg?width=640&height=640&fit=bounds)

















